







最近在学习《尚硅谷大数据技术之Spark3.x性能优化》,这系列文章是学习笔记结合本人的学习感想。
本章结主要讲了Explain 查看执行计划、资源调优、SparkSQL语法优化。
文章目录
前置信息
本文全部资源来源于《尚硅谷大数据技术之Spark3.x性能优化》和本人的学习感想,感兴趣的朋友可以去尚硅谷公众号获取资料学习。
Explain 查看执行计划
.explain(mode="xxx")使用这个可以查看执行计划
explain(mode="simple"):只展示物理执行计划。explain(mode="extended"):展示物理执行计划和逻辑执行计划。explain(mode="codegen"):展示要 Codegen 生成的可执行 Java 代码explain(mode="cost"):展示优化后的逻辑执行计划以及相关的统计。explain(mode="formatted"):以分隔的方式输出,它会输出更易读的物理执行计划,
并展示每个节点的详细信息。
资源调优
资源规划
资源设定考虑
总体原则
以单台服务器 128G 内存,32 线程为例。
先设定单个 Executor 核数,根据 Yarn 配置得出每个节点最多的 Executor 数量,每个节点的 yarn 内存/每个节点数量=单个节点的数量
总的 executor 数=单节点数量*节点数。
具体提交参数
-
executor-cores
每个 executor 的最大核数。根据经验实践,设定在 3~6 之间比较合理。 -
num-executors
该参数值=每个节点的 executor 数 * work 节点数每个 node 的 executor 数 = 单节点 yarn 总核数 / 每个 executor 的最大 cpu 核数
考虑到系统基础服务和 HDFS 等组件的余量,yarn.nodemanager.resource.cpu-vcores 配置为:28,参数 executor-cores 的值为:4,那么每个 node 的 executor 数 = 28/4 = 7,假设集
群节点为 10,那么 num-executors = 7 * 10 = 70 -
executor-memory
该参数值=yarn-nodemanager.resource.memory-mb / 每个节点的 executor 数量
如果 yarn 的参数配置为 100G,那么每个 Executor 大概就是 100G/7≈14G,同时要注意
yarn 配置中每个容器允许的最大内存是否匹配。
内存估算
在堆内内存中,一共有三大块内存,分别是Storage内存、Executor内存以及Other内存。
Storage内存:广播变量+cache/Executor数量
Executor内存:每个Executor核数*(数据集大小/并行度)。设Executor占用4个核,一个数据集有100G,然后shuffle默认有200个并行度,那么每个task就要占500Mb内存,Executor内存就占有2G的内存!
Other内存:自定义数据结构*每个Executor核数
调整内存配置项
一般情况下,各个区域的内存比例保持默认值即可。如果需要更加精确的控制内存分配,可以按照如下思路:
spark.memory.fraction=(估算 storage 内存+估算 Execution 内存)/(估算 storage 内存 +估算 Execution 内存+估算 Other 内存)得到spark.memory.storageFraction = ( 估 算 storage 内 存 ) / ( 估 算 storage 内 存 + 估 算Execution 内存)
