






本内容是kaggle 官网的题目-房屋价格预测。涵盖了详细特征挖掘和模型建立完整的内容。若是你是一个刚入门的数据挖掘师,本文章可以帮助你进行一次完整的数据挖掘。希望对你有帮助~
以下内容涵盖了数据探查、模型建立、其他处理方法介绍。
一、数据探查
1.1 基本信息了解
首先先对基本信息进行中文翻译,得出以下结论:
-
存在两列的字段含义一致:Condition1 和 Condition2
-
YearBuilt 和 YearRemodAdd
为创建日期和改建日期,日期需要转化为时间长度,根据售卖月份进行计算。可以进行程序对比,对于空值需要做处理 -
存在两列的字段含义一致:BsmtFinType1+BsmtFinSF1 和 BsmtFinType2+BsmtFinSF2
import pandas as pd
from translate import Translator
# 读取字段的含义并期望进行中文翻译
df_description = pd.read_excel('E:\qbn\数据分析\kaggle-regress\data_description.xlsx')
df_description['transform'] = ''
# 调取翻译库
def translate_text(text):
translator = Translator(to_lang="zh")
translation = translator.translate(text)
return translation
# 循环调用字段并进行翻译赋值
n = -1
for item in df_description['txt']:
n += 1
print(n)
if len(str(item)) == 0:
continue
df_description['transform'][n] = translate_text(str(item))
df_description.to_csv('data_description_transform.csv', index=False)
1.2 特征处理
由于在进行特征处理过程中,测试集和训练集必须保持一样的处理方式,因此先把数据集进行合并。
train_data=pd.read_csv('.train.csv', encoding='utf-8')
test_data=pd.read_csv('.test.csv', encoding='utf-8')
test_data['SalePrice']=0
data_all = pd.concat([train_data, test_data]).reset_index(drop=True)
1.2.1数值型
1.2.1.1 空值处理
数值型的字段,判断是否有空值,并进行处理
data_all.info()
发现:
● LotFrontage:相同的领居其地理位置应该差不多,再根据数据显示,Neighborhood 相同的 LotFrontage 比较相似,因此空值可以取其同Neighborhood的LotFrontage众值
● 其余进行0补充处理
# 空值可以取其同Neighborhood的LotFrontage众值
data_all['LotFrontage'] = data_all.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.mode()[0]))
# 0替换空值
for i in data_all.columns:
if data_all[i].dtype != object:
data_all[i] = data_all[i].fillna(0)
注:在合并数据集之后,凡是涉及到删除数据的,不可以删除到测试集的数据。因此不建议在合并数据集后的环节进行删除,可以等到后面的拆分后进行处理,当然也可以利用其他方法进行训练集和测试集的识别后再进行训练集部分数据过滤。
取分类众数的方法进行补充空值有以下两种方式,可以任意选择。
'方法一'
#LotFrontage 的空值用众数替代
mean_LotFrontage = pd.pivot_table(data_test0, index="Neighborhood", values="LotFrontage", aggfunc=mode1)
# print(mean_LotFrontage)
n=0
for items in data_test0['LotFrontage']:
if math.isnan(items) == True:
# 获取Neighborhood的分类
neib = data_test0['Neighborhood'][n]
# 找到分类的众数
for item in mean_LotFrontage.index:
if item == neib :
m0 = data_test0['LotFrontage'][n]
m1 = mean_LotFrontage['LotFrontage'][item]
data_test0['LotFrontage'][n] = m1
# print("n:",n," data_test0['LotFrontage'][n]:",data_test0['LotFrontage'][n])
break
n = n + 1
'方法二'
data_test0['LotFrontage'] = data_test0.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.mode()[0]))
1.2.1.2 异常值处理
判断是有异常值,散点图发现异常值,进行平滑处理或者剔除。
#转化datadrame 类型变成 字典类型
column_types = data_test0.dtypes.to_dict()
# 查看每一列的数据类型,采用散点分布查看,过滤掉异常点
for column, data_type in column_types.items():
