









目录
词性标注
词性作为词语基本的语法属性,是词语和语句的关键性特征。词性种类也越多,可参考ICTCLAS汉语词性标注集归纳的词性种类及其种类表。
词性标注的难点:
1、相对于英文,中文缺少词语形态变化,不能从词的形态来识别词性
2、一词多词性很常见。统计发现,一词多词性的概率高达22.5%。而且越常用的词,多词性线性越严重,比如“研究”既可以是名字也可以是动词。
3、词性划分标准不统一。词类划分粒度和标记符号等,目前还没有一个广泛认可的统一标准。比如LDC词性标注预料中,将汉语一级词性分为33类,而北京大学语料库则将其划分为26类。词类划分标准和标记符号的不统一,以及分词规范的含糊,都给词性标注带来了很大的困难。jieba分词采用了使用较为广泛的ICTCLAS 汉语词性标注集规范。
4、未登录词问题。和分词一样,未登录词的词性也是一个比较大的课题。未登录词不能通过查找字典的方式获取词性,可以采用HMM隐马尔科夫模型等基于统计的算法。
词性标注算法
词性标注算法分为两大类,基于字符串匹配的字典查找算法和基于统计的算法。
jieba分词就综合了两种算法,对于分词后识别出来的词语,直接从字典中查找其词性。而对于未登录词,则采用HMM隐马尔可夫模型和viterbi算法来识别。
基于字符串匹配的字典查找算法
先对语句进行分词,然后从字典中查找每个词语的词性,对其进行标注即可。
jieba词性标注中,对于识别出来的词语,就是采用了这种方法。这种方法笔记哦啊简单,通俗易懂,但是不能解决一词多词性的问题,因此存在一定的误差。
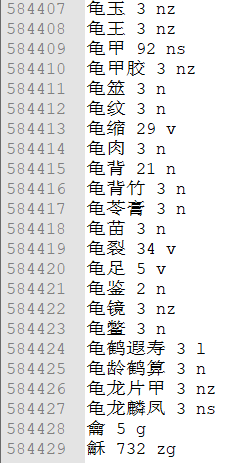
下图为jieba分词中词典的一部分词语。每一行对应一个词语,分为三部分,分别为词语名、词数、词性。因此分词完成后只需要在字典中查找该词语的词性即可对其完成标注。
基于统计的词性标注算法
可以通过HMM隐马尔可夫模型来进行词性标注。
- 观测序列即为分词后的语句,隐藏序列即为经过标注后的词性标注序列;
- 其实概率、发射概率和转移概率和分词中的含义大同小异,可以通过大规模预料统计得到;
- 观测序列和隐藏序列的计算可以通过viterbi算法,利用统计得到的其实概率、发射概率和转移概率来得到;
- 得到隐藏序列后,就完成了词性标注过程。
jieba分词可以在分词的同时,完成词性标注,因此标注速度可以得到保证。通过查询字典的方式获取识别词的词性,通过HMM隐马尔可夫模型来获取未登录的词的词性,从而完成整个语句的词性标注。
句法分析
句法分析也是自然语言处理中的基础性工作,它分析句子的句法结果(主谓宾结构)和词汇间的依存关系(并列、从属等)。通过句法分析,可以为语义分析,情感倾向,观点抽取等NLP应用场景打下坚实的基础。
随着深度学习在NLP中的使用,特别是本身携带句法关系的LSTM模型的应用,句法分析已经变得不是那么必要了。但是,在句法结构十分复杂的长语句,以及标注样本较少的情况下,句法分析依然可以发挥出很大的作用。因此研究句法分析依然是很有必要的。
句法分析主要分为两类,一类是分析句子的主谓宾、定状补的句法结构;另一类是分析词汇之间的依存关系,如并列、从属、比较、递进等。
句法结构分析
通过句法结构分析,就能够分析出语句的主干,以及各成分之间的关系。对于复杂语句,仅仅通过词性分析,不能得到正确的语句成分关系。
语义依存关系分析
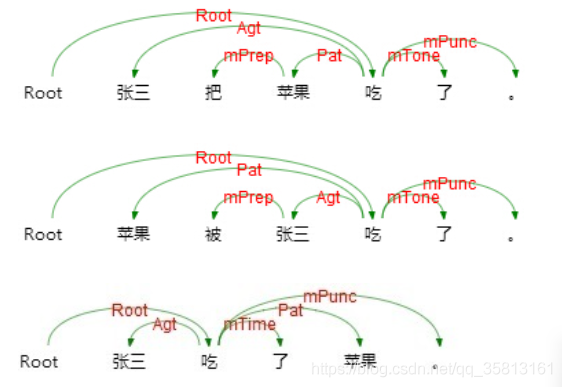
语义依存关系分析可以获得较深层的语言信息。
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 施事关系 | Agt | Agent | 我送她一束花 (我 <-- 送) |
