









目录
一、介绍
transformer在视觉上的应用


二.ViT及其改进算法
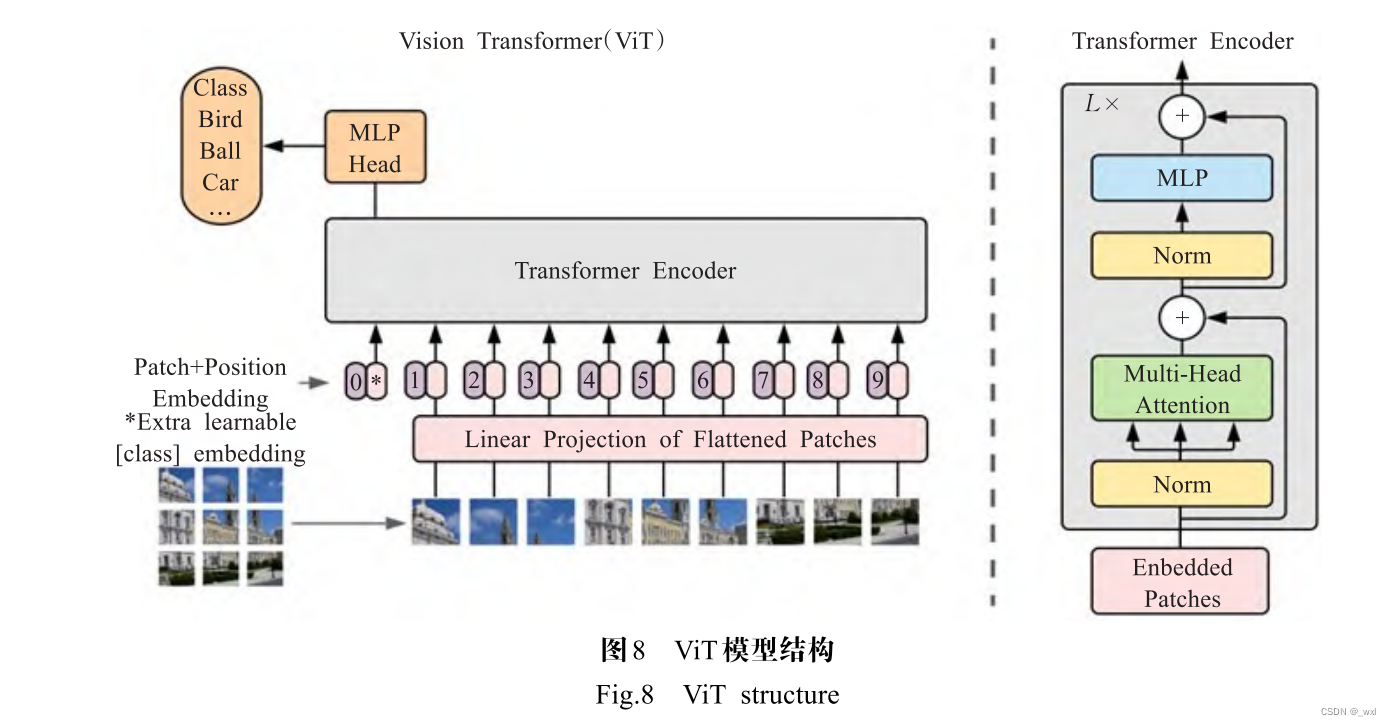
Dosovitskiy等[8]首次将原始的Transformer 模型应用于图像分类任务,提出了ViT(Vision Transformer), 一种完全基于自注意力机制的结构。作者认为在大规 模数据集上,不依赖CNN,Transformer完全可以在分类 任务中表现的很好,ViT的框架如图8所示。 为了将图像转化成Transformer结构可以处理的序列数据,引入了图像块(patch)的概念。首先将二维图像做分块处理,每个图像块展平成一维向量,接着对每 个向量进行线性投影变换,同时引入位置编码,加入序列的位置信息。此外在输入的序列数据之前添加了一个分类标志位(class),更好地表示全局信息。ViT模型 通常在大型数据集上预训练,针对较小的下游任务进行微调。在ImageNet数据集上,VIT-H/14以88.55% Top-1 的准确率超越了EfficientNet模型[47],成功打破了基于卷积主导的网络在分类任务上面的垄断,比传统的CNN 网络更具效率和可扩展性。 ViT是Transformer在大规模数据集上替代标准卷积的第一部作品,为Transformer在计算机视觉任务的 发展奠定了重要的基础。虽然它取得了突破性的进展, 但缺点也十分明显。
(1)ViT将输入图像切块并展平成向量,忽略了图像的特有性质,破坏了其内部固有的结构信息,导致学 习效率不高,难以训练。
(2)ViT所需的计算资源大,在JFT数据集上,ViT-L/16的预训练样本达到100×106 时,准确率才会高于BiT[48] 。因此在有限的计算资源和数据的情况下,ViT难以学到 丰富的特征。 针对ViT的缺陷,Han等[21]提出了TNT(Transformerin Transformer),一种新型的基于结构嵌套的Transformer 架构。通过内外两个Transformer联合,提取图像局部和 全局的特征。具体而言,在每个TNT块中,外Transformer 对图像块之间的关系进行建模,内Transformer对像素 之间的关系进行建模,经过线性变换将像素级特征投影 到图像块所在的空间中并与块信息相加。通过堆叠多 个TNT块,形成TNT模型。通过这种嵌套方式,块特征 可以更好地保持全局空间结构信息,像素特征可以保持 局部信息,显著提高了模型的识别效果。 Yuan等[22]
