







《基于百科类语料的语义关系获取研究》___江苏科技大学
今天看了一篇江苏科技大学的一篇硕士论文,记录一下~
相比于基于规则的方法,基于统计的方法虽然可以摆脱对语言学知识的依赖,具有更好的通用性和灵活性,但是如果想要达到很好地效果,仍然需要大量高质量的人工设计特征。然而如果使用基于深度学习的方法需要大量人为设计的特征的问题,但是精度方面仍然有一定的提升空间,经过研究发现目前基于深度学习的 方法和语言学知识的结合比较少,以此来提升基于深度学习的命名实体识别效果的研究还是比较少的。
实体关系抽取:
+ 基于统计学习的关系抽取模型首先需要设计大量的人工标注的语料库,然后从语料库中进行特征的抽取和选择,在使用不同的机器学习算法的基础上训练分类模型,并不断地自动地识别提取出其中新的实体对和实体对之间的关系。基于统计学习的关系抽取模型的方法有最大熵和随机场、支持向量机。
+ 深度学习作为一种特殊的机器学习方法,具有机器学习方法的诸多优点,然而深度学习方法可以自动学习句子特征上并且不需要复杂的特征工程。与之前的关系抽取方法相比,深度学习具有特殊的优势:
(1)深度学习方法使用统一的连续、低维、实数词向量,表示不同粒度的语言单元,如短语、句子、文本片段 等。
(2)深度学习方法使用递归、卷积、循环等神经网络模型对不同的特征单元进行组合,可以获得更大的语言单元的向量表示。
大量的实验表明,对关系抽取任务而言,多种词向量组合的效果比使用单一的word2vec词向量的效果更好。有的人提出使用词向量、词性标注、句法分析等方法对实体之间依存路径信息进行学习,这些方法都是在LSTM进行关系抽取,然而LSTM无法对局部特征以及全局特征充分利用,加上词向量、词性标注、句法分析十分依赖解析工具(jieba分词、hanlp),虽然啊,句法分析这一类属于比较高级的特征,但是会造成结果十分依赖于解析器的准确性,导致错误的叠加。
注意力机制,通过计算概率分布,突出关键输入信息对模型输出的影响以优化模型。注意力机制可以充分利用句子的局部特征以及全局特征,通过赋予重要特征更高的权重,减少噪声,提高关系抽取的准确性。
作者的创新点:
(1)基于深度学习的命名实体识别模型中融入语义学知识,尝试在深度学习网络中假若句法信息,改进命名实体识别模型并取得了还不错的精度提升。