| 当事关系 | Exp | Experiencer | 我跑得快 (跑 --> 我) |
| 感事关系 | Aft | Affection | 我思念家乡 (思念 --> 我) |
| 领事关系 | Poss | Possessor | 他有一本好读 (他 <-- 有) |
| 受事关系 | Pat | Patient | 他打了小明 (打 --> 小明) |
| 客事关系 | Cont | Content | 他听到鞭炮声 (听 --> 鞭炮声) |
| 成事关系 | Prod | Product | 他写了本小说 (写 --> 小说) |
| 源事关系 | Orig | Origin | 我军缴获敌人四辆坦克 (缴获 --> 坦克) |
| 涉事关系 | Datv | Dative | 他告诉我个秘密 ( 告诉 --> 我 ) |
| 比较角色 | Comp | Comitative | 他成绩比我好 (他 --> 我) |
| 属事角色 | Belg | Belongings | 老赵有俩女儿 (老赵 <-- 有) |
| 类事角色 | Clas | Classification | 他是中学生 (是 --> 中学生) |
| 依据角色 | Accd | According | 本庭依法宣判 (依法 <-- 宣判) |
| 缘故角色 | Reas | Reason | 他在愁女儿婚事 (愁 --> 婚事) |
| 意图角色 | Int | Intention | 为了金牌他拼命努力 (金牌 <-- 努力) |
| 结局角色 | Cons | Consequence | 他跑了满头大汗 (跑 --> 满头大汗) |
| 方式角色 | Mann | Manner | 球慢慢滚进空门 (慢慢 <-- 滚) |
| 工具角色 | Tool | Tool | 她用砂锅熬粥 (砂锅 <-- 熬粥) |
| 材料角色 | Malt | Material | 她用小米熬粥 (小米 <-- 熬粥) |
| 时间角色 | Time | Time | 唐朝有个李白 (唐朝 <-- 有) |
| 空间角色 | Loc | Location | 这房子朝南 (朝 --> 南) |
| 历程角色 | Proc | Process | 火车正在过长江大桥 (过 --> 大桥) |
| 趋向角色 | Dir | Direction | 部队奔向南方 (奔 --> 南) |
| 范围角色 | Sco | Scope | 产品应该比质量 (比 --> 质量) |
| 数量角色 | Quan | Quantity | 一年有365天 (有 --> 天) |
| 数量数组 | Qp | Quantity-phrase | 三本书 (三 --> 本) |
| 频率角色 | Freq | Frequency | 他每天看书 (每天 <-- 看) |
| 顺序角色 | Seq | Sequence | 他跑第一 (跑 --> 第一) |
| 描写角色 | Desc(Feat) | Description | 他长得胖 (长 --> 胖) |
| 宿主角色 | Host | Host | 住房面积 (住房 <-- 面积) |
| 名字修饰角色 | Nmod | Name-modifier | 果戈里大街 (果戈里 <-- 大街) |
| 时间修饰角色 | Tmod | Time-modifier | 星期一上午 (星期一 <-- 上午) |
| 反角色 | r + main role | 打篮球的小姑娘 (打篮球 <-- 姑娘) | |
