










Introduction
我是R的忠实粉丝 - 这不是什么秘密。 自从我在大学学习统计数据以来,我一直依赖它。 实际上,R仍然是机器学习项目的首选语言。
R有三件事主要吸引我:
- 易于理解和使用的语法
- 令人难以置信的RStudio工具
- R套餐!
R提供了大量用于执行机器学习任务的软件包,包括用于数据操作的’dplyr’,用于数据可视化的’ggplot2’,用于构建ML模型的’caret’等。

甚至还有用于特定功能的R套餐,包括信用风险评分,从网站上搜集数据,计量经济学等等。这就是为什么R在世界各地的统计学家中都很受欢迎的原因 - 可用的R套餐数量太多,这使得生活变得更加容易。
在本文中,我将展示8个R软件包,这些软件包已经被数据科学家们所忽视,但对于执行特定的机器学习任务非常有用。 为了帮助您入门,我提供了一个示例以及每个包的代码。
相信我,你对R的爱将要经历另一场革命!
The R Packages We’ll Cover in this Article
I have broadly divided these R packages into three categories:
- Data Visualization
- DataExplorer
- esquisse
- Machine Learning
- MLR
- parsnip
- Ranger
- purrr
- Other Miscellaneous R Packages
- rtweet
- Reticulate
- Bonus: More R Packages!
- InstallR
- GitHubInstall
Data Visualization

R是一个用于可视化数据的神奇工具。 我们只用一两行代码就能轻松生成各种图形? 真正节省时间。
R提供了看似无数的可视化数据的方法。 即使我在某个任务中使用Python,我也会回到R来探索和可视化我的数据。 我相信大多数R用户都有同感!
让我们看一些用于执行探索性数据分析的可怕但鲜为人知的R包。
DataExplorer
这是我进行探索性数据分析的首选方案。 从绘制数据结构到Q-Q图,甚至为数据集创建报告,这个包完成了所有工作。
让我们看看DataExplorer可以使用一个例子做些什么。 考虑到我们已将数据存储在数据变量中。 现在,我们想要计算出每个要素中缺失值的百分比。 当我们处理大量数据集并计算缺失值的总和可能非常耗时时,这非常有用。
您可以使用以下代码安装DataExplorer:
install.packages("DataExplorer")
现在让我们看看DataExplorer可以为我们做些什么:
library(DataExplorer)
data(iris)
plot_missing(iris)
我们得到了一个非常直观的缺失值图:

我最喜欢的DataExplorer方面之一是我们只需一行代码即可生成的综合报告:
create_report(iris)
以下是我们在本报告中获得的各种因素:

You can access the full report through this link. A VERY useful package.
esquisse
用于在R中生成绘图的“拖放”插件怎么样? 这是正确的 - esquisse是一个包,让你继续创建绘图而无需编写它们。