# 处理数据类型异常值
if data_type !='object' and column !='SalePrice':
# 1.创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2.绘制图像
plt.scatter(data_test0[column], data_test0['SalePrice'], s=100, c='deeppink', marker='o', label=column)
# 3. 添加网格显示
plt.grid(True, linestyle="--", alpha=0.5)
# 4 图像保存
plt.savefig("E:/QBN/数据分析/kaggle/picture/%s.png" %(column))
# 5 添加图例
plt.legend(loc="best")
# 6 图像显示
plt.show()
print (column)
通过散点图得出以下结论:
- LotFrontage : 与街道的英尺距离,在右下角发现两个异常值,需要过滤掉(其它值都呈现和价格同趋势,比如价格越高其LotFrontage 也是越高)
- LotArea:地块面积,有四个点的面积很大,但是其价格一般,阈值是超过10万
- Yearbulit:分布比较合理,但是其是年份信息,需要和售卖时间进行时间差处理,表示建立时长,但是售卖时间作为分类不做处理
- YearRemodAdd: 改建日期,和 Yearbulit 处理方法一致
- BsmtFinSF1和BsmtFinSF2:类型1完工平方英尺和类型2完工平方英尺,先进行“类型1完工平方英尺信息”信息录入,因此在预测中影响不大."类型1完工平方英尺信息"有一个 超过5千的异常值,其评分较高,但是价格较低,过滤掉
- TotalBsmtSF:地下室总面积,有一个异常值,超过6千的,过滤掉 。新增一个字段,计算地下室+一楼+二楼的总面积
- BsmtHalfBath和FullBath:地下室半套浴室数和地面以上全套浴室数,未发现异常,不做处理。新增一个地下室浴室数
- HalfBath:地面以上半套浴室数。新增一个地面以上浴室数和一个全部浴室数
- OpenPorchSF和EnclosedPorch:开放门厅面积和关闭门厅面积,未发现异常,不做处理。新增一个门厅总面积
综合以上为两种处理:异常值过滤和新增部分特征
'异常值过滤'
def drop_pot(data, col, nm):
n1 = 0
for items in data[col]:
if items > nm:
data.drop(index=n1, axis=0, inplace=True)
n1 = n1 + 1
return data
train_data = drop_pot(train_data, 'LotFrontage', 250)
train_data = drop_pot(train_data, 'LotArea', 100000)
train_data = drop_pot(train_data, 'BsmtFinSF1', 5000)
train_data = drop_pot(train_data, 'TotalBsmtSF', 6000)
以下为新增部分特征,包括时间相减和其他指标相加
'时间做差值处理'
def year_diff(data,year1,year2):
year_diff = year1+year2
data[year_diff] = data[year2]-data[year1]
return data
data_all = year_diff(data_all, 'YearBuilt', 'YrSold') # 获取销售时候对应房子的创建年限
data_all = year_diff(data_all, 'YearRemodAdd', 'YrSold') # 获取销售时候对应房子的翻新年限
data_all['all_area'] = data_all['TotalBsmtSF']+data_all['1stFlrSF']+data_all['2ndFlrSF'] #总面积
data_all['basement_bashroom'] = data_all['BsmtFullBath']+data_all['BsmtHalfBath'] # 地下室总浴室数
data_all['garde_bashroom'] = data_all['FullBath']+data_all['HalfBath'] # 地面总浴室数
data_all['bashroom'] = data_all['basement_bashroom']+data_all['garde_bashroom'] # 总浴室数
data_all['Porch'] = data_all['OpenPorchSF']+data_all['EnclosedPorch'] # 门厅总面积
1.2.1.3 特殊数值型转换
年和月份其实是一种分类,其数值大小没有优劣之分,所以先进行字符串转化,最后再进行分类处理
data_all['YrSold'] = data_all['YrSold'].astype(str)
data_all['MoSold'] = data_all['MoSold'].astype(str)
data_all['YearBuilt'] = data_all['YearBuilt'].astype(str)
data_all['YearRemodAdd'] = data_all['YearRemodAdd'].astype(str)
data_all['GarageYrBlt'] = data_all['GarageYrBlt'].astype(str)
data_all['YearBuiltYrSold'] = data_all['YearBuiltYrSold'].astype(str)
