






LLM微调
LLM微调指的是对大型语言模型(Large Language Models,简称LLM)进行的再训练过程,目的是使这些模型更好地适应特定的任务或应用场景。是将预训练模型进一步适配到特定任务或领域的过程。微调通常在模型已经在大量数据上进行了预训练之后进行,这一阶段会让模型学习到更具体的知识和技能,从而提高其在特定任务上的表现
以下是LLM微调中涉及的一些关键步骤:
- 模型选择:选择是从头开始训练模型还是修改现有模型。在许多情况下,适应性调整现有模型是高效的。
- 数据准备:收集和准备用于微调的数据集,可能包括对数据进行清洗、标注和构建特定的提示模板。
- 执行微调:将数据集分为训练、验证和测试部分,并在训练数据集上对模型进行微调,以优化其在特定任务上的性能。
- 模型更新:在微调过程中,模型会根据标记数据进行更新,通过比较模型的猜测与实际答案之间的差异来进行优化。
- 评估与迭代:定期使用指标和基准进行评估,并在提示工程、微调和评估之间进行迭代,直到达到期望的结果。
- 模型部署:当模型表现符合预期时,进行部署,并在这个阶段优化计算效率和用户体验。
微调的种类
- 参数高效微调(PEFT):这是一种技术,它只更新模型的一小部分参数,以适应特定任务,从而显著降低计算成本。
- 指令微调:使用示例来训练模型,展示模型应该如何响应查询,这可以提高模型在各种任务上的表现。
- 全微调(FFT):更新模型所有权重的过程,与预训练相比,全微调需要更多的内存和计算资源。
优化思路
- 适配器方法:在预训练模型的顶部添加一个小型神经网络(适配器),然后对这个适配器进行训练。
- 剪枝方法:通过移除模型中的一些不重要的参数来降低模型的复杂度,并只对剩余的重要参数进行训练。
- 知识蒸馏:利用一个小型模型(学生模型)来模仿大型预训练模型(教师模型)的行为,学生模型通过学习教师模型的输出来获取任务相关的知识。
- 多任务学习:训练数据集包含多个任务的输入和输出示例,同时提高模型在所有任务上的性能。
- 检索增强:结合自然语言生成和信息检索的方法,确保语言模型通过外部最新知识或相关文档提供信息来源。
什么是量化LoRA(QLoRA)
QLoRA代表了LoRA的一种更具内存效率的迭代。QLoRA还通过将LoRA适配器(较小矩阵)的权重量化到较低精度(例如,4-bit而不是8-bit),使LoRA更进一步。这进一步减少了内存占用和存储需求。在QLoRA中,预训练的模型用量化的4位权重加载到GPU存储器中,而在LoRA中使用的是8位。尽管比特精度有所下降,QLoRA仍保持着与LoRA相当的有效性水平。
使用QLoRA在自定义数据集上微调LLM流程
- 安装所需的库
- 加载数据集
- 创建和字节配置
- 加载经过预训练的模型
- Tokenization
- 对原始模型进行测试
- 预处理数据集
- 为QLoRA准备模型
- 设置用于微调的PEFT
- 列车PEFT适配器
- 定性评估模型(人工评估)
- 量化评估模型(使用ROUGE度量)
安装需要的依赖
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
AutoTokenizer,
TrainingArguments,
Trainer,
GenerationConfig
)
from tqdm import tqdm
from trl import SFTTrainer
import torch
import time
import pandas as pd
import numpy as np
from huggingface_hub import interpreter_login
#interpreter_login() ## 登录 Huggingface,输入免费 token 即可 选择操作
import os
# disable Weights and Biases
#禁用Weights and Biases(W&B)跟踪
#减少程序的资源消耗时
os.environ['WANDB_DISABLED']="true"
加载数据集
huggingface_dataset_name = "neil-code/dialogsum-test"
dataset = load_dataset(huggingface_dataset_name)
#加载之前下载过的数据
## 查看数据范例
print(dataset['train'][0])
返回结果
{‘id’: ‘train_0’, ‘dialogue’: “#Person1#: Hi, Mr. Smith. I’m Doctor
Hawkins. Why are you here today?\n#Person2#: I found it would be a
good idea to get a check-up.\n#Person1#: Yes, well, you haven’t had
one for 5 years. You should have one every year.\n#Person2#: I know. I
figure as long as there is nothing wrong, why go see the
doctor?\n#Person1#: Well, the best way to avoid serious illnesses is
to find out about them early. So try to come at least once a year for
your own good.\n#Person2#: Ok.\n#Person1#: Let me see here. Your eyes
and ears look fine. Take a deep breath, please. Do you smoke, Mr.
