







大家好,我是程序员鱼皮。最近 DeepSeek AI 太火了,效果也很强,但致命问题是 不稳定, 经常给我返回 服务器繁忙,请稍后再试,甚至让我怀疑自己被杀熟了。
也有网友说,第一次使用成功率很高,第二次可能就繁忙了。。。
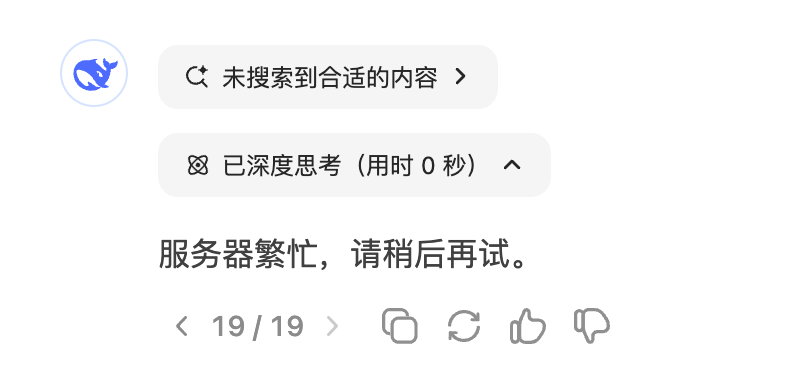
那有什么办法稳定使用 DeepSeek 么?
作为一名程序员,首先想到的是:既然 DeepSeek 都开源了,那我直接本地部署一个不就行了吗?
可是满血版的 DeepSeek-R1 光模型就占了 404GB 空间,个人电脑根本负担不起呀!我就要稳定使用满血版 DeepSeek,怎么办呢?

我们可以使用第三方平台提供的接口服务,大公司帮我们部署了满血版 DeepSeek,我们直接通过 API 调用就行。下面只需 2 分钟,教你如何使用 API 来调用满血版的 DeepSeek!
学会之后,可以接入 DeepSeek AI 到自己项目中、写到简历上,面试官看到也会眼前一亮~
建议观看视频版教程:https://bilibili.com/video/BV1zVAHesEv7
第三方平台选择
