






导语
phi-系列模型是微软研究团队推出的轻量级人工智能模型,旨在实现“小而精”的目标,能够实现在低功耗设备上例如智能手机和平板电脑上部署运行。截止目前,已经发布到了phi-3模型,本系列博客将沿着最初的phi-1到phi-1.5,再到phi-2和phi-3模型展开介绍,本文介绍phi-2模型。
- 标题:Phi-2: The surprising power of small language models
- 链接:https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
概览
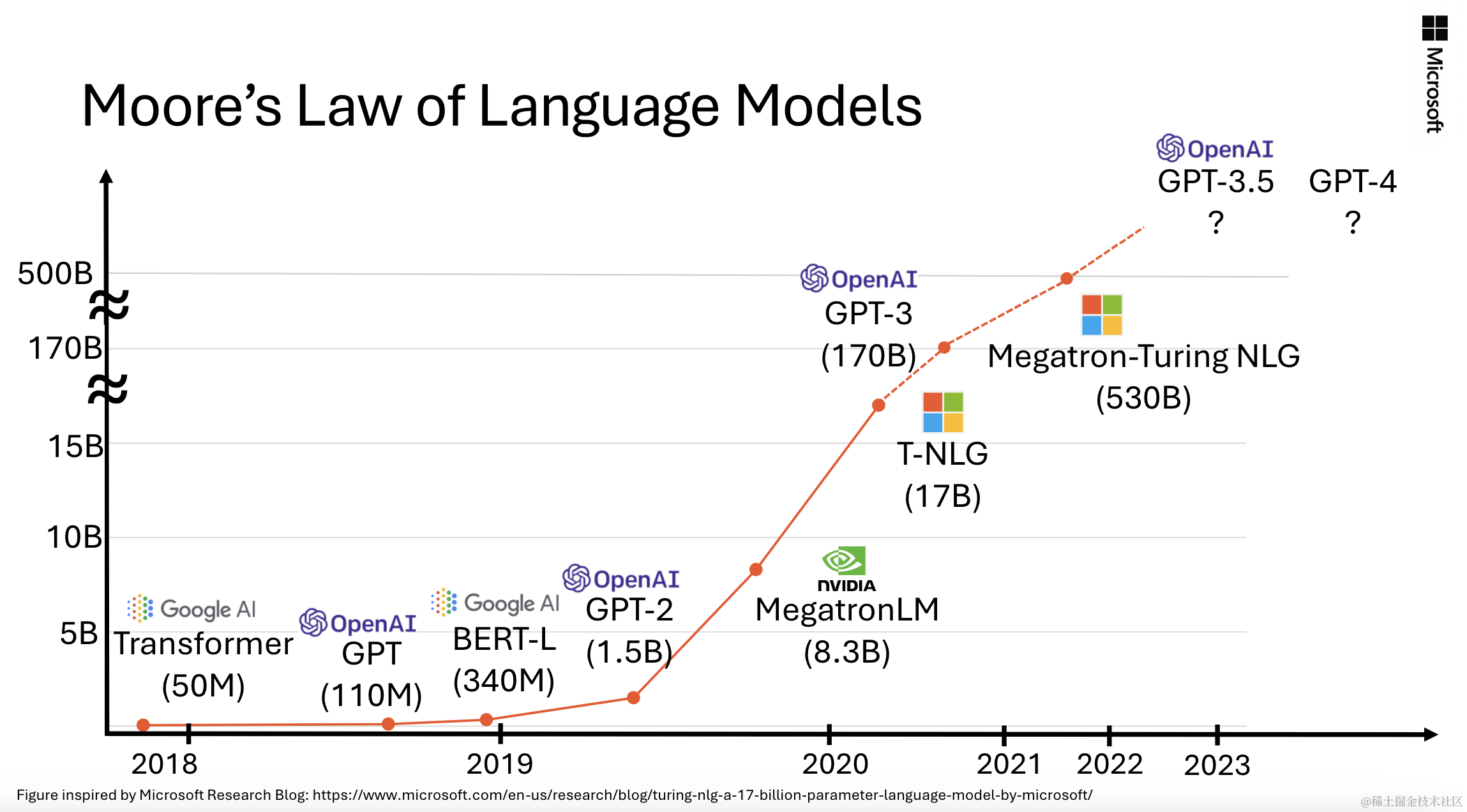
过去的几个月中,微软研究院的机器学习基础团队发布了一套名为“Phi”的小语言模型(Small Language Models,SLMs),在各种基准测试中取得了显著的性能。包括1.3B参数的Phi-1,在现有的SLMs中实现了Python编码的最先进性能(具体来说是在HumanEval和MBPP基准测试中)。