Esquisse建立在ggplot2包之上。 这意味着您可以通过生成ggplot2图表以交互方式探索esquisse环境中的数据。
使用以下代码在您的机器上安装和加载esquisse:
# From CRAN
install.packages("esquisse")
#Load the package in R
library(esquisse)
esquisse::esquisser() #helps in launching the add-in
您还可以通过RStudio菜单启动esquisse加载项。 esquisse的用户界面如下所示:
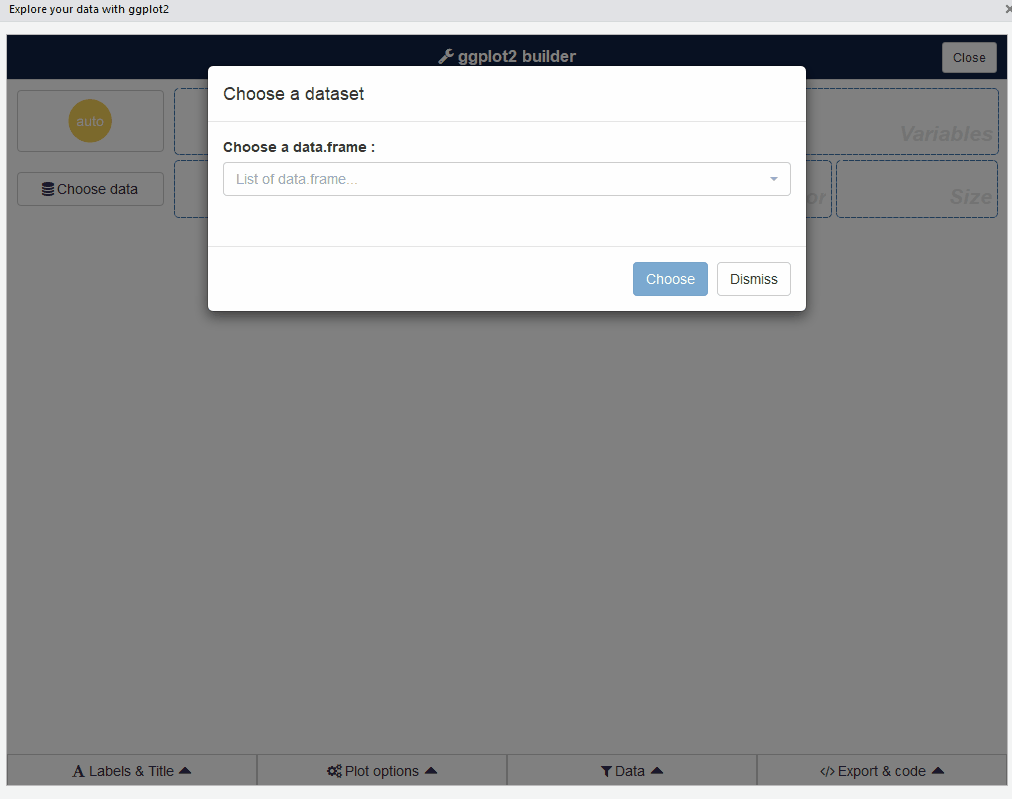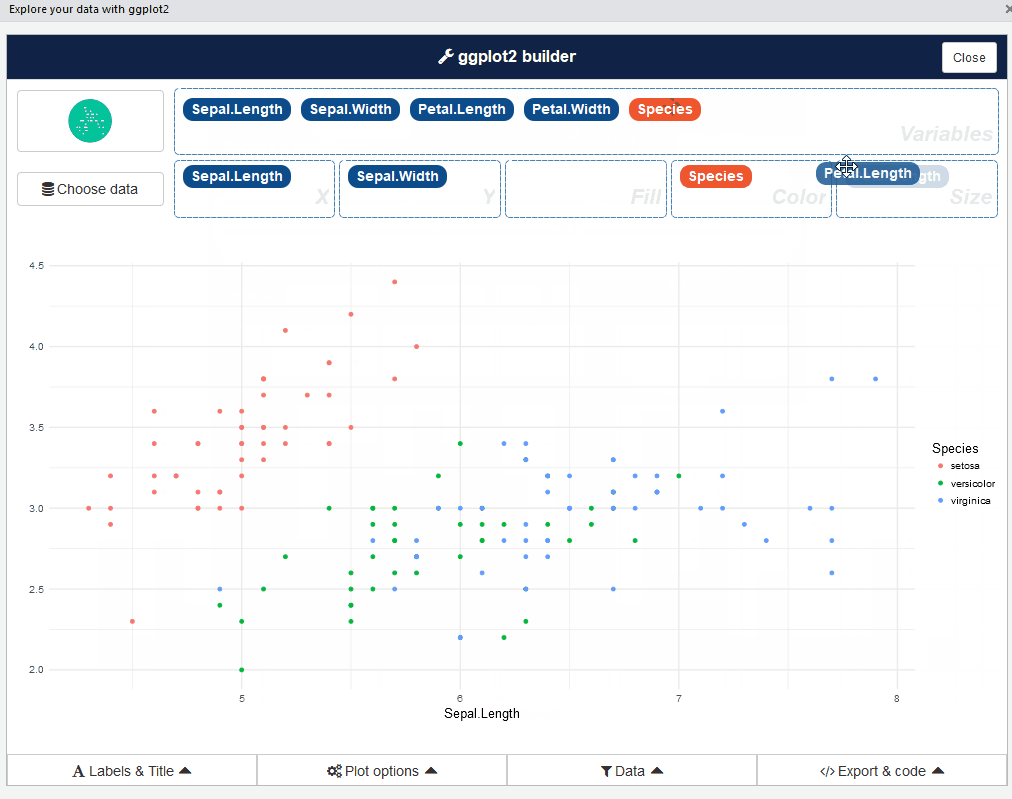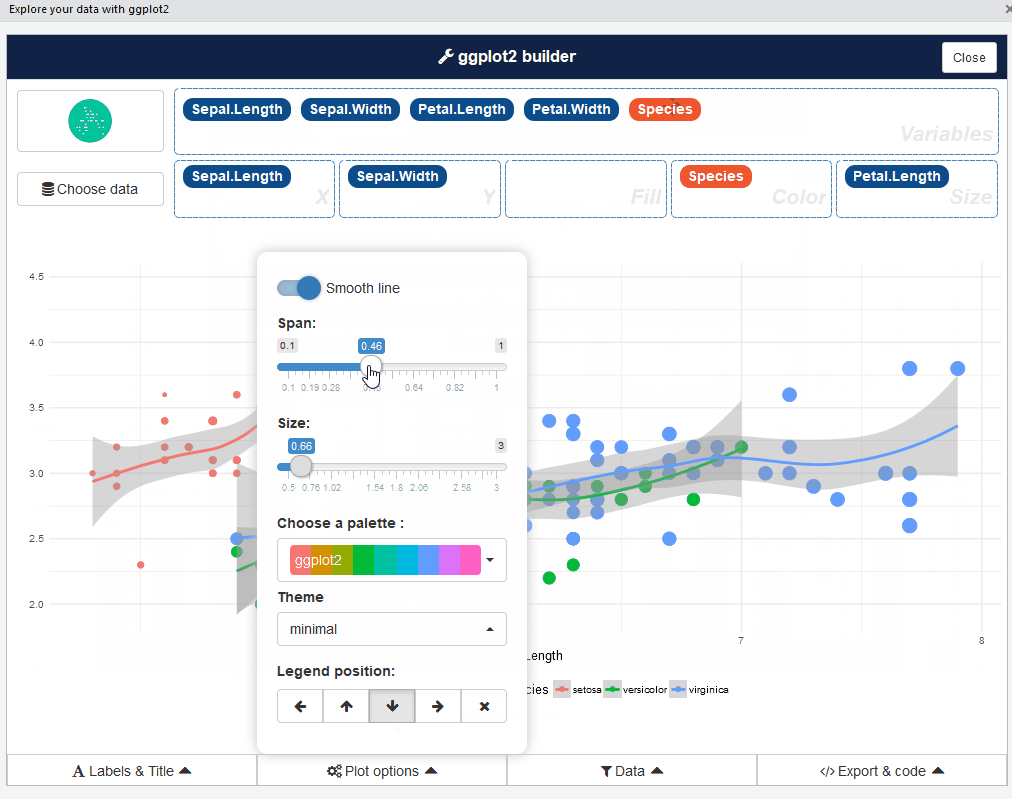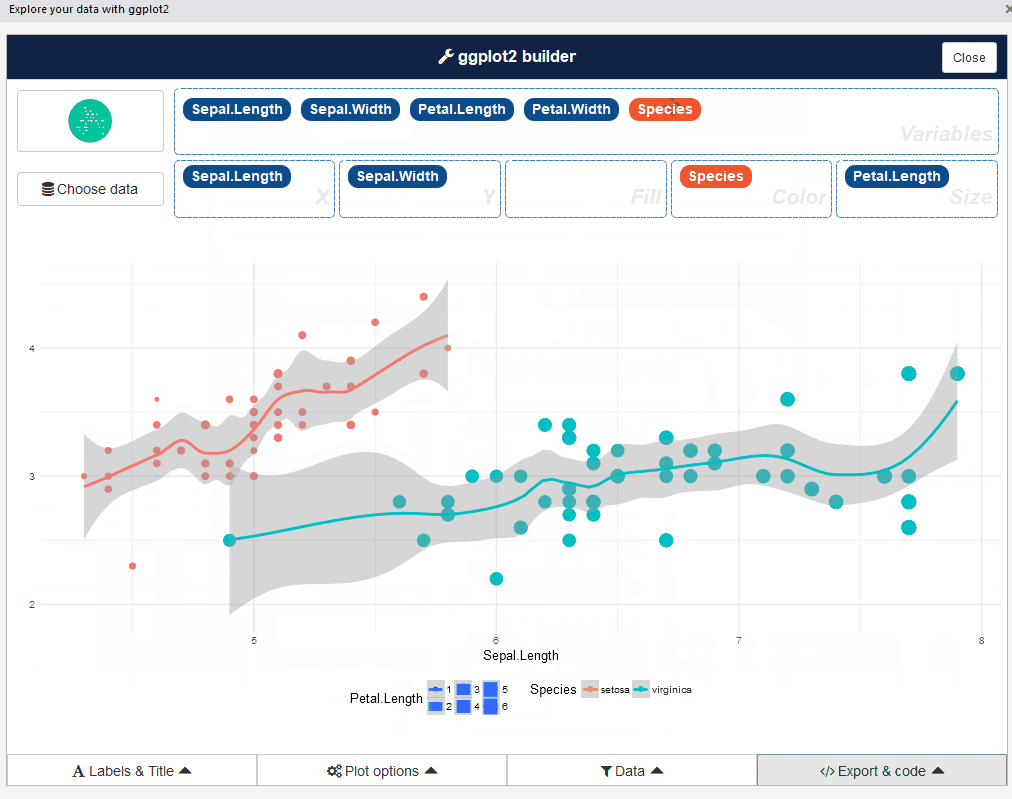
很酷,对吗? 来吧,玩弄不同类型的情节 - 这是一个令人大开眼界的体验。
Machine Learning