1.2.1.4 偏态处理
数值内容,较好的数据分布是正态分布,有利于模型的处理。因此可以利用偏态处理使其为正态分布
- 先获取到数值类型的字段
- 判断偏态值,获取到偏态值大于0.5的字段
- 进行偏态处理,若是还是偏态,判断是否不合适做偏态纠正处理
- 若是由于有非正数,采用加偏移值
- 若是不合适做偏态纠正,不做揪态
success_half=[]
success_all= []
fail=[]
for i in data_all.columns:
if data_all[i].dtype != object and i not in ['BsmtFinSF2', 'LowQualFinSF', 'BsmtHalfBath', 'HalfBath', 'KitchenAbvGr', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal','SalePrice' ]:
if abs(data_all[i].skew())>0.5:
try:
data_all[i], fitted_lambda = stats.boxcox(data_all[i])
success_all.append(i)
except:
data_all[i]=data_all[i]+1
data_all[i], fitted_lambda = stats.boxcox(data_all[i])
success_half.append(i)
if abs(data_all[i].skew())>0.5:
fail.append(i)
print('已揪态:',success_all)
print('偏移+揪态:', success_half)
print('揪态失败:', fail)
1.2.1.5 数据标准化
数据标准化更有利于模型进行数据的理解。数据标准化有多种,以下是采取了最大最小化,将数据限制在[0,1]之间
for i in data_all.columns:
if data_all[i].dtype != object and i not in ['SalePrice','Id']:
data_all[i] = (data_all[i] - data_all[i].min()) / (data_all[i].max() - data_all[i].min())
1.2.2 分类型
1.2.2.1 NA值处理
若有NA值,若属于有业务意义得某种单独分类,可以设定一个特定值,比如None ,若是可以根据其他信息处理,比如通过均值、众数等,也可以进行替换,替换方式需要根据字段的意义结合。
data_all["MSZoning"].fillna(data_all["MSZoning"].mode()[0], inplace=True)
data_all["Alley"].fillna('None', inplace=True)
data_all["Exterior1st"].fillna(data_all["Exterior1st"].mode()[0], inplace=True)
data_all["Exterior2nd"].fillna(data_all["Exterior2nd"].mode()[0], inplace=True)
data_all["MasVnrType"].fillna(data_all["MasVnrType"].mode()[0], inplace=True)
data_all["BsmtQual"].fillna('None', inplace=True)
data_all["BsmtCond"].fillna('None', inplace=True)
data_all["BsmtExposure"].fillna('None', inplace=True)
data_all["BsmtFinType1"].fillna('None', inplace=True)
data_all["BsmtFinType2"].fillna('None', inplace=True)
data_all["Electrical"].fillna(data_all["Electrical"].mode()[0], inplace=True)
data_all["KitchenQual"].fillna(data_all["KitchenQual"].mode()[0], inplace=True)
data_all["Functional"].fillna(data_all["Functional"].mode()[0], inplace=True)
data_all["FireplaceQu"].fillna('None', inplace=True)
data_all["GarageType"].fillna('None', inplace=True)
data_all["GarageFinish"].fillna('None', inplace=True)
data_all["GarageQual"].fillna('None', inplace=True)
data_all["GarageCond"].fillna('None', inplace=True)
data_all["PoolQC"].fillna('None', inplace=True)
data_all["Fence"].fillna('None', inplace=True)
data_all["MiscFeature"].fillna('None', inplace=True)
1.2.2.2 分类改为数值化
分类字段数值化分为两种:1、有优劣之分,需要特定设置大小值;2、无优劣之分,可以通过特定方式进行处理
以下是需要进行特殊处理,带有优劣之分意义的分类。
