






随着人工智能的发展,大型语言模型在各个领域的应用越来越广泛。但是,要使这些模型在特定任务上表现最佳,通常需要进行微调。本文将介绍如何在Windows操作系统上进行本地微调大型模型,也算是对我这段时间的实践进行个总结性记录。
微调速览
数据集:kigner/ruozhiba-llama3或本地ruozhiba_qa.json,601k大小,1500条指令与答复
微调耗时:6分钟
输出模型文件耗时:5分钟
转换成GGUF耗时:1分钟
量化模型文件耗时:1分钟
原始模型文件:unsloth/llama-3-8b-bnb-4bit(unsloth经过4位量化)5.31G的.safetensors文件
输出模型文件:(量化前)
-
model-00001-of-00004.safetensors,4个核心模型文件,加起来14.9G
-
adapter_model.safetensors,160M的lora模型文件
GGUF文件:llama3-gguf-model.gguf,1个14.9G的未量化GGUF模型文件
量化模型文件:llama3-gguf-model-Q4_K_M.gguf,1个4.58G的量化模型文件
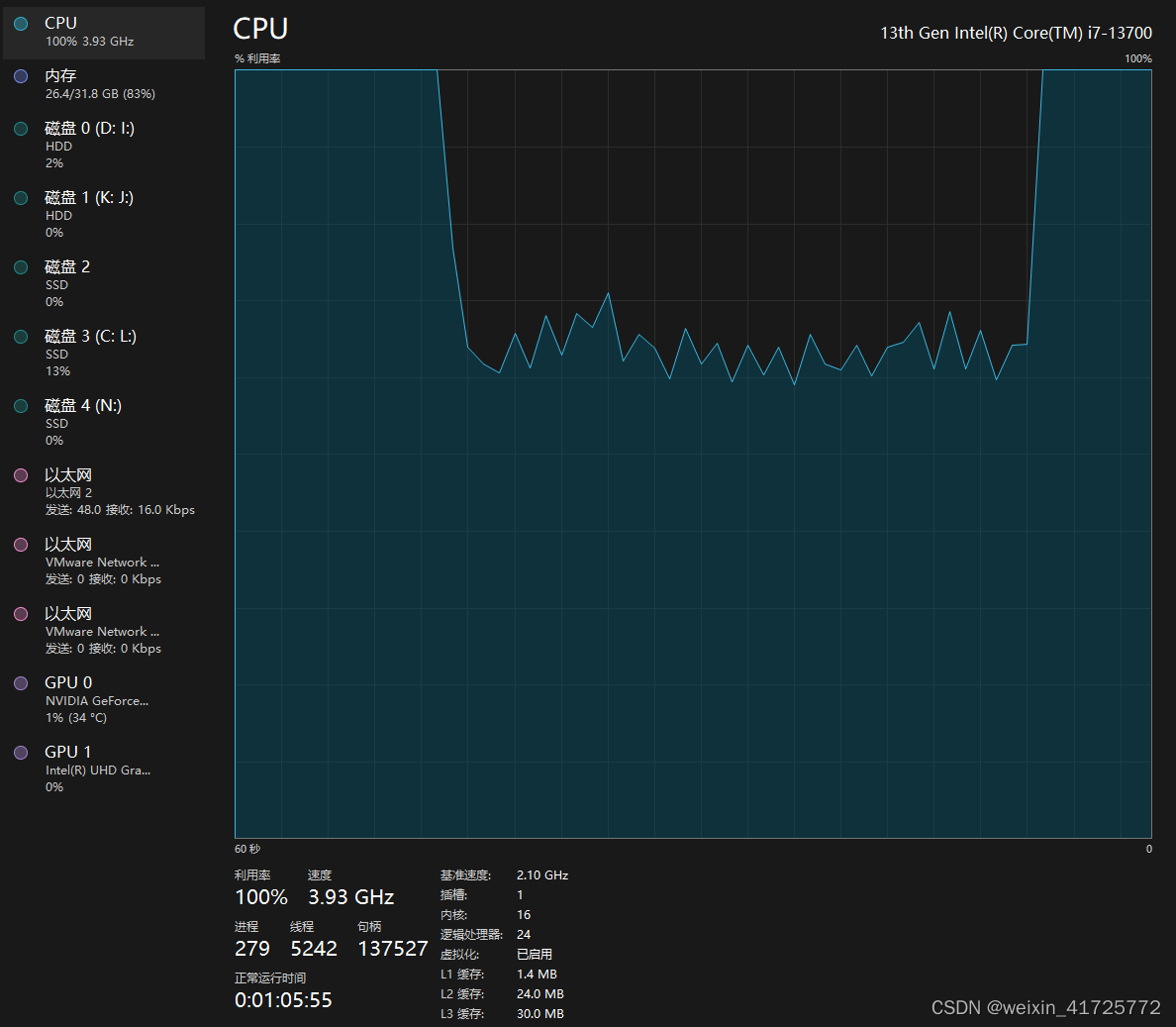
微调基本信息:

训练硬件占用:

微调基本信息 量化硬件占用:
微调实践
本文基于我的多方学习和回忆完成,难免有错漏,有问题的可以评论区留言交流。
步骤 1:准备环境
在进行微调之前,首先确保你的系统满足以下要求:
-
硬件环境:准备显存大于等于8G的显卡,16G内存,C盘20G空间,unsloth安装盘40GB空间。本案例使用GeForce RTX 4090 显存24G,32G内存
-
软件包:本文的软件环境安装会讲得简单些,比如不会讲每一步,包括验证安装之类的,不会的同学请自行上网查找其他教程。
-
操作系统:Windows10/Windows11
-
Annaconda:用于管理环境,安装各种工具https://www.anaconda.com/download/
-
Python3.11.9:用于执行后缀为py的python脚本 https://www.python.org/downloads/windows/
-
Visual Studio 2022 社区版:用于安装C++桌面开发工具 https://visualstudio.microsoft.com/zh-hans/downloads/
-
CUDA12.1支持:包括 GPU 加速库、调试和优化工具、C/C++ 编译器和运行时库https://developer.nvidia.com/cuda-12-1-0-download-archive
-
cuDNN8.9.6:用于深度神经网络的 GPU 加速基元库 https://developer.nvidia.com/rdp/cudnn-archive
-
Git:用于拉取github项目,任何版本 https://git-scm.com/download/win
-
unsloth:开源微调项目,能以更低的硬件需求和更高的效率微调 https://github.com/unslothai/unsloth
-
整合unsloth包:https://pan.baidu.com/s/17XehOXC2LMbnLnVebV79lQ?pwd=rycn有编译好的deepspeed和triton,以及测试、微调脚本(感谢提供者AI百晓生)
-
llama.cpp:用于将safetensors转换为gguf和量化,量化后可以用cpu运行模型https://github.com/ggerganov/llama.cpp
-
LLVM(可选):用于编译triton https://releases.llvm.org/
-
模型:选择好你要微调的大型模型,本案例使用huggingface的unsloth/llama-3-8b-bnb-4bit
-
数据集:用hugging face上的弱智吧数据集kigner/ruozhiba-llama3,或其他可用数据集https://huggingface.co/datasets
步骤 2:安装软件
安装annaconda


用annaconda安装python

conda create -n env_name python=3.119 # 创建一个名为env_name,版本为3.119的python虚拟环境安装Visual Studio 2022 社区版,安装好后重启电脑

安装cuda12.1

系统变量path中添加环境变量


系统变量中添加环境变量(忽略11.7版本的)

安装cnDNN
对下载的cuDNN压缩包解压后出现如下三个文件夹子
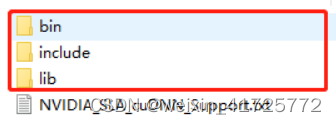
将其复制到cuda安装目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
然后添加环境变量:系统变量-path
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\lib
安装git