| 嵌套角色 | d + main role | 爷爷看见孙子在跑 (看见 --> 跑) | |
| 并列关系 | eCoo | event Coordination | 我喜欢唱歌和跳舞 (唱歌 --> 跳舞) |
| 选择关系 | eSelt | event Selection | 您是喝茶还是喝咖啡 (茶 --> 咖啡) |
| 等同关系 | eEqu | event Equivalent | 他们三个人一起走 (他们 --> 三个人) |
| 先行关系 | ePrec | event Precedent | 首先,先 |
| 顺承关系 | eSucc | event Successor | 随后,然后 |
| 递进关系 | eProg | event Progression | 况且,并且 |
| 转折关系 | eAdvt | event adversative | 却,然而 |
| 原因关系 | eCau | event Cause | 因为,既然 |
| 结果关系 | eResu | event Result | 因此,以致 |
| 推论关系 | eInf | event Inference | 才,则 |
| 条件关系 | eCond | event Condition | 只要,除非 |
| 假设关系 | eSupp | event Supposition | 如果,要是 |
| 让步关系 | eConc | event Concession | 纵使,哪怕 |
| 手段关系 | eMetd | event Method | |
| 目的关系 | ePurp | event Purpose | 为了,以便 |
| 割舍关系 | eAban | event Abandonment | 与其,也不 |
| 选取关系 | ePref | event Preference | 不如,宁愿 |
| 总括关系 | eSum | event Summary | 总而言之 |
| 分叙关系 | eRect | event Recount | 例如,比方说 |
| 连词标记 | mConj | Recount Marker | 和,或 |
| 的字标记 | mAux | Auxiliary | 的,地,得 |
| 介词标记 | mPrep | Preposition | 把,被 |
| 语气标记 | mTone | Tone | 吗,呢 |
| 时间标记 | mTime | Time | 才,曾经 |
| 范围标记 | mRang | Range | 都,到处 |
| 程度标记 | mDegr | Degree | 很,稍微 |
| 频率标记 | mFreq | Frequency Marker | 再,常常 |
| 趋向标记 | mDir | Direction Marker | 上去,下来 |
| 插入语标记 | mPars | Parenthesis Marker | 总的来说,众所周知 |
| 否定标记 | mNeg | Negation Marker | 不,没,未 |
| 情态标记 | mMod | Modal Marker | 幸亏,会,能 |
| 标点标记 | mPunc | Punctuation Marker | ,。! |
| 重复标记 | mPept | Repetition Marker | 走啊走 (走 --> 走) |
| 多数标记 | mMaj | Majority Marker | 们,等 |
| 实词虚化标记 | mVain | Vain Marker | |