提出了基于渐进式Token化机制的T2TViT(tokens-to-token ViT),同时建模图像的局部结构信 息与全局相关性。通过递归聚集相邻的对象逐步将图 像结构化为序列组(tokens),继而连接成一个更长的序 列(token)。这种渐进化机制不仅可以对局部信息建 模,还能减少token序列的长度,降低模型的维度,减少 计算量。同时为了增加特征的丰富性,借鉴CNN架构 的设计思想提出了具有深窄结构(deep-narrow)的ViT 骨干,减少了信息冗余,参数量和计算量显著降低。T2TViT是以ViT为骨干网络的一次突破性探索,在标准 ImageNet数据集上达到了80.7%的Top-1精度,超越了 模型大小相似的ResNet50[49],甚至比MobileNet系列[50-51]更加轻量化。 Jiang等[23]提出了一种提高ViT性能的新的训练目标——token labeling,来探索 Transformer 在 ImageNet 分类中的潜力。作者将一张图片分成若干patch,每个 patch转化为token,利用文献[52]中的Re-labeling技术, 得到每个token的软标签(token-label),对图像进行重新 标注,从而将图像分类问题转化为多个token-label识别问题。同时在训练模型时使用了CutMix技术,它能提 高模型的性能和鲁棒性。Token Labeling技术可以改 善不同规模的ViT模型的性能,以具有26×106
可学习参数的视觉 Transformer 为例,可以在 ImageNet 上达到 84.4%的Top-1精度。
三、Vit
我们将图像分割成小块,并提供这些小块的线性嵌入序列作为Transformer的输入。在NLP应用程序中,图像补丁的处理方式与令牌(单词)相同。我们以监督的方式对模型进行图像分类训练。
Transformer模型在准确度上低于同等规模的ResNets。在中等规模的数据集(如ImageNet)上,在没有进行强正则化,进行训练时产生的精度比同等规模的ResNets低几个百分点。
