







目录
原文内容概要
1)首先作者介绍了本书所用到的若干个用于实验的数据集,包括但不限于工资数据集(Wage Data)、股票数据集(Stock Market Data)、基因序列数据集(Gene Expression Data)等,在介绍这些数据集的时候,巧妙引出了很多统计学(或机器学习)领域重要的概念,如:输入变量(input)、输出变量(output)、连续值(continuous or quantitative output)、离散值(categorical or qualitative output)、监督(supervised)、非监督(supervised)、回归问题(regression problem)、分类问题(classification problem)、聚类问题(clustering problem)、主成分(principal components)等。这些概念我会在后面章节的读书笔记中详细讲解,这里就不先赘述了。
2)接着作者简要介绍了统计学的历史:
- 在19世纪前叶,最小二乘法(least squares)得以发展,实现了现在所称的线性回归(linear regression)的最早形式,其最早成功运用在了天文学领域(astronomy)。
- 但线性回归有个局限性,就是它只能输出连续值,而有些现实问题只能用离散值来表示,比如股票的涨跌等,所以统计学家在1936年发明了线性判别分析(linear discriminant analysis)来解决这个问题。
- 在1940年代,逻辑回归(logistic regression)开始在统计学中崭露头角,逐渐替代了线性判别分析。
- 在1970年代,为了统一种类繁多的线性模型,统计学家又提出了广义线性模型(generalized linear model)。许多广泛应用的统计模型均属于广义线性模型,如logistic回归模型、Probit回归模型、Poisson回归模型、负二项回归模型等。
- 当目前为止,上述方法展现出明显的进步趋势,但却始终局限在了线性领域(linear)。主要原因在于非线性模型的计算量难以控制,而当时的计算机算力无法满足其需求。
- 但到了1980年代,计算机得到飞速发展,算力不再是问题,这个时候,非线性(non-linear)的方法就开始出现了。在1980年中叶,树模型(classification and regression trees)被发明出来,紧随其后的是广义加性模型(generalized additive models),后来神经网络(Neural networks)也大受追捧。到了1990年代,支持向量机(support vector machines)又诞生了。
- 随着时间的推移,这些方法被集成到了强大的统计软件中,如R语言和Python等,这些软件不仅功能强大,而且易于使用,使得这些优秀的统计学方法得以广泛应用于其他领域。
3)然后作者介绍了这边书的定位。相较于晦涩难懂的《统计学习方法元素》(The Elements of Statistical Learning (ESL)),本书更通俗易懂,抛弃了多余的技术细节,更适合非统计专业的人学习。作者总结了写这本书的四大初衷:
- 许多统计学习方法不仅在统计学领域中具有重要性和实用性,而且在更广泛的学术和非学术领域中同样适用。(Many statistical learning methods are relevant and useful in a wide range of academic and non-academic disciplines, beyond just the statistical sciences)
- 不应该将统计学习视为一系列黑箱。(意思是我们应该对常用的统计方法做更多的了解,不能仅仅停留表面)。(Statistical learning should not be viewed as a series of black boxes)