目前支持 DeepSeek 的主流第三方平台有硅基流动、OpenRouter、腾讯云、阿里云、百度云、火山引擎等等,看来各大厂都积极入局了。接下来我会以其中 2 个平台为例,用 Java 来调用 AI 完成智能问答,学会之后换个平台也是易如反掌。
最后我还会给大家分享一个详细的第三方平台对比表格,大家可以按需选择。
硅基流动
汇集了很多类 AI 大模型的云服务平台。进入模型广场,选择满血版的 DeepSeek-R1 模型:
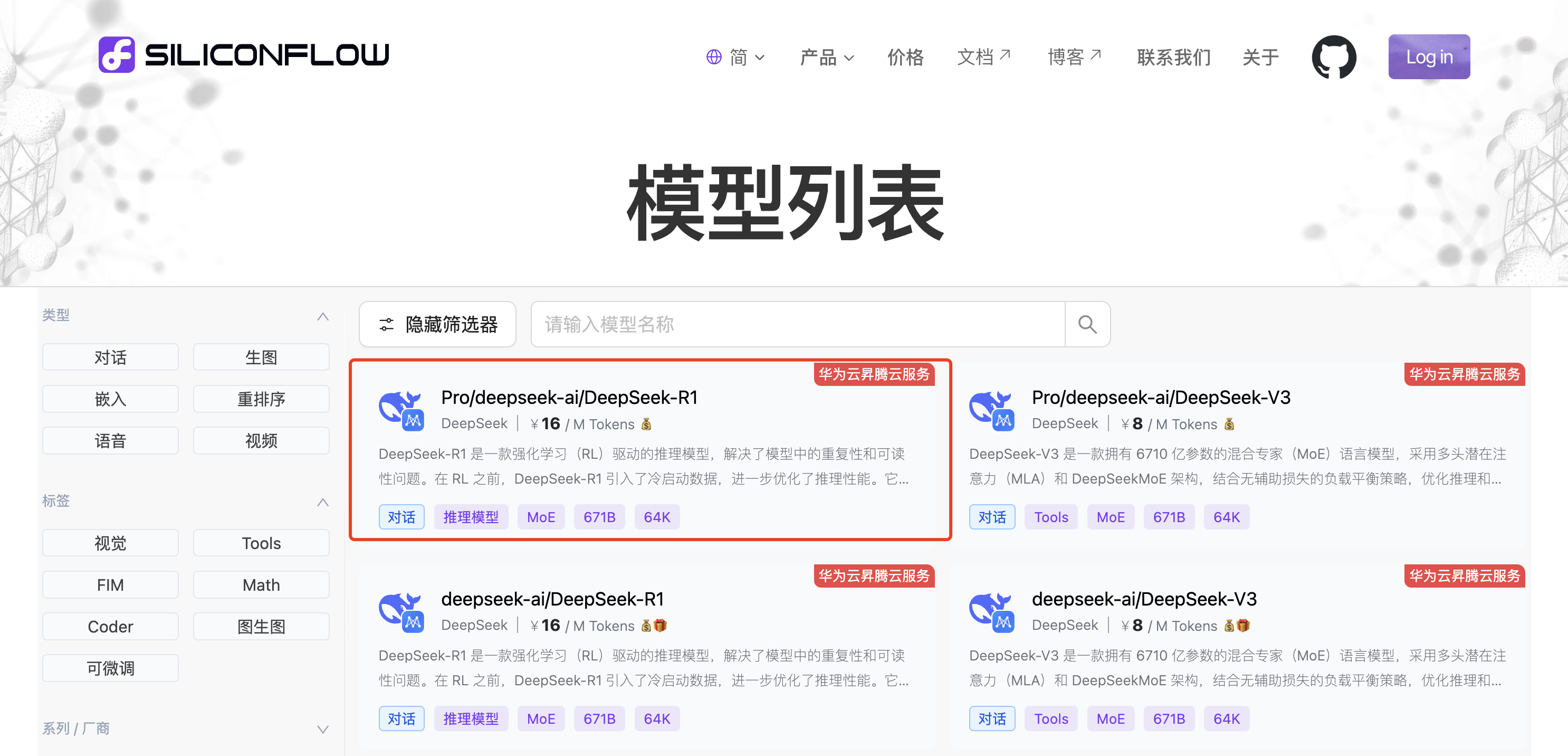
注意,调用 AI 大模型通常是按照消耗的 token 数计费的,不过新用户会赠送一定额度,也够我们学习和日常使用了。
查看模型对应的 API 文档,选择对应的编程语言,就能看到发送请求的示例代码了,可以直接复制使用:
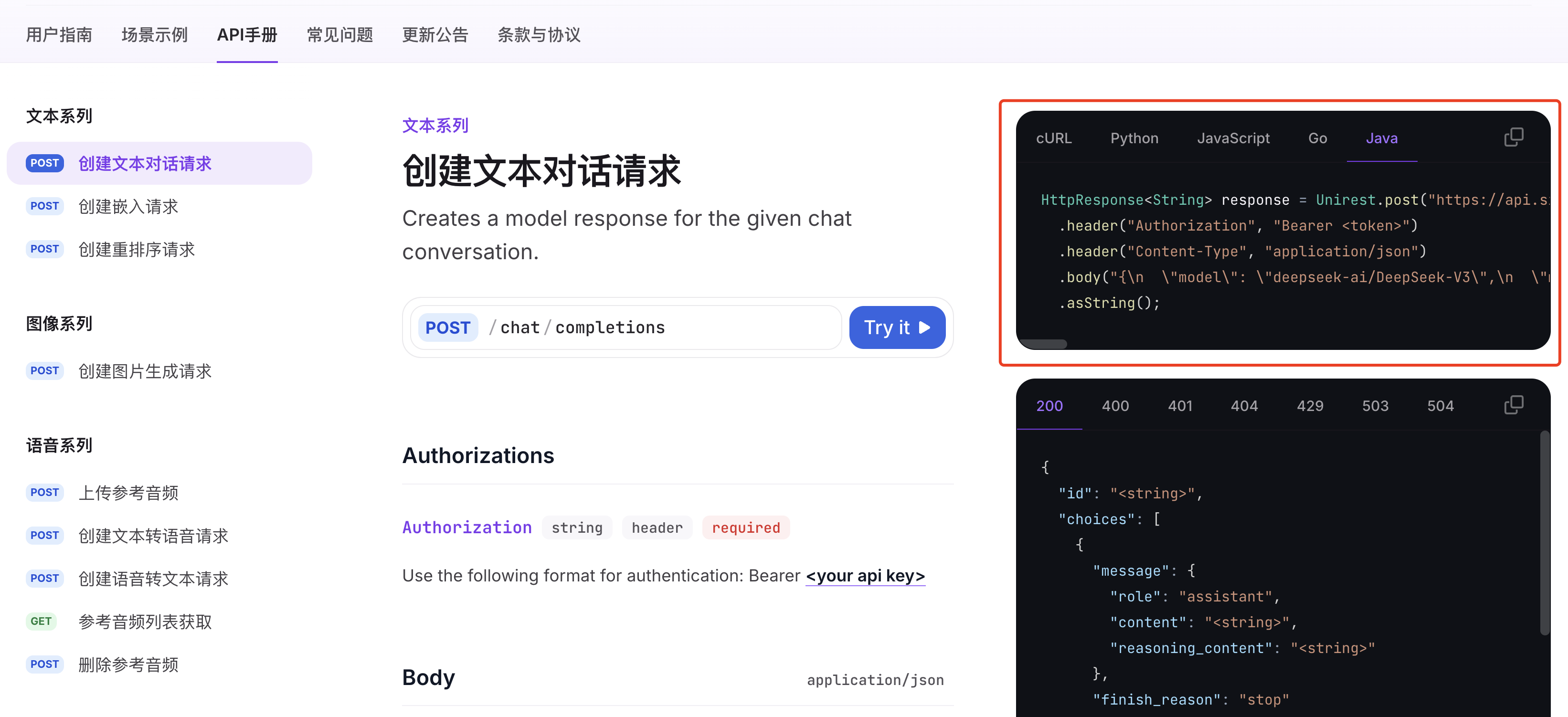
随便新建一个干净的 Java Maven 项目,引入发送请求所需的 Unirest 库:
<dependency>
<groupId>com.konghq</groupId>
<artifactId>unirest-java</artifactId>
<version>3.14.1</version>
</dependency>
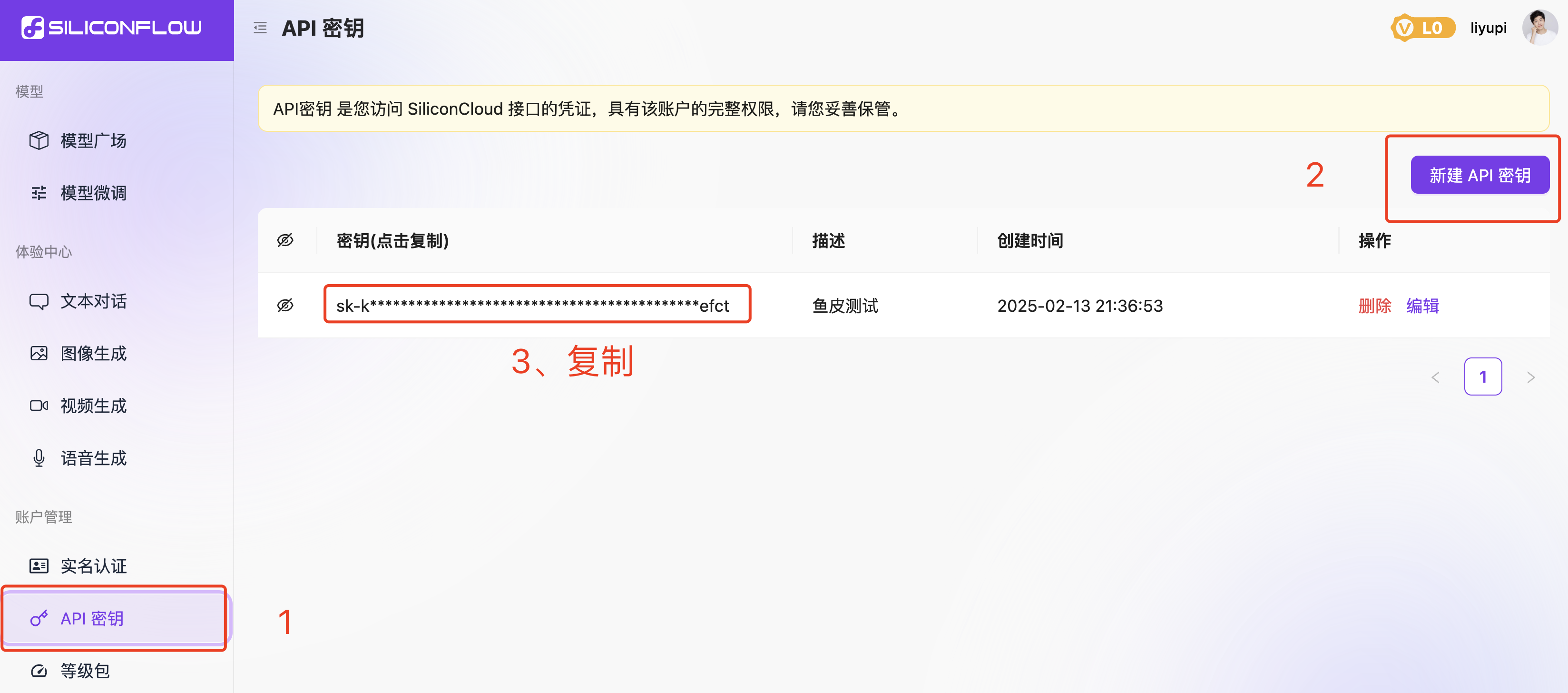