(2)对语义关系获取问题增加词级的注意力机制,具有一定的特殊性,所以在本文中尝试在输入层使用字向量并增加字的位置特征向量形成字的融合特征向量,对于关键句字句赋予重要权重,增强句子的局部特征和全局特征。
一、关键技术研究
-
文本预处理
文本预处理是对文本进行加工处理,删掉文本中的无用信息,只保留能体现文本主题意义的部分的过程。预处理主要包含:文本分词、去停用词。
-
词向量
如何让计算机识别我们的文字,将文字转换为数字表示。
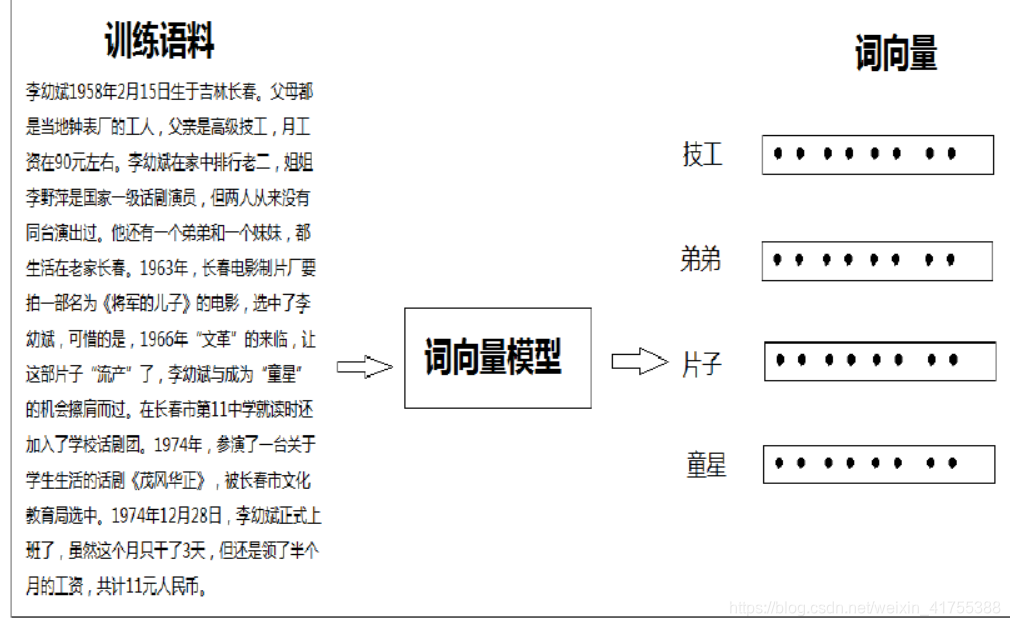
-
注意力机制
二、基于百科类语料的实体识别方法研究
在命名实体识别中,目前大部分的技术是以数据为驱动的,通过大量的标注数据进行有监督学习来获取数据中的信息,通常没有太多的语言学知识。将句法分析加入命名实体识别的模型中,提升精度。
1、数据源的选择
由于网络文本的庞大和各类数据的混杂,要从整个互联网文本中进行信息抽取是非常困难的。作者本文选取了中文网络百科全书进行信息获取,主要选取互动百科 、百度百科作为主要数据来源。
(1)句法分析
句法分析是对句子中的各个词语语法功能进行自动分析。例如:“董璇是演员”,其中“董璇”是主语,“是”是谓语,“演员”是宾语。
句法分析是语法分析思想的一种具体实现,通过识别出高层次的语义结构单元,并对单元进行解释来简化句子的描述。一般句法分析可分为成分句法分析和依存句法分析两种。
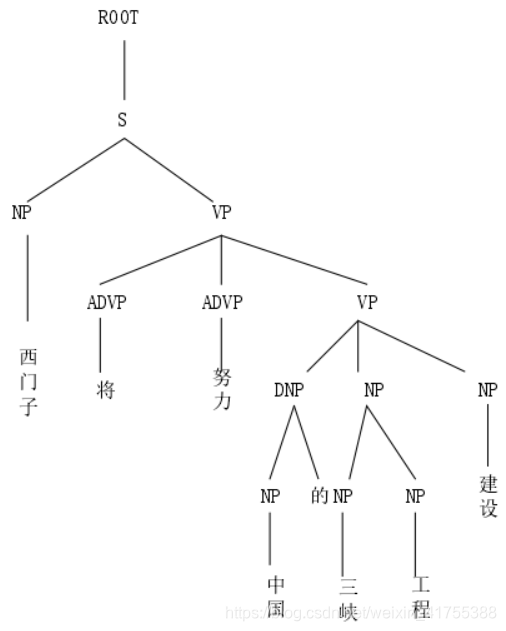
成分句法分析:将句子划为独立短语形式的一种方法。例如句子“西门子将努力参与中国的三峡工程建设”的句法分析树,NP表示“西门子”和“中国的三峡工程建设”是一个名词短语,VP表示“将”、“努力”和"参与"组成了一个动词短语。此外,成分分析数中叶子节点是一个词语,每个词语的父节点标签是这个单词的词性。通过这种成分句法分析树,能够了解到句子中各种短语的信息。根据语法规则,若干个叶节点构成一个短语。
依存句法分析:通过分析识别句子中的“主谓宾”,“定状补”等语法形式来表示句子中词与词之间的相互依赖关系。“西门子将努力参与中国的三峡工程建设”的依存句法分析树,图中,“西门子”是“参与”的名词主语,“建设”是“参与”的直接宾语。通过句法依存句法分析,可以充分句子中词与词之间的依赖关系。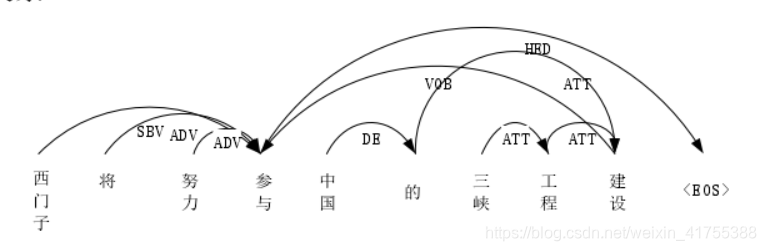
总结:
成分句法分析的目的是为了显示句子中的连续单词组成的短语的信息,而依存句法分析的目的是表示句子中不连续的两个词之间的关系。