- ExterQual:外部材料的质量,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1]
- ExterCond:材料的当前条件,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1]
- BsmtQual:地下室高度,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1,NA=0]
- BsmtCond:地下室条件,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1,NA=0]
- BsmtExposure:地下室关照,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1]
- BsmtFinType1和BsmtFinType2:地下室竣工面积等级,有优劣之分,设置[GLQ=6,ALQ=5,BLQ=4,Rec=3,LwQ=2,Unf=1,NA=0]
- CentralAir:中央空调,有优劣之分,设置[Y=1,N=0]
- HeatingQC:加热类型质量,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1]
- Electrical:电路类型,有优劣之分,设置[SBrkr=5,FuseA=4,Mix=3,FuseF=2,FuseP=1]
- KitchenQual:厨房质量,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1]
- Functional:功能型内容,有优劣之分,设置[Typ=8,Min1=7,Min2=6,Mod=5,Maj1=4,Maj2=3,Sev=2,Sal=1]
- FireplaceQu:壁炉质量,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1,NA=0]
- GarageFinish:车库完成度,有优劣之分,设置[Fin=3,RFn=2,Unf=1,NA=0]
- GarageQual:车库质量,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1,NA=0]
- GarageCond:车库条件,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,Po=1,NA=0]
- PavedDrive:驾驶路面情况,有优劣之分,设置[Y=3,P=2,N=1]
- PoolQC:泳池质量,有优劣之分,设置[Ex=5,Gd=4,TA=3,Fa=2,NA=0]
data_all.replace({"ExterQual": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1},
"ExterCond": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1},
"BsmtQual": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1,'NA':0},
"BsmtCond": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1,'NA':0},
"BsmtExposure": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1},
"BsmtFinType1": {'GLQ':6,'ALQ':5,'BLQ':4,'Rec':3,'LwQ':2,'Unf':1,'NA':0},
"BsmtFinType2": {'GLQ':6,'ALQ':5,'BLQ':4,'Rec':3,'LwQ':2,'Unf':1,'NA':0},
"CentralAir": {'Y':2,'N':1},
"HeatingQC": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1},
"Electrical": {'SBrkr':5,'FuseA':4,'Mix':3,'FuseF':2,'FuseP':1},
"KitchenQual": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1},
"Functional": {'Typ':8,'Min1':7,'Min2':6,'Mod':5,'Maj1':4,'Maj2':3,'Sev':2,'Sal':1},
"FireplaceQu": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1,'NA':0},
"GarageFinish":{'Fin':3,'RFn':32,'Unf':1,'NA':0},
"GarageQual": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1,'NA':0},
"GarageCond": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1,'NA':0},
"PavedDrive": {'Y':3,'P':2,'N':1},
"PoolQC": {'Ex':5,'Gd':4,'TA':3,'Fa':2,'Po':1,'NA':0}
},inplace=True)
pandas.factize()方法通过识别不同的值来帮助获得一个数组的数字表示。因此其他分类可以用此来数值化
# 转化datadrame 类型变成 字典类型
column_types = data_all.dtypes.to_dict()
# 转化为数值
for i in data_all.columns:
if data_all[i].dtype == object:
data_all[i] = pd.factorize(data_all[i])[0]
1.2.2.3 多噪音特征过滤
分类字段中,数值集中在一个值里面或者其特征权重很小,会影响模型准确型且加大训练时间。因此将值过于集中和特征重要度较低的过滤。
为了去掉一些噪音,把一些容易导致过拟合的特征去掉,该逻辑的定义为某一个特征的某值占比超过95%。
'若是某列中某个值的占比超过95%'
overfit=[]
for i in data_all.columns:
keys = data_all[i].value_counts()
for keys_key in keys.index:
perce = keys[keys_key]/(2920*1.0000)
if perce>0.9:
overfit.append(i)
print('过拟合:',overfit)
for over in overfit:
data_all = data_all.drop([over], axis=1)
还可以利用决策树的逻辑,剔除掉一些权重较弱的特征。我这次选择的剔除掉基本为0权重的特征。
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(random_state=0)
rf.fit(train_features, train_data['SalePrice'])
print(rf.feature_importances_)
1.2.2.4 其他处理
- 先进行合并数据集拆分为训练集和测试集
- 将价格字段进行正态分布调整,因为线性回归的因变量需要是正态分布
- 提取掉无意义的id和测试集的价格字段
'数据集拆分'
train_data = data_all[(data_all['Id']<=1460)]
test_data = data_all[(data_all['Id']>1460)]
'因变量正态分布'
train_data['SalePrice'], fitted_lambda = stats.boxcox(train_data['SalePrice'])
'拆分过滤'
train_features = train_data.drop(['SalePrice'], axis=1)
train_features = train_features.drop(['Id'], axis=1)
test_all = test_data.drop(['SalePrice'], axis=1)
test_features = test_all.drop(['Id'], axis=1)
二、模型建立
2.1 模型介绍
sklearn 官网:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ElasticNetCV.html

说明:在应用过程中,并非以上模型都需要用到,也并非只限制于以上模型。各位可以根据自己的经验自行选择,再通过模型效果做最后的选择。
2.2 模型参数讲解
中文社区文档:https://scikit-learn.org.cn/
sklearn 英文社区:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.RidgeCV.html
极客教程:https://geek-docs.com/pandas/python-pandas-series/python-pandas-factorize.html
非常推荐使用的文档,对于模型和参数讲解,特别是初学者,简直就是知识天堂!!!!
问答社区:https://stackoverflow.com/
对于初学者来说,但看模型文档描述或者其他应用文章,很难去进行参数调整,从其他人遇到的问题沟通中或许可以给予一定的信息和灵感
2.2.1 线性回归
模型:LinearRegression
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
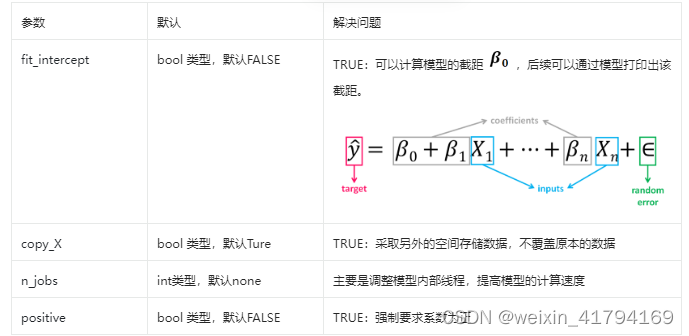
总结:线性回归是一种比较基础的回归方式,无需要进行参数调整,主要是需要对特征进行处理,且由于模型需要,其因变量必须满足正态分布
2.2.2 loss回归
模型:LassoCV
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LassoCV.html
参数:与‘弹性网络’的参数不同的是,Loss回归没有‘l1_ratio’参数。
2.2.3 岭回归
模型:RidgeCV
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.RidgeCV.html
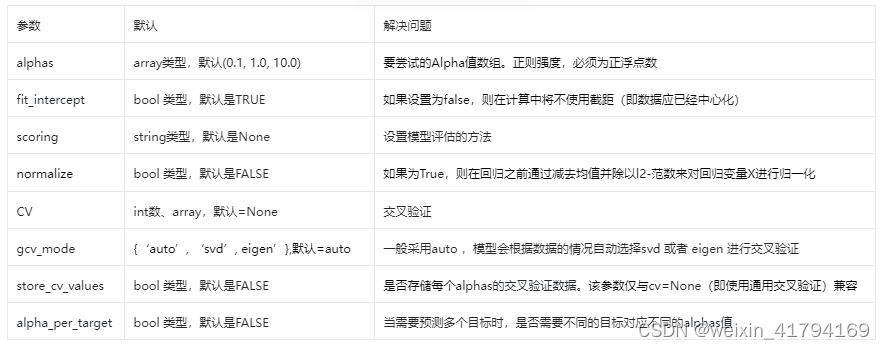
总结:岭回归的惩罚系数是L2范数,其相关值为alphas,因此准确率与alphas有关。数据的分布会影响预测结果,特别若是存在分布不均匀或者异常值,可以通过归一化做处理,为normalize。因此模型中参数需要调整的是alphas和normalize
参数调整逻辑
1)alphas 默认是0,1,10,任意选择0-1、1-10、10到20 进行拆分,继续校验,不断缩短范围,然后设置一个合理的范围
2)由于岭回归本身模型是有进行交叉验证的,因此降低了过拟合的风险
alphas = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas))
2)原数据已有进行正态分布调整,且经过实验,采用归一化的效果不佳,因此normalize不做处理,采用默认值
2.2.4 弹性网络
模型:ElasticNetCV
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ElasticNetCV.html