然后粘贴示例代码到主类中。我们首先需要修改代码中的鉴权 token,在官网找到 API 密钥,新建一个 API 密钥,注意不要暴露出去哦!然后复制到代码中。
接下来就可以指定想用的模型、要输入给 AI 的提示词,最后打印出 AI 响应的结果即可。就这么几行代码:
HttpResponse<String> response = Unirest.post("https://api.siliconflow.cn/v1/chat/completions")
.header("Authorization", "Bearer " + "你自己的 APIKey")
.header("Content-Type", "application/json")
.body("{\n \"model\": \"deepseek-ai/DeepSeek-V3\",\n \"messages\": [\n {\n \"role\": \"user\",\n \"content\": \"程序员鱼皮是谁?\"\n }\n ],\n \"stream\": false,\n \"max_tokens\": 512,\n \"stop\": [\n \"null\"\n ],\n \"temperature\": 0.7,\n \"top_p\": 0.7,\n \"top_k\": 50,\n \"frequency_penalty\": 0.5,\n \"n\": 1,\n \"response_format\": {\n \"type\": \"text\"\n },\n \"tools\": [\n {\n \"type\": \"function\",\n \"function\": {\n \"description\": \"<string>\",\n \"name\": \"<string>\",\n \"parameters\": {},\n \"strict\": false\n }\n }\n ]\n}")
.asString();
System.out.println(response.getBody());
我们来 Debug 一下,稍等一会儿,就能看到 AI 的回复了:
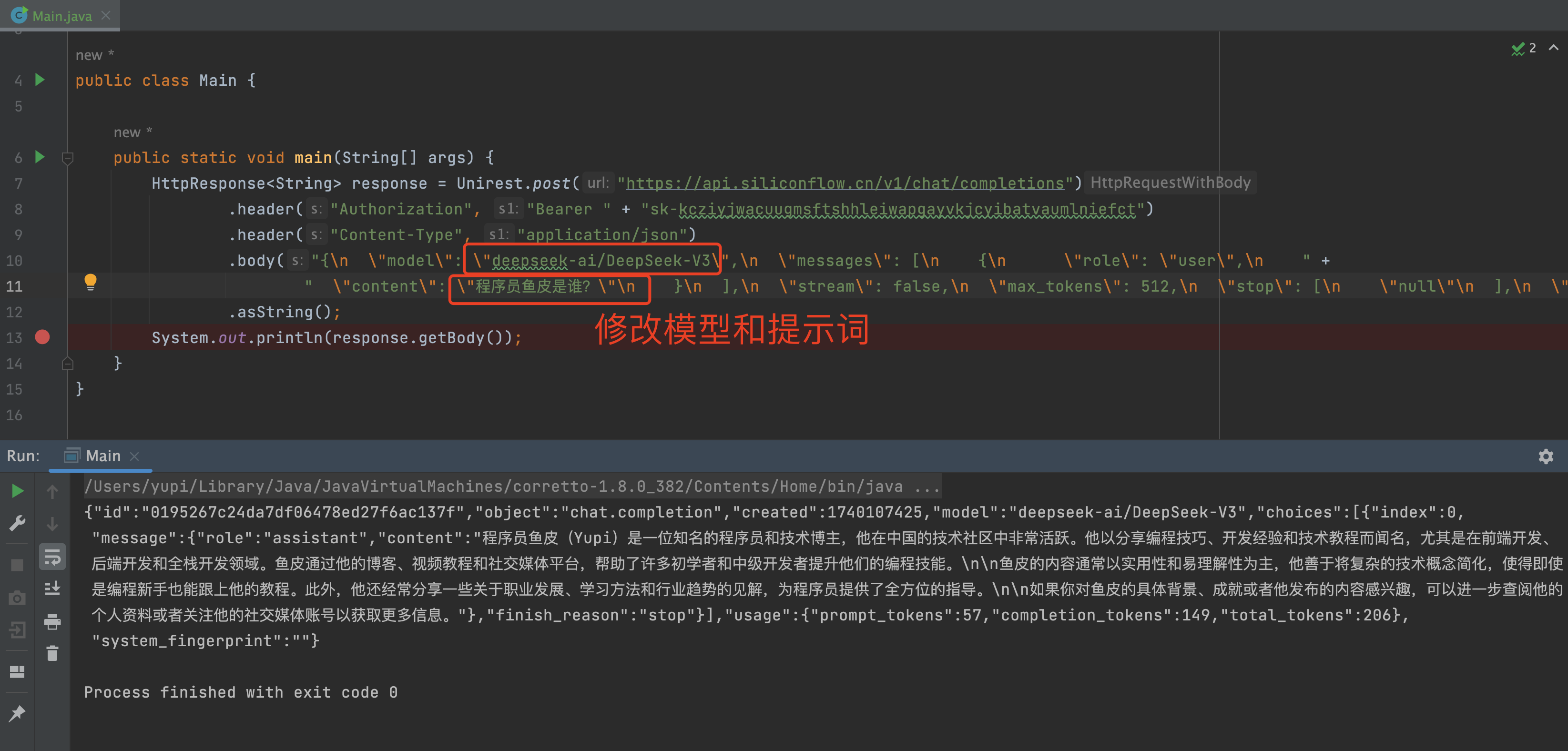
不过我尝试的这段时间,这个平台输出速度比较慢、也不是很稳定吧。
火山引擎
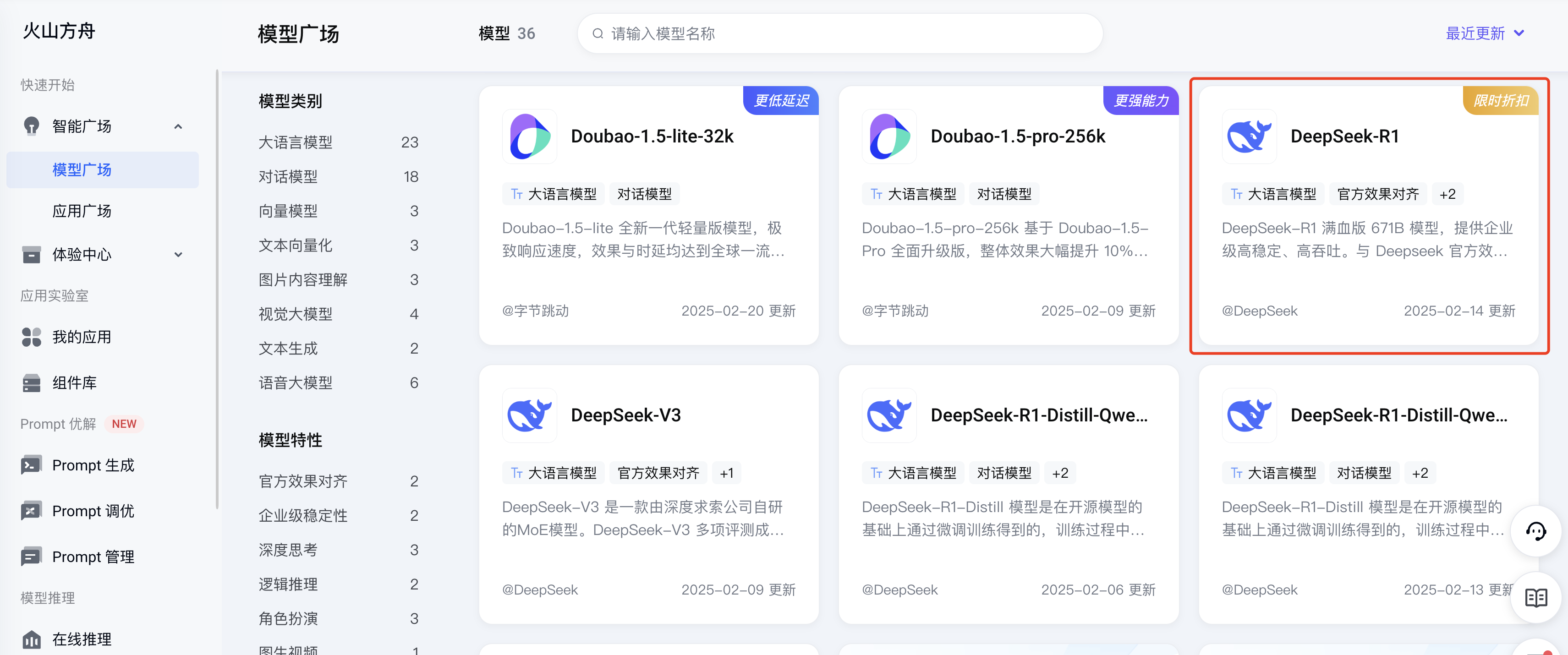
我们再换一个平台 —— 火山,首先进入模型广场,选择满血版的 DeepSeek-R1 模型:
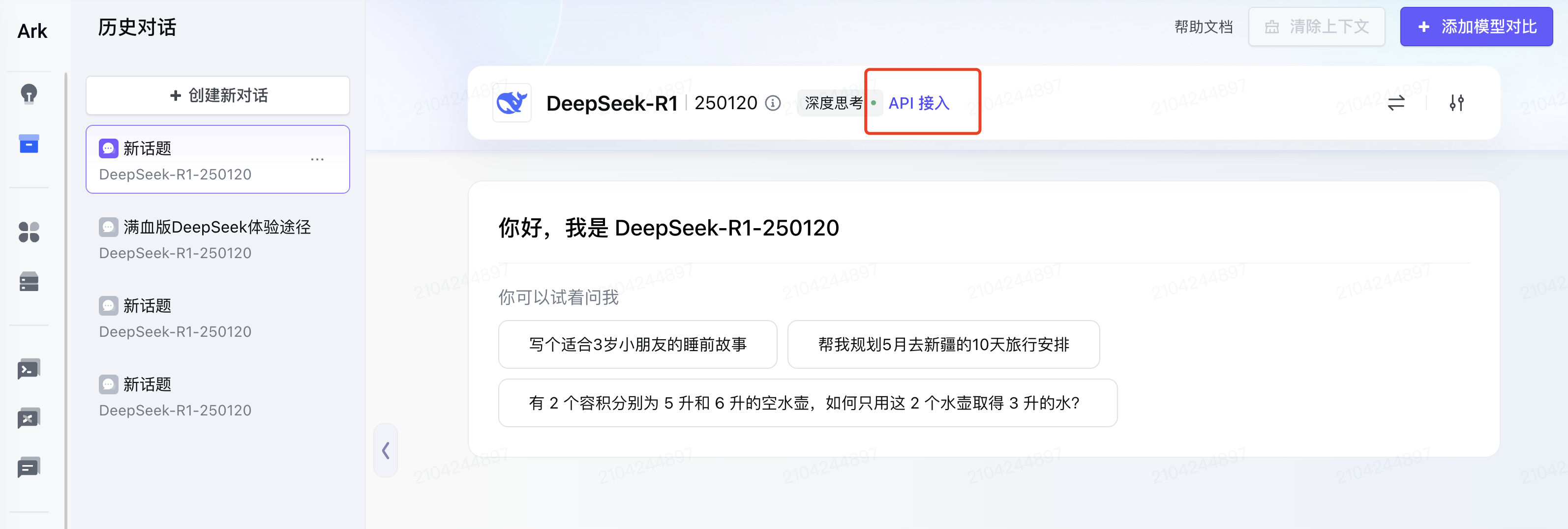