代入公式计算:
Storage 堆内内存=(spark.executor.memory–300MB)*spark.memory.fraction*spark.memory.storageFraction
Execution 堆内内存=(spark.executor.memory–300MB)*spark.memory.fraction*(1-spark.memory.storageFraction)
持久化和序列化
RDD
cache
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("RddCacheDemo")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
val result = sparkSession.sql("select * from sparktuning.course_pay").rdd
result.cache()
result.foreachPartition(( p: Iterator[Row] ) => p.foreach(item => println(item.get(0))))
while (true) {
//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束
}
}
打成jar包执行以下命令
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.cache.RddCacheDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
上面的命令中driver为1g,总共executors数为3,每个excutor核为2,每个executor内存为6g。这里设置executor内存的时候要注意,这个 数值是需要比yarn配置中的nodemanager和容器上限小的。
根据内存结构图可以看到,估算出executor中的Storage内存+Executor内存=6g * 60 % = 3g左右
然后打开SPARK WEB UI查看,验证是否单纯使用内存cache是否能缓存成功

DataFrame和DataSet
kryo+序列化缓存:使用kryo序列化并且使用rdd序列化缓存级别,可以看到内存只占用了1083.6Mb,而且还成功cache
使用Dataset的缓存:cache的默认级别是MEMORY_AND_DISK:内存仅占612.3mb
使用Dataset的序列化:有自己的序列化器,不需要kyro:内存仅占646.2mb
所以直接默认使用Dataset的默认级别的cache即可,开发的过程中建议使用Dataset和Dataframe
CPU优化
CPU低效原因
概念理解
-
并行度
-
spark.default.parallelism:
设置RDD的默认并行度,没有设置时,由join、reduceByKey 和 parallelize 等转换决定
-
spark.sql.shuffle.partitions:
适用 SparkSQL 时,Shuffle Reduce 阶段默认的并行度,默认200。此参数只能控制Spark sql、DataFrame、DataSet 分区个数。不能控制 RDD 分区个数
-
-
CPU低效原因