Smith?\n#Person2#: Yes.\n#Person1#: Smoking is the leading cause of
lung cancer and heart disease, you know. You really should
quit.\n#Person2#: I’ve tried hundreds of times, but I just can’t seem
to kick the habit.\n#Person1#: Well, we have classes and some
medications that might help. I’ll give you more information before you
leave.\n#Person2#: Ok, thanks doctor.”, ‘summary’: “Mr. Smith’s
getting a check-up, and Doctor Hawkins advises him to have one every
year. Hawkins’ll give some information about their classes and
medications to help Mr. Smith quit smoking.”, ‘topic’: ‘get a
check-up’}
#查看每个KEY
for key in dataset['train'][0]:
print(key)
id 、dialogue、 summary、 topic
加载经过预训练的模型
## bnb config
#量化模型
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)
model_name='microsoft/phi-2'
device_map = {"": 0}
original_model = AutoModelForCausalLM.from_pretrained(model_name,
device_map=device_map,
quantization_config=bnb_config,
trust_remote_code=True,
use_auth_token=True,
torch_dtype=torch.float16 #减少模型的消耗可能是出现报错的原因
)
加载tokener
## tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True,padding_side="left",add_eos_token=True,add_bos_token=True,use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
# 词汇表中添加了特殊标记,请确保相关的单词嵌入经过微调或训练的
seed = 42
#设置随机数
tokenizer.pad_token:这个标记通常用作填充(padding)标记。在处理文本序列时,为了保持一致性,需要将所有序列填充到相同的长度。这样,模型就可以有效地使用这些序列进行批量处理。pad_token
就是用来填充序列末尾的标记,以确保所有序列的长度相同。
tokenizer.eos_token:这个标记代表序列结束(end of sequence)标记。它用于指示一个文本序列的结束。在某些模型中,特别是那些需要知道序列结束位置的模型,这个标记非常重要。例如,在翻译任务中,模型需要知道输入序列何时结束,以便开始生成翻译后的输出序列。
预处理数据集
def create_prompt_formats(sample):
"""
格式化示例的各个字段(“指令”、“输出”)
然后使用两个换行符将它们连接起来
:param sample:字典示例
"""
INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
#以下是描述任务的说明。编写一个适当完成请求的响应。
INSTRUCTION_KEY = "### Instruct: Summarize the below conversation."
#指导:总结以下对话。
RESPONSE_KEY = "### Output:"
END_KEY = "### End"
blurb = f"\n{INTRO_BLURB}"#请求相应
instruction = f"{INSTRUCTION_KEY}"#总结
input_context = f"{sample['dialogue']}" if sample["dialogue"] else None
response = f"{RESPONSE_KEY}\n{sample['summary']}"
end = f"{END_KEY}"
parts = [part for part in [blurb, instruction, input_context, response, end] if part]
formatted_prompt = "\n\n".join(parts)
sample["text"] = formatted_prompt
print('*'*10)
print(sample)
print('*'*10)
return sample
from functools import partial
#函数可以实现函数参数的固定化,从而简化函数调用和减少重复的代码。
def get_max_length(model):
#加载模型参数
conf = model.config
#最大长度加载
max_length = None
for length_setting in ["n_positions", "max_position_embeddings", "seq_length"]:
#加载量化的结果
max_length = getattr(model.config, length_setting, None)
if max_length:
print(f"Found max lenth: {max_length}")
break
if not max_length:
max_length = 1024
print(f"Using default max length: {max_length}")
return max_length
def preprocess_batch(batch, tokenizer, max_length):
"""
Tokeniz
"""
return tokenizer(
batch["text"],
max_length=max_length,
truncation=True,
)
# 参考详细说明 https://github.com/databrickslabs/dolly/blob/master/training/trainer.py
def preprocess_dataset(tokenizer: AutoTokenizer, max_length: int,seed, dataset):
"""数据格式 & tokenize 已经准备好用于训练
:参数 tokenizer (AutoTokenizer): 模型 Tokenizer
:参数最大擦灰姑娘高度 : 从标记生成器发出的最大标记数
"""
# Add prompt to each sample
print("Preprocessing dataset...")