啊,在R中构建机器学习模型。当我们开始新的机器学习项目时,数据科学家们正在努力实现这一目标。 您可能以前使用’插入’包来构建模型。
现在,让我向您介绍一些可能会改变您接近模型构建过程的方法。
MLR – Machine Learning in R
Python在R之前飙升的最大原因之一是它的机器学习重点库(如scikit-learn)。 很长一段时间,R缺乏这种能力。 当然你可以使用不同的包来执行不同的ML任务,但是没有一个包可以完成所有任务。 我们不得不调用三个不同的库来构建三个不同的模型。
不理想。
然后MLR包出现了。 这是一个令人难以置信的包,它允许我们执行各种机器学习任务。 MLR包括我们在项目中使用的所有流行的机器学习算法。

我强烈建议您仔细阅读以下文章深入了解MLR:
让我们看看如何在iris数据集上安装MLR并构建随机森林模型:
install.packages("mlr")
library(mlr)
# Load the dataset
data(iris)
# create task
task = makeClassifTask(id = ”iris”, iris, target = ”Species”)
# create learner
learner = makeLearner(”classif.randomForest”)
# build model and evaluate
holdout(learner, task)
# measure accuracy
holdout(learner, task, measures = acc)
Output:
Resample Result
Task: iris
Learner: classif.randomForest
Aggr perf: acc.test.mean=0.9200000 # 92% accuracy - not bad!
Runtime: 0.0239332
parsnip
R中可用的不同函数(执行相同的操作)的常见问题是它们可以具有不同的接口和参数。 以随机森林算法为例。 你在randomforest包和插入符包中使用的代码是不同的,对吧?
与MLR一样,parsnip消除了为特定机器学习算法引用多个包的问题。 它成功地在R中模仿Python的scikit-learn包。
让我们看一下下面的简单示例,让您深入了解parsnip如何适用于线性回归问题:
install.packages("parsnip")
library(parsnip)
#Load the dataset
data(mtcars)
#Build a linear regression model
fit <- linear_reg("regression") %>%
set_engine("lm") %>%
fit(mpg~.,data=mtcars)
fit #extracts the coefficient values
Output:
parsnip model object
Call:
stats::lm(formula = formula, data = data)
Coefficients:
(Intercept) cyl disp hp drat wt qsec
12.30337 -0.11144 0.01334 -0.02148 0.78711 -3.71530 0.82104
vs am gear carb
0.31776 2.52023 0.65541 -0.19942
Ranger
Ranger是我最喜欢的R套餐之一。 我经常使用随机森林来建立基线模型 - 特别是当我参与数据科学黑客马拉松时。
这是一个问题 - 你有多少次遇到R中大型数据集的慢随机森林计算? 它在我的旧机器上经常发生。
插入符号,随机森林和rf等包都需要花费大量时间来计算结果。 “Ranger”软件包加速了随机森林算法的模型构建过程。 它可以帮助您在更短的时间内快速创建大量树木。
让我们使用Ranger编写一个随机森林模型:
install.packages("ranger")
#Load the Ranger package
require(ranger)
#Load the dataset
data(iris)
## Classification forest
ranger(Species ~ ., data = iris,num.trees=100,mtry=3)
## Prediction
train.idx <- sample(nrow(iris), 2/3 * nrow(iris))
iris.train <- iris[train.idx, ]
iris.test <- iris[-train.idx, ]
rg.iris <- ranger(Species ~ ., data = iris.train)
pred.iris <- predict(rg.iris, data = iris.test)
#Build a confusion matrix
table(iris.test$Species, pred.iris$predictions)
Output:
setosa versicolor virginica
setosa 16 0 0
versicolor 0 16 2
virginica 0 0 16
相当令人印象深刻的表现。 您应该在更复杂的数据集上尝试Ranger,看看您的计算速度有多快。
purrr
在数据的不同部分运行线性回归模型并计算每个模型的评估指标时,会筋疲力尽吗? purrr包来救你。
您还可以为不同的数据块构建广义线性模型(glm),并以列表的形式为每个要素计算p值。 purrr的优点是无穷无尽的!
让我们看一个例子来了解它的功能。 我们将在此建立一个线性回归模型,并对R平方值进行子集化:
#First, read in the data mtcars
data(mtcars)
mtcars %>%
split(.$cyl) %>% #selecting cylinder to create three sets of data using the cyl values
map(~ lm(mpg ~ wt, data = .)) %>%
map(summary) %>%
map_dbl("r.squared")
Output
4 6 8
0.5086326 0.4645102 0.4229655
所以你观察到了吗? 这个例子使用purrr来解决一个相当现实的问题:
- 将数据框拆分为多个部分
- 为每件作品安装模型
- 计算摘要
- 最后,提取R平方值
给我们节省了很多时间,对吧? 我们只使用一行代码,而不是运行三个不同的模型和三个命令来对R平方值进行子集化。
Utilities: Other Awesome R Packages
让我们来看看其他一些不一定属于“机器学习”保护伞的软件包。 我发现这些在使用R方面很有用。
rtweet
情感分析是机器学习中最受欢迎的应用之一。 在当今的数字世界中,这是一个不可避免的现实。 Twitter是提取推文和构建模型以理解和预测情绪的主要目标。
现在,有一些R包用于提取/抓取推文和执行情绪分析。 'rtweet’包也是如此。 那么它与其他包装有什么不同呢?

