







首先引入两个概念
Fixation Prediction (FP): 眼动点预测,目的为确定眼动点。一张图中,我们人第一眼注意到的位置即为眼动点。
Salient Object Detection (SOD): 显著性目标检测,目的为突出图像中的显著性目标区域。
一、动机:
在视觉显著性方面的研究中,主要分为两类任务:眼动预测和显著性目标检测。但是两者之间的关系,却很少被研究人员探索。下图中的 (a), (b), (c)均为单任务网络结构,即只实现眼动预测或者显著性目标检测。(d)FP 和 SOD 只是共享浅层权重。

作者想通过利用两者间的关系来实现显著性目标检测,于是提出了 (e) 的网络结构。
二、贡献点:
- 在统一的神经网络中从眼动图(在较高层中编码)推断显著性目标(在较低网络层中获取)。
- 提出了注意力显著性网络ASNet,它convLSTM的层次结构,用于逐步推断目标显著性。
- 在显著性目标检测中引入了新颖的损失函数,这些损失函数均是已存在的SOD评估指标。
三、本文的方法:

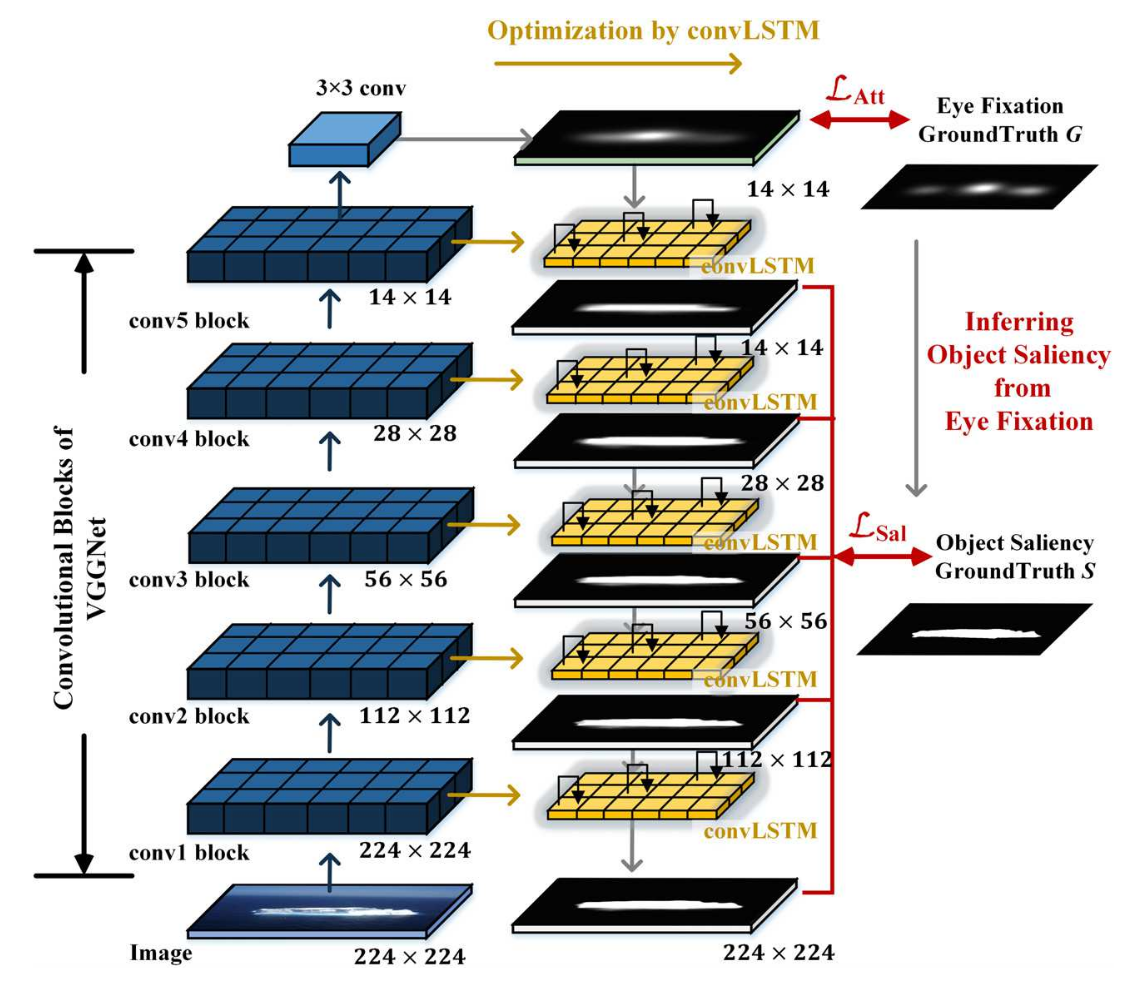
如上图所示:
左图中 a 为网络的输入图片,c 为眼动点的预测图片,b 为通过c获取得到的显著性目标检测图片。
右图为本文提出的 ASNet 网络框架。最上面一层输出为眼动点预测,通过它一级一级的往下调节显著性目标检测结果,每一层都有损失函数。最终的输出为最底层的高质量 224 * 224 * 1 的显著性目标检测图。