最小目标函数: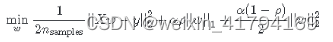
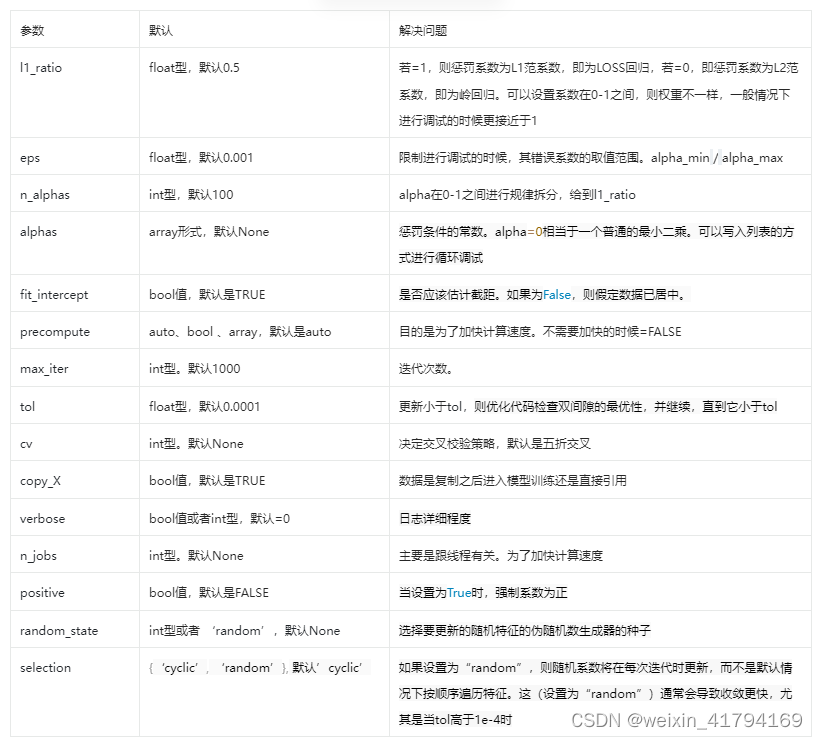
总结:
1)l1_ratio、eps、n_alphas、alphas:主要是限制惩罚系数,调整拟合程度,避免过度拟合或者欠拟合。根据拟合程度,进行参数调整
2)max_iter、tol:调整迭代的步长和次数,若步长较短,则迭代慢,容易陷入局部优,难以找到更优;若步长较长,迭代快,但容易错过较优
3)precompute、n_jobs :主要调整目的是加快计算速度
4)cv:根据多次校验来判断是否过拟合
参数调整逻辑
1)由于从ElasticNetCV、LassoCV、RidgeCV 表现判断,ElasticNetCV并未出现过拟合的情况,因此需要是提高预测的准确率。因此要增加迭代次数、提高惩罚系数、使ElasticNetCV其模型更靠近RidgeCV,因此提高L2范数的权重。所以要调整的参数有l1_ratio、alphas、max_iter
'采用多个入参自动选择最优'
e_alphas = [0.0001, 0.0002, 0.0003, 0.0004, 0.0005, 0.0006, 0.0007]
e_l1ratio = [0.6, 0.7, 0.8, 0.85, 0.9, 0.95, 0.99, 1]
elasticnet = make_pipeline(RobustScaler(), ElasticNetCV(max_iter=10000, l1_ratio=e_l1ratio,alphas=e_alphas))
2)根据以上调参,其方差分值有微量提升,约0.7%
2.2.5 支持向量
说明:该数据中,SVR的效果不佳,所以在最终的训练中不加入该模型进行预测
模型:SVR
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVR.htm

总结:SVR最重要的选择是选择内核类型,而不同的内核类型又会被其他参数影响。因此参数调整重要的比较多,包括kernel、degree、C、gamma、coef0、tol、epsilon。
1)内核类型:由于特征较多,采用‘linear’,‘poly’, ‘rbf’, ‘sigmoid’,‘precomputed’进行尝试
● 采用‘linear’,需要设置参数为C、tol、epsilon
● 采用‘poly’,需要设置参数为C、tol、epsilon、gamma、coef0、degree
● 采用‘rbf’,需要设置参数为C、tol、epsilon、gamma
● 采用‘sigmoid’,需要设置参数为C、tol、epsilon、gamma、coef0
● 采用‘precomputed’,需要设置参数为C、tol、epsilon。因为训练的参数必须是方阵,因此在训练过程或者预测过程需要将特征修正
'precomputed特征修正'
if refer=='precomputed':
print('true')
train_features = np.dot(train_features, train_features.T) # 预计算矩阵必须是方阵,modified the train_set
2)参数调整
- 如果数据间无明显的线性关系,会导致模型无法收敛,所以当迟迟不能收敛,先设置max_iter=1000
- 训练过程中,发现没有明显的平面可以很好划分,因此很难收敛,其分数也较差,其中较好的内核类型=‘rbf’
- C的默认值是1,但是C的变大会提高准确率也会增加过拟合的可能性,所以在此基础上,均衡其问题,选择了C=40
- tol在0.015以下,其效果一致,但是提升其值,准确率也提升不多,因此不做调整,避免过度拟合
- epsilon可以选择0.06或者0.08,但是0.06会存在过拟合程度比较高
- epsilon和gamma 结合,其epsilon=0.06的过拟合比较严重,因此选择epsilon=0.08和gamma=0.00031
'多参数调整验证逻辑'
def last(model,refer,refer1):
# 五折交叉
score = cross_val_score(estimator=model,X=train_features,y=train_data['SalePrice'],cv=5,n_jobs=1)
R1 = np.mean(score)
R3 = np.var(score)
# 训练
model.fit(train_features, train_data['SalePrice']) # 自变量在前,因变量在后
# 训练预测
train_predicts = model.predict(train_features) # 预测值
# 拟合度计算
R2 = model.score(train_features, train_data['SalePrice']) # 拟合程度 R2
print('refer:%s & refer1:%s,五折=%0.5f,R2=%.5f,R3=%.5f'%(refer,refer1,R1,R2,R3))
for refer in ['poly','sigmoid']:
for refer1 in [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1,2,3,4,5,6,7,8,9]:
svr = make_pipeline(RobustScaler(), SVR(kernel=refer,coef0=refer1))
last(xgboost,refer,refer1)
2.2.6 XGBRegressor
模型:LGBMRegressor
官方文档:https://xgboost.readthedocs.io/en/stable/parameter.html
