







 AutoGluon是亚马逊推出的自动机器学习工具,尤其适合初学者。它简化了模型训练和预测过程,只需几行代码即可完成。相比微软的NNI,AutoGluon具有更高的封装程度,减少了选择模型、定义搜索空间和配置实验的复杂性。通过选择任务类型,如表格任务、多模态任务和时序任务,AutoGluon会自动处理数据预处理、特征工程、模型训练和集成。这是一个让初学者也能轻松上手的高效工具。
AutoGluon是亚马逊推出的自动机器学习工具,尤其适合初学者。它简化了模型训练和预测过程,只需几行代码即可完成。相比微软的NNI,AutoGluon具有更高的封装程度,减少了选择模型、定义搜索空间和配置实验的复杂性。通过选择任务类型,如表格任务、多模态任务和时序任务,AutoGluon会自动处理数据预处理、特征工程、模型训练和集成。这是一个让初学者也能轻松上手的高效工具。
如果一个机器学习初学者,仅用三行代码就训练了一个模型,并且模型的性能要比从业数十年的都要好,这是一种什么样的感觉?
AutoGluon就能帮你梦想成真。
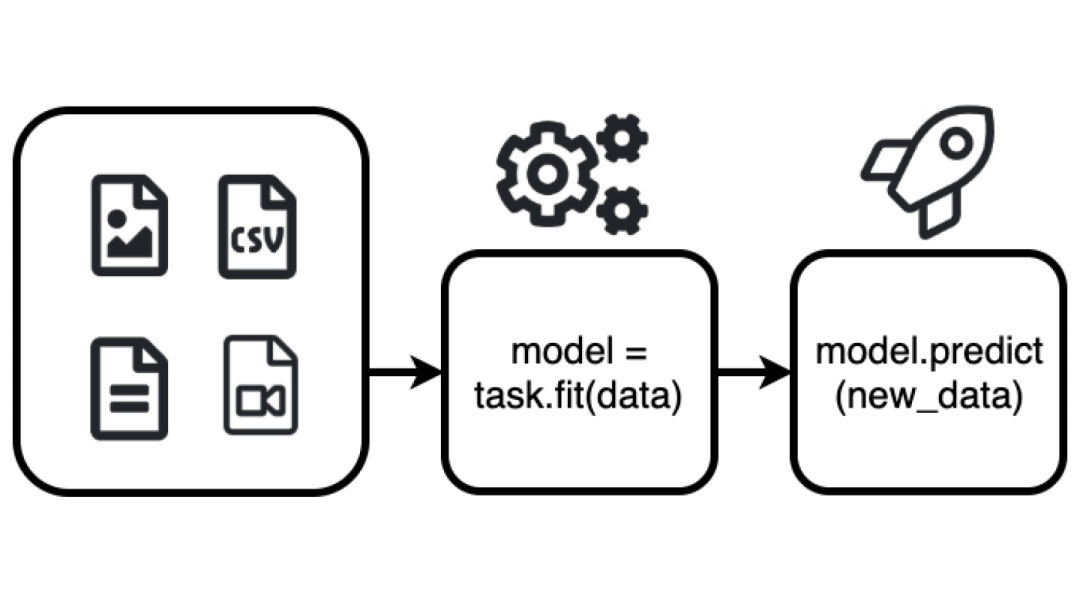
上面这张图片就是AutoGluon的工作流,多么简单啊!根据数据类型(问题定义)实例化任务,仅通过一个fit函数就完成了训练过程,仅通过一个predict函数就完成了对新数据的预测过程。
那么,模型,损失函数,优化器,超参数的选择哪去了?
所有这一切AutoGluon都帮你做了。
AutoML(一):概述
AutoML(二):微软NNI框架
AutoML(三):利用贝叶斯优化进行超参数搜索
https://nni.readthedocs.io/en/stable/index.html
我之前介绍过微软的NNI,同样是AutoML工具,为什么还要介绍AutoGluon呢?
因为NNI不够亲民。
来看一下NNI是如何进行超参数搜索的?
Step1:准备模型
Step2:定义搜索空间
Step3:配置实验
配置实验代码
配置搜索空间
配置微调算法
配置实验次数
Step4:开始实验
实验可以理解为一个超参数搜索过程,为什么说它不够亲民呢?