点击立即体验,就可以和 AI 对话了,新用户也会赠送一定 tokens 额度。我们选择 API 接入:
创建一个接入点:
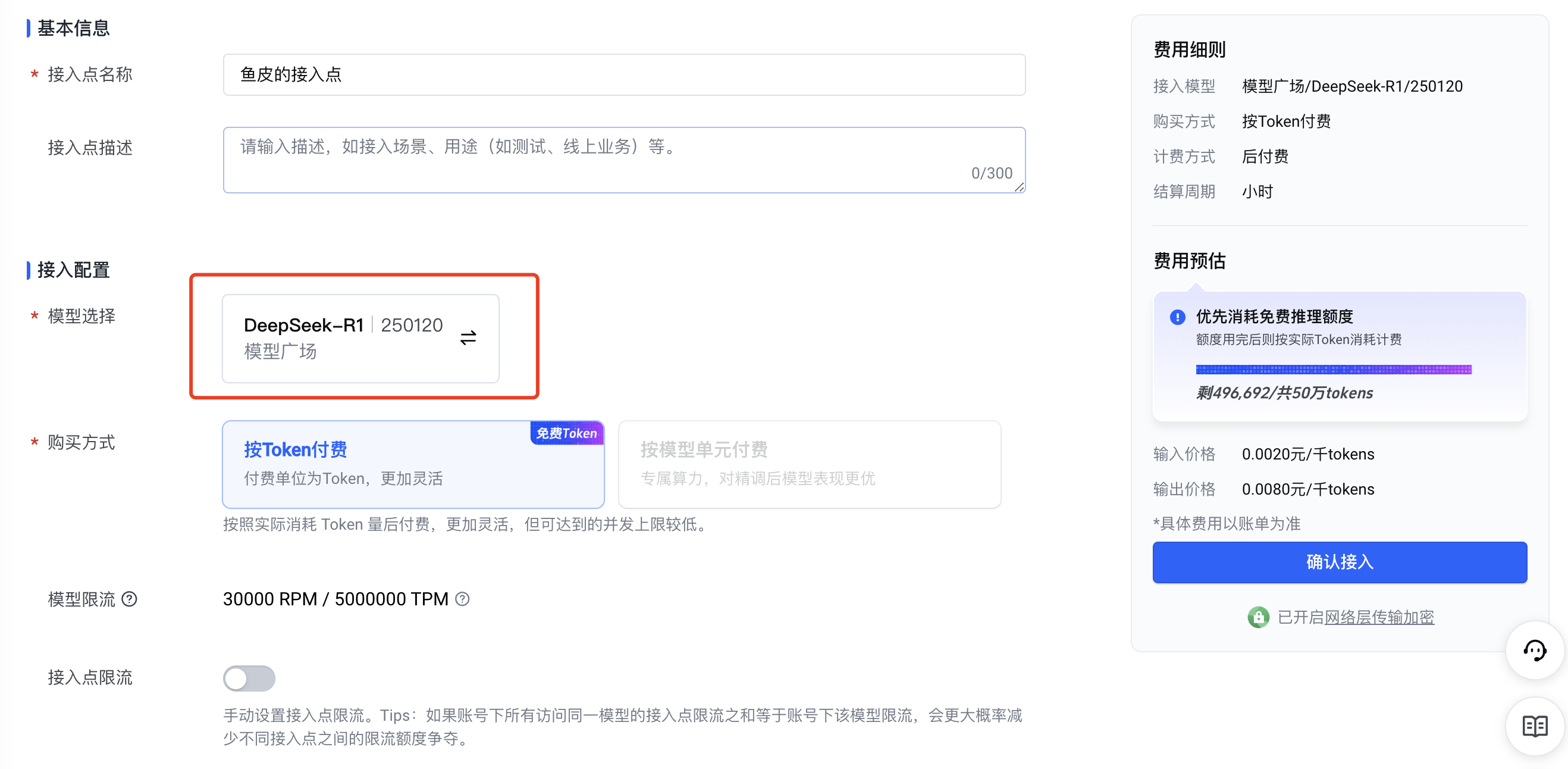
注意,如果还没有开通模型,需要选择 DeepSeek-R1 模型,点击立即开通:
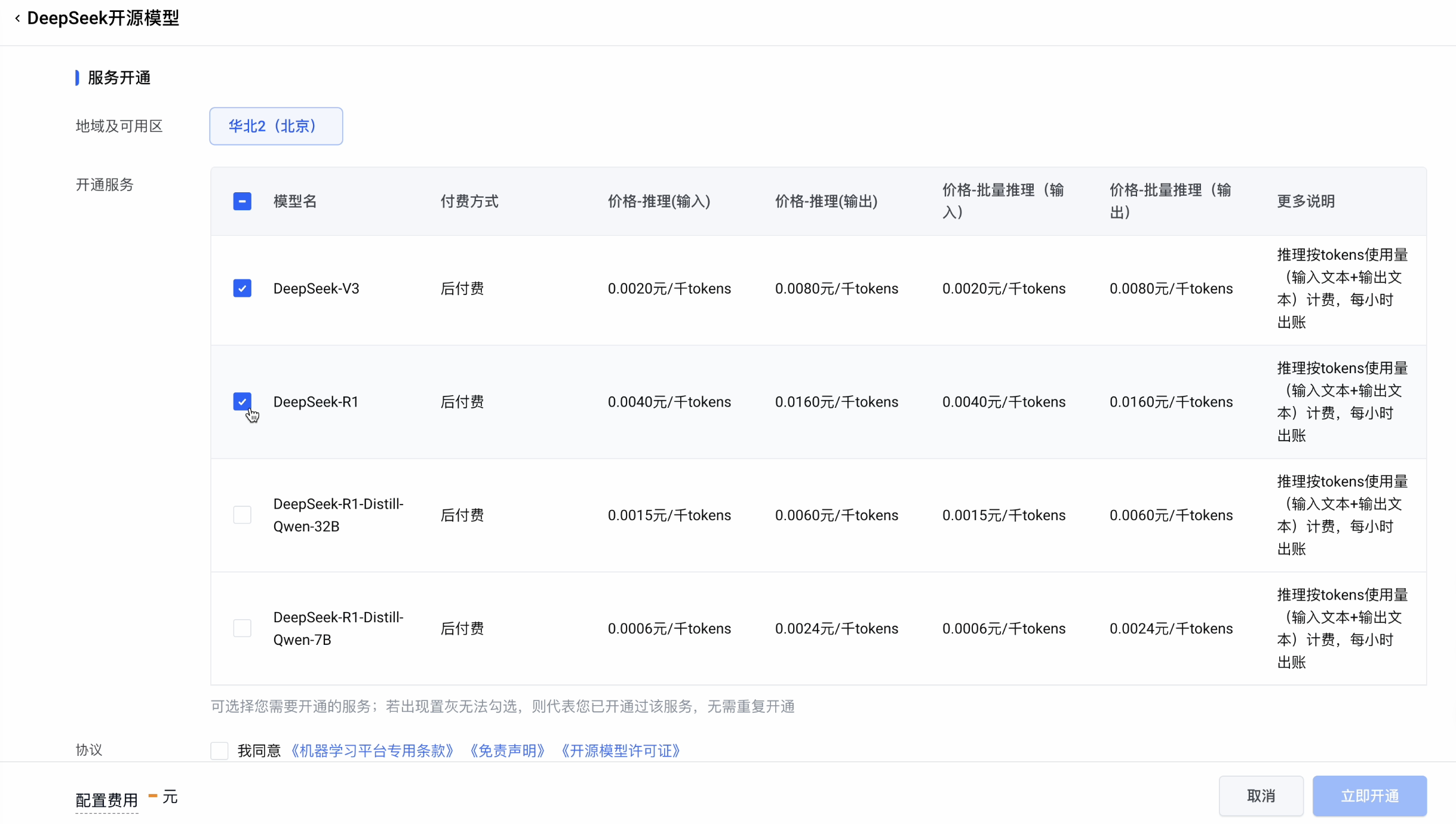
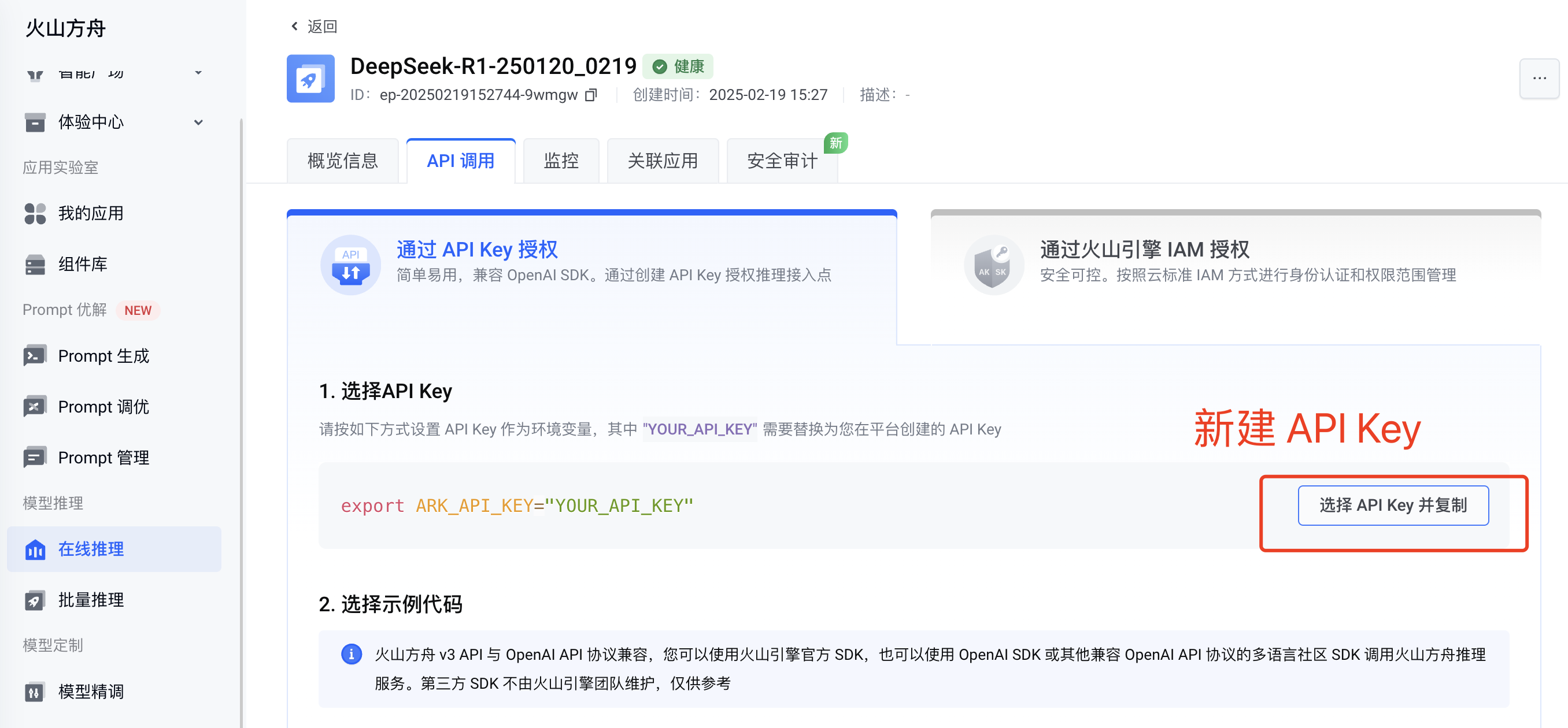
开通成功后,回到之前的页面,确认接入。然后就进入到了 API 调用页面,先创建一个自己的 API Key,保存好等下会用到。
然后我们选择官方的 SDK 调用示例,获取到对应编程语言的示例代码:
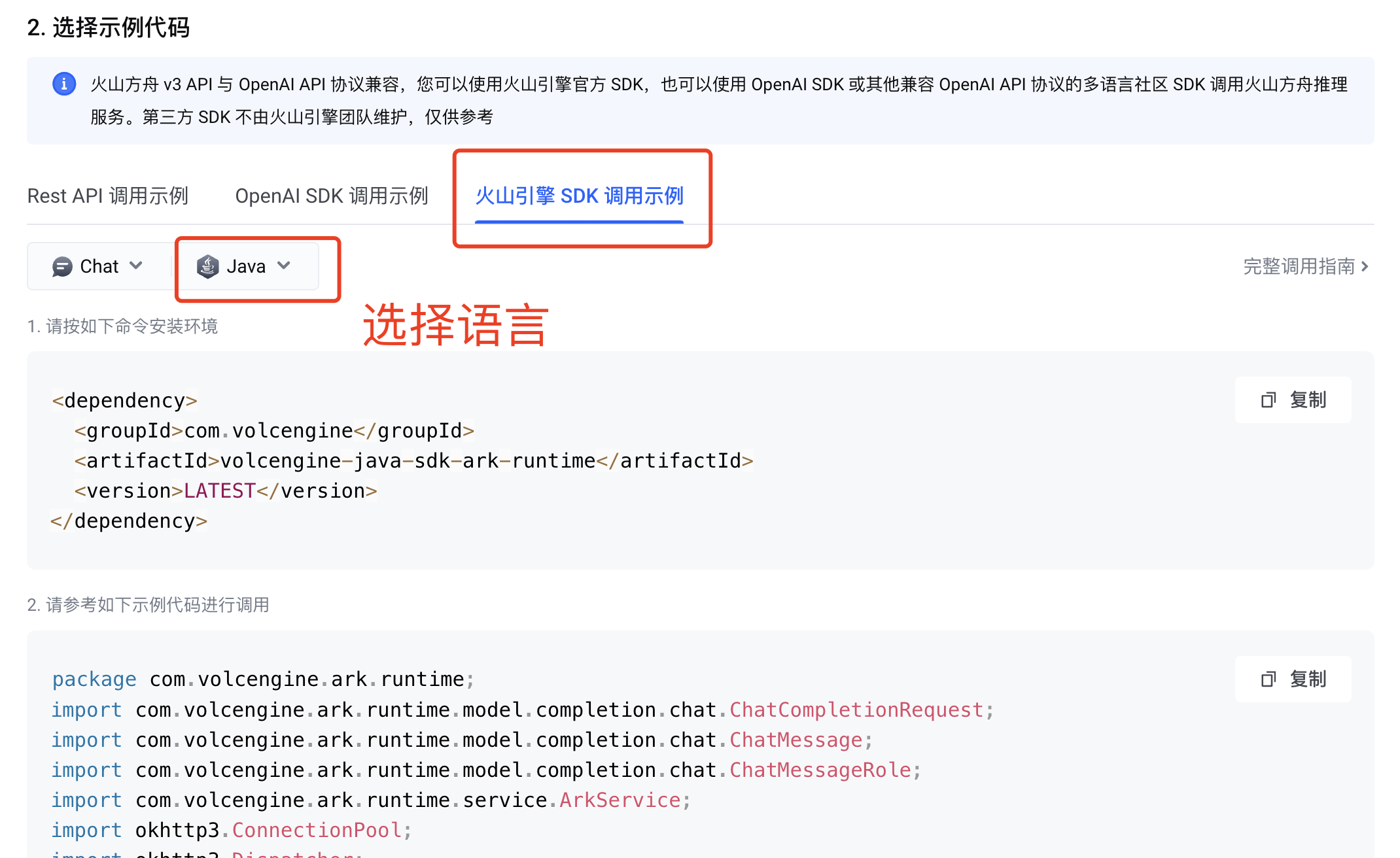
首先在项目中引入 SDK 和相关依赖,注意要修改依赖的版本号(不要直接用 “LATEST”):
<dependency>
<groupId>com.volcengine</groupId>
<artifactId>volcengine-java-sdk-ark-runtime</artifactId>
<version>0.1.151</version>
</dependency>
