









【论文】2018_基于中文形态学和语义关系的类比推理 Analogical Reasoning on Chinese Morphological and Semantic Relations
开源地址: https://github.com/Embedding/Chinese-Word-Vectors
论文地址: Analogical Reasoning on Chinese Morphological and Semantic Relations - ACL Anthology
文章目录
0 摘要
类比推理在捕捉语言规律方面是有效的。本文提出了一个关于汉语的类比推理任务。在深入挖掘汉语词汇知识后,我们勾勒出68个隐性形态关系和28个显性语义关系。然后为该任务构建了一个大型且平衡的数据集CA8,包括17813个问题。此外,我们系统地探讨了向量表示、上下文特征和语料对类比推理的影响。通过实验,CA8被证明是评估中文词向量的可靠基准。
1 引言
介绍中文语言特点与英语语言特点具有不同之处:
- 英文为黏着语, 具有词根词缀; 而中文为孤立语, 没有词根词缀的概念(但存在”半词缀”现象, 将在后文中展开研究)
- 中文中很多词语的语义关系与中国历史文化息息相关.
目前存在的问题:
- 没有中文类比推理数据集, 现有唯一的数据集CA_translation 是从英文数据集中翻译来的(后文研究中进一步指出,这个数据集中只具有中文语义关系, 而不具有中文形态学关系)
研究贡献:
- 发布一个中文类比推理数据集CA8, 具有更平衡的中文语言学特点.
- 开源了36个中文预训练词向量
2 中文的形态学关系 Morphological Relations
2.1. 重叠关系(reduplication)
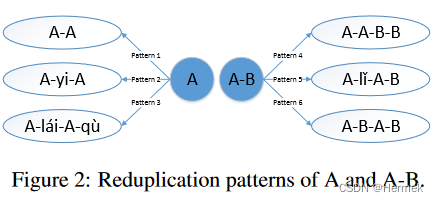
2.2. 半黏着关系(semi-affixation)
中文是孤立语,没有词缀的概念,但是, 2001年的一项研究表明中文中仍然有一部分的词语具有词缀的属性,如 一/第一,二/第二,胖/胖子,瘦/瘦子. 这类语素被称为半黏着(semi-affixes)
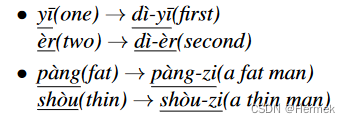
本研究发现了21个半前缀(semi-prefixes)和41个半后缀(semi-suffixes).
3 中文的语义关系 Semantic Relations
本研究提出了地理\历史\自然\人 4个方面共28种语义关系, 用于研究语义类比推理.
此外,研究还提出了新的类推关系,如 科学家–发明, 公司 — 资助者 等.
4 中文类比推理任务
(我的研究方向关注的重点不在类比推理任务,因此这部分略过)
“CA8 incorporates both morphological and semantic questions, and it brings in much more words, relation types and questions. Table 1 shows details of the two datasets.” (Li 等, 2018, p. 140) 🔤CA8融合了形态问句和语义问句,引入了更多的词语、关系类型和问句。表1给出了两个数据集的详细信息。🔤
5 实验部分
5.1 验证向量表示(稀疏、稠密)对捕获语言关系的影响
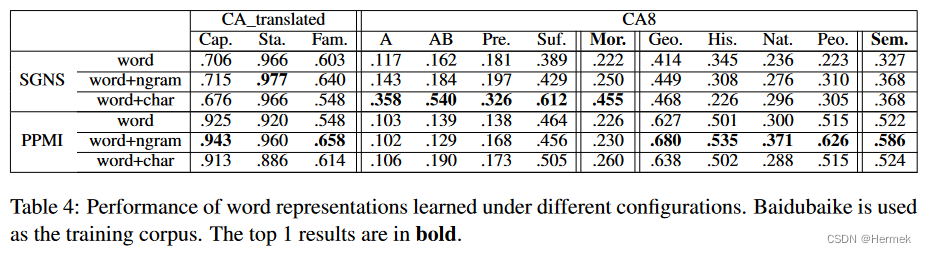
“Existing vector representations fall into two types, dense vectors and sparse vectors. SGNS (skipgram model with negative sampling) (Mikolov et al., 2013) and PPMI (Positive Pointwise Mutual Information) (Levy and Goldberg, 2014a) are respectively typical methods for learning dense and sparse word vectors.” (Li 等, 2018, p. 140) **现有的向量表示分为两类,稠密向量和稀疏向量。**SGNS (带负采样的N元语法模型) (米科洛夫等, 2013)和PPMI (正的点态互信息) ( Levy和Goldberg , 2014a)分别是学习稠密词向量和稀疏词向量的典型方法。
验证两种向量表示法在不同特征下、在CA_translated数据集和CA8数据集中的效果。
实验目的:
验证CA8在语义关系和形态关系推理中比其他数据集更平衡; 验证稠密向量和稀疏向量在捕获语言关系中的特点
实验结论:
结论一:
“that on CA8 dataset, SGNS representations perform better in analogical reasoning of morphological relations and PPMI representations show great advantages in semantic relations.” (Li 等, 2018, p. 140) 在CA8数据集上,SGNS表示在形态关系的类比推理上表现更好,PPMI表示在语义关系上表现出很大的优势。