dataset = dataset.map(create_prompt_formats)#, batched=True)
print(dataset)
#对数据集的每个批次应用预处理&并删除“指令”、“上下文”、“响应”和“类别”字段
#函数可以实现函数参数的固定化,从而简化函数调用和减少重复的代码。
_preprocessing_function = partial(preprocess_batch, max_length=max_length, tokenizer=tokenizer)
#数据拼接
dataset = dataset.map(
_preprocessing_function,
batched=True,
remove_columns=['id', 'topic', 'dialogue', 'summary'],
)
# 筛选出input_id超过max_length的样本
dataset = dataset.filter(lambda sample: len(sample["input_ids"]) < max_length)
# 无序数据集
dataset = dataset.shuffle(seed=seed)
return dataset
## 预处理微调数据集
## Pre-process dataset
max_length = get_max_length(original_model)
print(max_length)
train_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset['train'])
eval_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset['validation'])
train_dataset[0]['text']
查看详细内容
“\nBelow is an instruction that describes a task. Write a response
that appropriately completes the request.\n\n### Instruct: Summarize
the below conversation.\n\n#Person1#: How are your French lessons
going?\n#Person2#: Well, I’m no longer taking French
lessons.\n#Person1#: Are you kidding? You told me you made up your
mind to study French well this summer. Didn’t you sign up for the
four-week course?\n#Person2#: I did. But the teacher told me not to
come back any more after only one week and he returned my money for
the remaining three weeks.\n#Person1#: How come? I’ve never heard of a
case like that before. Did you have a quarrel with your
teacher?\n#Person2#: Of course not. At first everything went well and
he was satisfied with me. But he got angry after I broke the class
rules several times.\n#Person1#: It was your fault, I think. You’d
gone too far.\n#Person2#: Perhaps. But I don’t understand why he told
me to stop coming. He was very kind, you know.\n#Person1#: Just forget
it.\n\n### Output:\n#Person2# is no longer taking French lessons
because #Person2# has been kicked out for broking the class rules
several times. #Person1# comforts #Person2#.\n\n### End”
train_dataset[0]['input_ids'][0:10]
[50256, 198, 21106, 318, 281, 12064, 326, 8477, 257, 4876]
train_dataset[0]['attention_mask'][0:10]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
加载 PEFT 模块
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
#https://huggingface.co/docs/peft/quicktour 可查看详细内容
original_model = prepare_model_for_kbit_training(original_model)
PEFT为微调大型预训练模型提供了参数有效的方法。传统的范式是为每个下游任务微调模型的所有参数,但由于当今模型中的参数数量巨大,这变得极其昂贵和不切实际。相反,训练较少数量的提示参数或使用像低秩自适应(LoRA)这样的重参数化方法来减少可训练参数的数量更有效。
每个PEFT方法都由PeftConfig类定义,该类存储用于构建PeftModel的所有重要参数。例如,要使用LoRA进行训练
task_type:要训练的任务(在本例中为序列到序列语言建模)
i> nference_mode:无论您是否使用该模型进行推理
r: 低秩矩阵的维数
lora_alpha:低秩矩阵的比例因子
lora_dropout:lora层的丢失概率
#加载 模型参数
config = LoraConfig(
r=32, #低秩矩阵的维数
lora_alpha=32,低秩矩阵的比例因子
#target_modules 要应用适配器的模块的名称。如果指定了此项,则仅替换具有指定名称的模块。传递字符串时,将执行正则表达式匹配。
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense'
],
bias="none", #LoRA的偏移类型。可以是“none”、“all”或“lora_only”。如果“全部”或“lora_only”,则在训练期间会更新相应的偏差。
lora_dropout=0.05, # 每一层的遗忘比例
task_type="CAUSAL_LM",#因果关系大模型 #"SEQ_2_SEQ_LM"
)
# 1 - 启用梯度检查点以减少微调期间的内存使用
original_model.gradient_checkpointing_enable()
#从模型和配置中返回Peft模型对象。
#加载模型和模型参数
peft_model = get_peft_model(original_model, config)
## 打印参数
def print_number_of_trainable_model_parameters(model):
trainable_model_params = 0
