









EMNLP 2020 多视图序列到序列的模型

介绍
最近有一些关于对话摘要的研究,例如直接部署现有的文档摘要模型(Gliwa et al., 2019)和探索多句子压缩(Shang et al., 2018),但是大多数都没有使用特定的对话结构,指的是在对话中组织话语的方式,以使对话变得有意义、愉快和易于理解(Sacks 等人,1978 年)——这是区分对话与结构化文档的关键因素。作为一种与他人一起“用语言做事”的社交语言方式,对话有其自身的动态结构,这些结构以特定的顺序组织话语,使对话变得有意义、愉快和易于理解(Sacks et al., 1978) .尽管有一些例外,例如利用主题分割 (Liu et al., 2019b; Li et al., 2019)、对话行为 (Goo and Chen, 2018) 或关键点序列 (Liu et al., 2019a),但它们要么需要对话语行为进行广泛的专家注释(Goo and Chen, 2018; Liu et al., 2019a),要么只根据话题对对话进行编码(Liu et al., 2019b),这无法捕捉对话中丰富的对话结构。
甚至可以从不同的角度查看单个对话,从而产生多种对话或话语模式。例如,在表 1 中,根据讨论的主题(主题视图)(Galley et al., 2003; Liu et al., 2019b; Li et al., 2019),可以分割成问候语、今天的计划、计划明天,计划周六和接机时间;从对话进展的角度(阶段视图)(Ritter 等人,2010;Paul,2012;Althoff 等人,2016),相同的对话可以分为开场、意图、讨论和结论。从粗略的角度来看(全局视图),对话可以被视为一个整体,或者每个话语都可以作为一个片段(离散视图)。仅利用对话的固定主题视图的模型(Joty 等人,2010;Liu 等人,2019b)可能无法捕捉其全面而细微的对话结构,并且对话编码器引入的任何数量的信息丢失都可能导致在解码阶段产生更大的错误级联。为了填补这些空白,我们建议将这些多重、不同的对话观点结合起来,以生成更精确的摘要。
总而言之,我们的贡献是 :( 1) 我们建议利用丰富的对话结构,即结构化视图 (主题视图和阶段视图) 和通用视图 (全局视图和离散视图) 进行抽象的对话摘要。(2) 我们设计了一个多视图序列对序列模型,该模型由一个用于编码不同视图的对话编码器和一个具有多视图关注的多视图解码器组成,以生成对话摘要。(3) 我们在大型对话摘要数据集SAMSum (Gliwa等,2019) 上进行了实验,并证明了我们提出的方法的有效性。(4) 我们进行彻底的错误分析,并讨论当前方法在此任务中面临的特定挑战。
方法
1、对话视图的提取
对话摘要模型很容易在各种说话者和话语之间的各种信息中迷失,尤其是当对话变得很长时。自然,如果可以从长时间的对话中明确地提取小块形式的信息结构,则模型可能能够以更有组织的方式更好地理解它们。因此,我们首先从对话中提取不同的结构视图。
主题视图
尽管对话通常比文档的结构更少,但它们大多以粗粒度结构围绕主题组织 (Honneth等,1988)。例如,从话题的角度来看,电话聊天可能具有 “问候 → 邀请 → 聚会细节 → 拒绝” 的模式。这种明确的视图和主题流可以帮助模型更精确地解释对话,并生成涵盖重要主题的摘要。在这里,我们将经典的主题段算法C99 (Choi,2000) 与最近的高级句子表示形式SentenceBERT (Reimers和Gurevych,2019) 相结合,以提取主题视图。具体来说,对话C = {u1,u2,...,um} 中的每个话语ui首先通过句子-BERT编码为隐藏向量。然后通过C99将会话C分成块Ctopic = {b1,...,bn},其中bi是一个块,它包含几个连续的话语,例如表1中描述的主题视图。
阶段视图