和扩展到常识推理和语言理解的1.3B参数模型Phi-1.5,其性能可与大5倍的模型相媲美。
本文介绍Phi-2,一个2.7B参数的语言模型,展示了出色的推理和语言理解能力,在少于13B参数的基础语言模型中表现出最先进的性能。在复杂的基准测试中,Phi-2匹配或超过了大25倍的模型,这要归功于模型扩展和训练数据策划方面的新创新。Phi-2以其紧凑的尺寸成为研究人员的理想试验模型,包括对机械性可解释性、安全性改进或对各种任务进行微调实验。在Azure AI Studio模型目录中提供了Phi-2,以促进语言模型的研究和开发。

Phi-2的关键亮点
语言模型规模的大幅增加至数千亿参数已经解锁了一系列新兴能力,重新定义了自然语言处理的格局。一个问题仍然存在,即是否可以通过战略选择训练数据,例如数据选择,在较小的规模上实现这种新兴能力。
Phi系列模型的工作旨在通过训练实现与规模更大的模型相当的SLMs来回答这个问题(尽管仍远未达到前沿模型)。本文通过Phi-2打破传统语言模型扩展规律的关键见解有两个:
首先,训练数据质量对模型性能至关重要。几十年来这一点已经为人所知,但本文将这一见解发挥到了极致,着重于“教科书质量”的数据,延续了之前的工作“Textbook is all you need”。本文的训练数据混合包含了专门创建的合成数据集,用于教导模型常识推理和一般知识,包括科学、日常活动和心理理论等内容。进一步通过精心筛选的网络数据增强训练语料库,这些数据根据教育价值和内容质量进行了过滤。其次,使用创新技术进行扩展,从1.3B参数模型Phi-1.5开始,并将其知识嵌入到2.7B参数的Phi-2中。这种规模化的知识传递不仅加速了训练收敛,而且在Phi-2的基准分数中显示出明显提升。
训练细节
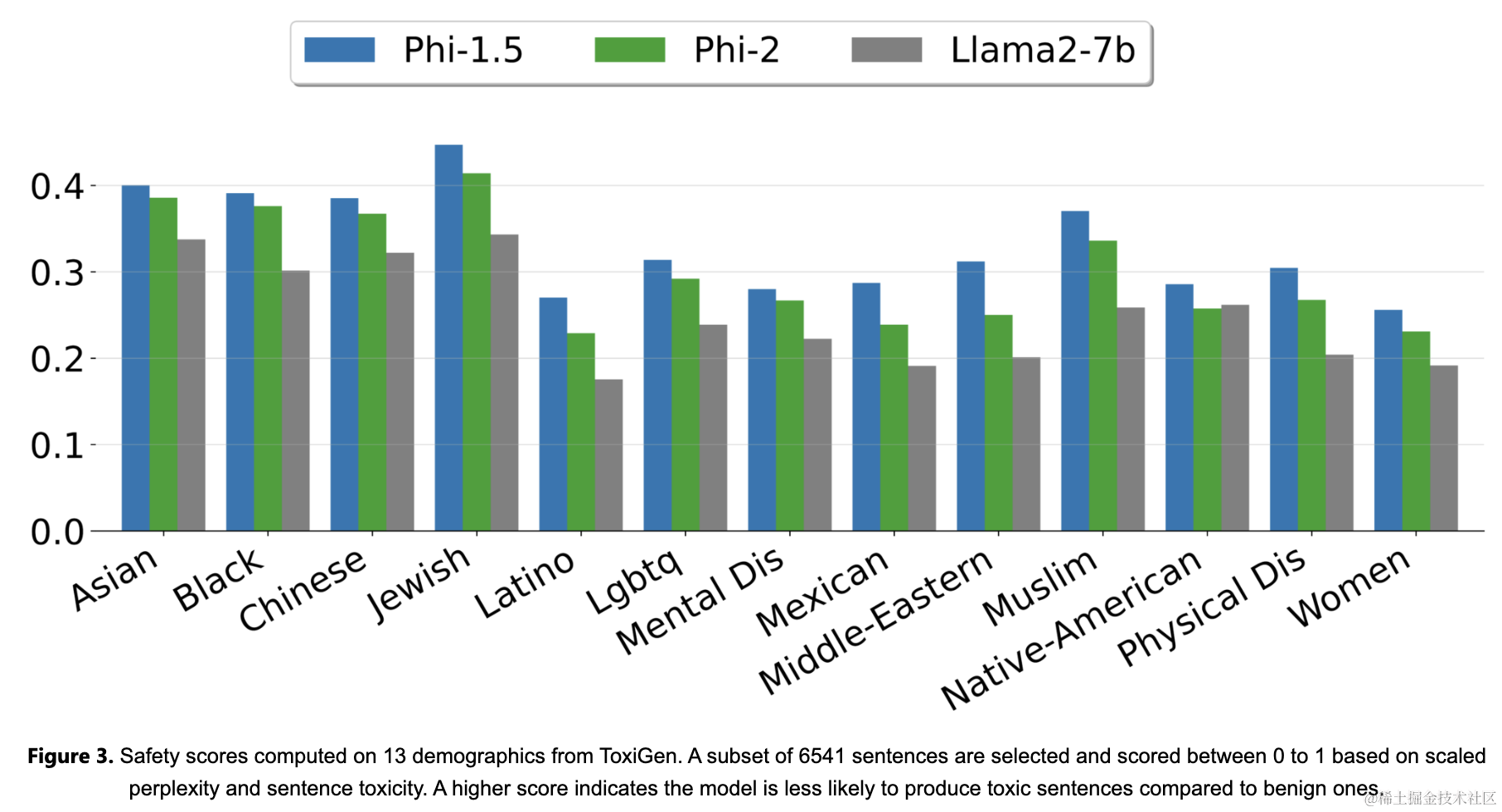
Phi-2是基于Transformer的模型,使用下一个单词预测目标,通过对多次经过的合成和网络数据集进行了NLP和编码的混合训练,共计1.4T词元(token)。