- 虽然了解每个“齿轮”的工作非常重要(意思是那些统计方法的技术细节),但并不需要具备在盒子里建造机器的技能(意思是不需要你从0到1自己落地这些统计方法,因为已经有很多现成的工具了)。(While it is important to know what job is performed by each cog, it is not necessary to have the skills to construct the machine inside the box)
- 我们认为,读者希望将统计学习方法应用到解决实际问题上。(We presume that the reader is interested in applying statistical learning methods to real-world problems)
4)之后作者介绍了这本书的受众群体。任何对统计学习或者机器学习感兴趣的,并乐于在数据领域实践的人都是这本书的受众(This book is intended for anyone who is interested in using modern statistical methods for modeling and prediction from data)。为了能更好地理解这本书,作者希望读者应该具有基本的统计学知识。这本书已经作为很多大学在教授商科、经济学、计算机科学、生物学等专业的研究生和博士生的教材(The first edition of this textbook has been used to teach master’s and PhD students in business, economics, computer science, biology, earth sciences, psychology, and many other areas of the physical and social sciences)。
5)随后作者简要介绍了本书的符号系统和简单的线性代数知识(Notation and Simple Matrix Algebra),这里我就不重复了,我帮大家理解了。
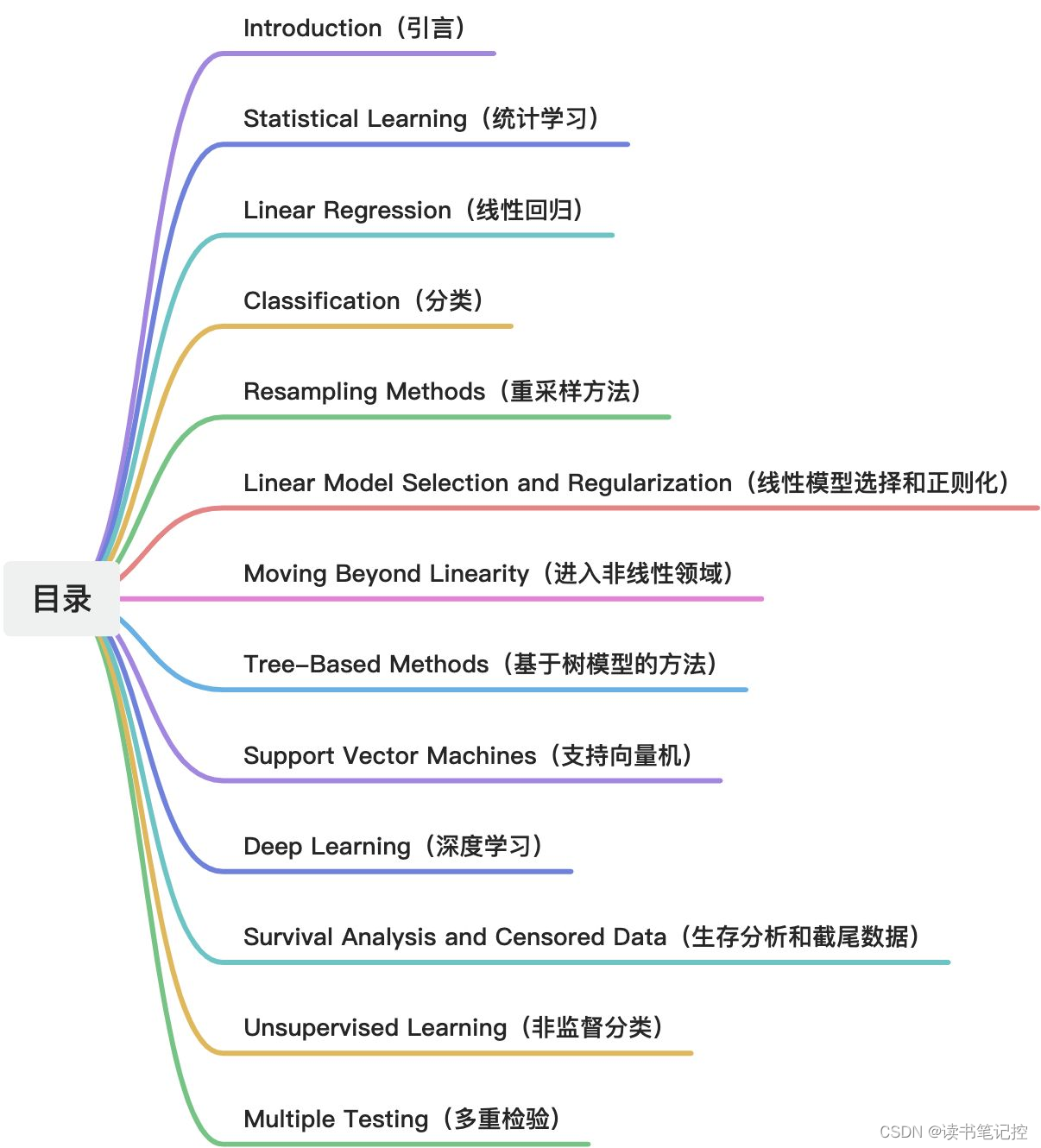
6)最后作者讲了本书的结构,其实就是把目录再说一遍,然后告诉大家,www.statlearning.com,去这个网站可以免费下载本书的PDF。本书目录如下:
英语语句积累
挑了一些长难句以及我觉得写得有意思的语句给大家做讲解。
1)Statistical learning refers to a vast set of tools for understanding data, which can be classified as supervised or unsupervised.
首先提炼出句子的主干:
Statistical learning(主语)+ refers(谓语),使用了第三人称单数的一般现在时,陈述事实。
再来对其他成分进行分析:
- to a vast set of tools for understanding data 是介词短语作状语,作为refers的补足语,表示“一系列理解数据的工具”;
- which can be classified as supervised or unsuper
- vised 是非限制性定语从句,修饰先行词tools,表示“这些工具可以被分类为有监督或无监督”。
最后再总结下这句话的意思:
统计学习指的是一系列理解数据的工具,这些工具可以被分类为有监督或无监督。
2)But for this audience, many of the technical details behind statistical learning methods, such as optimization algorithms and theoretical properties, are not of primary interest.