'rtweet’还可以帮助您检查R本身的推文趋势。真棒!
# install rtweet from CRAN
install.packages("rtweet")
# load rtweet package
library(rtweet)
必须授权所有用户与Twitter的API进行交互。 要获得授权,请按照以下说明操作:
1.制作Twitter应用程序
2.创建并保存访问令牌
有关从Twitter获取身份验证的详细分步过程,请点击此链接。
您可以使用下面提到的代码行搜索带有某些主题标签的推文。 让我们尝试使用标签#avengers搜索所有推文,因为Infinity War已全部发布。
#1000 tweets with hashtag avengers
tweets <- search_tweets(
"#avengers", n = 1000, include_rts = FALSE)
You can even access the user IDs of people following a certain page. Let’s see an example:
## get user IDs of accounts following marvel
marvel_flw <- get_followers("marvel", n = 20000)
你可以用这个包做更多的事情。 尝试一下,如果您发现令人兴奋的事情,请不要忘记更新社区。
Reticulate
喜欢R和Python编码,但想坚持RStudio? 网纹就是答案! 该软件包通过在R中提供Python接口解决了这个突出的问题。您可以轻松地使用R本身内的主要python库,如numpy,pandas和matplotlib!
您还可以使用一行代码轻松地将数据从Python转换为R和R转换为Python。 这不是很棒吗? 查看下面的代码块,看看在R中运行python是多么容易。

在继续在R中直接安装网状网之前,您必须先安装TensorFlow和Keras。
install.packages("tensorflow")
install.packages("keras")
library(tensorflow)
library(keras)
install_keras()
install.packages("reticulate")
library(reticulate)
你很高兴去! 运行我在屏幕截图中提供的命令,并以类似的方式尝试您的数据科学项目。
BONUS
这里有两个其他实用程序R包,适合所有编程书呆子!
Installr
你是否单独更新你的R套餐? 这可能是一项繁琐的任务,尤其是当有多个包在起作用时。
'InstallR’包允许您只使用一个命令更新R及其所有包! 我们可以使用InstallR一次性更新所有软件包,而不是检查每个软件包的最新版本。
# installing/loading the package:
if(!require(installr)) {
install.packages("installr"); require(installr)} #load / install+load installr
# using the package:
updateR() # this will start the updating process of your R installation.
# It will check for newer versions, and if one is available, will guide you through the decisions you'd need to make
GitHubInstall – An Easy Way to Install R Packages from GitHub
您使用哪个包从GitHub安装库? 我们大多数人长期依赖’devtools’套餐。 这似乎是唯一的方式。 但有一点需要注意 - 我们需要记住开发人员的名字来安装软件包:
install_github("DeveloperName/PackageName")
使用’githubinstall’包,不再需要开发人员名称。
install.packages("githubinstall")
#Install any GitHub package by supplying the name
githubinstall("PackageName")
#githubinstall("AnomalyDetection")
该软件包还为GitHub上托管的R软件包提供了一些有用的功能。 我建议查看包文档(上面链接)以获取更多详细信息。
End Notes
这绝不是一份详尽的清单。 还有很多其他R套件可以提供有用的功能,但却被大多数人忽略了。
你知道我在这篇文章中遗漏的任何套餐吗? 或者您是否在项目中使用了上述任何一种? 我很乐意听到你的消息! 在下面的评论部分与我联系,让我们谈谈R!
















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