训练耗时14天,使用96个A100 GPU。Phi-2是一个基础模型,尚未通过人类反馈的强化学习对齐(RLHF),也没有进行指令微调。尽管如此,与经过对齐的现有开源模型相比,本文观察到在毒性和偏见方面表现更好(参见图3)。这与在Phi-1.5中观察到的情况一致,这归功于作者量身定制的数据策划技术,请查阅之前的技术报告以了解更多详情。
Phi-2 评估
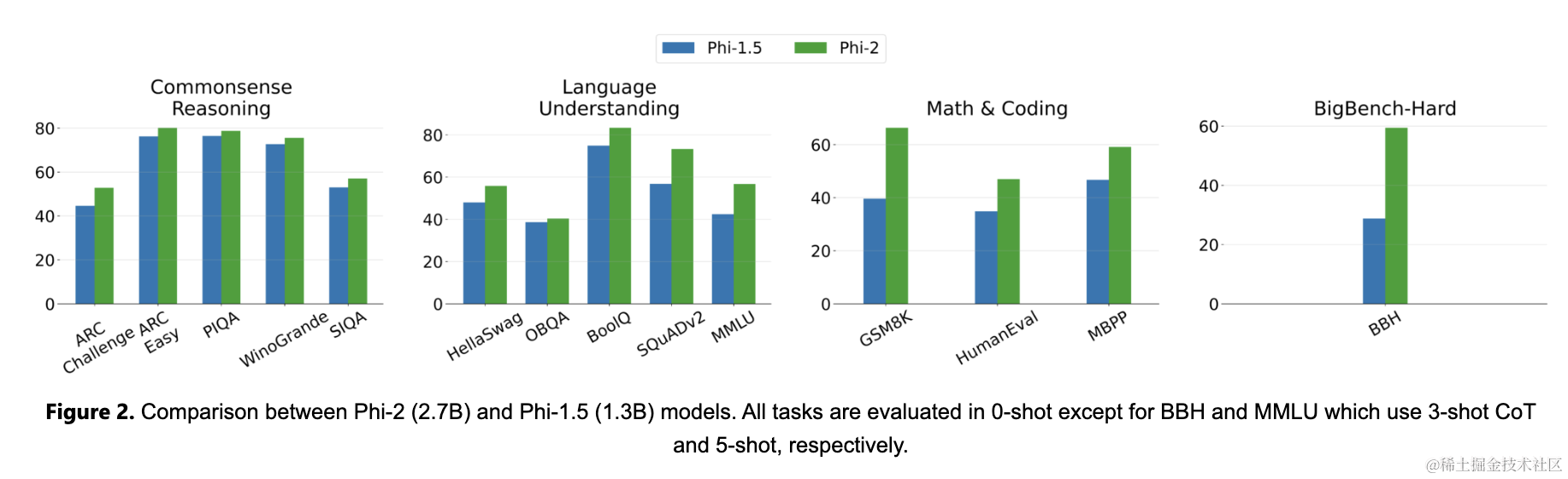
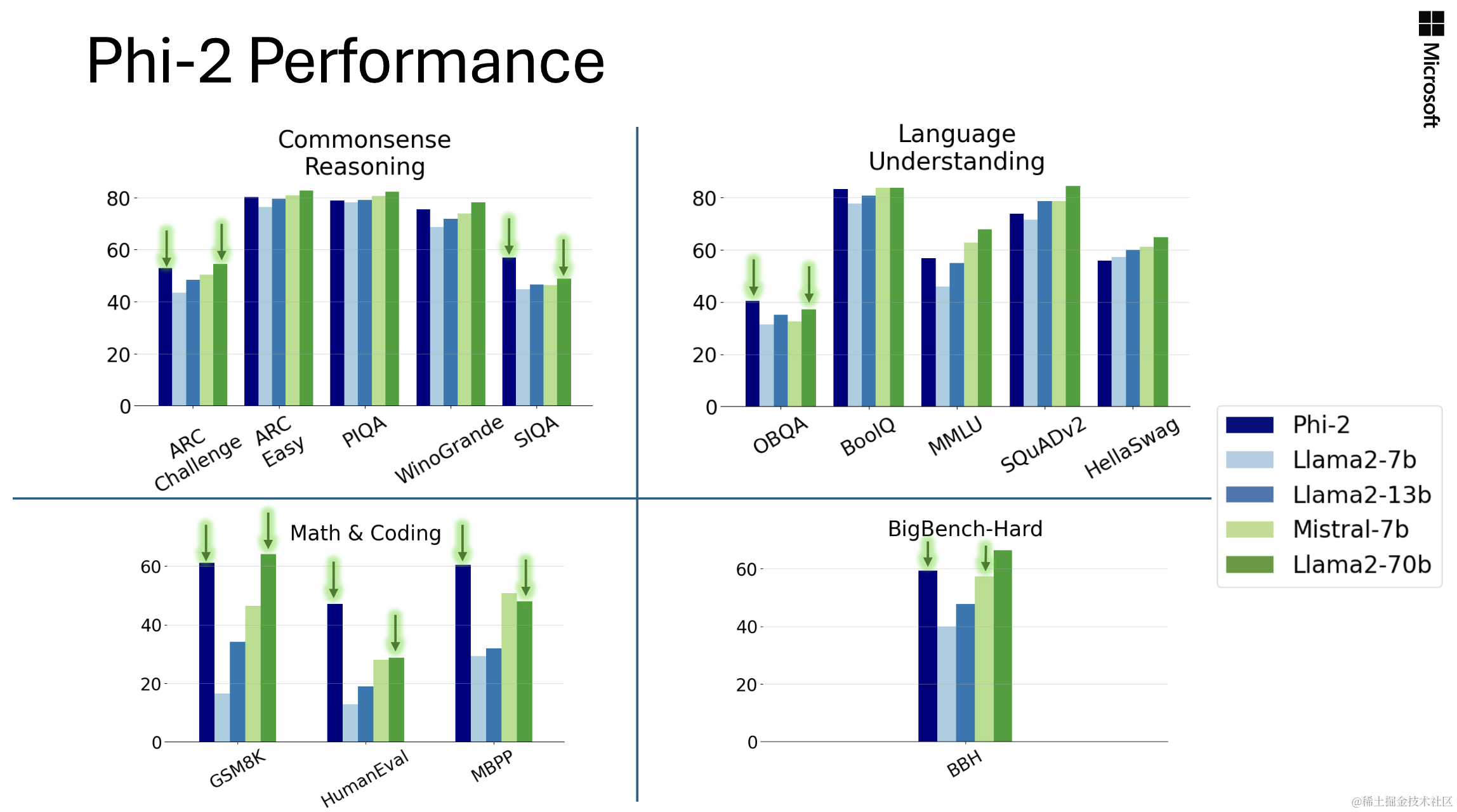
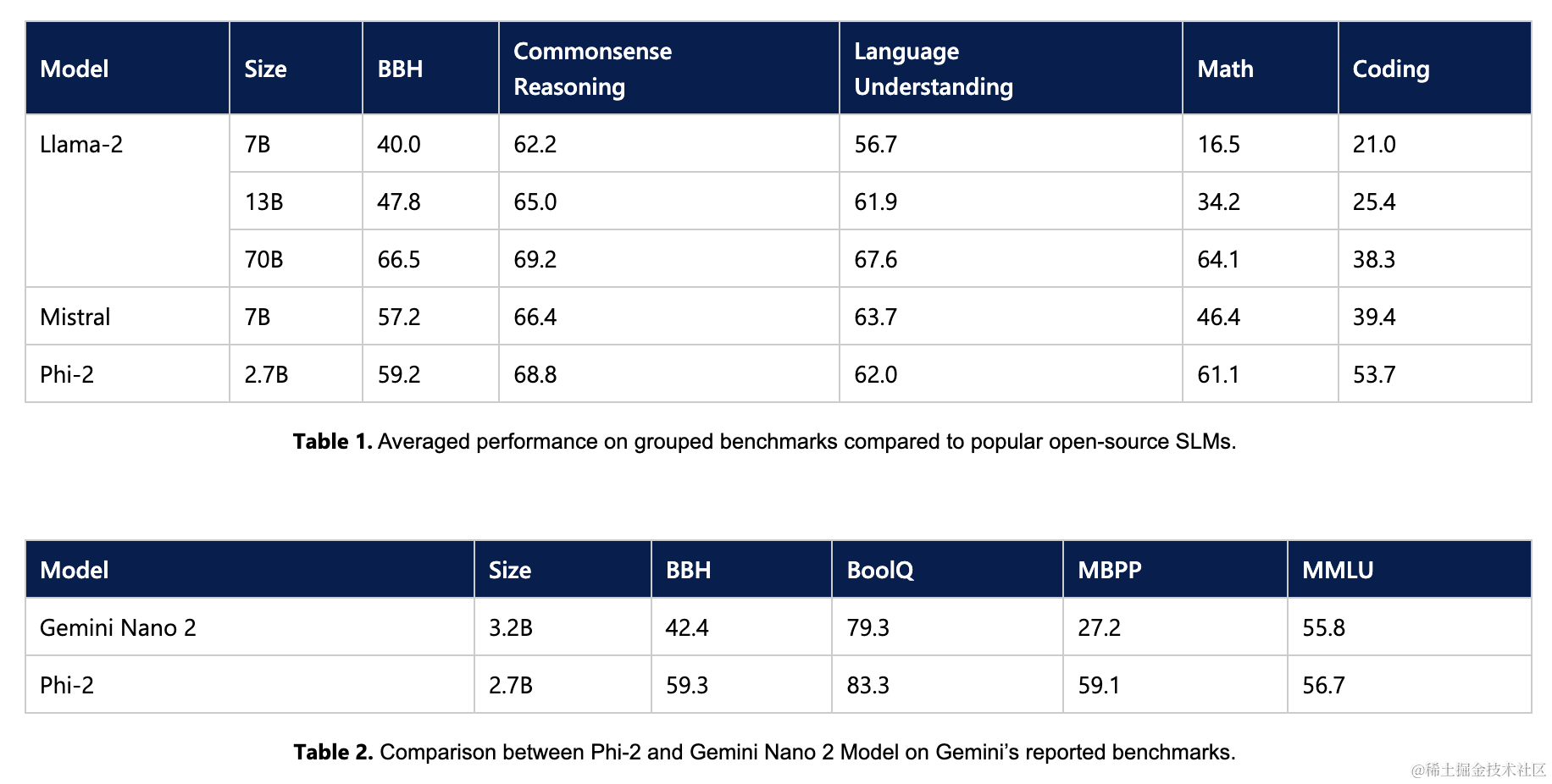
下面总结了Phi-2在学术基准测试中与流行语言模型的性能对比情况。基准测试涵盖了几个类别,包括大型基准测试(BBH)(3-shot与CoT)、常识推理(PIQA、WinoGrande、ARC、SIQA)、语言理解(HellaSwag、OpenBookQA、MMLU(5-shot)、SQuADv2(2-shot)、BoolQ)、数学(GSM8k(8-shot))和编码(HumanEval、MBPP(3-shot))。