参考文档:https://www.cnblogs.com/yifanrensheng/p/13859327.html



影响效果较多的是:树构建算法、优化目标、惩罚系数、树的深度、迭代步长、训练集的模型
● 树构建算法:tree_method、grow_policy 。因为tree_method=auto会自动根据数据集的大小进行自行选择,所以采用默认即可。grow_policy 的两种分裂方式效果一样,采用默认的。
● 优化目标:objective 和eval_metric 。objective 保持和其他模型的评估方式一致,采用默认reg:squarederror。
● 惩罚系数:gamma、lambda 、alpha 。随着gamma变大,其精确效果较差,所以选择gamma=0。默认reg_lambda=1存在过拟合的情况,因此在进行实验过程中,需要注意数据的稳定性,可以采用五折交叉校验,因此在0.9-0.99之间进行处理,最终选中0.95。alpha 默认=0,数值提高一般情况下是更加欠拟合,所以不需要担心过拟合,只需要找到拟合效果比较好的,由于起始点在0,因此在0附近寻找最优质,通过0-0.001,0-0.01,0.1拆分最终选中0.0002。
● 树的深度:min_child_weight、max_depth、max_leaves 。min_child_weight=1不做设置,max_depth=6中,通过5-10之间进行测试,发现6的拟合度和稳定性是相对较好,所以采用默认值,max_leaves 不进行设置。
● 迭代步长:learning_rate。通过0.1-0.5之间,0.05到0.15之间,0.25-0.35进行尝试,在稳定性和拟合度中选择较好的0.07
● 训练集的模型:subsample、sampling_method 、colsample_bytree、n_estimators、colsample_bylevel、colsample_bynode 。本身特征数和训练集不多,因此不做筛选。迭代次数可以提高准确率,调整为1000
xgboost = XGBRegressor(tree_method='auto', grow_policy='depthwise', objective='reg:squarederror', gamma=0.01,reg_lambda=0.95,alpha=0.0002,learning_rate=0.07,n_estimators=1000)
2.2.7 LGBMRegressor
模型:LGBMRegressor
官方文档:https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMRegressor.html
https://lightgbm.readthedocs.io/en/latest/Parameters.html

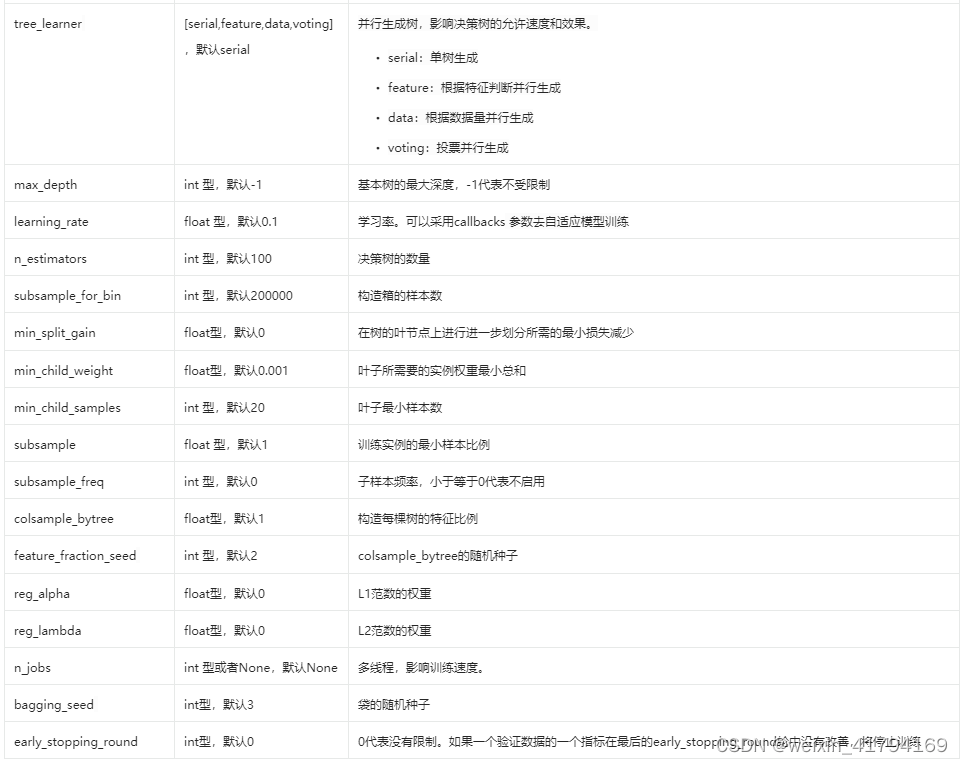
影响效果较多的是:树构建算法、优化目标、惩罚系数、树的深度、迭代步长、训练集的模型
树构建算法:boosting_type、tree_learner
优化目标:objective
惩罚系数:reg_alpha、reg_lambda
树的深度:num_iterations 、num_leaves、max_depth、n_estimators、
迭代步长:learning_rate、early_stopping_round
训练集的模型:data_sample_strategy 、min_split_gain、min_child_weight、min_child_samples、subsample、subsample_freq、bagging_seed
由于参数的选择逻辑和其他模型的方法是一致的,本内容不再赘叙,最终的参数选择如下
lightgbm = LGBMRegressor(objective='regression',num_leaves = 6,learning_rate = 0.01,n_estimators = 5000,max_bin = 200,bagging_fraction = 0.75,bagging_freq = 5,bagging_seed = 7,feature_fraction = 0.2,feature_fraction_seed = 7,verbose = -1)
2.2.8 GradientBoostingRegressor
模型:GradientBoostingRegressor
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html
中文社区:https://scikit-learn.org.cn/view/629.html


由于参数的选择逻辑和其他模型的方法是一致的,本内容不再赘叙,最终的参数选择如下
gbr = GradientBoostingRegressor(n_estimators=1000, learning_rate=0.01, max_depth=4, max_features='sqrt',min_samples_leaf=15, min_samples_split=10, loss='huber', random_state=42)
2.2.9 StackingCVRegressor
主要是选择多个基回归模型和1个元回归模型,以上的模型中一共有8个模型,我主要选择了表现相对较好的几个模型作为基回归,最好的模型作为元模型。
stack_gen = StackingCVRegressor(regressors=(lr,elasticnet, gbr, xgboost, lightgbm),meta_regressor=gbr,
use_features_in_secondary=True)
三、额外信息
3.1 强制正态分布