all_model_params = 0
for _, param in model.named_parameters():
all_model_params += param.numel()
if param.requires_grad:
trainable_model_params += param.numel()
return f"\n训练模型参数总量: {trainable_model_params}\n所有模型参数的总量: {all_model_params}"
print(print_number_of_trainable_model_parameters(peft_model))
训练模型参数总量: 20971520
所有模型参数的总量: 1542364160
加载模型参数
output_dir = f'./output_model/peft-dialogue-summary-training-{str(int(time.time()))}'
#保存路径
import transformers
"""
首先在TrainingArguments中定义训练超参数。
可以根据自己的喜好更改大多数参数的值。
"""
#https://huggingface.co/docs/transformers/v4.40.0/en/main_classes/trainer#transformers.TrainingArguments
peft_training_args = TrainingArguments(
output_dir = output_dir,# 模型输出地址
warmup_steps=1,#用于从0到learning_rate的线性预热的步骤数。
per_device_train_batch_size=1,#用于训练的每个GPU/XPU/TPU/MPS/NPU核心/CPU的批量大小。
gradient_accumulation_steps=4,#在执行向后/更新过程之前,用于累积梯度的更新步骤数。
#使用梯度累加时,一步算一步,向后通过。因此,每个gradient_accumulation_steps*xxx_step训练示例都会进行记录、评估和保存。
max_steps=400,#最大步长
learning_rate=2e-4,#学习率
optim="paged_adamw_8bit",#优化器 paged_adamw_8bit paged:分页器 ;ADAMV: adamw 在adam基础上添加了权重衰减(weight decay),这是一种正则化技术,有助于防止过拟合。
logging_steps=50,#(int或float,可选,默认为500)--如果logging_rategy=“steps”,则两个日志之间的更新步骤数。应为[0,1)范围内的整数或浮点值。如果小于1,将被解释为总训练步骤的比率。
logging_dir="./logs",#日志保存地址
save_strategy="steps",#在训练过程中采用的检查点保存策略。“no”:训练期间不进行任何保存。“epoch”:保存在每个epoch结束时完成。“steps”:每次Save_step都进行保存。
save_steps=50,#多少多少步保存
evaluation_strategy="steps",#同上 测试过程中检查点保存测量
eval_steps=50,#测试数据间距
do_eval=True,#是否eval
gradient_checkpointing=True,#如果为True,则使用线性检查点以节省内存为代价,降低向后传递的速度。
report_to="none",#要向其报告结果和日志的集成列表。使用“all”报告所有已安装的集成,使用“none”报告无集成。
overwrite_output_dir = 'True',#如果为True,则覆盖输出目录的内容。
group_by_length=True,#是否将训练数据集中大致相同长度的样本分组在一起(
)
peft_model.config.use_cache = False
配置训练器
peft_trainer = transformers.Trainer(
model=peft_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
args=peft_training_args,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
开始训练
peft_trainer.train()
训练结果:
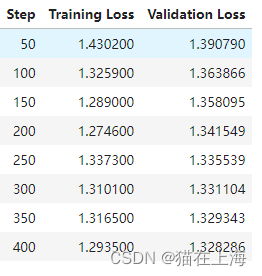
可以看到从350之后 验证集合上的loss 下降已经缓慢顾采用350迭代次数的模型作为后续测试。一旦模型训练成功,我们就可以使用它进行推理。
推理验证人工
加载依赖
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
AutoTokenizer,
TrainingArguments,
Trainer,
GenerationConfig
)
加载模型参数
model_name='microsoft/phi-2'
device_map = {"": 0}
original_model = AutoModelForCausalLM.from_pretrained(model_name,
device_map=device_map,
quantization_config=bnb_config,
trust_remote_code=True,
use_auth_token=True,
torch_dtype=torch.float16 #减少模型的消耗可能是出现报错的原因
)
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)
base_model_id = "microsoft/phi-2"
base_model = AutoModelForCausalLM.from_pretrained(base_model_id,
device_map='auto',
quantization_config=bnb_config,
trust_remote_code=True,
use_auth_token=True)
加载token
eval_tokenizer = AutoTokenizer.from_pretrained(base_model_id, add_bos_token=True, trust_remote_code=True, use_fast=False)
eval_tokenizer.pad_token = eval_tokenizer.eos_token
加载pef
from peft import PeftModel
ft_model = PeftModel.from_pretrained(base_model, "./output_model/peft-dialogue-summary-training-1713691307/checkpoint-350",torch_dtype=torch.float16,is_trainable=False)
验证数据加载
from datasets import load_dataset
huggingface_dataset_name = "neil-code/dialogsum-test"
dataset = load_dataset(huggingface_dataset_name)
#加载之前下载过的数据
## 查看数据范例#print(dataset['train'][0])
seed = 42
#设置随机数