结论二:
“The above observation shows that CA8 is a reliable benchmark for studying the effects of dense and sparse vectors. Compared with CA_translated and existing English analogy datasets, it offers both morphological and semantic questions which are also balanced across different types 4.” (Li 等, 2018, p. 141) 上述观测表明,CA8是研究稠密向量和稀疏向量影响的可靠基准。与CA _ translation和已有的英语类比数据集相比,它同时提供了形态问题和语义问题,这些问题在不同类型之间也是平衡的( 4 )。
结果分析:
“probably because the reasoning on morphological relations relies more on common words in context, and the training procedure of SGNS favors frequent word pairs. Meanwhile, PPMI model is more sensitive to infrequent and specific word pairs, which are beneficial to semantic relations.” (Li 等, 2018, p. 141) 这可能是因为形态关系的推理更多地依赖于上下文中的常用词,而SGNS的训练过程偏向于频繁词对。同时,PPMI模型对非频繁词对和特定词对更加敏感,这有利于语义关系。
什么是形态关系(Morphological)的推理?
**Morphological Analysis(形态分析)**是语言学的一个分支,研究词汇单元(如单词或汉字)的内部结构以及它们如何组合形成新的意义。在形态分析中,词汇单元被分解成更小的、具有独立意义的部分,称为形态素(morphemes)。形态素是语言中最小的含义单位。 形态分析关注词汇单元的构成和变化规律,例如词缀的添加、词根的组合以及词汇单元之间的其他关系。这些规律有助于我们理解词汇之间的关系,以及如何通过组合和变换形成新词汇。 在不同的语言中,形态分析的方法和重点可能有所不同。例如,在英语等屈折语言中,形态分析通常关注词缀(如前缀、后缀)的变化以及它们对词义的影响;而在汉语等孤立语言中,形态分析可能更关注汉字的组合和拆分,以及它们在词汇和语法层面上的作用。
形态关系的推理(Morphological reasoning) 是指在自然语言处理和计算语言学领域中,研究如何从词汇单元(如单词或汉字)的形态结构中提取和推断潜在的关系和规律。这种推理过程通常涉及到词汇单元的分解、组合和变换,以便更好地理解语言的结构和意义。 在类比推理任务中,形态关系的推理要求模型理解并应用这些形态学联系来解决问题。**例如,**给定一个类比问题:“父亲 - 母亲:儿子 - ?”,模型需要识别出这种形态关系(即亲属关系),并应用这种关系来找到合适的答案(女儿)。 形态关系的推理对于评估自然语言处理模型的能力非常重要,因为它们可以揭示模型对词汇知识的理解程度,以及在不同语境下应用这些知识的能力。通过研究形态关系的推理,研究人员可以更好地理解语言的特点,并为改进自然语言处理模型提供有价值的见解。
5.2 验证上下文特征对语言关系的影响
选取三种特征:词特征、ngram特征(此处用bigram)、汉字字符特征(单字、双字)
实验结论:
“Furthermore, character features are especially advantageous for reasoning of morphological relations. SGNS model integrating with character features even doubles the accuracy in morphological questions.” (Li 等, 2018, p. 141) 此外, **字符特征对于形态关系的推理尤其有利. **融合了字符特征的SGNS模型在形态学问题上的准确率甚至提高了一倍。
5.3 验证语料库对实验准确率的影响
实验结论:
结论一:
语料库规模越大,准确性越高
结论二:
不同领域的语料库所训练出的词向量, 对不同类型的词语表征具有不同的效果:
- 如, 由人民日报这类以政治为主的新闻预料训练出的词向量对地理关系有益;
- 如,由知乎问答zhihuQA这类具有大量非正式词语(informal data)的语料库训练出的词向量, 在表征叠词(reduplication words) 的时候有较好的效果,这是因为口语中往往会使用更多的叠词.
可以进一步验证以上两点的是, 使用Combination语料库(即把该实验所用的5个数据集合在一起,具有最大规模\最多样的领域) 训练出的词向量, 比独立语料库拥有更好的性能.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