- 并行度较低、数据分片较大容易导致CPU线程挂起。比如两个Task同时跑,需要占用的内存较大,因此内存资源不够时,就只能允许并发为1的一个Task任务跑,就会造成CPU低效。
- 并行度过高、数据过于分散会让调度开销更多
合理利用CPU资源
每个并行度的数据量(总数据量/并行度) 在(Executor 内存/core 数/2, Executor 内存/core 数)区间
去向 yarn 申请的 executor vcore 资源个数为 12 个(num-executors*executor-cores),如果不修改 spark sql 分区个数,那么就会存在 cpu 空转的情况。这个时候需要合理控制 shuffle 分区个数。如果想要让任务运行的最快当然是一个 task 对应一个 vcore,但是一般不会这样设置,为了合理利用资源,一般会将**并行度(task 数)设置成并发度(vcore 数)**的 2 倍到 3 倍
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("PartitionDemo")
.set("spark.sql.autoBroadcastJoinThreshold", "-1")//为了演示效果,先禁用了广播join
// .setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select * from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse
.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
// .coalesce(6)
// .repartition(6)
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).saveAsTable("sparktuning.salecourse_detail")
}
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 6g --class com.atguigu.sparktuning.partition.PartitionDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
- driver的内存为1g
- executors数量为3
- executor核为4
- executor-memory内存为6g
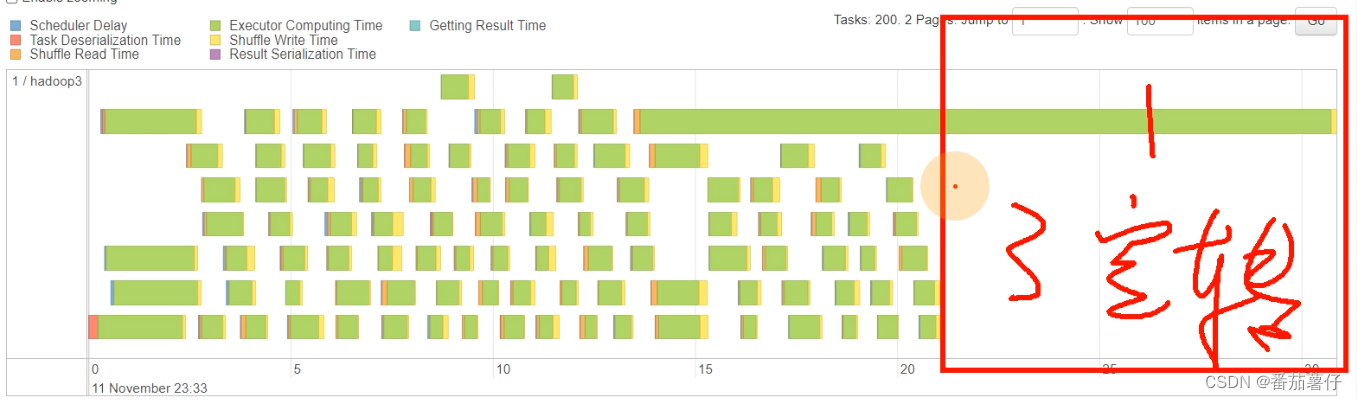
上面的任务可以看到,有的stage是200个task的,这就是默认的shuffle partition数量。而且红框框里面的内容显示,其中有一个task执行的时间特别长,就是在空转。
优化
为了将并行度调成并发度的2-3倍。首先看sparks-submit里面的参数,计算出并发度为12,那么并行度就可以修改为36。在程序中修改.set("spark.sql.shuffle.partitions", "36")。
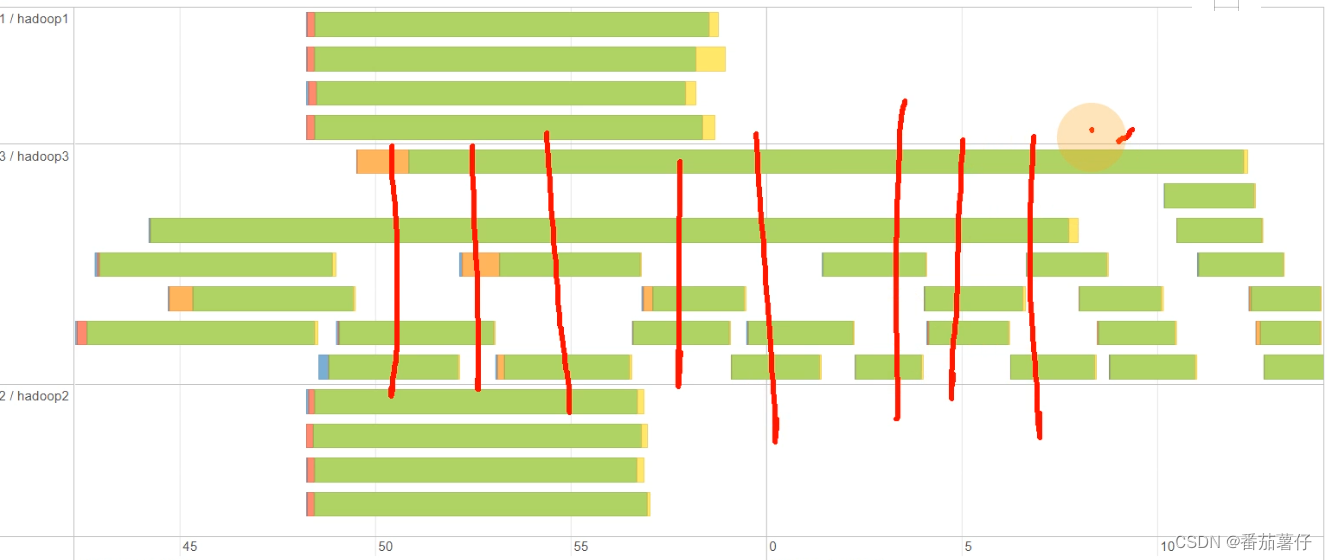
这个图分析到:空闲的位置是其他任务再跑,而中间画竖线的位置可以看到cpu基本每个时段都有4个核在跑,说明资源是没有太大浪费的。
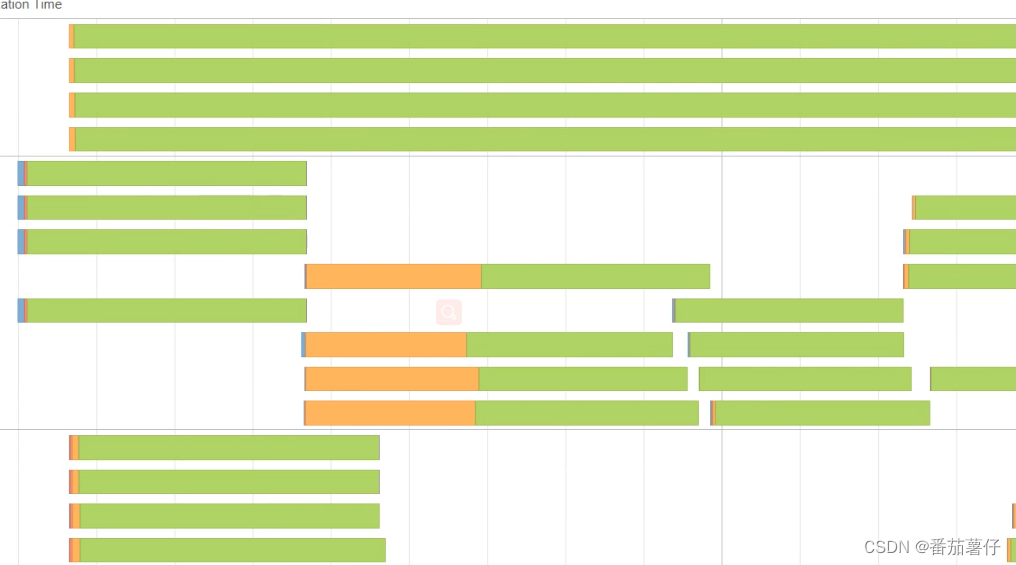
这个图看到每个executor运行的时长都是很均匀的。也说明CPU没有浪费!