%%time
from transformers import set_seed
set_seed(seed)
index = 5
dialogue = dataset['test'][index]['dialogue']
summary = dataset['test'][index]['summary']
prompt = f"Instruct: Summarize the following conversation.\n{dialogue}\nOutput:\n"
print(prompt)
“Instruct: Summarize the following conversation.\n#Person1#: You’re finally here! What took so long?\n#Person2#: I got stuck in traffic again. There was a terrible traffic jam near the Carrefour intersection.\n#Person1#: It’s always rather congested down there during rush hour. Maybe you should try to find a different route to get home.\n#Person2#: I don’t think it can be avoided, to be honest.\n#Person1#: perhaps it would be better if you started taking public transport system to work.\n#Person2#: I think it’s something that I’ll have to consider. The public transport system is pretty good.\n#Person1#: It would be better for the environment, too.\n#Person2#: I know. I feel bad about how much my car is adding to the pollution problem in this city.\n#Person1#: Taking the subway would be a lot less stressful than driving as well.\n#Person2#: The only problem is that I’m going to really miss having the freedom that you have with a car.\n#Person1#: Well, when it’s nicer outside, you can start biking to work. That will give you just as much freedom as your car usually provides.\n#Person2#: That’s true. I could certainly use the exercise!\n#Person1#: So, are you going to quit driving to work then?\n#Person2#: Yes, it’s not good for me or for the environment.\nOutput:\n”
查看验证效果 加载pompt
def gen(model,p, maxlen=100, sample=True):
toks = eval_tokenizer(p, return_tensors="pt")
res = model.generate(**toks.to("cuda"), max_new_tokens=maxlen, do_sample=sample,num_return_sequences=1,temperature=0.1,num_beams=1,top_p=0.95,).to('cpu')
return eval_tokenizer.batch_decode(res,skip_special_tokens=True)
peft_model_res = gen(ft_model,prompt,100,)
peft_model_output = peft_model_res[0].split('Output:\n')[1]
#print(peft_model_output)
prefix, success, result = peft_model_output.partition('###')
dash_line = '-'.join('' for x in range(100))
print(dash_line)
print(f'INPUT PROMPT:\n{prompt}')
print(dash_line)
print(f'BASELINE HUMAN SUMMARY:\n{summary}\n')
print(dash_line)
print(f'PEFT MODEL:\n{prefix}')
--------------------------------------------------------------------------------------------------- INPUT PROMPT: Instruct: Summarize the following conversation.
#Person1#: You’re finally here! What took so long?
#Person2#: I got stuck in traffic again. There was a terrible traffic jam near the Carrefour intersection.
#Person1#: It’s always rather congested down there during rush hour. Maybe you should try to find a different route to get home.
#Person2#: I don’t think it can be avoided, to be honest.
#Person1#: perhaps it would be better if you started taking public transport system to work.
#Person2#: I think it’s something that I’ll have to consider. The public transport system is pretty good.
#Person1#: It would be better for the environment, too.
#Person2#: I know. I feel bad about how much my car is adding to the pollution problem in this city.
#Person1#: Taking the subway would be a lot less stressful than driving as well.
#Person2#: The only problem is that I’m going to really miss having the freedom that you have with a car.