第一步你需要自己选择模型,可我是个初学者,我咋知道选择什么模型?我甚至连模型是啥都不知道,就算有点经验的人,在是选择传统的机器学习还是神经网络方面也会犯糊涂,毕竟,就连吴恩达老师在这个问题上都承认犯过错误。
可见,选择多了也不是什么好事。
可这还没完,接下来你仍然要面临选择,例如,传统机器学习中能完成分类任务的也不止一个,有基于树的分类器:决策树,提升树,贝叶斯分类器,逻辑回归,SVM等等。
神经网络中也有卷积神经网络CNN,前馈神经网络类ANN以及循环神经网络RNN,仍然要面临类似的选择问题,例如,对于NLP任务,大家首先想到的是RNN,但你可知道CNN也能完成同样的任务。
第二步你需要自己定义搜索空间,空间定义大了,搜索过程会慢,定义小了会错过最优解,甚至连划分粒度都得小心翼翼。
第三步中你需要自己定义搜索算法,是选择基于贝叶斯优化的搜索算法还是强化学习的搜索算法?虽然是个选择题,可是选择哪个鬼真是一点思路都没有啊!
。。。
之前对NNI的一顿吹真是啪啪打自己的脸?
总结来说,不是NNI不好,而是NNI需要有一定的经验和基础。
封装程度
NNI的问题在AutoGluon中三行代码就搞定了。
可见,AutoGluon的封装程度很高。什么是封装程度呢?
举个例子,要使用GPU的并行计算能力。
你是个软件工程师,不想触碰硬件,显卡驱动代替你与硬件交流,你就不用读硬件手册,不用了解寄存器或者总线地址什么的了。
可你仍然不想内核编程,所以CUDA出现了,CUDA代替你与驱动交流,你就不用去了解系统调用等复杂的API了。
可是面对浩如烟海的CUDA API仍然令人头疼,所以机器学习框架代替你与CUDA交流,你只需要一句话device=“gpu”就用上并行计算了。
但封装程度越高,也就意味着可控程度越低。
如何使用AutoGluon?
官方网址:
https://auto.gluon.ai
源码:
https://github.com/autogluon/autogluon
使用AutoGluon,你的工作重心就一个:选择任务类型。
每一个任务类型都有两个重要的角色:DataSet和Predictor。前者用于处理数据,后者用于拟合模型。
在AutoGluon中有三种任务类型。表格任务,多模态任务,以及时序任务。
表格任务
机器学习界的hello world想必你肯定知道吧,加利福尼亚房价预测,也就是输入房屋的面积,房间数,是否邻街道等等特征,输出预测的房价。

我们通常把这种类型的数据称为表格数据。
能处理表格数据的任务就是表格任务。对应的DataSet和Predictor为TabularDataset和TabularPredictor。
来看一个具体的例子:
使用TabularDataset加载数据,可以加载网络数据也可以加载本地数据。
重要的是,你不需要进行数据预处理操作,AutoGluon会帮你数据清理,归一化,异常值处理等操作。
data_url = 'https://raw.githubusercontent.com/mli/ag-docs/main/knot_theory/'
train_data = TabularDataset(f'{
data_url}train.csv')
train_data.head()
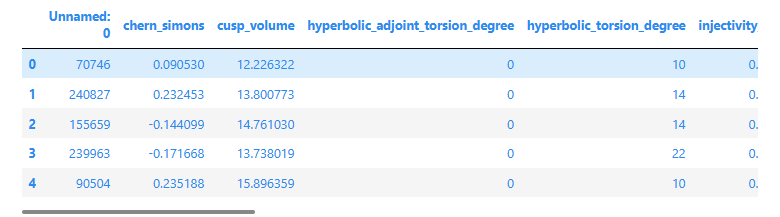
除此之外,还可以输出数据的统计信息。
label = 'signature'
train_data[label].describe()
count 10000.000000
mean -0.022000
std 3.025166
min -12.000000
25% -2.000000
50% 0.000000
75% 2.000000
max 12.000000
Name: signature, dtype: float64
label = 'signature’指定输出列,这很重要,因为后续要根据这个选择模型,之后就可以模型训练了。
predictor = TabularPredictor(label=label).fit(train_data)
虽然一行代码就搞定了。但通过日志可知它背着我们做了很多事。
No path specified. Models will be saved in: "AutogluonModels/ag-20230913_185705/"
Beginning AutoGluon training ...
AutoGluon will save models to "AutogluonModels/ag-20230913_185705/"
AutoGluon Version: 0.8.2b20230913
Python Version: 3.10.8
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Tue Nov 30 00:17:50 UTC 2021
Disk Space Avail: 226.64 GB / 274.87 GB (82.5%)
Train Data Rows: 10000
Train Data Columns: 18
Label Column: signature
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