Transformer模型缺乏一些卷积神经网络(CNN)固有的归纳偏差,如平移等变性和局部性,因此在训练数据不足时无法很好地泛化。由于缺乏这些归纳偏差,当Transformer模型在训练数据不足的情况下进行训练时,其泛化能力可能会受到限制。较少的训练数据可能不足以捕捉复杂的图像结构和上下文信息,导致模型在未见过的数据上表现不佳。初始化时的位置嵌入不包含有关补丁的二维位置的任何信息,所有补丁之间的空间关系都需要从头开始学习。MLP层是局部的和平移等变的,而自注意力层是全局的。
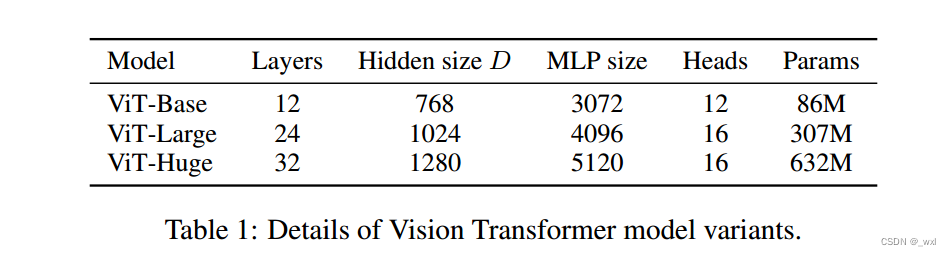
ViT在足够规模的预训练和转移到数据较少的任务时取得了出色的结果。当在公开的ImageNet-21k数据集或内部的JFT-300M数据集上进行预训练时,ViT在多个图像识别基准测试上接近或超过了最先进的结果。特别是,最好的模型在ImageNet上达到了88.55%的准确率,在ImageNet-ReaL上达到了90.72%的准确率,在CIFAR-100上达到了94.55%的准确率,并且在VTAB的19个任务套件上达到了77.63%的准确率。
在微调阶段对ViT进行设置和调整的过程: 在大型数据集上对ViT进行预训练,并在(较小的)下游任务上进行微调。首先,我们移除预训练的预测头部,并连接一个与下游任务类别数量相匹配的新的前馈层。然后,我们在更高的分辨率下进行微调,但保持补丁的大小不变,这导致了更长的有效序列长度。然而,由于分辨率的改变,预训练的位置嵌入可能不再适用。因此,我们通过对预训练位置嵌入进行2D插值来调整它们的位置,以适应新的高分辨率图像。需要注意的是,这种分辨率调整和补丁提取是唯一手动注入关于图像的2D结构的步骤,其他情况下,Vision Transformer对图像的处理是基于学习从头开始的特征表示。
试验比较:
Noisy Student在ImageNet上是最先进的模型,而其他数据集上最先进的是BiT-L模型
BiT-L是Big Transfer(BiT)模型的一个变种,大规模的转移学习模型。它使用大型ResNet在大规模数据集上进行了预训练,采用了监督转移学习的方法。BiT-L在各种计算机视觉任务和基准测试中表现出强大的性能,如图像分类、目标检测和语义分割。它在多个数据集上取得了最先进的结果,并被广泛应用于计算机视觉任务中的迁移学习,作为强大的骨干网络。
