







Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization 阅读笔记
Motivation
与传统的文本不同,对话中往往隐含着丰富的特定结构信息,也就是说对话其实是按一定结构组织的。一段对话可以从多个不同视角去看待,会产生不同的语篇结构。从一般视角(generic view)上看,可以把对话总体上看成一块(global view),也可以把每条语句可以看成一块(discrete view)。从话题视角去看(topic view),可以分成连续的若干段,每段中的语句具有相似的话题。从阶段视角去看(stage view),对话又可以分为开始,意图,讨论,结论等若干段。如下图所示:

现有的对话摘要生成方法往往只使用 一般视角或是只关注话题视角,这样就难以全面的捕获对话的结构信息,造成了信息的损失。本文提出了一个mutil-view的seq2seq模型,结合了这4个视角的信息,编码器从多个视角编码文本,解码器结合多个视角的信息,生成对话的摘要。
Model
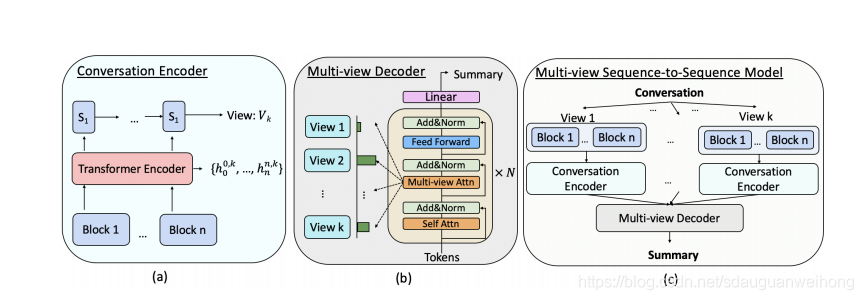
上图给出了模型的总体架构
首先根据不同视角将文本分为若干块。如果按照topic view划分使用sentence bert和c99算法,如果按照stage view划分使用sentence bert和HMM算法,如果按照global view划分,将所有语句连接在一起作为1块,如果按照discrete view划分,将每条语句作为1块。
multi-view seq2seq模型基于BART模型,conversation encoder先通过transformer编码器将分块后的每块文本编码为表示
S
i
{S}_{i}
Si,再使用LSTM对所有
S
i
S_i
Si编码获得每个视图的表示
multi-view decoder,相比传统的transformer decoder增加了一个multi-view attention层,首先计算每个视图的注意力权重,把各视图的信息结合在一起向前传递。

















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