#Person1#: Well, when it’s nicer outside, you can start biking to work. That will give you just as much freedom as your car usually
provides.
#Person2#: That’s true. I could certainly use the exercise!
#Person1#: So, are you going to quit driving to work then?
#Person2#: Yes, it’s not good for me or for the environment. Output:--------------------------------------------------------------------------------------------------- BASELINE HUMAN SUMMARY:
#Person2# complains to #Person1# about the traffic jam, #Person1# suggests quitting driving and taking public transportation instead.--------------------------------------------------------------------------------------------------- PEFT MODEL:
#Person2# got stuck in traffic again and #Person1# suggests #Person2# should take public transport system to work. #Person2# agrees and will
start biking to work.#Person1# and #Person2# are talking about #Person2#'s traffic jam.
#Person1# suggests #Person2# should take public transport system to work.
#Person2# agrees and will start biking to work.#Person1# and
量化评估模型(使用ROUGE度量)
ROUGE,或面向回忆的Gisting Evaluation Understudy,是一组指标和软件包,用于评估自然语言处理中的自动摘要和机器翻译软件。
度量将自动生成的摘要或翻译与参考文献或参考文献集(人工生成)摘要或翻译进行比较。
加载模型
original_model = AutoModelForCausalLM.from_pretrained(base_model_id,
device_map='auto',
quantization_config=bnb_config,
trust_remote_code=True,
use_auth_token=True)
import pandas as pd
dialogues = dataset['test'][0:10]['dialogue']
human_baseline_summaries = dataset['test'][0:10]['summary']
original_model_summaries = []
instruct_model_summaries = []
peft_model_summaries = []
#验证
for idx, dialogue in enumerate(dialogues):
human_baseline_text_output = human_baseline_summaries[idx]
prompt = f"Instruct: Summarize the following conversation.\n{dialogue}\nOutput:\n"
original_model_res = gen(original_model,prompt,100,)
original_model_text_output = original_model_res[0].split('Output:\n')[1]
peft_model_res = gen(ft_model,prompt,100,)
peft_model_output = peft_model_res[0].split('Output:\n')[1]
print(peft_model_output)
peft_model_text_output, success, result = peft_model_output.partition('###')
original_model_summaries.append(original_model_text_output)
peft_model_summaries.append(peft_model_text_output)
zipped_summaries = list(zip(human_baseline_summaries, original_model_summaries, peft_model_summaries))
df = pd.DataFrame(zipped_summaries, columns = ['human_baseline_summaries', 'original_model_summaries', 'peft_model_summaries'])
返回结果的部分样例
验证
import evaluate
rouge = evaluate.load('rouge')
original_model_results = rouge.compute(
predictions=original_model_summaries,
references=human_baseline_summaries[0:len(original_model_summaries)],
use_aggregator=True,
use_stemmer=True,
)
peft_model_results = rouge.compute(
predictions=peft_model_summaries,
references=human_baseline_summaries[0:len(peft_model_summaries)],
use_aggregator=True,
use_stemmer=True,
)
结果打印
print('ORIGINAL MODEL:')
print(original_model_results)
print('PEFT MODEL:')
print(peft_model_results)
print("Absolute percentage improvement of PEFT MODEL over ORIGINAL MODEL")
ORIGINAL MODEL: {‘rouge1’: 0.2982172181627305, ‘rouge2’:
0.10884949396933342, ‘rougeL’: 0.2265921122820806, ‘rougeLsum’: 0.2370444112189944} PEFT MODEL: {‘rouge1’: 0.3454568975970058, ‘rouge2’: 0.10093065901837833, ‘rougeL’: 0.27296572386050966,
‘rougeLsum’: 0.2632051713333925} Absolute percentage improvement of
PEFT MODEL over ORIGINAL MODEL
rouge的变化
improvement = (np.array(list(peft_model_results.values())) - np.array(list(original_model_results.values())))
for key, value in zip(peft_model_results.keys(), improvement):
print(f'{key}: {value*100:.2f}%')
rouge1: 4.72%
rouge2: -0.79%
rougeL: 4.64%
rougeLsum: 2.62%
以上是本次样例的全部内容,如果有疑问可以留言交流















 2021
2021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