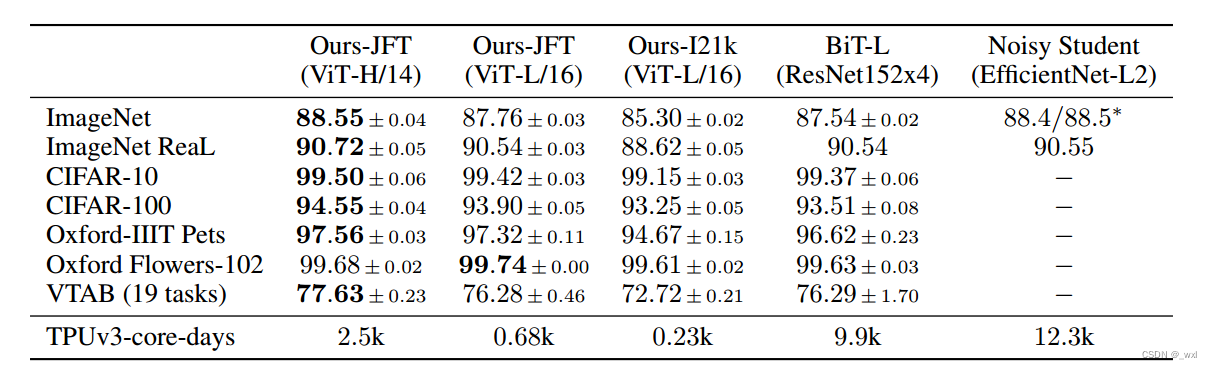
在JFT-300M数据集上预训练的Vision Transformer模型在所有数据集上的表现都优于基于resnet的基线,同时预训练所需的计算资源大大减少。在较小的公共ImageNet-21k数据集上预训练的ViT也表现良好
预训练数据集的选择,比较了ImageNet、ImageNet-21k和JFT300M。,优化了三个基本的正则化参数(为了提高在较小数据集上的性能)——权重衰减、dropout和标签平滑。只有使用JFT-300M,我们才能看到更大型号的全部好处。

为了开始理解Vision Transformer如何处理图像数据,我们分析其内部表示。Vision Transformer的第一层将扁平化的patches线性投影到一个低维空间中(方程式1)。图7(左图)展示了学习到的嵌入滤波器的前几个主要成分。
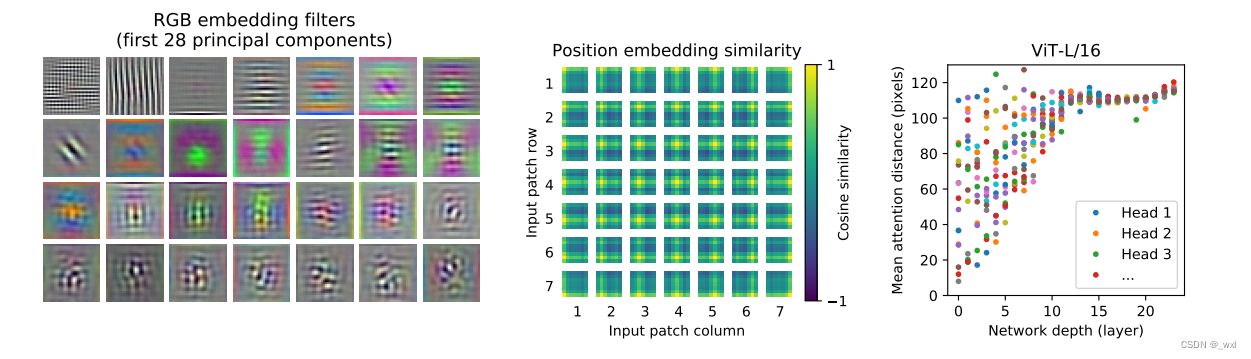
这些成分类似于对每个patche内部细节的低维表示的合理基本函数。投影后,将学习到的位置嵌入添加到patch表示中。图7(中)显示,该模型在位置嵌入的相似性中学习对图像内的距离进行编码,即距离越近的patch往往有更多相似的位置嵌入。
结论:
Vision Transformer在许多图像分类数据集上与或超过了最先进的方法,同时相对较便宜地进行了预训练。与先前在计算机视觉中使用自注意力的工作不同,除了初始的补丁提取步骤外,没有在架构中引入图像特定的归纳偏差。相反,将图像解释为一系列的patch,并通过标准的Transformer编码器(NLP中使用的方式)对其进行处理。这种简单但可扩展的策略,结合对大规模数据集的预训练,表现出惊人的效果。
挑战:
1.将ViT应用于其他计算机视觉任务,如检测和分割
2.继续探索自监督的预训练方法。初步实验显示自监督的预训练有所改善,但是自监督和大规模监督预训练之间仍存在很大差距
3.进一步扩展ViT可能会导致更好的性能表现















 1803
1803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