然后复制示例代码,修改 API Key 和输入给 AI 的提示词,然后运行一下试试:
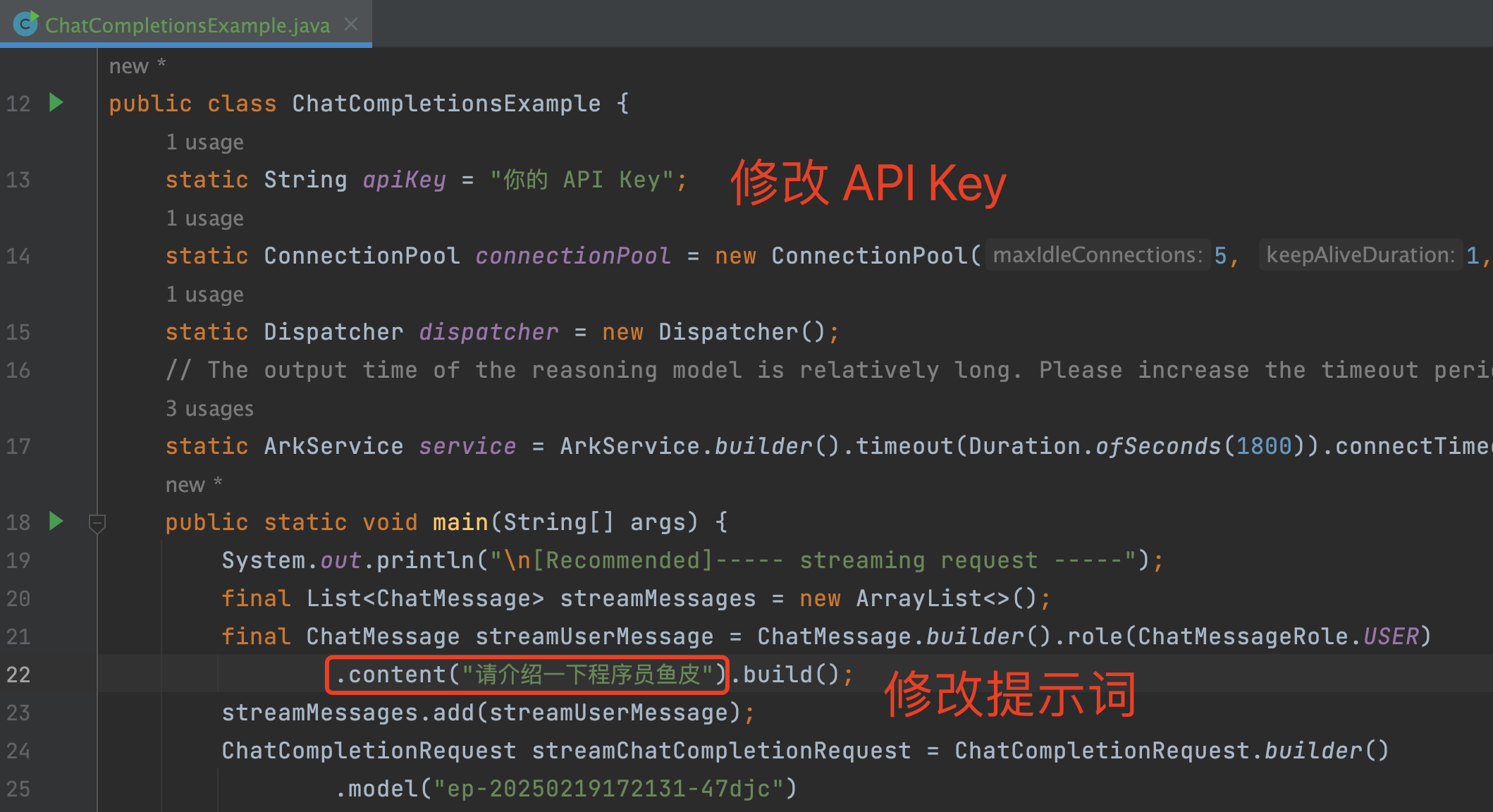
浇给!很快,AI 就给出了回复,实际测试下来比较稳定、响应速度也比较快。
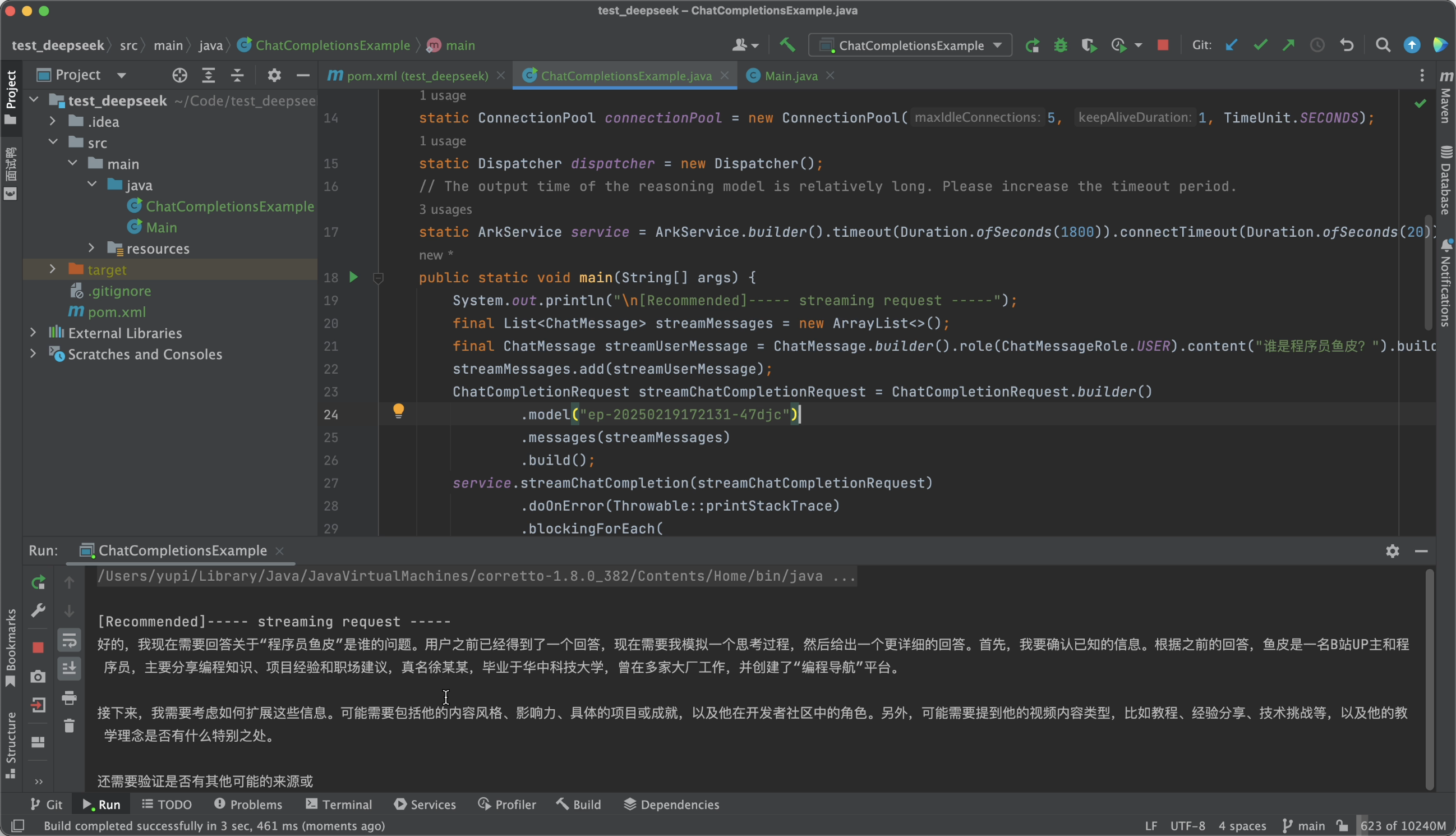
总结
怎么样,通过调用 API 将 AI 接入到项目中还是很简单吧。大家如果遇到更多的问题,建议优先查看官方的 API 调用指南文档,还有问题就去问 AI 和客服吧~
基本上每个平台我都体验了下,也整理了一个平台对比表格,大家可以参考下:
| 平台 | 价格(单位:百万 tokens) | 赠送 | 输出稳定性 | 输出速度(单位:秒) | 个人感受 |
|---|---|---|---|---|---|
| 硅基流动 | 输入:¥4,输出:¥16 | 14 元 | 较为不稳定,调用五次可能才有一次正常响应 | 9.05 tokens | 赠送的金额虽然很多,但是服务很不稳定,且输出速度也很慢。 |
| openrouter | 输入:$0.55,输出:$2.19 | 无赠送,但可最高欠费 1 美元。 | 服务较为稳定 | 7.47 tokens | 输出速度在上述平台中最慢,且在此平台付费较为麻烦,需要使用信用卡或者国外的银行卡,不建议国内使用。 |
