







 在上一篇文章我们已经完成数据的采集,并将数据存储在mysql,现在我们来继续后面的数据分析工作,先放出项目流程:0. 主要流程0. 数据采集0. 目标网址获取1. 爬虫框架选用注:了解这一步请登录https://www.jianshu.com/p/2b015d289083 或http://blog.csdn.net/weixin_41716128/article/details/7930...
在上一篇文章我们已经完成数据的采集,并将数据存储在mysql,现在我们来继续后面的数据分析工作,先放出项目流程:0. 主要流程0. 数据采集0. 目标网址获取1. 爬虫框架选用注:了解这一步请登录https://www.jianshu.com/p/2b015d289083 或http://blog.csdn.net/weixin_41716128/article/details/7930...
在上一篇文章我们已经完成数据的采集,并将数据存储在mysql,现在我们来继续后面的数据分析工作,先放出项目流程:
0. 主要流程
0. 数据采集
0. 目标网址获取
1. 爬虫框架选用
注:了解这一步请登录https://www.jianshu.com/p/2b015d289083
或http://blog.csdn.net/weixin_41716128/article/details/79306923
1. 数据处理
由于某种原因上一篇采集的960条记录不小心给我删除了--_--(而且没有备份)
因此我重新再采集了一次,并且这次只采集只有有追加评论的订单。如图:
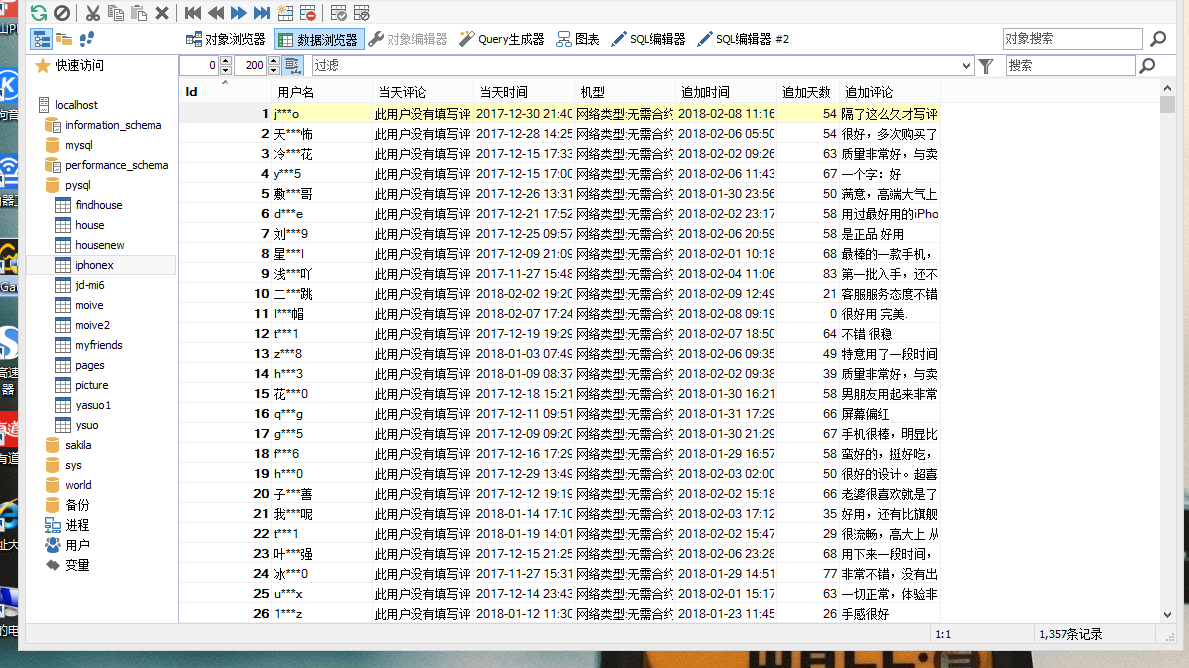
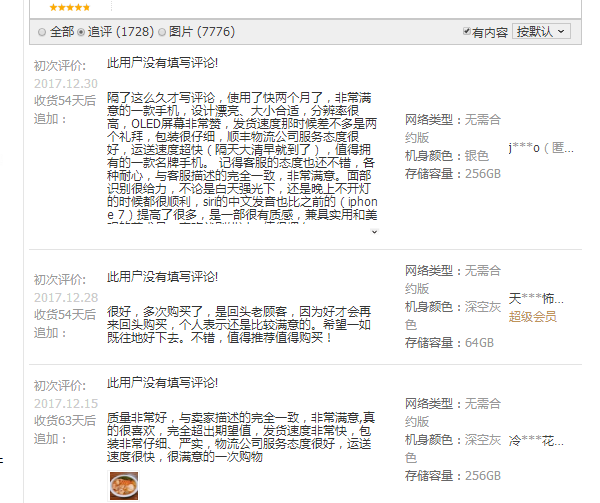
对比一下抓取的数据与网页基本一致。
0. 数据存储
数据库是mysql5.7版本,配置与安装数据库这里就不介绍了,度娘很多教材呢!
1. 数据清洗
好了进入正题,我们开始整理数据。初步观察数据是比较完整的,没有什么缺失值。但是要专业分析sql代码还是需要敲下!如下:
select id from iphonex where 当天评论 is NULL or 追加评论 is NULL;
#选择评论为空的id
update iphonex set 当天评论=replace(当天评论,'此用户没有填写评论!','0');
#消除 ’此用户没有填写评论!’ 的字符值
update iphonex set 当天评论=replace(当天评论,',',',');
update iphonex set 追加评论=replace(追加评论,',',',');
#把英文的逗号改为中文格式,方便以后导出csv格式
update iphonex set 机身颜色=机型;
update iphonex set 存储容量=机型;
update iphonex set 机身颜色=replace(机身颜色,'网络类型:无需合约版;机身颜色:','');
update iphonex set 机身颜色=replace(机身颜色,';存储容量:256GB','');
update iphonex set 机身颜色=replace(机身颜色,';存储容量:64GB','');
update iphonex set 存储容量=replace(存储容量,'网络类型:无需合约版;机身颜色:银色;存储容量:','') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5747
5747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