安装unsloth
解压unsloth整合包

安装llama.cpp
将llama.cpp克隆到unsloth目录下
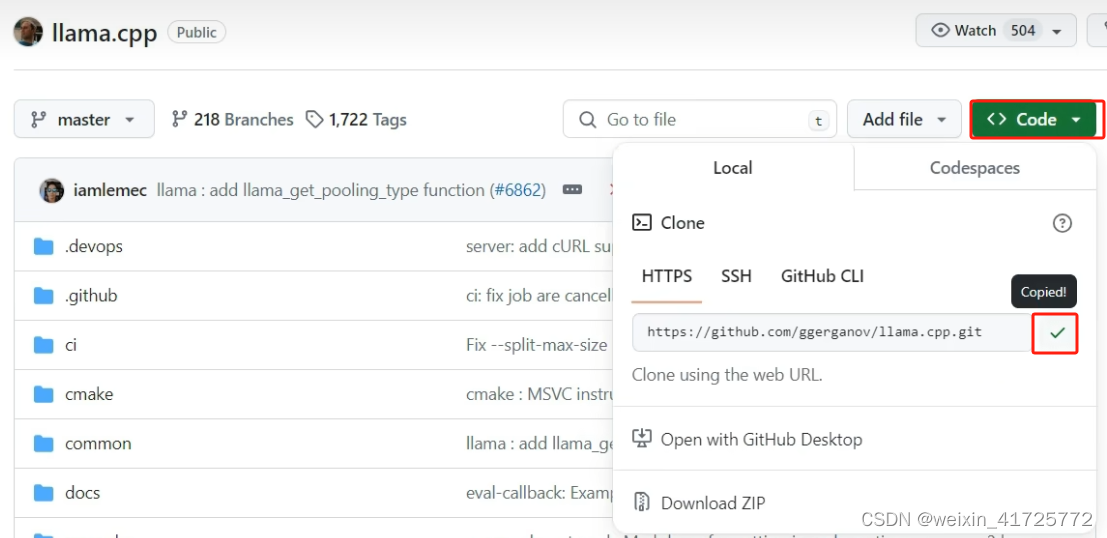
在unsloth目录中打开cmd,输入
git clone https://github.com/ggerganov/llama.cpp.git编译:进入llama.cpp目录,新建文件夹build
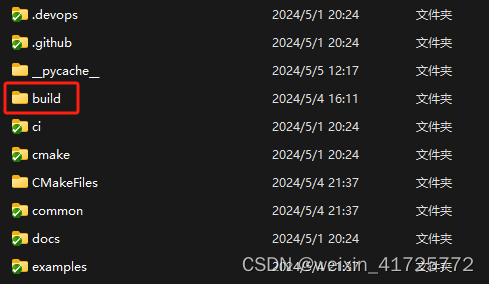
在build目录打开cmd,运行
cmake .. -DLLAMA_CUBLAS=ON添加cmake环境变量:
C:\Program Files\Microsoft Visual Studio\2022\Professional\Common7\IDE\CommonExtensions\Microsoft\CMake\CMake\bin
C:\Program Files\Microsoft Visual Studio\2022\Professional
在build目录下打开cmd,执行以下命令,中途黄字警告可忽略
cmake --build . --config Release编译好以后,把llama.cpp\build\bin\release目录下的所有文件复制到llama.cpp目录下
激活虚拟环境
打开cmd
conda activate env_name安装依赖包
在env_name的虚拟环境中逐个输入以下指令
pip install torch==2.2.2 --index-url https://download.pytorch.org/whl/cu121
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps trl peft accelerate bitsandbytes
pip install deepspeed-0.13.1+unknown-py3-none-any.whl
pip install triton-2.1.0-cp311-cp311-win_amd64.whl
pip install xformers==0.0.25.post1测试安装是否成功
nvcc --version
python -m [xformers.info](http://xformers.info/)
python -m bitsandbytes步骤3:微调
进入unsloth目录,运行微调脚本
python fine-tuning.py #用数据集微调参数:

微调过程:


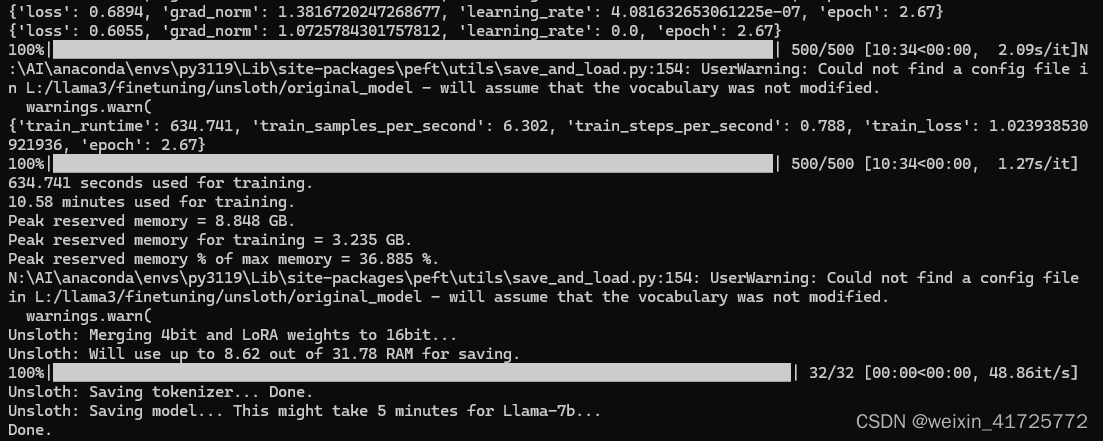
步骤4:转换为gguf
微调完成后模型文件很大,并且配置文件很多,运行起来占用硬件资源多,并且大多数可视化的大语言模型聊天UI工具都没法调用safetensors,只能用gguf,所以要进行格式转换。
微调后生成的模型文件
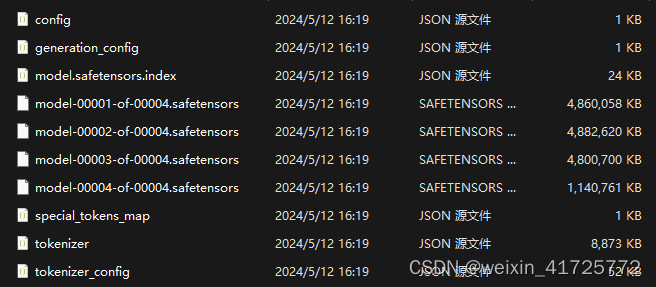
进入llama.cpp目录,cmd中输入以下命令
Python convert-hf-to-gguf.py --outfile 用于存转换模型的目录绝对路径/llama3.gguf output目录的绝对路径转换过程:


步骤5:量化
转换为gguf后虽然把多个文件合成了1个文件,并且能用cpu运行了,但是文件依然很大,加载这个gguf推理模型需要31.5的内存(不是显存),需要进行量化来让文件大小和所需内存等各方面要求都降低,但这会损失一些模型效果,选择Q4_K_M的量化方式,损失效果还能接受。
现在来把刚刚转化获得的gguf文件,量化为Q4_K_M,进入llama.cpp/build/bin/Release/目录,cmd执行
quantize.exe gguf文件的绝对路径/llama3.gguf 量化文件存储目标目录绝对路径/llama3-gguf-model-Q4_K_M.gguf Q4_K_M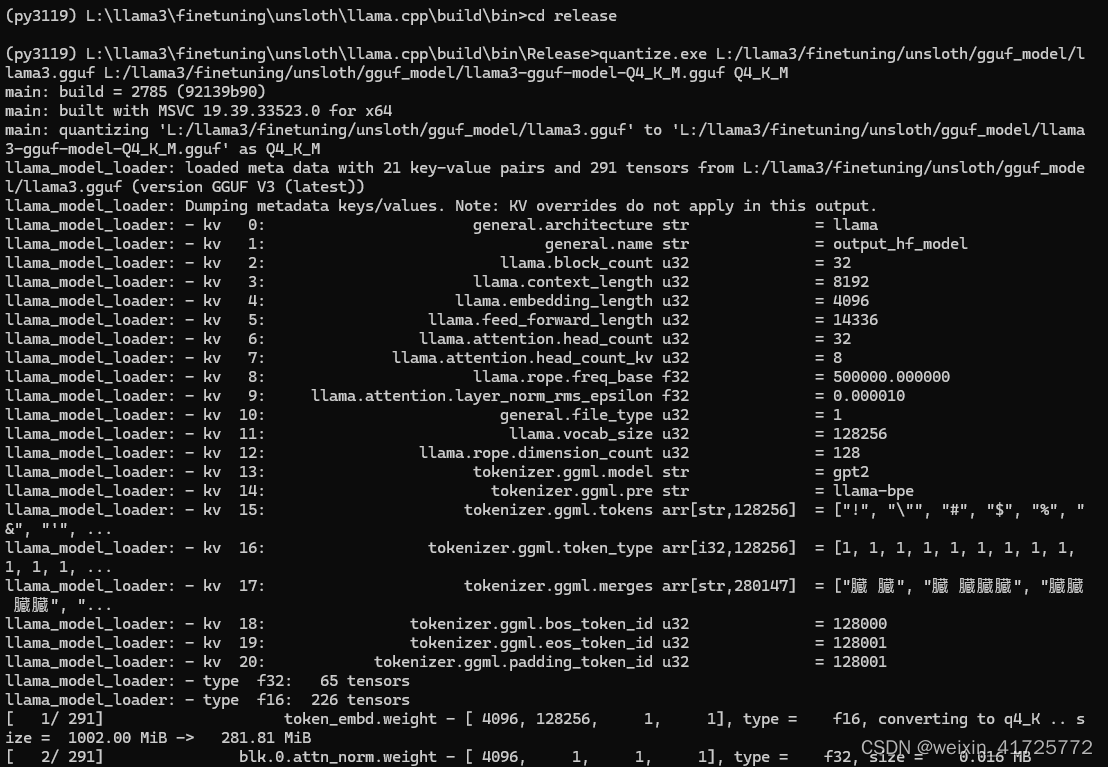

