







前面我分享了两篇内容:
一文搞懂 Transformer(总体架构 & 三种注意力层)
一文带你搞懂DiT(Diffusion Transformer)
这些都是面试必知的知识点,今天,我来ViT的本质、ViT的原理、ViT的应用三个方面,带您一文搞懂Vision Transformer

Vision Transformer(ViT)
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:《大模型实战宝典》(2024版) 正式发布!
一、ViT的本
ViT的定义:ViT将Transformer架构从自然语言处理领域引入到计算机视觉中,用于处理图像数据。
在计算机视觉领域中,卷积神经网络(CNN)因其强大的局部特征提取能力而长期占据主导地位。然而,近年来,Vision Transformer(ViT)作为一种新兴的模型架构,已经开始在多个视觉任务中展现出与CNN相当甚至更好的性能。

CNN vs ViT
Transformer及其视觉变种Vision Transformer(ViT)发展历程中的关键节点如下,红色标记了与视觉任务相关的模型。

Transformer的发展历程
Transformer的起源:
-
2017年,Google提出了Transformer模型,这是一种基于Seq2Seq结构的语言模型,它首次引入了Self-Attention机制,取代了基于RNN的模型结构。
-
Transformer的架构包括Encoder和Decoder两部分,通过Self-Attention机制实现了对全局信息的建模,从而能够解决RNN中的长距离依赖问题。
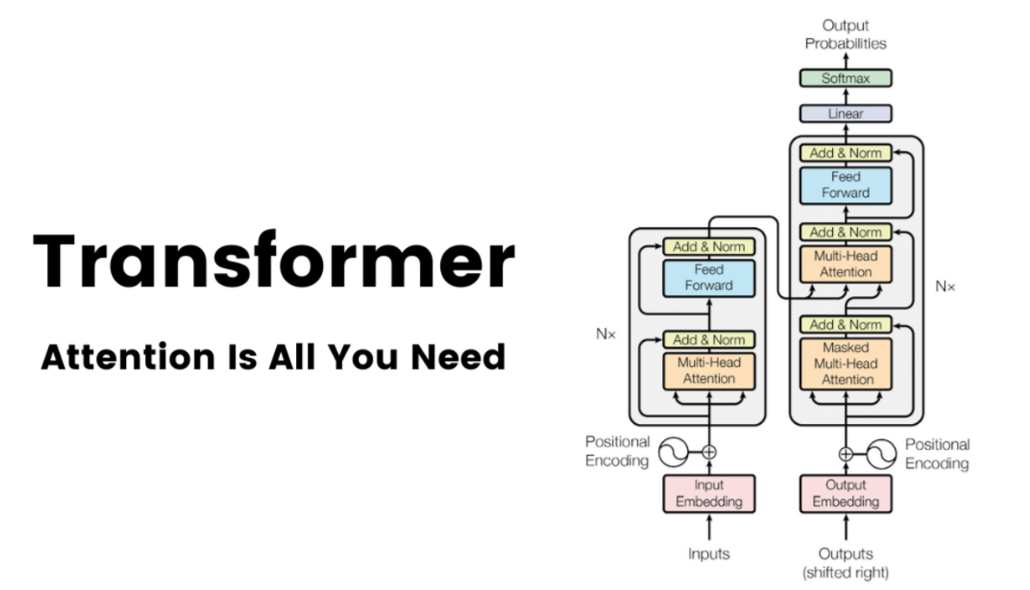
Transformer
ViT的出现:
-
ViT采用了Transformer模型中的自注意力机制来建模图像的特征,这与CNN通过卷积层和池化层来提取图像的局部特征的方式有所不同。
-
ViT模型主体的Block结构基于Transformer的Encoder结构,包含Multi-head Attention结构。
Vision Transformer(ViT)
ViT的进一步发展:
-
随着研究的深入,ViT的架构和训练策略得到了进一步的优化和改进,使其在多个计算机视觉任务中都取得了与CNN相当甚至更好的性能。
-
目前,ViT已经成为计算机视觉领域的一个重要研究方向,并有望在未来进一步替代CNN成为主流方法。

ViT的进一步发展
ViT的本质:将图像视为一系列的“视觉单词”或“令牌”(tokens),而不是连续的像素数组。

Vision Transformer
图像块(Image Patches):
-
ViT首先将输入图像切分为多个固定大小的图像块(patches)。
-
这些图像块被线性嵌入到固定大小的向量中,类似于NLP中的单词嵌入。
-
每个图像块都被视为一个独立的“视觉单词”或“令牌”,并用于后续的Transformer层中进行处理。

