









Feature Selection 特征选择
数据预处理后,我们生成了大量的新变量(比如独热编码生成了大量仅包含0或1的变量)。但实际上,部分新生成的变量可能是多余:一方面它们本身不一定包含有用的信息,故无法提高模型性能;另一方面过这些多余变量在构建模型时会消耗大量内存和计算能力。因此,我们应该进行特征选择并选择特征子集进行建模。
特征过滤
过滤法通过使用一些统计量或假设检验结果为每个变量打分。得分较高的功能往往更加重要,因此应被包含在子集中。以下为一个简单的基于过滤法的机器学习工作流(以最简单的训练-验证-测试这种数据集划分方法为例)。

Variance Threshold 方差选择法
方差选择法删除变量方差低于某个阈值的所有特征。例如,我们应删除方差为零的特征(所有观测点中具有相同值的特征),因为该特征无法解释目标变量的任何变化。
import numpy as np
import pandas as pd
from sklearn.feature_selection import VarianceThreshold
# 合成一些数据集用于演示
train_set = np.array([[1,2,3],[1,4,7],[1,4,9]]) # 可见第一个变量方差为0
# array([[1, 2, 3],
# [1, 4, 7],
# [1, 4, 9]])
test_set = np.array([[3,2,3],[1,2,7]]) # 故意将第二个变量方差设为0
# array([[3, 2, 3],
# [1, 2, 7]])
selector = VarianceThreshold()
selector.fit(train_set) # 在训练集上训练
transformed_train = selector.transform(train_set) # 转换训练集
# 下面为返回结果,可见第一个变量已被删除
# array([[2, 3],
# [4, 7],
# [4, 9]])
transformed_test = selector.transform(test_set) # 转换测试集
# 下面为返回结果,可见第一个变量已被删除
# array([[2, 3],
# [2, 7]])
# 虽然测试集中第二个变量的方差也为0
# 但是我们的选择是基于训练集,所以我们依然删除第一个变量
Pearson Correlation 皮尔森相关系数
皮尔森相关系数一般用于衡量两个连续变量之间的线性相关性,也可以用于衡量二元变量与目标变量的相关性。故可以将类别变量利用独热编码转换为多个二元变量之后利用皮尔森相关系数进行筛选。公式:
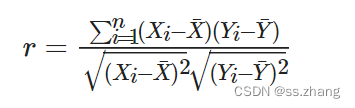
对dataframe数据进行相关性分析

热力图
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(dpi=100, figsize=(15, 8))
sns.heatmap(data=f_df.corr())