| 腾讯云平台 | 输入:¥4,输出:¥16 | 无赠送 | 服务非常稳定 | 11.16 tokens | 上手特别简单,不需要开通任何东西,只需要拿到 ak / sk 直接调用官方提供的示例代码即可。 |
| 火山引擎 | 输入:¥2,输出:¥8 | 赠送 50 万 tokens | 服务非常稳定 | 28.08 tokens | 输出速度在上述平台中最快,且目前价格只有官网一半,赠送 50 万 tokens。 |
| 阿里云平台 | 输入:¥2,输出:¥8 | 赠送 100 万 tokens | 需要等大模型部署一段时间后才能稳定使用 | 12.24 tokens | 需要等百炼大模型部署完成后才能使用,部署需要花较长的时间,不过赠送的 tokens 比较多 |
大家如果要学习更多平台的调用、AI 提示词技巧、AI 部署教程、AI 行业资讯、AI 项目,都可以来看看我刚刚开源的 AI 知识库( https://github.com/liyupi/ai-guide )。大家如果还了解到了其他的满血 DeepSeek 平台,欢迎评论区留言分享~
更多编程学习资源
- Java前端程序员必做项目实战教程+毕设网站
- 程序员免费编程学习交流社区(自学必备)
- 程序员保姆级求职写简历指南(找工作必备)
- 程序员免费面试刷题网站工具(找工作必备)
- 最新Java零基础入门学习路线 + Java教程
- 最新Python零基础入门学习路线 + Python教程
- 最新前端零基础入门学习路线 + 前端教程
- 最新数据结构和算法零基础入门学习路线 + 算法教程
- 最新C++零基础入门学习路线、C++教程
- 最新数据库零基础入门学习路线 + 数据库教程
- 最新Redis零基础入门学习路线 + Redis教程
- 最新计算机基础入门学习路线 + 计算机基础教程
- 最新小程序入门学习路线 + 小程序开发教程
- 最新SQL零基础入门学习路线 + SQL教程
- 最新Linux零基础入门学习路线 + Linux教程
- 最新Git/GitHub零基础入门学习路线 + Git教程
- 最新操作系统零基础入门学习路线 + 操作系统教程
- 最新计算机网络零基础入门学习路线 + 计算机网络教程
- 最新设计模式零基础入门学习路线 + 设计模式教程
- 最新软件工程零基础入门学习路线 + 软件工程教程


















 5951
5951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