SparkSQL语法优化
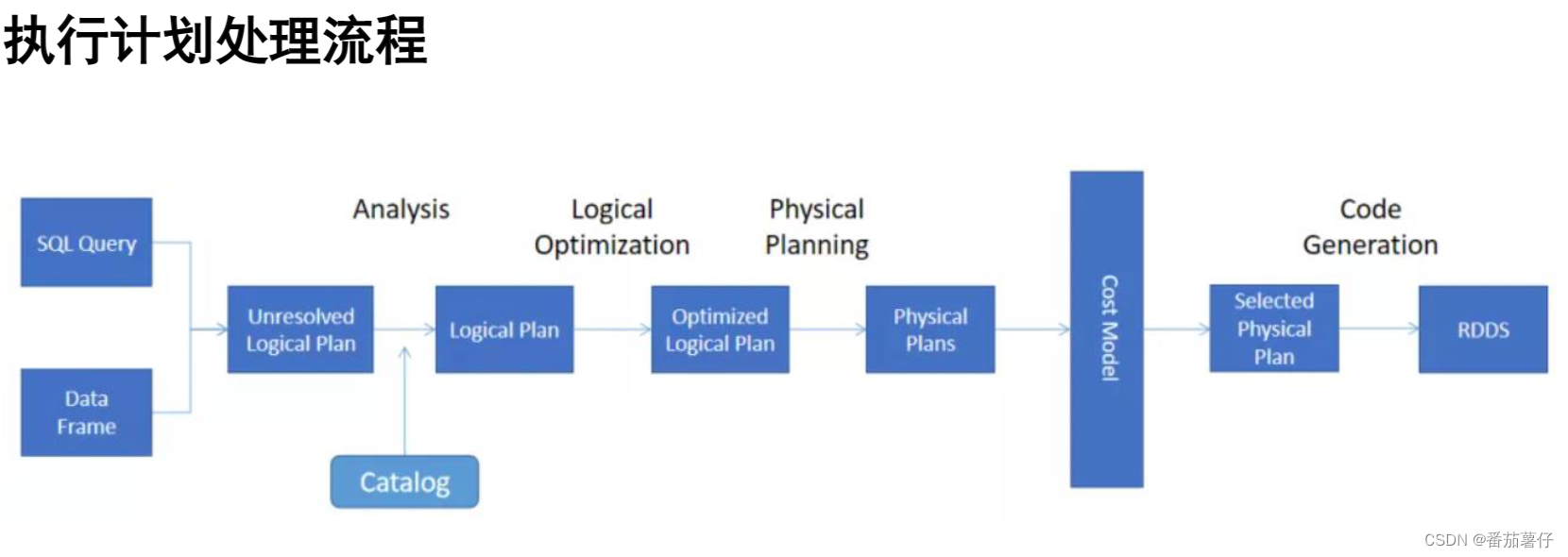
SparkSQL 在整个执行计划处理的过程中,使用了 Catalyst 优化器。
基于RBO的优化
在 Spark 3.0 版本中,Catalyst 总共有 81 条优化规则(Rules),分成 27 组(Batches),其中有些规则会被归类到多个分组里。因此,如果不考虑规则的重复性,27 组算下来总共会有 129 个优化规则。
如果从优化效果的角度出发,这些规则可以归纳到以下 3 个范畴:
谓词下推(Predicate Pushdown)
将 过 滤 条 件 的 谓 词 逻 辑 都 尽 可 能 提 前 执 行 , 减 少 下 游 处 理 的 数 据 量 。 对 应PushDownPredicte 优化规则,对于 Parquet、ORC 这类存储格式,结合文件注脚(Footer)中的统计信息,下推的谓词能够大幅减少数据扫描量,降低磁盘 I/O 开销。
inner join
- 在inner join中使用条件on,spark sql会两张表都过滤掉,再进行join
- 在where中,会两张表都下推
outer join
-
左外关联下推规则:左表 left join 右表
这时候会先提前过滤右表,然后再join
左表 右表 Join 中条件(on) 只下推右表 只下推右表 Join 后条件(where) 两表都下推 两表都下推 -
where,会两张表都下推
列裁剪(Column Pruning)
列剪裁就是扫描数据源的时候,只读取那些与查询相关的字段
常量替换
假设我们在年龄上加的过滤条件是 “age < 12 + 18”,Catalyst 会使用 ConstantFolding规则,自动帮我们把条件变成 “age < 30”。再比如,我们在 select 语句中,掺杂了一些常量表达式,Catalyst 也会自动地用表达式的结果进行替换。
基于CBO的优化
CBO 优化主要在物理计划层面,原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划。
而每个执行节点的代价,分为两个部分:
- 该执行节点对数据集的影响,即该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:
- 初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到;
- 中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
Statistics 收集
需要先执行特定的 SQL 语句来收集所需的表和列的统计信息。
使用CBO
通过 spark.sql.cbo.enabled 来开启,默认是 false。配置开启 CBO 后,CBO 优化器可以基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。比如:Build 侧选择、优化 Join 类型、优化多表 Join 顺序等。
广播join
Spark join 策略中,如果当一张小表足够小并且可以先缓存到内存中,那么可以使用Broadcast Hash Join,其原理就是先将小表聚合到 driver 端,再广播到各个大表分区中,那么再次进行 join 的时候,就相当于大表的各自分区的数据与小表进行本地 join,从而规避了shuffle。
-