首先提炼出句子的主干:
Many of the technical details(主语)+ are(系动词)+ not(表语),使用了被动语态的一般现在时,陈述事实。
再来对其他成分进行分析:
- But for this audience 是介词短语作状语,表示“但对于这个受众来说”;
- behind statistical learning methods 是介词短语作后置定语,修饰主语the technical details,表示“统计学习方法的背后”;
- such as optimization algorithms and theoretical properties 是介词短语作定语,修饰the technical details,表示“优化算法和理论属性等”。
最后再总结下这句话的意思:
对于这个受众来说,统计学习方法背后的许多技术细节,如优化算法和理论属性等,并不是首要关注的点。
3)At the beginning of the nineteenth century, the method of least squares was developed, implementing the earliest form of what is now known as linear regression.
首先提炼出句子的主干:
The method of least squares(主语)+ was developed(谓语),使用了被动语态的一般过去时,陈述事实。
再来对其他成分进行分析:
- At the beginning of the nineteenth century 是介词短语作状语,修饰谓语was developed,表示“在19世纪初”;
- implementing the earliest form of what is now known as linear regression 是现在分词短语作状语,作为伴随状语,表示“实施了现在被称为线性回归的最早形式”。
最后再总结下这句话的意思:
在19世纪初,最小二乘法得以发展,实施了现在被称为线性回归的最早形式。
4)Many statistical learning methods are relevant and useful in a wide range of academic and non-academic disciplines, beyond just the statistical sciences.
首先提炼出句子的主干:
Many statistical learning methods(主语)+ are(系动词)+ relevant and useful(表语),使用了被动语态的一般现在时,陈述事实。
再来对其他成分进行分析:
- in a wide range of academic and non-academic disciplines 是介词短语作状语,表示“在广泛的学术和非学术领域”;
- beyond just the statistical sciences 是介词短语作状语,表示“不仅仅是统计科学领域”。
最后再总结下这句话的意思:
许多统计学习方法在广泛的学术和非学术领域都是相关和有用的,而不仅仅是统计科学领域。
5)Statistical learning should not be viewed as a series of black boxes
首先提炼出句子的主干:
Statistical learning(主语)+ should not be viewed(谓语),使用了被动语态的一般现在时,表示“统计学习不应该被视为”。
再来对其他成分进行分析:
- as a series of black boxes 是介词短语作状语,作为should not be viewed的补足语,表示“一系列黑盒子”。
最后再总结下这句话的意思:
统计学习不应该被视为一系列的黑盒子。
6)While it is important to know what job is performed by each cog, it is not necessary to have the skills to construct the machine inside the box!
首先,我们解析句子的结构:
这是一个并列句,由并列连词while进行连接。
第一部分:While it is important to know what job is performed by each cog。
- 主干是:it(主语)+ is(系动词)+ important(表语),使用了一般现在时,表示“它是重要的”;
- to know what job is performed by each cog 是不定式短语作形容词的补足语,表示“知道每个齿轮执行什么工作是重要的”;
- While 是从属连词,表示“虽然”,引导让步状语从句。
第二部分:it is not necessary to have the skills to construct the machine inside the box。
- 主干是:it(主语)+ is not(系动词)+ necessary(表语),使用了一般现在时,表示“它不是必要的”;
- to have the skills to construct the machine inside the box 是不定式短语作形容词的补足语,表示“拥有构建箱子内部机器的技能不是必要的”。
最后再总结下这句话的意思:
虽然了解每个齿轮所执行的工作是重要的,但拥有构建箱子内部机器的技能并不是必需的。
7)We presume that the reader is interested in applying statistical learning methods to real-world problems.
首先提炼出句子的主干:
We(主语)+ presume(谓语),使用了第一人称复数的一般现在时,陈述事实。
再来对其他成分进行分析:
- that the reader is interested in applying statistical learning methods to real-world problems 是宾语从句,作为presume的宾语,使用了现在时的一般现在时,陈述事实,表示“读者对将统计学习方法应用于现实世界的问题感兴趣”。
最后再总结下这句话的意思:
我们假设读者对将统计学习方法应用于现实世界的问题感兴趣。
8)The first edition of this textbook has been used to teach master’s and PhD students in business, economics, computer science, biology, earth sciences, psychology, and many other areas of the physical and social sciences.
首先提炼出句子的主干:
The first edition of this textbook(主语)+ has been used(谓语),使用了被动语态的一般现在完成时,陈述事实。
再来对其他成分进行分析:
- to teach master’s and PhD students in business, economics, computer science, biology, earth sciences, psychology, and many other areas of the physical and social sciences 是目的状语,表示“用于教授商业、经济学、计算机科学、生物学、地球科学、心理学以及许多其他物理和社会科学领域的硕士和博士生”。
最后再总结下这句话的意思:
这本教科书的初版已经用于教授商业、经济学、计算机科学、生物学、地球科学、心理学以及许多其他物理和社会科学领域的硕士和博士生。
引用
















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