前提:线性回归其因变量需要满足正态分布
现状:价格分布是偏右态分布,需要进行分布转换
sns.displot(data_test0['SalePrice'],color='y')
plt.show() # 偏右态分布
print("原始偏态:",data_test0['SalePrice'].skew()) # 偏度为1.88
'采用boxcox 处理高度正偏'
data_test0['SalePrice'],fitted_lambda = stats.boxcox(data_test0['SalePrice'])
sns.displot(data_test0['SalePrice'],color='y')
plt.show() # 正态分布
print("处理偏态:",fitted_lambda) # 偏度为-0.077
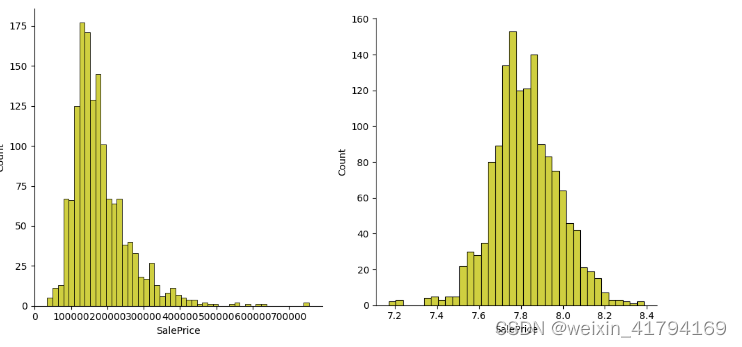
内容讲解
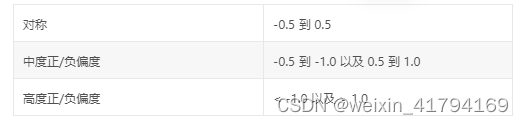
1)在数据挖掘中,往往会假设特征或者预测值都是正态分布的,但是正常情况下非如此理想。若是对应的字段是偏态分布,无论是中度、高度还是偏左偏右,都可以通过’Box-Cox’变换进行处理
'采用对数处理高度正偏'
data_test2 = np.log(data_test0['SalePrice'])
print("高度正偏处理:",data_test2.skew()) # 偏度为0.12
'采用boxcox 处理高度正偏'
data_test0['SalePrice'],fitted_lambda = stats.boxcox(data_test0['SalePrice'])
print("处理偏态:",fitted_lambda) # 偏度为-0.077
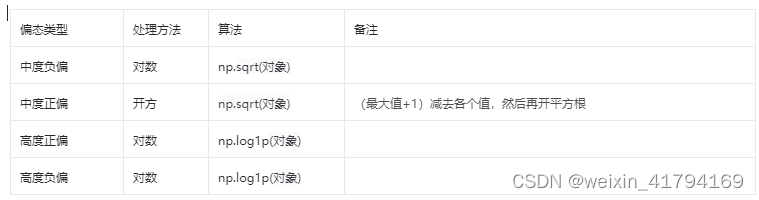
3)由于过程中采用了修正,最终的效果需要还原
predicts = inv_boxcox(predicts, fitted_lambda)
3.2 参数选择和调试
参数调整过程:根据拟合度和稳定性,选出相对较好的参数值
第一步:参数选择需要先确定测试结果是过拟合还是欠拟合。
- 若是过拟合,先选择稳定性较好的几个参数,再从中选择准确度较高的
- 若是欠拟合,主要关注精确度较高的
第二步:一般情况下默认的值都是经过检验,效果相对比较好的,可以在此附近进行调整
第三步:根据目的,计算出稳定性指标和准确度指标
- 稳定性指标:五折交叉校验的分数方差,判断不同校验的准确度差距
- 准确度指标:五折交叉校验的均方差分值和总训练集的分值
def last(model,refer):
# 五折交叉
score = cross_val_score(estimator=model,X=train_features,y=train_data['SalePrice'],cv=5,n_jobs=1)
R1 = np.mean(score)
# 训练
model.fit(train_features, train_data['SalePrice']) # 自变量在前,因变量在后
# 训练预测
train_predicts = model.predict(train_features) # 预测值
# 拟合度计算
R2 = model.score(train_features, train_data['SalePrice']) # 拟合程度 R2
print('refer:%s,五折=%0.5f,R2=%.5f'%(refer,R1,R2))
'reg_lambda的参数调整'
for refer in [0.8,0.9,0.95,0.96,0.97,0.98,0.99]:
xgboost = XGBRegressor(tree_method='auto', grow_policy='depthwise', objective='reg:squarederror', gamma=0.01,
reg_lambda=refer, )
last(xgboost,refer)
3.3 模型训练和结果存储
最终模型的训练代码如下
def last(model):
# 训练
model.fit(train_features, train_data['SalePrice']) # 自变量在前,因变量在后
# 训练预测
train_predicts = model.predict(train_features) # 预测值
print('11111:', model)
# 拟合度计算
R2 = model.score(train_features, train_data['SalePrice']) # 拟合程度 R2
print('R2 = %.5f' % R2) # 输出 R2
# 获取到处理好的测试特征
# 引用现有的模型进行预测
predicts = model.predict(test_features) # 预测值
# 预测价格还原
predicts = inv_boxcox(predicts, fitted_lambda)
return predicts
预测之后进行文档存储
test_all['predicts_original'] =last(stack_gen)
# 预测结果进行excel存储
result = pd.DataFrame()
result['Id'] = test_all['Id']
result['SalePrice'] = test_all['predicts_original']
result.to_csv("E:/QBN/analyse/kaggle/House_price_test.csv", index=False)














 1959
1959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