| 离合标记 | mSepa | Seperation Marker | 吃了个饭 (吃 --> 饭) 洗了个澡 (洗 --> 澡) |
| 根节点 | Root | Root | 全句核心节点 |
深度学习与句法分析
基于深度学习的RNN和LSTM序列模型,本身可以携带很多句法结构和依存关系等深层信息,同时,句法分析树结构也可以和深度学习结合起来。利用句法分析树可以构建LSTM网络(tree-lstm),从而对语句进行文本摘要、情感分析。
词向量
在NLP里面,最细粒度的是词语,词语组成句子,句子组成段落、篇章、文档。所以要处理NLP的问题,首先拿词语开刀。
举个栗子,判断一个词语的情感,是积极还是消极,用机器学习的思路,我们有一些类样本(x,y),这里x是词语,y是他们的情感类别,我们要构建f(x)到y的映射,但这里的数学模型f(比如神经网络)只接受数值型输入,而NLP里的词语,是人类的抽象总结,是符号形成的(比如中文、英文、拉丁文等),所以需要把他们转换成数值形式,或者说嵌入到一个数学空间里,这种嵌入方式就叫做词嵌入(vord embeding)。既然深度学习方法需要用数学符号才能进行,那就需要把每个单词表示为一个d维的向量。
![]()
词袋模型(bag of words)
词袋模型是一种机器学习算法,一种对文本进行建模时表示文本数据的方法。其假设不考虑文本中词与词之间的上下文关系,仅仅只考虑只有所有词的权重,而权重与词在文本中出现的频率有关。
与词袋模型类似的一个模型是词集模型(Set of Words,SoW),和词袋模型唯一不同在于它仅仅考虑是否在文本中出现,而不考虑词频,也就是一个词在文本中出现1词或者多次特征处理是一样的。但在大多是时候,都是用词袋模型。
词袋模型/One-Hot编码方法
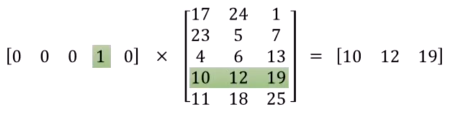
把词汇表中的词排成一列,对于某个单词A,如果他出现在词汇序列中的位置为k,那么它的向量表示就是“第k位时1,其他位置都为0”的一个向量。例如,语料为“John likes to watch movies. Mary likes movis too. John alse like to watch football games, likes.”,把预料中的词汇表整理出来并排序(具体排序原则可以有很多,例如可以根据字母表顺序,也可以根据出现在语料库中的先后顺序)。
假设词汇表排序结果为"{"John":1, "likes":2, "to":3, "watch":4, "movies":5, "also":6, "football":7, "games":8, "Mary":9, "too":10},那么则有如下word的向量表示:John:[1,0,0,0,0,0,0,0,0,0],likes[0,1,0,0,0,0,0,0,0,0],此时可以进一步把文档也表示成向量,方法就是直接将各词的词向量之和表示加和,于是则有原来的两句话的向量表示如下:[1,2,1,1,2,0,0,0,1,1],[1,2,1,1,0,1,1,1,0,0]。
其缺点其一在于没有考虑单词之间的相对位置关系,其二在于词向量可能非常非常长。
词嵌入-共现矩阵(Concurrence matrix)
共现矩阵的每个元素表示一个词语另一个词在整篇文章中相邻出现的次数。例如“I Love NLP and I like dogs"。其共现矩阵如下:
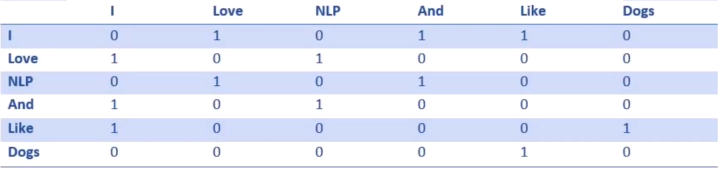
可以将共现矩阵的每一行当做词向量的初始值。如下:

但是需要注意到这种向量表示方式的维度会随着语料集的增长而呈线性增长。倘若有一百万个单词,就会得到一个1000000 X 1000000 的矩阵,而且这个矩阵非常的稀疏。从存储效率来说,这显然不是一种好的表示方法。