好啦,大功告成,现在你可以用gpt4all、LM studio、Jan等工具来运行模型,进行对话看微调效果啦
疑难杂症
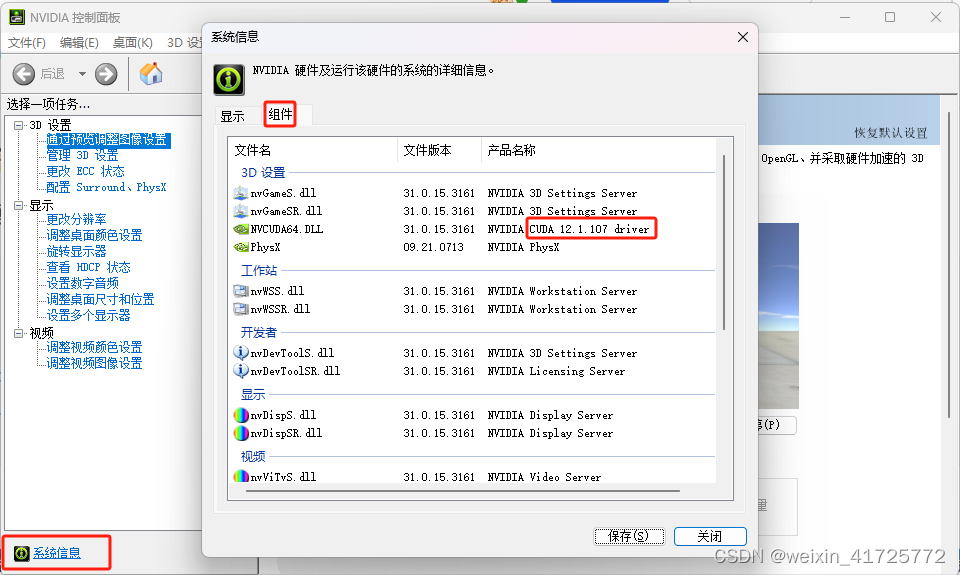
1、如果你发现你安装了cuda12.1但是运行还是报错说cuda版本不正确,那你可能需要卸载显卡驱动,重新安装显卡对应版本的显卡驱动,直到nvidia control panel中显示正确版本
2、如果在微调时报错:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\lib\x64/cuda.lib: error adding symbols: File in wrong format collect2.exe: error: ld returned 1 exit status
请尝试把GCC从环境变量去掉,配置llvm的环境变量
3、安装torch1要与xformers配套,实际安装过程中可能出现自动卸载对方版本的问题,我记得最终是通过安装xformers=0.0.25.post1后再安装torch=2.2.2+cu121来解决的
4、如果你已经安装了各种版本的环境,报各种版本错,建议用conda新建虚拟环境来管理,会解决很多问题
结论
通过本文,你可以了解windows微调大模型的基本步骤,有的地方讲得比较粗浅,本人也还处在学习阶段,有能力专研的同学可以根据自己的需求调整脚本中的参数,尝试用不同的模型、本地数据集、改变学习率、改变训练轮数等来进一步加深理解。
之后可能会继续出调整超参、评估模型质量、降低模型幻觉的文章,希望大家点赞鼓励,一起学习进步。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