Mutual Information互信息
互信息(Mutual Information)衡量变量间的相互依赖性。其本质为熵差,即,即知道另一个变量信息后混乱的降低程度(类似于信息增益)。当且仅当两个随机变量独立时MI等于零。MI值越高,两变量之间的相关性则越强。与Pearson相关和F统计量相比,它还捕获了非线性关系。
公式:
若两个变量均为离散变量:
I
(
x
,
y
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
=
∑
x
∈
X
∑
x
∈
Y
p
(
X
,
Y
)
(
x
,
y
)
log
(
p
(
X
,
Y
)
(
x
,
y
)
p
X
(
x
)
p
Y
(
y
)
)
I(x, y)=H(Y)-H(Y \mid X)=\sum_{x \in X} \sum_{x \in Y} p_{(X, Y)}(x, y) \log \left(\frac{p(X, Y)(x, y)}{p_{X(x) p Y(y)}}\right)
I(x,y)=H(Y)−H(Y∣X)=x∈X∑x∈Y∑p(X,Y)(x,y)log(pX(x)pY(y)p(X,Y)(x,y))
若两个变量均为连续变量:
I ( X , Y ) = H ( Y ) − H ( Y ∣ X ) = ∫ X ∫ Y p ( X , Y ) ( x , y ) log ( p ( X , Y ) ( x , y ) p X ( x ) p Y ( y ) ) d x d y I(X, Y)=H(Y)-H(Y \mid X)=\int_{X} \int_{Y} p_{(X, Y)}(x, y) \log \left(\frac{p(X, Y)(x, y)}{p_{X(x) p Y(y)}}\right) d x d y I(X,Y)=H(Y)−H(Y∣X)=∫X∫Yp(X,Y)(x,y)log(pX(x)pY(y)p(X,Y)(x,y))dxdy
连续变量情形下,在实际操作中,往往先对数据离散化分桶,然后逐个桶进行计算。
但是实际上,一种极有可能的情况是,x和y中的一个可能是离散变量,而另一个是连续变量。因此在sklearn中,它基于[1]和[2]中提出的基于k最临近算法的熵估计非参数方法。
[1] A. Kraskov, H. Stogbauer and P. Grassberger, “Estimating mutual information”. Phys. Rev. E 69, 2004.
[2] B. C. Ross “Mutual Information between Discrete and Continuous Data Sets”. PLoS ONE 9(2), 2014.
import numpy as np
from sklearn.feature_selection import mutual_info_regression
from sklearn.feature_selection import SelectKBest
# 直接载入数据集
from sklearn.datasets import fetch_california_housing
dataset = fetch_california_housing()
X, y = dataset.data, dataset.target # 利用 california_housing 数据集来演示
# 此数据集中,X,y均为连续变量,故此满足使用MI的条件
# 选择前15000个观测点作为训练集
# 剩下的作为测试集
train_set = X[0:15000,:].astype(float)
test_set = X[15000:,].astype(float)
train_y = y[0:15000].astype(float)
# KNN中的临近数是一个非常重要的参数
# 故我们重写了一个新的MI计算函数更好的来控制这一参数
def udf_MI(X, y):
result = mutual_info_regression(X, y, n_neighbors = 5) # 用户可以输入想要的临近数
return result
# SelectKBest 将会基于一个判别函数自动选择得分高的变量
# 这里的判别函数为F统计量
selector = SelectKBest(udf_MI, k=2) # k => 我们想要选择的变量数
selector.fit(train_set, train_y) # 在训练集上训练
transformed_train = selector.transform(train_set) # 转换训练集
transformed_train.shape #(15000, 2), 其选择了第一个及第八个变量
assert np.array_equal(transformed_train, train_set[:,[0,7]])
transformed_test = selector.transform(test_set) # 转换测试集
assert np.array_equal(transformed_test, test_set[:,[0,7]]);
# 可见对于测试集,其依然选择了第一个及第八个变量
# 验算上述结果
for idx in range(train_set.shape[1]):
score = mutual_info_regression(train_set[:,idx].reshape(-1,1), train_y, n_neighbors = 5)
print(f"第{idx + 1}个变量与因变量的互信息为{round(score[0],2)}")
# 故应选择第一个及第八个变量
第1个变量与因变量的互信息为0.38
第2个变量与因变量的互信息为0.03
第3个变量与因变量的互信息为0.1
第4个变量与因变量的互信息为0.03
第5个变量与因变量的互信息为0.02
第6个变量与因变量的互信息为0.09
第7个变量与因变量的互信息为0.37
第8个变量与因变量的互信息为0.46
Chi-squared Statistics卡方统计量
卡方统计量主要用于衡量两个类别特征之间的相关性。sklearn提供了chi2函数用于计算卡方统计量。其输入的特征变量必须为布尔值或频率(故对于类别变量应考虑独热编码)。卡方统计量的零假设为两个变量是独立的,因为卡方统计量值越高,则两个类别变量的相关性越强。因此,我们应该选择具有较高卡方统计量的特征。
公式:
χ
2
=
∑
i
=
1
r
∑
j
=
1
c
(
O
i
,
j
−
E
i
,
j
)
2
E
i
,
j
=
n
∑
i
,
j
p
i
p
j
(
Q
i
j
n
−
p
i
p
j
p
i
p
j
)
2
\chi^{2}=\sum_{i=1}^{r} \sum_{j=1}^{c} \frac{\left(O_{i, j-} E_{i, j}\right)^{2}}{E_{i, j}}=n \sum_{i, j} p_{i} p_{j}\left(\frac{\frac{Q_{i j}}{n}-p_{i} p_{j}}{p_{i} p_{j}}\right)^{2}
χ2=i=1∑rj=1∑cEi,j(Oi,j−Ei,j)2=ni,j∑pipj(pipjnQij−pipj)2
其中,
O
i
,
j
O_{i, j}
Oi,j 为在变量X上具有i-th类别值且在变量
Y
Y
Y 上具有j-th类别值的实际观测点计数。
E
i
,
j
E_{i, j}
Ei,j 为利用概率估计的应在在变量X上具有
j
\mathrm{j}
j-th类别值且在变量
Y
\mathrm{Y}
Y 上具有i-th类别值的观 测点数量。
n
\mathrm{n}
n 为总观测数,
p
i
p_{i}
pi 为在变量
X
\mathrm{X}
X 上具有
i
−
t
h
\mathrm{i}-\mathrm{th}
i−th 类别值的概率,
p
j
p_{j}
pj 为在变量
Y
\mathrm{Y}
Y 上具有
j
−
\mathrm{j}-
j− th类别值的概率。
#案例
# 首先,随机生成一个数据集
import pandas as pd
sample_dict = {'Type': ['J','J','J',
'B','B','B',
'C','C','C','C','C'],
'Output': [0, 1, 0,
2, 0, 1,
0, 0, 1, 2, 2,]}
sample_raw = pd.DataFrame(sample_dict)
#原始数据,Output是我们的目标变量,Type为类别变量
# 下面利用独热编码生成布尔变量,并利用sklearn计算每一个布尔变量的chi2值
sample = pd.get_dummies(sample_raw)
from sklearn.feature_selection import chi2
chi2(sample.values[:,[1,2,3]],sample.values[:,[0]])
(array([0.17777778, 0.42666667, 1.15555556]),
array([0.91494723, 0.8078868 , 0.56114397]))
可以看出计算出来两列值为,这是X单个特征变量对目标变量y的卡方值,两列相加,这个才是真正意义上的卡方检验的卡方值,那么对应的P值同样也不是统计意义上的P值
所以在sklearn.feature_selection.SelectKBest中基于卡方chi2,提取出来的比较好的特征变量,可以理解为在所有特征变量里面相对更好的特征,并不是统计里面分类变量与目标变量通过卡方检验得出的是否相关的结果,















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