细节如下图:
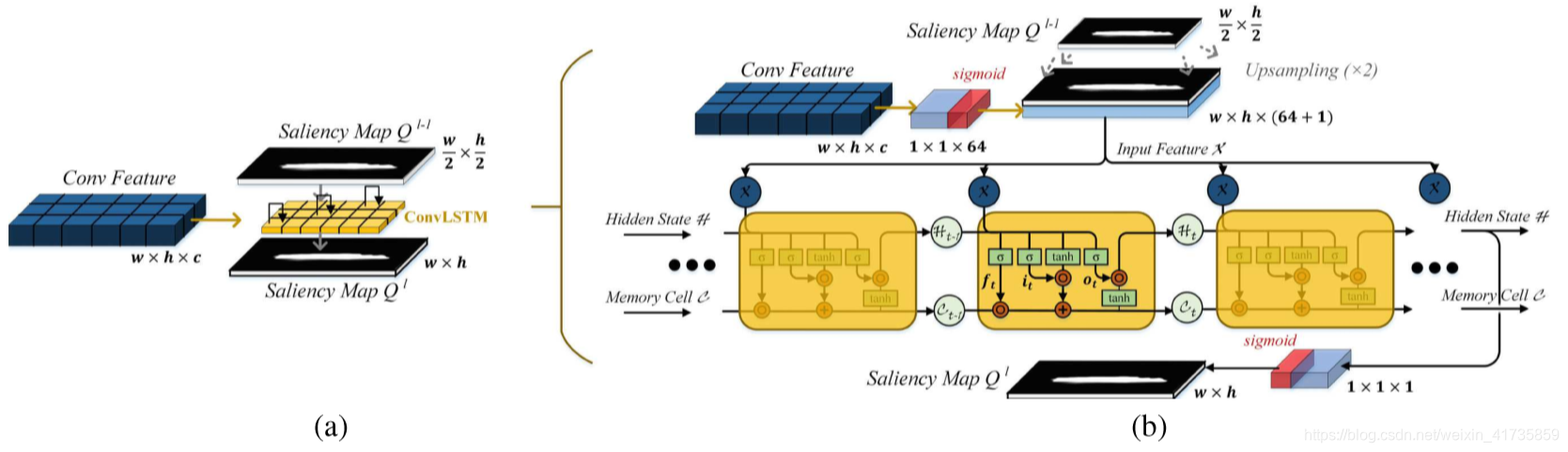
a 为 convsLSTM 的的优化模型,b 为 a 的结构细节展示。本文中利用convLSTM的作用不是作为时间推导,而是作为迭代作用。每一层使用3个 cell 的 convLSTM 进行迭代。同一层的每个 cell 的输入一致,输入 X 为将上一层得到的显著性图经过上采样后的图与这一层的经过降维后得到的卷积特征图进行融合的结果图。对于本文中最早的convLSTM来说,输入 X 为将眼动点预测图经过上采样后的图与这一层的经过降维后得到的卷积特征图进行融合的结果图。
损失函数:
在眼动点预测部分,使用的损失函数为相对熵
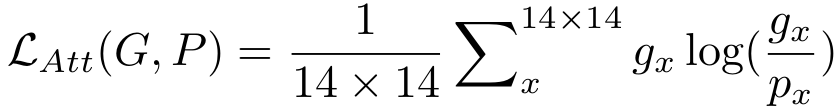
在显著性目标检测部分,使用的损失函数为几种损失函数的组合形式,G 代表resize后的groud-truth注意力图,P 代表眼动预测的输出图,
g
x
g_x
gx∈G,
p
x
p_x
px∈P。
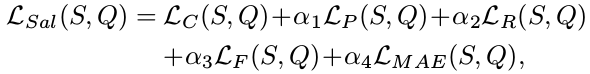