仅有2.7B参数的Phi-2在各种综合基准测试中超越了Mistral和Llama-2模型(其参数分别为7B和13B)。值得注意的是,与体积大25倍的Llama-2-70B模型相比,Phi-2在多步推理任务上(即编码和数学)表现更佳。此外,尽管体积较小,Phi-2在性能上与最近宣布的Google Gemini Nano 2相匹配或表现更好。
当然,模型评估面临一些挑战,许多公开基准测试可能泄漏到训练数据中。对于Phi-1,作者进行了广泛的净化研究以排除这种可能性,可以在第一篇报告中找到。作者相信,评判语言模型的最佳方式是在具体用例上进行测试。遵循这一精神,本文还使用了几个微软内部专有数据集和任务对Phi-2进行了评估,再次将其与Mistral和Llama-2进行了比较。可以观察到类似的趋势,即在平均水平上,Phi-2优于Mistral-7B,而后者优于Llama-2模型(7B、13B和70B)。
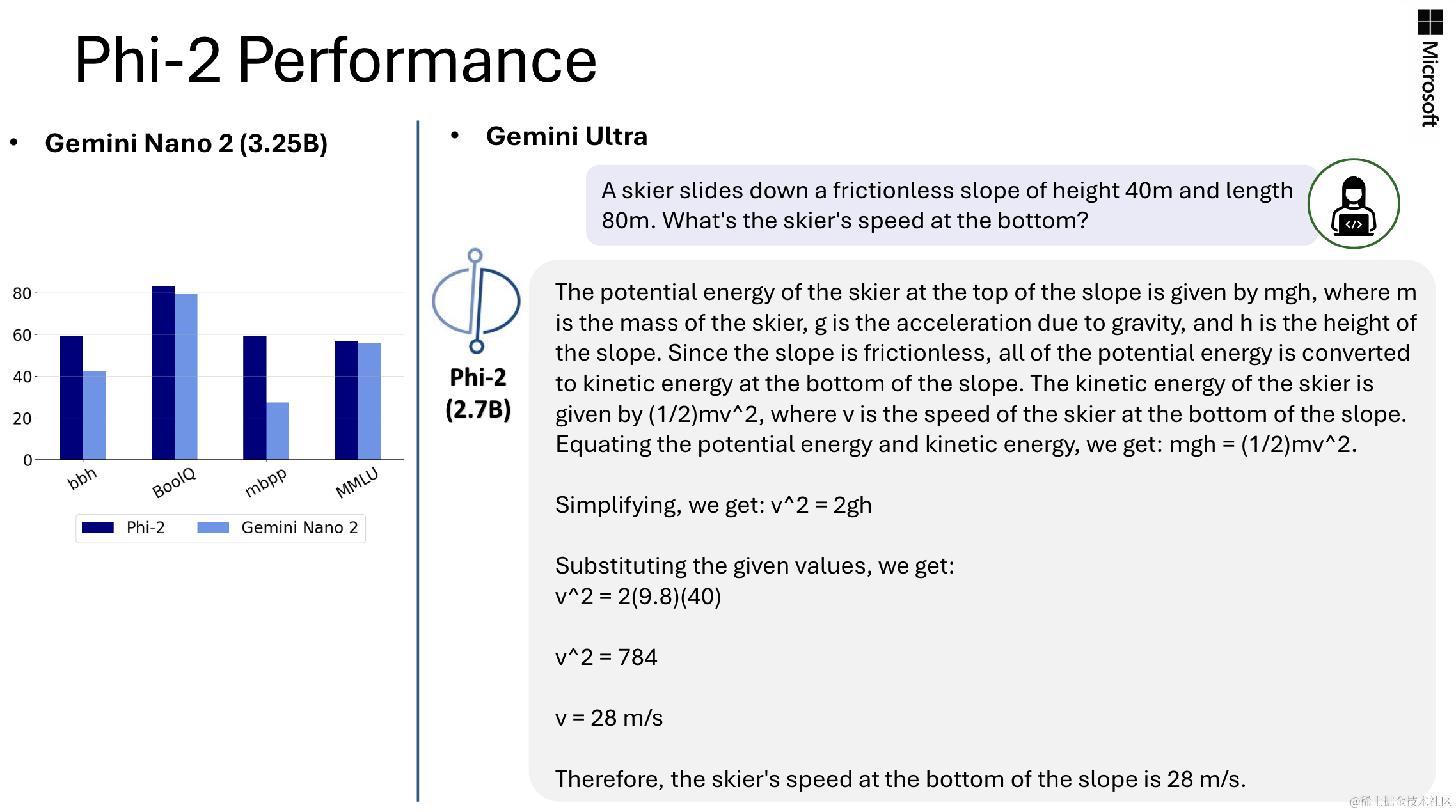
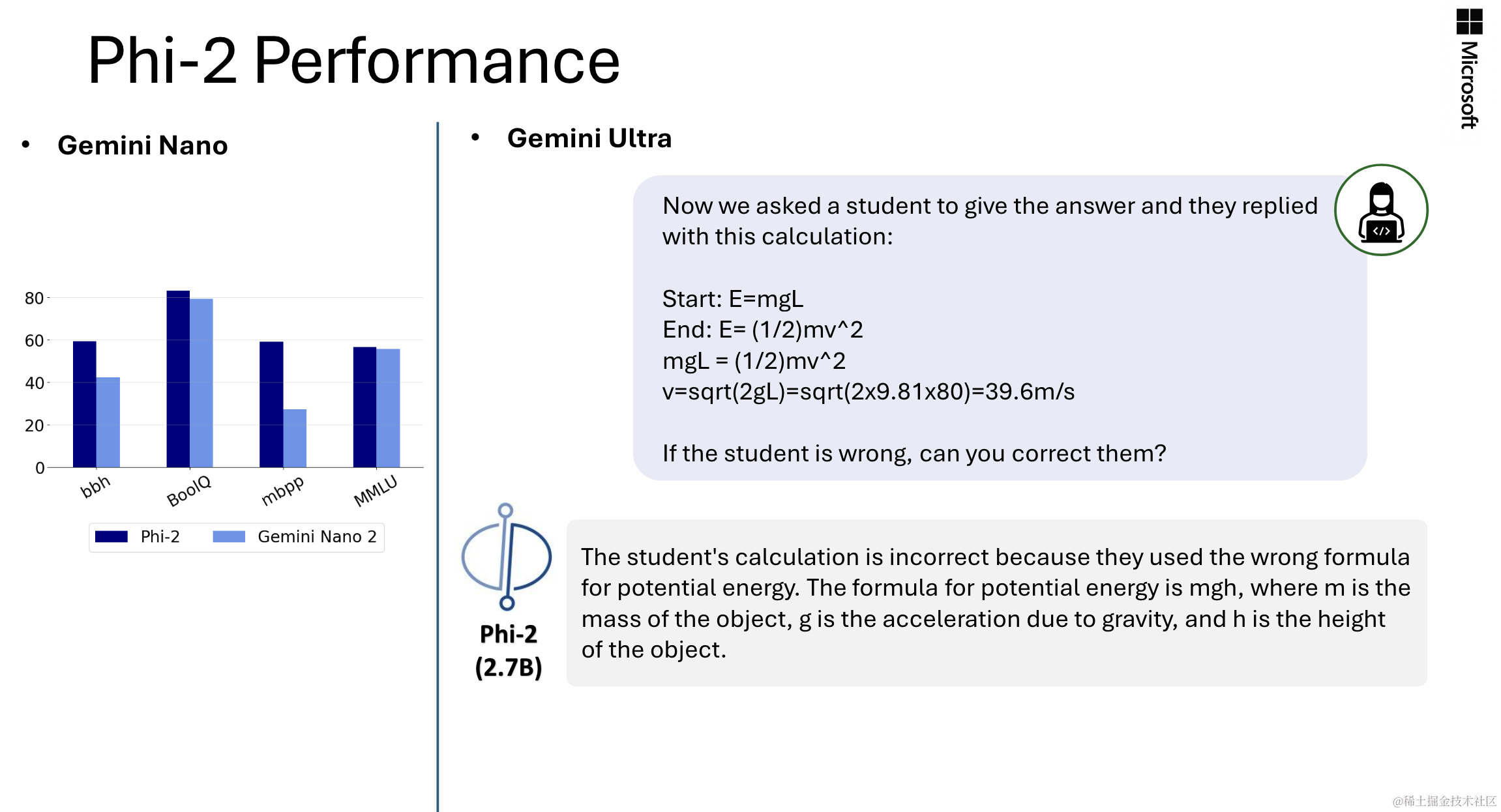
除了这些基准测试之外,本文还对研究界常用的提示进行了广泛测试。观察到的行为符合在基准测试结果的预期。例如,本文测试了用于探究模型解决物理问题能力的提示,最近用于评估Gemini Ultra模型的能力,并获得了以下结果:
扩大规模的最佳实践(Best Practices to Scale up)
在扩大规模时,作者首先给出了phi-1模型上的一些实验结果:
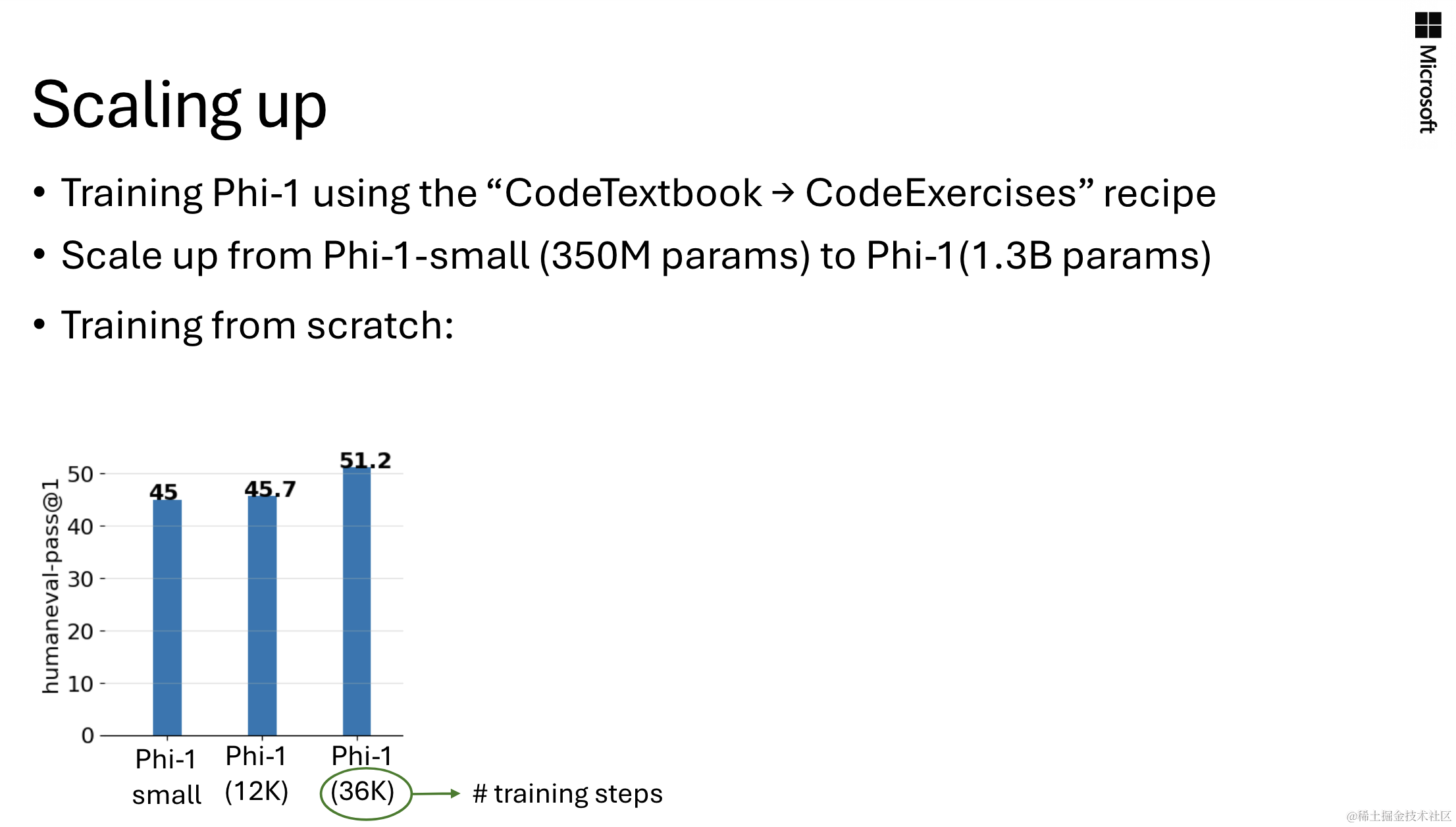
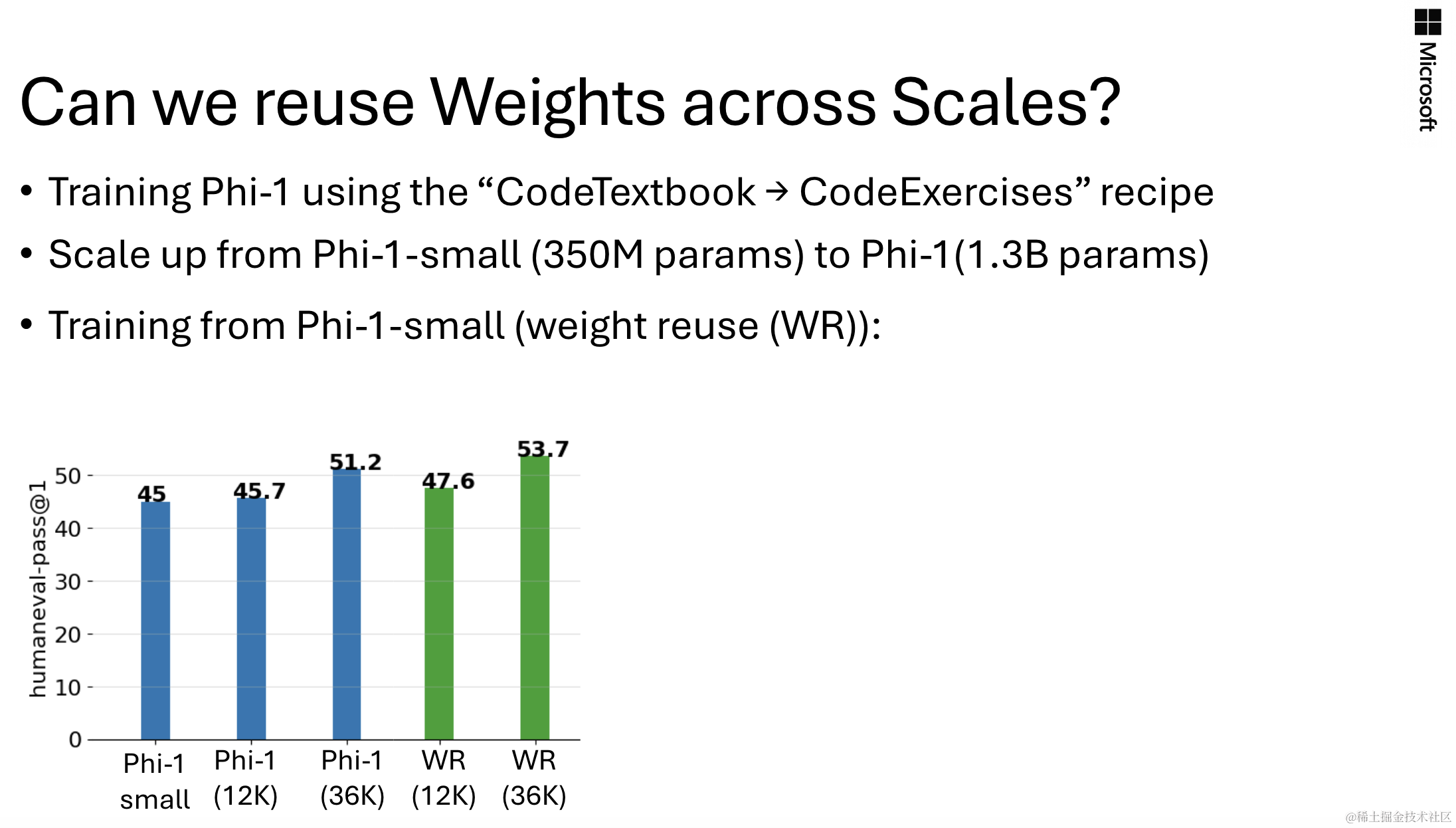
可以看到,训练的次数越长,模型性能越好,但这样就越花费时间。为此作者尝试在大模型中重用已经训练好的小模型权重,但因此也会面临一个挑战:如何把小模型的权重扩展到大模型的维度上?