作为与他人一起在社交上用文字做事的一种方式,对话以一定的顺序组织话语,以使其有意义、愉快和易于理解。 (Sacks 等人,1978 年;Althoff 等人,2016 年)例如,发现咨询对话遵循“介绍→问题探索→问题解决→总结”的常见模式(Althoff 等人,2016 年)。这种对话阶段视图提供了关于对话中不同部分的功能或目标的高级草图,这可以帮助模型专注于具有关键信息的阶段。我们遵循Althoff等人。 (2016)通过隐马尔可夫模型(HMM)提取阶段。我们对阶段施加了固定的顺序,并且只允许从当前阶段过渡到下一个阶段。 HMM 模型中的观察结果是来自 Sentence-BERT 的编码表示 hi。我们将隐藏阶段的数量设置为 4。与主题视图提取类似,我们将对话分割成块 Cstage = {b1, ..., bn},其中 si 是一个包含多个连续话语的块。我们定性地解释了推断的阶段,并进一步可视化了表 2 中每个阶段出现的前 6 个常用词。我们发现,围绕日常聊天的对话通常以开口开头,介绍对话的目标/焦点,然后讨论细节,最后以某些结局结束。表 1 显示了阶段视图的示例。
全局视图和离散视图
除了上述两种结构化视图外,对话还可以从相对粗略的角度自然地观看,即将所有话语串联成一个巨大块的全局视图 (Gliwa等,2019),以及将每个话语分成不同块的离散视图 (Liu和Chen,2019; Gliwa等,2019)。
2、多视图序列到序列的模型
我们扩展通用的序列到序列模型来编码和组合不同的对话视图。为了在最近的预训练模型中更好地利用语义信息,我们使用基于转换器的预训练模型 BART(Lewis 等人,2019)来实现我们的基本编码器和解码器。请注意,我们的多视图序列到序列模型与初始化它的 BART 无关。
Conversation Encoder
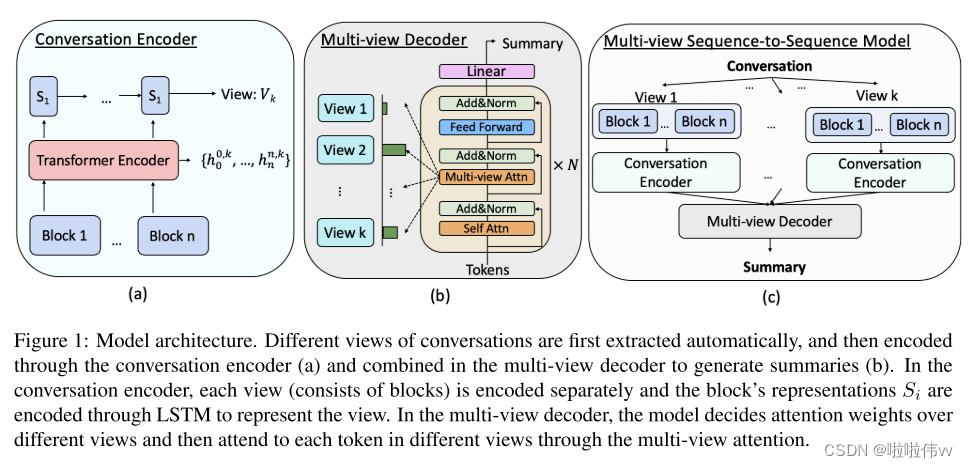
给定具有n个块的特定视图k下的对话: Ck = {bk 1,...,bk n},块bk中的每个令牌xk i,j = j {xk 0,j,xk 1,j,...,xk m,j} 首先通过对话编码器E (例如,如图1(a) 所示的BART编码器) 编码为隐藏的表示形式: {hk 0,j,hk 1,j,...,hk m,j} = E({xk 0,j,xk 1,j,...,xk m,j}) 注意,我们在每个块的开头添加特殊标记xk 0,j,并使用这些tokens的表示来描述每个块,即Sk j = hk 0,j。为了使用隐藏向量来描绘不同的视图,我们通过LSTM层 (Hochreiter和Schmidhuber,1997) 聚合来自一个会话中的所有块的信息: 我们使用最后一个隐藏状态Sk n来表示当前视图k,表示为Vk。
多视图解码器
不同的视图可以为模型提供不同类型的对话方面来学习并进一步确定哪一组话语应该得到更多关注,以生成更好的对话摘要。因此,战略性地结合不同观点的能力至关重要。为此,我们提出了一种基于变换器的多视图解码器,以整合来自不同视图的编码表示并生成摘要,如图 1(b) 所示。解码器的输入包含 l-1 个先前生成的令牌 t1, ..., tl-1。通过我们的多视图解码器 D,第 l 个令牌通过以下方式预测: 这里,Wp 是要学习的参数。与通用 Transformer 解码器不同,我们在每个 Transformer 块中引入了多视图注意力层。多视图注意力层首先通过以下方式决定每个视图 Vk 的重要性 αk: 其中 v 是一个随机初始化的上下文向量; W 和 b 是参数。为了避免注意力权重彼此过于相似,因为视图实际上是从相似的上下文中编码的,我们在 αk 上使用了一个锐化函数,温度为 T: 。当 T → 0 时,注意力 1 T 的权重将表现得像一个单热向量。然后对来自不同视图 k 的对话标记 hk i,j 执行多头注意力,并分别形成 Ak。参与的结果基于视图-注意力权重 〜αk 进一步组合并继续向前传递:














 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