广播Join默认值为10MB,由
spark.sql.autoBroadcastJoinThreshold参数控制val sqlstr = """ |select | sc.courseid, | csc.courseid |from sale_course sc join course_shopping_cart csc |on sc.courseid=csc.courseid """.stripMargin在广播开启前后,这条sql从10s运行时间减少到2s,在SPARK WEB UI可以看到,DAG 里面不显示shuffle了,可想而知,shuffle的减少非常有效果。
-
强行广播:比如以下形式Hint模式都可以广播
val sqlstr1 = """ |select /*+ BROADCASTJOIN(sc) */ | sc.courseid, | csc.courseid |from sale_course sc join course_shopping_cart csc |on sc.courseid=csc.courseid """.stripMargin val sqlstr2 = """ |select /*+ BROADCAST(sc) */ | sc.courseid, | csc.courseid |from sale_course sc join course_shopping_cart csc |on sc.courseid=csc.courseid """.stripMargin val sqlstr3 = """ |select /*+ MAPJOIN(sc) */ | sc.courseid, | csc.courseid |from sale_course sc join course_shopping_cart csc |on sc.courseid=csc.courseid """.stripMargin
SMB Join(两张大表join的时候使用)
SMB JOIN 是 sort merge bucket 操作,需要进行分桶,首先会进行排序,然后根据 key值合并,把相同 key 的数据放到同一个 bucket 中(按照 key 进行 hash)。分桶的目的其实就是把大表化成小表。相同 key 的数据都在同一个桶中之后,再进行 join 操作,那么在联合的时候就会大幅度的减小无关项的扫描。
使用条件是:
- 两表进行分桶,桶的个数必须相等
- 两边进行 join 时,join 列=排序列=分桶列
初始化分桶表
def initBucketTable( sparkSession: SparkSession ): Unit = {
sparkSession.read.json("/sparkdata/coursepay.log")
.write.partitionBy("dt", "dn")
.format("parquet")
.bucketBy(5, "orderid")
.sortBy("orderid")
.mode(SaveMode.Overwrite)
.saveAsTable("sparktuning.course_pay_cluster")
sparkSession.read.json("/sparkdata/courseshoppingcart.log")
.write.partitionBy("dt", "dn")
.bucketBy(5, "orderid")
.format("parquet")
.sortBy("orderid")