作者尝试了一个之前研究提出的方式,即层数上使用下图的公式将层数进行映射:

在维度上,则保留那些已有的权重作为新的大权重参数矩阵的一部分,剩下的部分进行随机初始化即可,如下图所示:
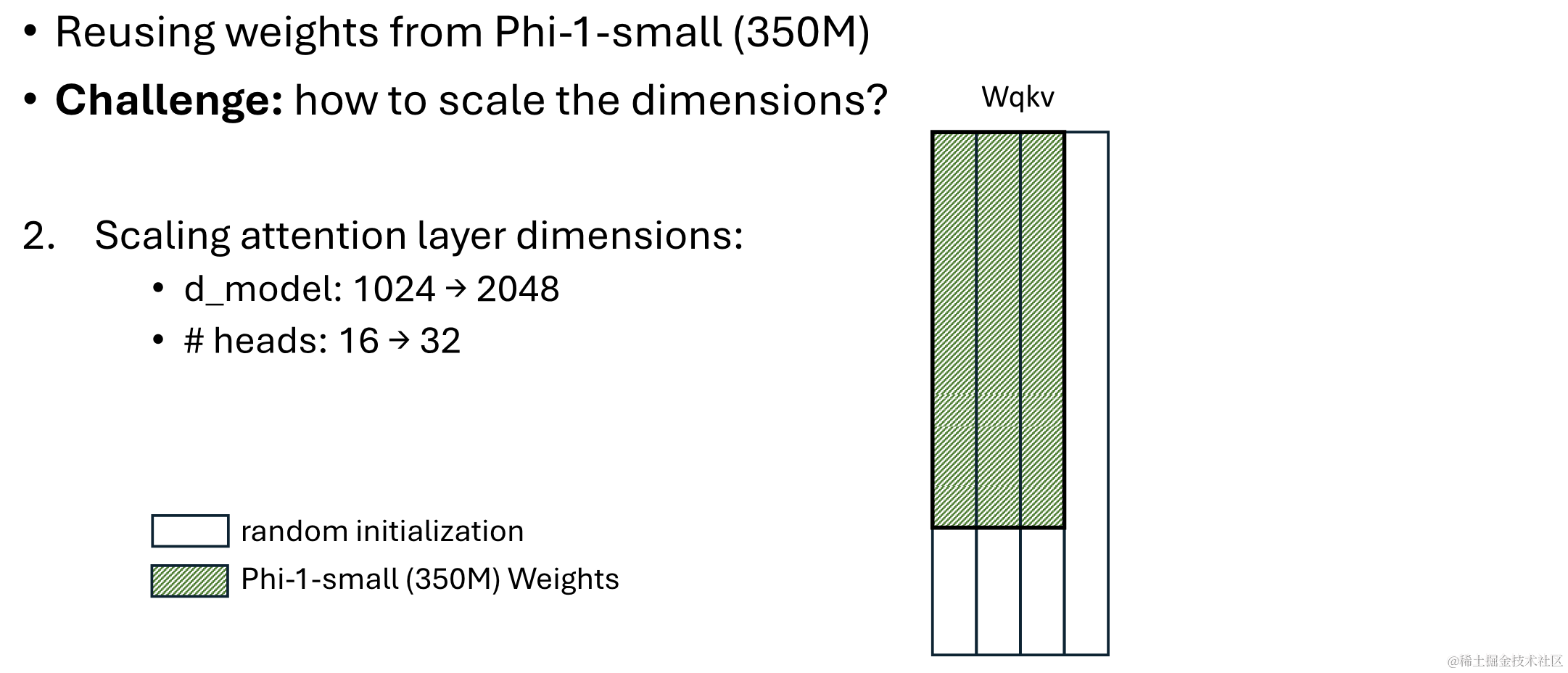
经过这样的重用实验后,得到实验结果如下:
另一种有效的参数继承方式是平铺(Tiling),示意如下:
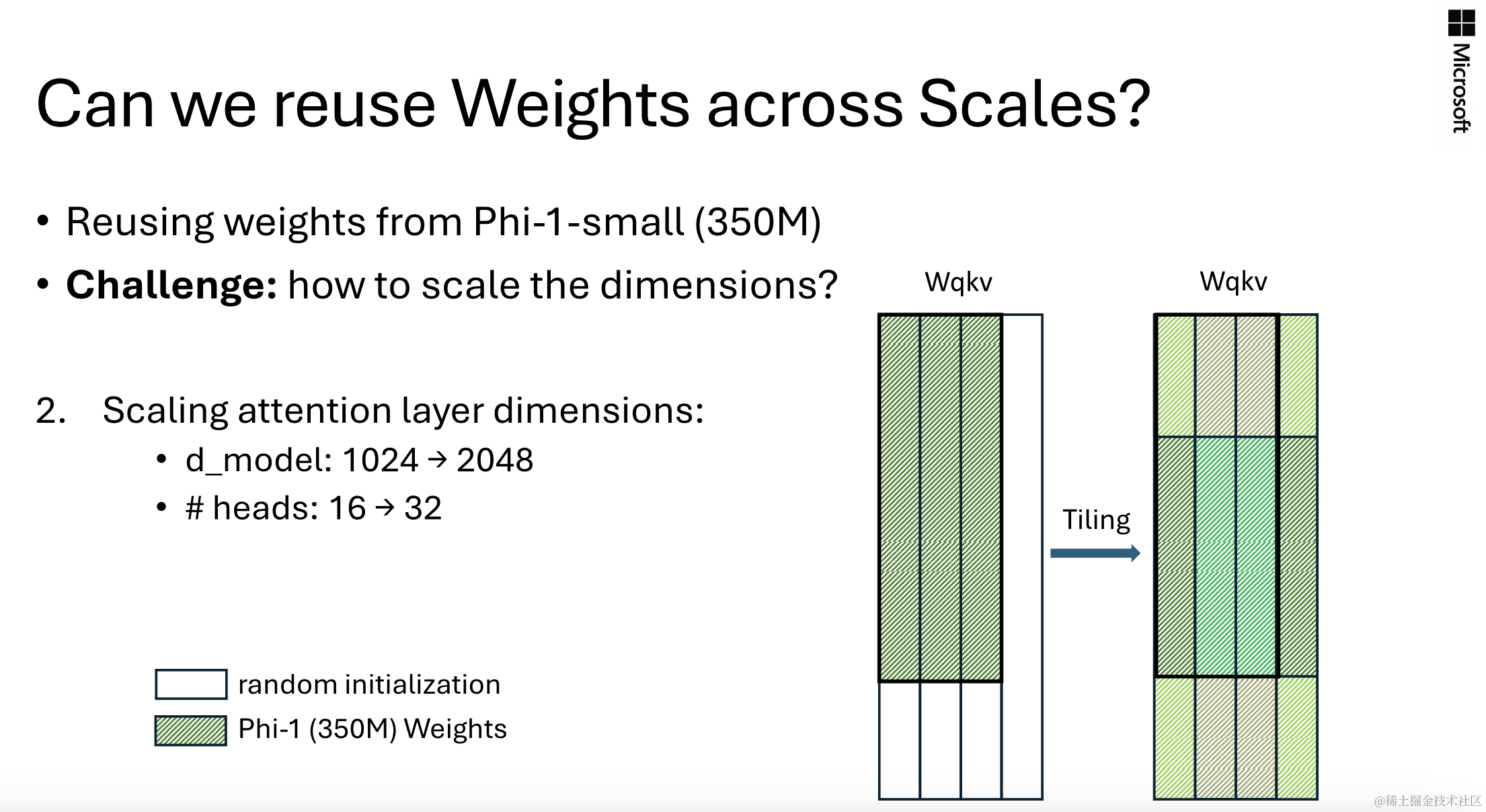
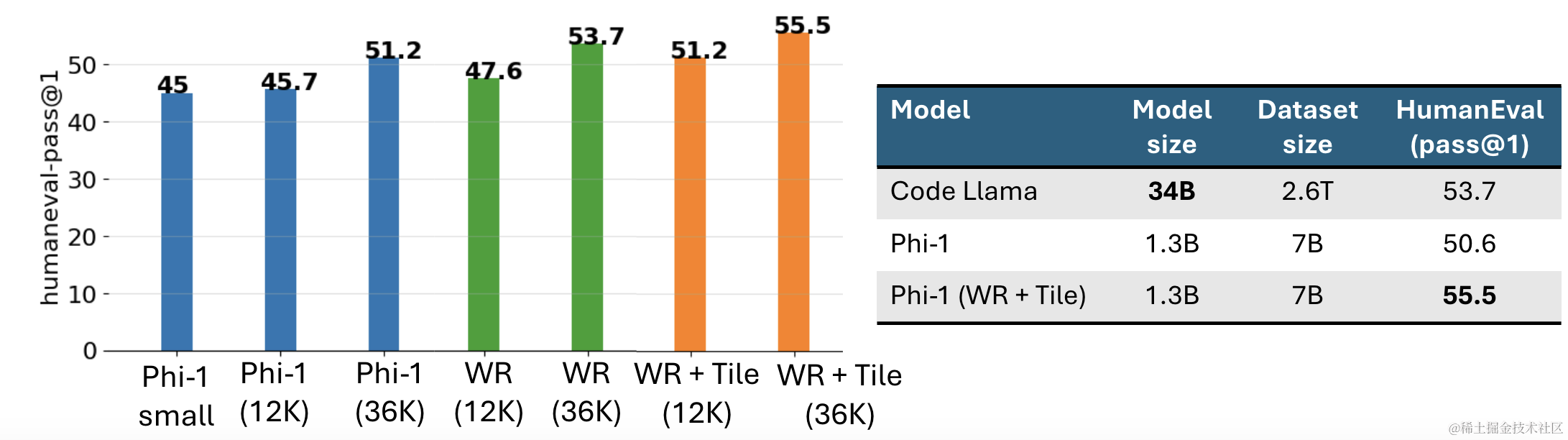
得到的最终性能表现如下:
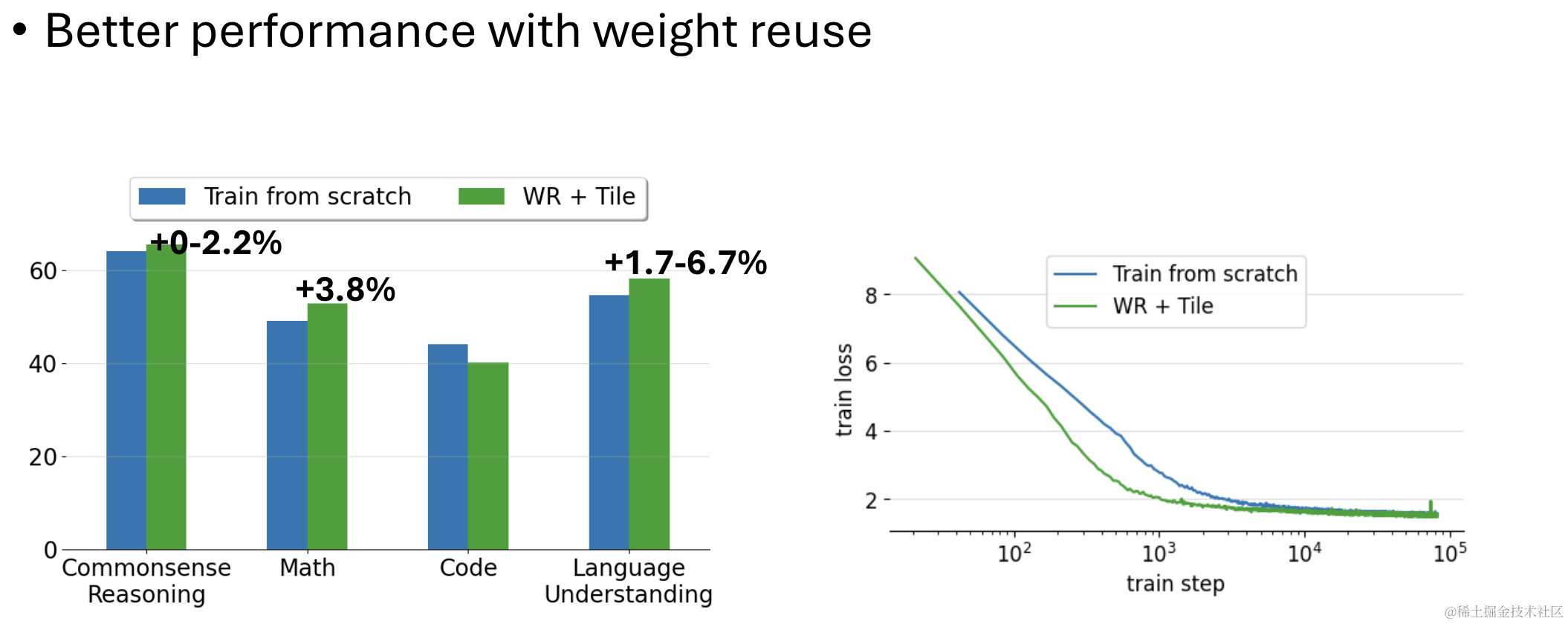
总结
一个良好的、通用的SLM可以通过以下方式实现:
- 与传统的网络数据相对比,生成和利用具有“教科书质量”的数据;
- 吸收扩展规模的最佳实践,以增强整体性能。
参考
- The Surprising Power of Small Language Models, Mojan Javaheripi, Microsoft Research, https://nips.cc/media/neurips-2023/Slides/83968_5GxuY2z.pdf

















 86
86

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