图像块(Image Patches)
二、ViT的原理
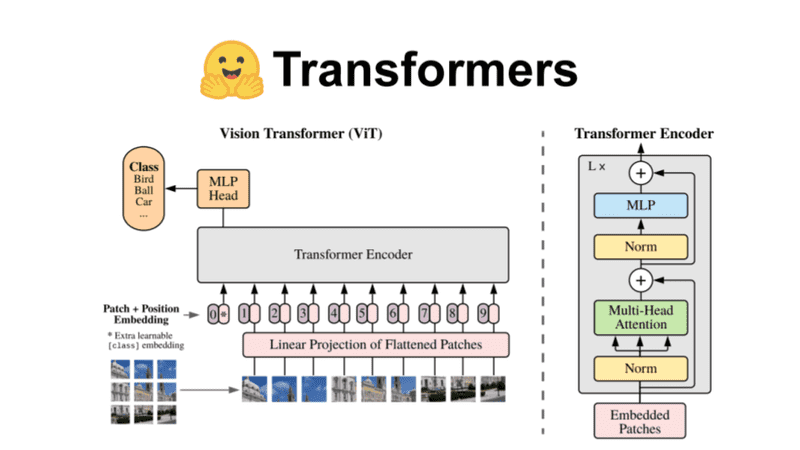
ViT的架构:通过将图像分割成一系列小块(patches)并视为序列化的token输入到Transformer编码器中,从而实现了图像特征的提取和分类。如下图所示:

ViT的架构
ViT的核心组件:Patch Embeddings,Position Embeddings,Classification Token,Linear Projection of Flattened Patches,以及Transformer Encoder。

ViT的核心组件
-
Patch Embeddings:如上图虚线的左半部分,我们将图片分成固定大小的图像块patches(如图左下9×9的图像),将它们线性展开。
-
Position Embeddings:Position embeddings加到图像块中是为了保留位置信息的。
-
Classification Token:为了完成分类任务,除了以上九个图像块,我们还在序列中添加了一个*的块0,叫额外的学习的分类标记Classification Token。
-
Linear Projection of Flattened Patches:图像分割为固定大小的图像块(patches)后,将每个图像块展平(flatten)为一维向量,并通过一个线性变换(即线性投影层或嵌入层)将这些一维向量转换为固定维度的嵌入向量(patch embeddings)。
-
Transformer Encoder:由多个堆叠的层组成,每层包括多头自注意力机制(MSA)和全连接的前馈神经网络(MLP block)。

ViT的Transformer Encoder
ViT的工作流程:将图像分割为固定大小的图像块(patches),将其转换为Patch Embeddings,添加位置编码信息,通过包含多头自注意力和前馈神经网络的Transformer编码器处理这些嵌入,最后利用分类标记进行图像分类等任务。
三、ViT的应用
分割(Segmentation):涵盖了全景分割、实例分割、语义分割和医学图像分割等。

Segmentation四种分类
Vision Transformer在Segmentation的应用:
-
全景分割Transformer:考虑了目标对象与全局图像上下文之间的关系,并通过并行方式直接输出最终的预测集合。这种架构能够同时处理多个对象实例和背景,从而实现全景分割任务的高效完成。
-
实例分割的Transformer:将视频实例分割任务视为一个直接的端到端并行序列解码/预测问题。它通过预测视频中每个实例的掩码序列,实现了高效的实例分割。这种方法的优点在于其能够处理动态变化的视频内容,并实时输出每个实例的分割结果。
-
语义分割Transformer:利用Transformer的自注意力机制来捕获全局上下文信息,从而提高了语义分割的性能。通过考虑图像中的全局信息,它能够更准确地识别不同区域所属的类别,并生成更精细的分割结果。
-
医学图像分割Transformer:通过预测各个对象实例,Transformer提高了数据处理的实验信息产量,使得在线监测实验和闭环最佳实验设计变得可行。这对于医学诊断、治疗和研究都具有重要的意义。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要大模型技术交流、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
想加入星球也可以如下方式:
方式①、微信搜索公众号:机器学习社区,后台回复:星球
方式②、添加微信号:mlc2040,备注:星球
面试精选
相关论文
- 《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