Word2Vec
词向量方法的基本思想就是让向量尽可能完整地表示该词包含的信息,同时让向量维度保持在一个可控范围内(合适的维度是25~1000维之间)。Word2Vec,也就是词嵌入(word embedding)的一种。
其能够自动实现:1)单词语义相似性的度量;2)词汇的语义的类比。此处,语义的类比,反应的是类似下面的这种关系:
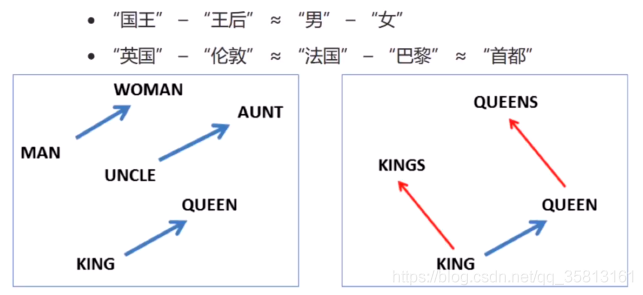
Word2Vec的目标是将一个词表示成一个向量,其包含两个重要模型CBOW和Skip-gram模型。
Word2Vec的详细实现,简而言之,就是一个三层的卷积神经网络。下图是Word2Vec的简要流程图(假设,词库的词数是10000,词向量的长度为300)。
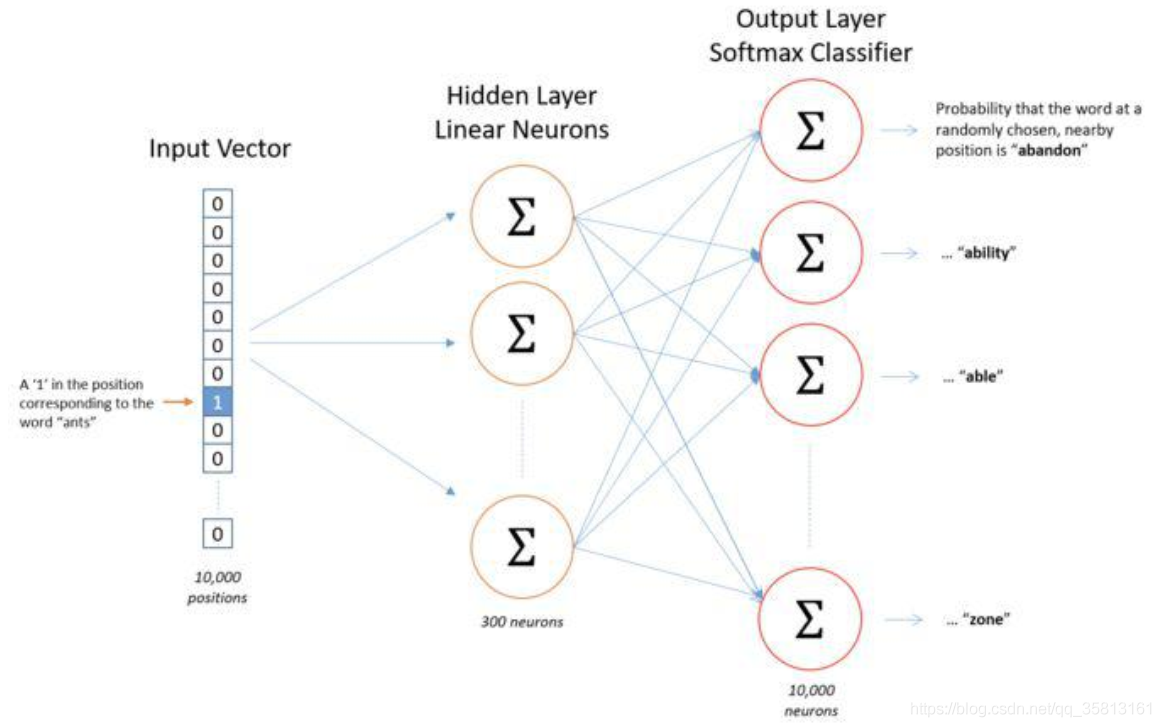
1、输入层:输入层时一个词的one-hot向量表示,这个向量长度10000。假设这个词为ants,ants在词库中id为i,则输入向量的第i个分量为1,其余为0,例如;[0,0,...,0,0,1,0,0,...,0,0];
2、隐藏层:隐藏层的神经元个数就是词向量的长度。隐藏层的参数是一个[10000, 300]的矩阵。实际上,这个参数矩阵就是词向量。回忆一下矩阵相乘,一个one-hot行向量和矩阵相乘,结果就是矩阵的第i行。经过隐藏层,实际上就是10000维的one-hot向量映射成了最终想要得到的300维的词向量。
3、输出层:输出层的神经元个数为总次数10000,参数矩阵尺寸为[300, 10000]。词向量经过矩阵计算后再加上softmax归一化,从新变为10000维的向量,每一维对应词库中的一个词与输入词(这里以ants为例)共同出现在上下文中的概率。
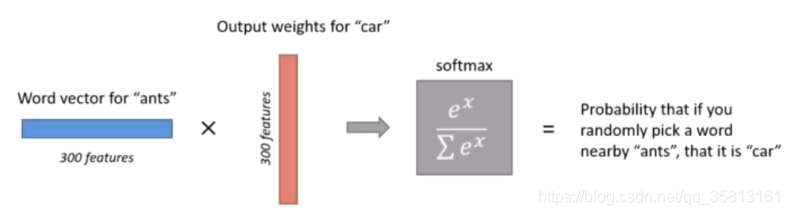
上图中计算car与ants出现的概率,car所对应的300维向量就是输出层参数矩阵中的一列。输出层的参数矩阵是[300,10000],也就是计算了词库中所有词与ants共现的概率,输出的参数矩阵训练完毕后没有作用。
上面步骤是一个词作为输入和一个上下文中的词作为输出的情况,但是实际情况显然更复杂。用一个词去预测周围的其他词,还是用周围的好多词来预测一个词,这里就要引入实际训练时的两个模型skip-gram和CBOW。
skip-gram
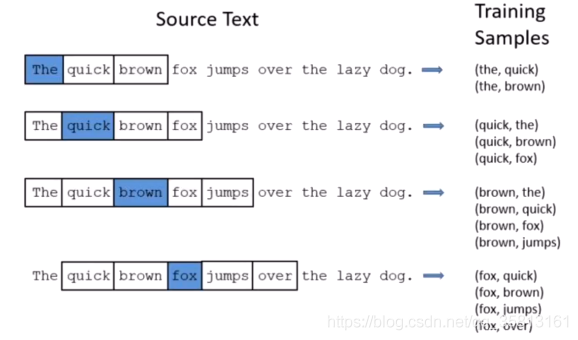
其核心思想是根据中心词来预测周围的词。假设中心词是cat,窗口长度为2,则根据cat预测左边两个词和右边两个词,这时,cat作为神经网络的input,预测的词作为label。在这里窗口长度为2,中心词一个一个移动遍历所有文本,每一次中心词的移动,最多会产生4对训练样本(input, label)。
CBOW(continous-bag-of-words)
CBOW模型其实就是skip-gram倒过来,用周围的所有词来预测中心词。这时候,每一次中心词移动,智能产生一个训练样本。如果还是用上面的例子,则CBOW模型会产生下列4个训练样本。

词向量的重要意义在于将自然语言转换成了计算机能够理解的向量。相对于词袋模型,词嵌入能抓住词的上下文、语义、衡量词与词的相似性,在文本分类、情感分析等许多自然语言处理领域有重要作用。















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









