







背景
理解一个模型的原理,主要是看模型的输入是什么,以及输出是如何定义的。因为大多数模型的结构都是全卷积层,只有输出是存在差异的。
输入320x320,精度和ssd一样,但速度是ssd的三倍。
模型输出
Bounding Box Prediction
通过网格的方法建模
每个网格负责预测bounding box中心点落在自己区域的目标。
t
x
t_{x}
tx 相对所属网格左上角横坐标的偏移量
t
y
t_{y}
ty 相对所属网格左上角纵坐标的偏移量
t
w
t_{w}
tw 相对对应anchor的对数大小
t
h
t_{h}
th 相对对应anchor的对数大小
解析目标框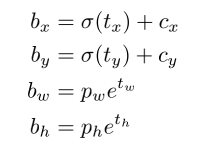
(
c
x
c_{x}
cx,
c
y
c_{y}
cy)网格的左上角坐标
p
w
p_{w}
pw,
p
h
p_{h}
ph prior box的宽和高
解析bounding box

通过sigmoid函数来预测物体中心点相对网格左上角的相对位置
Objectness Score
目标置信度逻辑回归(sigmoid)得到目标的置信度
YOLOv3 predicts an objectness score for each bounding
box using logistic regression.
目标如何与prior box匹配
论文原文:
This should be 1 if the bounding box prior overlaps a ground truth object by more than any other bounding box prior. If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold we ignore the prediction,Unlike faster rcnn our system only assigns one bounding box prior for each ground truth object.
在yolov3中一个gt只能被一个prior boxes预测。而在其他anchor系列的模型中,一个gt是可以被多个anchor预测的。
Class Prediction
通过逻辑回归输出每个类别上的得分
输出channel长度为255

loss
回归用MSE
分类用CE















 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