2、基于句法分析与深度学习的实体识别模型
- 词向量表示方法:对语料库中的文本信息进行句法分析,得到文本的句法分析之后,将这些结果转换为词向量,得到句子的融合句法分析的词向量表示,这是多个特征向量结合在一起的结果。这几个特征向量包括:词向量、词语的句法分析特征;
- 模型:GRU+CRF
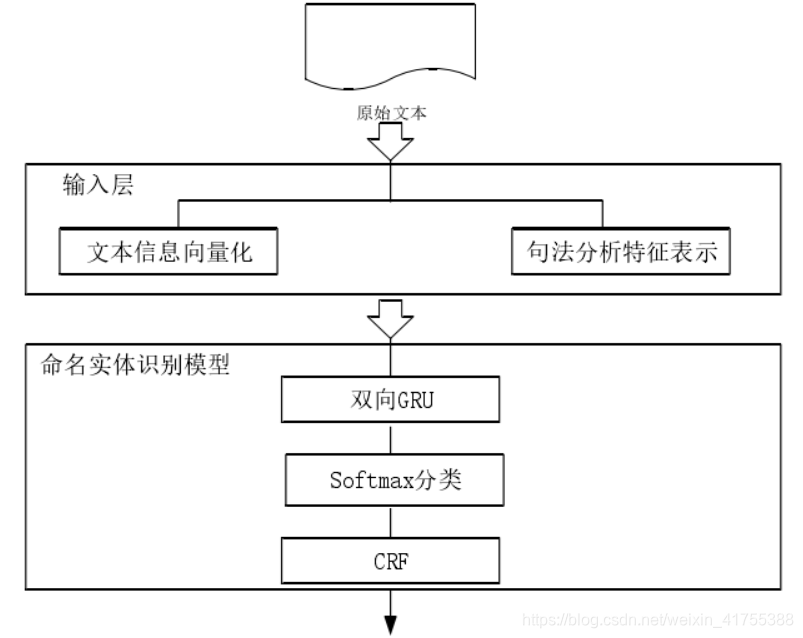
3、模型解析
(1)词向量层:给定一个由T个词组成的句子S={x1,x2,x3,…,xT},对于句子S的每个词,使用word2vec将每个词xi映射到一个低维实值向量空间中。通过公式进行字向量处理:
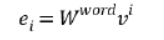
ei是字xi的字向量表示;
vi是输入字的one-hot形式;
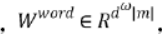 其中m固定长度的词典,dw是字向量的维度,
其中m固定长度的词典,dw是字向量的维度,
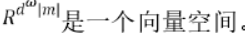 ,由此可以得到句子中每个字的向量表示e;
,由此可以得到句子中每个字的向量表示e;
 其参数可以直接随机初始化或者使用预训练好的词向量如word2vec、glove。本文采用word2vec进行参数初始化,并且在网络训练过程中wword可以选择固定参数或者随着网络训练的变化进行微调。
其参数可以直接随机初始化或者使用预训练好的词向量如word2vec、glove。本文采用word2vec进行参数初始化,并且在网络训练过程中wword可以选择固定参数或者随着网络训练的变化进行微调。
(2)句法分析层
线性编码成分句法树首先线性化句法分析树,然后深度优先遍历句法树,得到句法树的线性序列标签,与词向量相似,为句法树的每一个非叶子节点的标签标记宇哥标签向量,这样就可以将成分句法分析树的线性标签序列转换成向句子一样的标签向量序列,输入到网络中进行处理。
(3)双向GRU层
这层的主要作用是对词语的总特征向量序列进行处理,对每个词语输出一个预测的特征向量,将预测的特征向量传递到输出层来得到短语对应的预测标签。可以说,词语的预测特征向量需要考虑词语的上下文信息。
使用Bi-GRU模型,在输入层得到的句子向量化作为上输入,以第i个词为例,它输出的计算使用公式为:
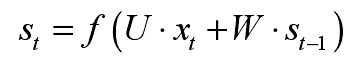
(4)softmax层
假设这一层的输入为X=(x1,x2,…,xt),xi为词语的预测特征向量,softmax层的作用是将经过xi经过一个大小为n的全连接层,得到S=(Si,1,Si,2,…,Si,n),n为标签的数量,Si为xi对应词语的标签预测结果向量,对Si使用softmax函数进行归一化处理得到Pi=(Pi,1,Pi,2,…,Pi,n),softmax函数公式:
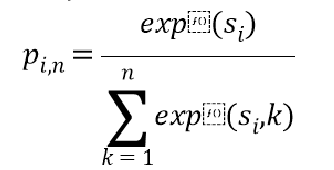
Pi,n代表xi对应词语预测为该结果的概率,然后在模型计算时,假设x的正确标签序列为Y=(y1,y2,…,yT),使用交叉熵计算损失函数的损失值loss,公式如下:
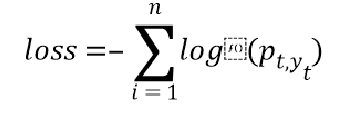
根据上式求得的loss计算梯度,使loss尽可能的小来使词语的预测正确标签的概率尽可能地大以达到优化目标调整参数的目的,模型的训练结束后,选取Pt中概率最大的作为最终的预测标签。
(5)CRF层
因为softmax层对每个词语是进行独立预测的,忽略了相邻标签之间的关系。CRF层采用条件随机场模型,考虑相邻标签之间的关系,增加全局优化的思想,通过增加标签转移的分数矩阵参数和定义序列的预测得分进行全局的优化,解决softmax层标签预测不合理的情况。
输入:X=(x1,x2,…,xT)输入CRF层,得到词语的标签分数矩阵sc,Si,j代表词语序列第i个字预测为标签j的分数,假设X的正确标签序列为Y=(y1,y2,…,yT),计算正确标签序列的分数S(X,T)。
然后使用softmax函数计算出正确标签序列的条件概率P(Y|X),计算损失函数的损失值loss,使得loss尽可能的大以达到优化目标调整参数的目的,模型的训练结束之后,使用维特比算法求出概率最大的一标签序列作为最终的预测标签。
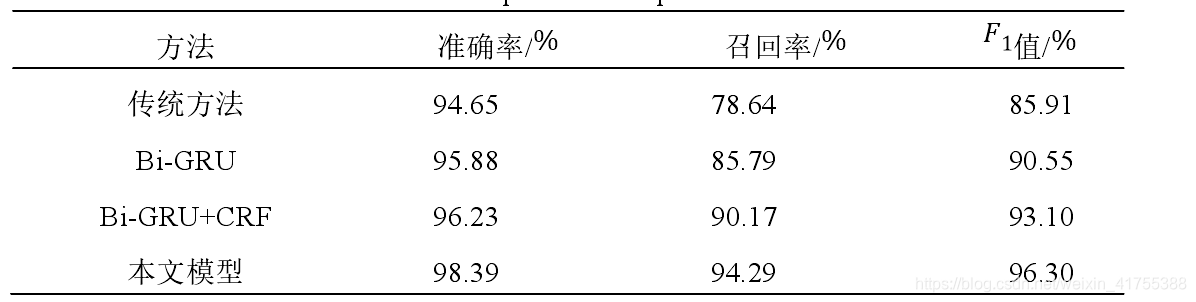
3、实验结果分析
使用交叉验证来确定模型的参数,然后评估句法分析的影响,并在不同大小的数据上显示其性能,最后将设计的模型与几种命名实体的方法在同一数据集上进行实验比较。
(1)语料统计

(2)评价指标
准确率、召回率、F1值
(3)参数设置
激活函数选用sigmoid函数
sofmax、crf
