






PyTorch切分模型和数据两种方法:
DataParallel是单进程多线程的,只用于单机情况;
DistributedDataParallel支持模型并行,同时适用于单机和多机情况。多进程,每个进程都有独立的优化器,执行自己的更新过程,梯度通过通信传递到每个进程(GPU之间只传递梯度),所有执行的内容是相同的。
DistributedDataParallel内部机制
https://pytorch.org/docs/stable/notes/ddp.html
大致流程
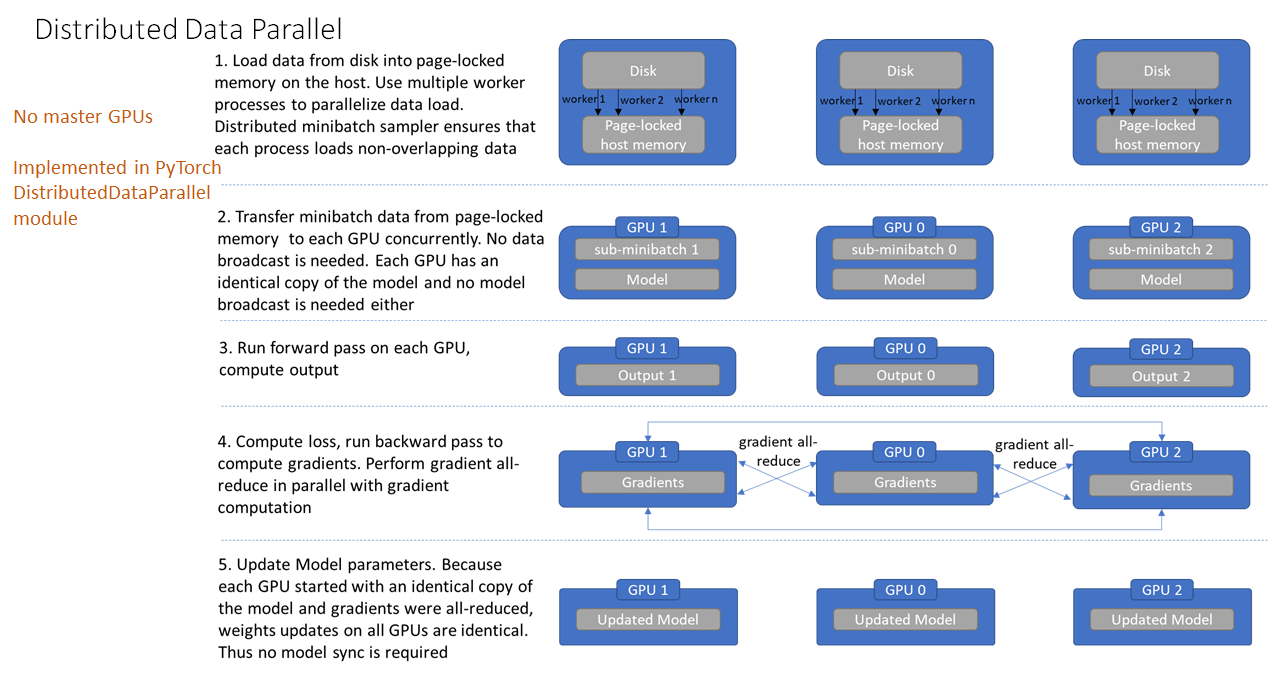
Figure 1. 多机多卡并行训练流程
初始化进程组。
创建分布式并行模型,每个进程都会有相同的模型和参数。
创建数据分发Sampler,使每个进程加载一个Batch中不同部分的数据。
每个进程前向传播并各自计算梯度。
模型某一层的参数得到梯度后会马上进行通讯并进行梯度平均。
各GPU更新模型参数。
初始化
# 初始化分布式环境
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank
)其中backend参数指定通信后端,包括mpi, gloo, nccl。nccl是Nvidia提供的官方多卡通信框架,相对比较高效;mpi也是高性能计算常用的通信协议,不过需要自己安装MPI实现框架,比如OpenMPI;gloo是内置通信后端,但是不够高效。init_method指的是如何初始化,以完成刚开始的进程同步;这里设置的env://指的是环境变量初始化方式,需要在环境变量中配置4个参数:MASTER_PORT,MASTER_ADDR,WORLD_SIZE,RANK。
初始化即建立一个默认的分布式进程组 (distributed process group),这个group同时会初始化Pytorch的torch.distributed包,后续可以直接用torch.distributed的API进行分布式的基本操作。
import torch.distributed as dist模型侧
torch.cuda.set_device(opt.local_rank)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[opt.local_rank])
rank = dist.get_rank()
device = torch.device(f'cuda:{opt.local_rank}')
dist.barrier() # synchronizes all processesrank是全局的进程序号,要根据这个参数来设置每个进程所使用的device设备。
local_rank是指的训练进程在当前节点的序号,即所采用的GPU编号。对于local_rank的获取有两种方式,方式一是在训练脚本添加一个命令行参数,程序启动时会对其自动赋值;方式二是采用torch.distributed.launch启动时加上--use_env=True,该情况下会设置LOCAL_RANK这个环境变量。
# 方式一
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
local_rank = args.local_rank
# 方式二
local_rank=int(os.environ["LOCAL_RANK"])数据侧
data_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True)
dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=opt.batchSize,
shuffle=False,
num_workers=int(opt.nThreads),
drop_last=True,
sampler=data_sampler
)注意训练循环过程的每个epoch开始时调用data_sampler.set_epoch(epoch),主要是为了保证每个epoch的划分是不同的,其它的训练代码都保持不变。
有效batch_size其实是batch_size_per_gpu * world_size (world_size为节点总数nnodes乘以每个节点的GPU数nproc_per_node)。
启动方式
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE_PER_NODE
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=1234
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)所有的进程需要知道进程0的IP地址以及端口,这样所有进程可以在开始时同步,一般情况下称进程0是master进程,通常在进程0中打印信息或者保存模型。
参考链接
https://github.com/pytorch/examples/tree/main/imagenet
https://zhuanlan.zhihu.com/p/113694038
https://support.huaweicloud.com/intl/zh-cn/develop-modelarts/modelarts-distributed-0008.html















 9055
9055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