.mode(SaveMode.Overwrite)
.saveAsTable("sparktuning.course_shopping_cart_cluster")
}
在上面可以看到使用了orderId进行分桶,分桶数为5,然后保存两张分桶表course_pay_cluster以及course_shopping_cart_cluster。
非分桶表
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("BigJoinDemo")
.set("spark.sql.shuffle.partitions", "36")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
useJoin(sparkSession)
}
def useJoin( sparkSession: SparkSession ) = {
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select *from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select *from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
courseShoppingCart
.join(coursePay, Seq("orderid"), "left")
.join(saleCourse, Seq("courseid"), "right")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "sparktuning.sale_course.dt", "sparktuning.sale_course.dn")
.write.mode(SaveMode.Overwrite).saveAsTable("sparktuning.salecourse_detail_1")
}
这里可以看到非分桶表,除此之外与限免的程序没啥区别
分桶表使用
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("SMBJoinTuning")
.set("spark.sql.shuffle.partitions", "36")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
useSMBJoin(sparkSession)
}
def useSMBJoin( sparkSession: SparkSession ) = {
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select *from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay_cluster")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select *from sparktuning.course_shopping_cart_cluster")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
val tmpdata = courseShoppingCart.join(coursePay, Seq("orderid"), "left")
val result = broadcast(saleCourse).join(tmpdata, Seq("courseid"), "right")
result
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "sparktuning.sale_course.dt", "sparktuning.sale_course.dn")
.write
.mode(SaveMode.Overwrite)
.saveAsTable("sparktuning.salecourse_detail_2")
}
在这里使用分桶对两张大表进行join: val tmpdata = courseShoppingCart.join(coursePay, Seq("orderid"), "left"),join完大表之后才join小表。
结果对比
- 优化前
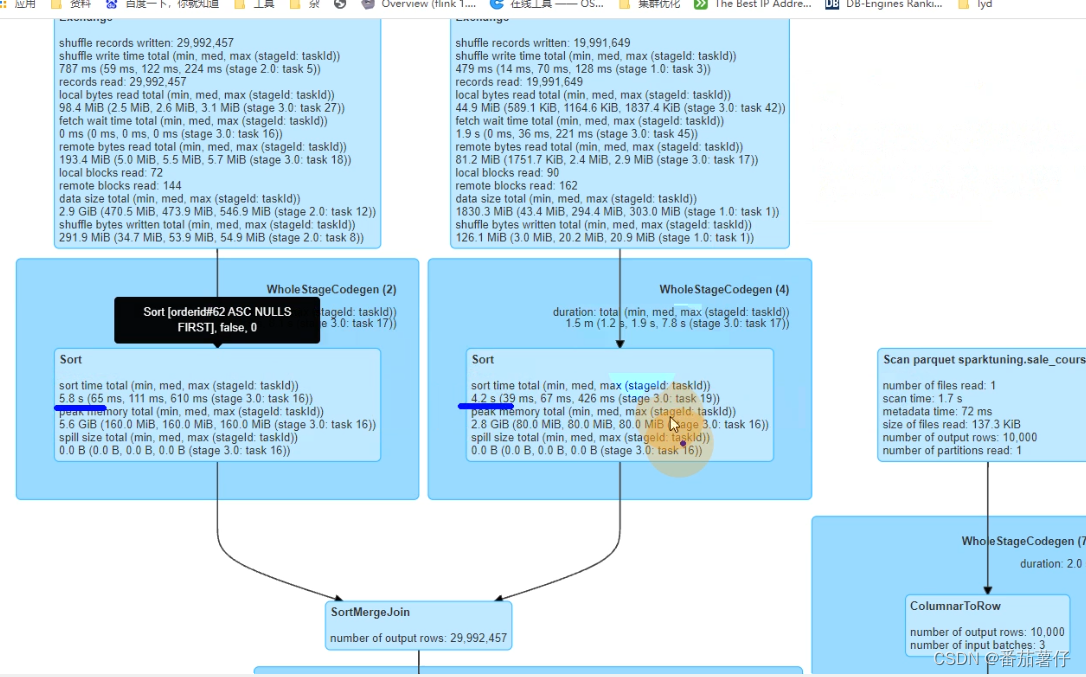
2.优化后
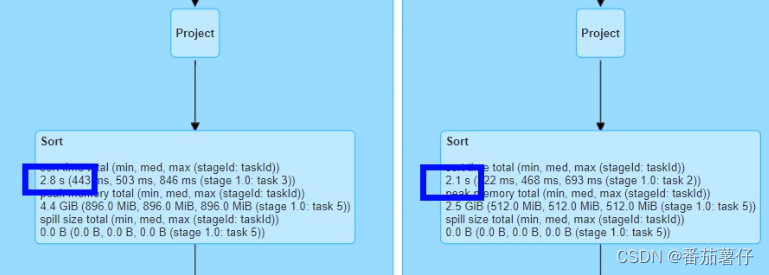
可以看到在这个sort里面时间减少了一半,所以看到有序分桶表是非常有作用的。
此外,打开HDFS的表文件中,可以看到普通join有36个文件(并行度为36),而分桶表有5个(5个bucket),从这里也可以看出它们的差别在哪的。
小结
资源调优
- 资源规划:资源配置的时候要考虑充分,合理配置资源,使程序不至于卡掉或者说空转,但也不能占用过多资源,在跑程序前可以预估使用量。
- 持久化和序列化:在使用RDD的cache时,默认是Memory级别,这样对于程序的性能是最优的,但是如果内存不够,那就要考虑kyro串行化和磁盘存储了。Spark SQL有自己优化的cache,默认级别就是Memory_DISK,而且与串行化之后占用的空间相差不大,所以直接使用默认级别即可。
- CPU优化:SparkSQL默认的shuffle并行度为200。并行度最好是并发度的2-3倍。
SparkSQL语法优化:如谓词下推(Predicate Pushdown)、列裁剪(Column Pruning)列裁剪(Column Pruning)、常量替换
基于CBO的优化
广播Join:默认值为10MB,由spark.sql.autoBroadcastJoinThreshold 参数控制。利用自动广播Join,使小于spark.sql.autoBroadcastJoinThreshold 大小的表通过广播方式广播到大表中,这样的话可以无需shuffle,其中最耗时的sortmergejoin也无需执行了,因此执行速度可以加快。
SMB Join:
- 两张大表join的时候使用,但有使用条件:两表进行分桶,桶的个数必须相等;两边进行 join 时,join 列=排序列=分桶列。
- 在执行过程中,首先会进行排序,然后根据 key值合并,把相同 key 的数据放到同一个 bucket 中(按照 key 进行 hash)。分桶的目的其实就是把大表化成小表。相同 key 的数据都在同一个桶中之后,再进行 join 操作,那么在联合的时候就会大幅度的减小无关项的扫描。
好了,以上是资源调优、SparkSQL语法优化的讲解,感谢各位读者读到这里。
接下来就要开始讲解数据倾斜的优化过程!















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