dropout、SGD、交叉验证
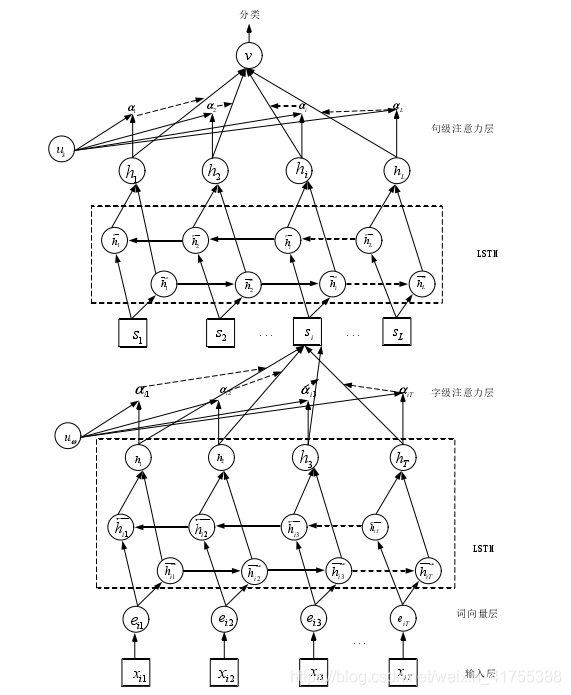
基于多层注意力机制的关系抽取
- 特征:字嵌入+ 位置嵌入,增加了语义相似度、
- 模型:bilstm
- 注意力层:局部特征+全局特征
一、向量
1、字向量层
这里使用字来表示相向量
2、位置向量
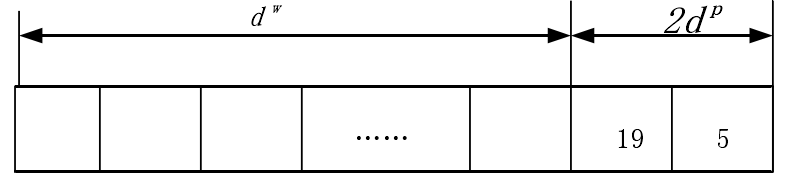
在关系抽取的任务中,越靠近目标实体的字经常更能表示句子中的两个实体的关系。作者的模型使用位置向量来标记实体对,可以帮助LSTM判断句子中的每个字与实体对的位置,将从句子中第i个字分别到e1和e2的相对距离的组合定义为位置向量。

关系:千金;
实体:卢恬儿(e1)、卢润森(e2)
字向量的维度:
针对上图,千金->卢恬儿距离为19;千金->卢润森距离为5,则”千金“的向量化表示为
二、注意力机制
中文的信息对关系抽取的影响可能来源于某一个关键字,所以局部特征非常重要。本文使用注意力机制增强局部特征与全局特征。
1、字级注意力机制
将句子向量w={w1,w2,…,w3}输入LSTM模型中,获得句子初步训练的结果ht,使用公式进行处理:
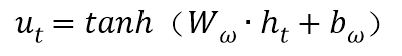
在实际场景中,并非所有的字都对句子含义的表示同等作用,在训练过程中随机初始化并共同学习字上下文向量Uw。引入字级注意力机制衡量字与关系的相关程度,并汇总那些信息字的表示形成句子向量,字级注意力机制的公式:
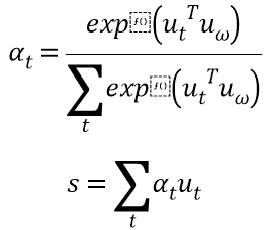
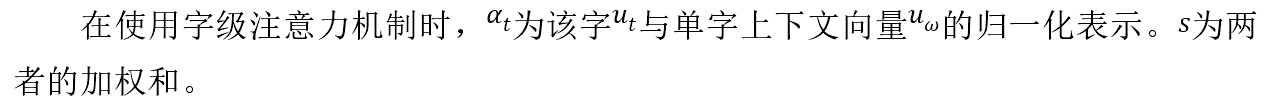
2、句子注意力机制
通过字级注意力机制得到的s组成的句子输入LSTM模型得到输出hi。与字级注意力机制相似,在训练过程中随机初始化并共同学习句子上下文向量us,得到所有句子的向量集合v:
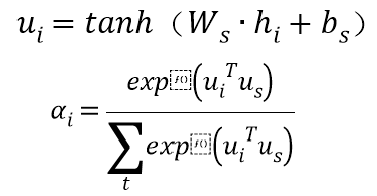
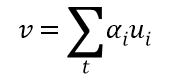
3、结果分类

4、整个模型训练



















 2872
2872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









