







 本文详细解释了基尼指数在机器学习中的应用,通过计算示例说明如何用基尼系数评估样本纯度,并演示了在CART分类树中如何根据Gini系数决定节点划分。重点在于如何利用基尼系数提高模型精度。
本文详细解释了基尼指数在机器学习中的应用,通过计算示例说明如何用基尼系数评估样本纯度,并演示了在CART分类树中如何根据Gini系数决定节点划分。重点在于如何利用基尼系数提高模型精度。
一、基尼指数的概念
基尼指数(Gini不纯度)表示在样本集合中一个随机选中的样本被分错的概率。
注意:Gini指数越小表示集合中被选中的样本被参错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为一个类时,基尼指数为0.
二、基尼指数的计算公式
基尼指数的计算公式为:
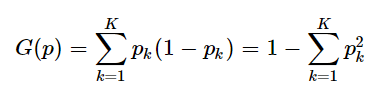
三、计算示例
我们分别来计算一下决策树中各个节点基尼指数:
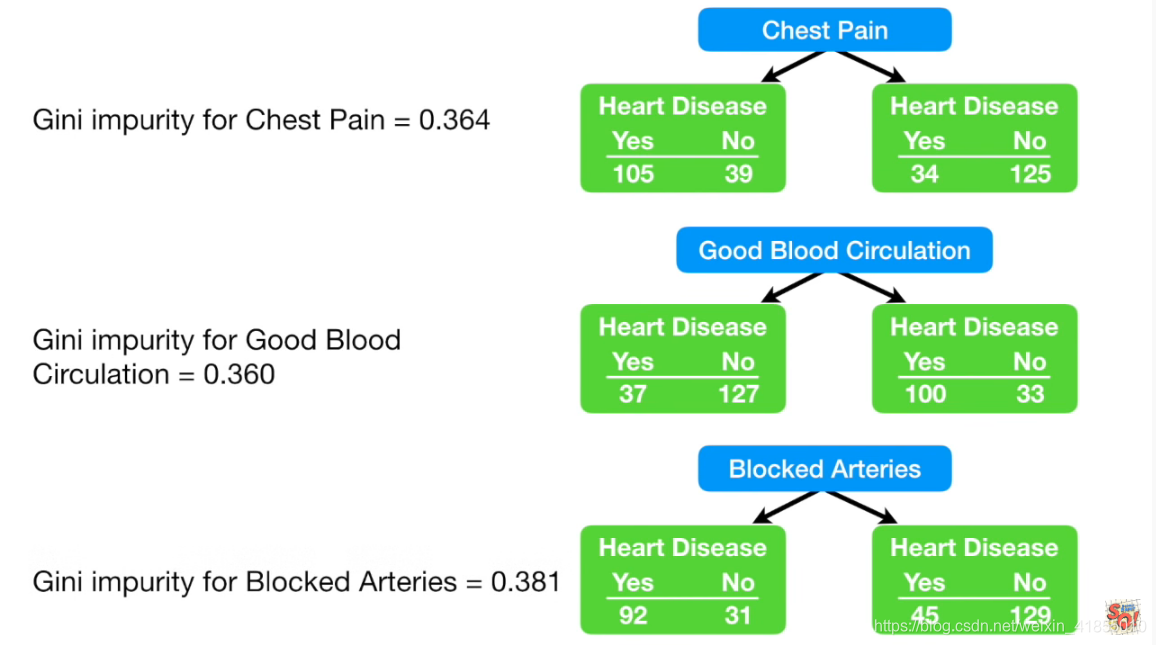
以下excel表格记录了Gini指数的计算过程。

我们可以看到,GoodBloodCircle的基尼指数是最小的,也就是最不容易犯错误,因此我们应该把这个节点作为决策树的根节点。在机器学习中,CART分类树算法使用基尼指数来代替信息增益比,基尼指数代表了模型的不纯度,基尼指数越小,不纯度越低,特征越好。这和信息增益(比)相反。

















 1626
1626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