L C L_C LC, L P L_P LP, L R L_R LR, L F L_F LF, L M A E L_{MAE} LMAE, 分别表示权重交叉损失,查准率,查全率,F-measure, and MAE。这里不深究,知道文章结合了这几个损失函数就行。S 表示显著性目标检测的ground-truth,Q 表示通过convLSTM输出的目标显著性图。作者以经验为主导,将 α 1 α_1 α1, α 2 α_2 α2, α 3 α_3 α3, α 4 α_4 α4 都设置为 0.1 。
最终的损失函数为
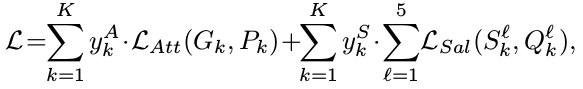
y k A y^A_k ykA 和 y k S y^S_k ykS 分别表示眼动点和显著性目标检测是否有标注,如果有,则为1,没有则为0。由于同时具备眼动点标注和显著性目标检测标注的数据集很少,所以在实验训练过程中结合了只有眼动点标注,只有显著性目标检测标注和同时包含两种标注的数据集。最终的损失函数这样表示,能够防止在训练过程中出现没有标注的错误提示。
四、实现结果:
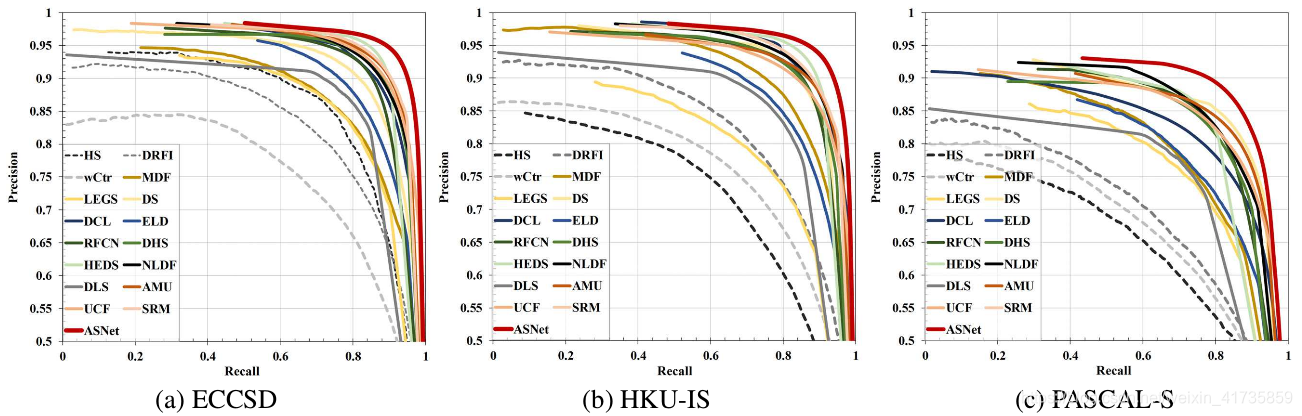
在三种数据集上显示显著性目标检测的PR-曲线图如下图所示:
可以看到所有的曲线图中,使用ASNet的曲线均在最外侧,也即是效果最好。
由于博主资历浅薄,若有解读错误之处,望指出!

















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









