






1、
1.1 凸优化定义:凸优化,或叫做凸最优化,凸最小化,是数学最优化的一个子领域,研究定义于中的数最小化的问题。即:
- 若可行域X是一个凸集:即对于任给的x,y∈X x,y∈X ,总有
λx+(1−λ)y∈X,对于任意的 λ∈(0,1) λx+(1−λ)y∈X,对于任意的 λ∈(0,1)
- 并且目标函数是一个凸函数:即
f(λx+(1−λ)y))≤λf(x)+(1−λ)f(y) f(λx+(1−λ)y))≤λf(x)+(1−λ)f(y)
我们称这样的优化问题为凸优化问题。
1.2 凸优化一般格式:
那么回到凸优化问题上来, 什么是一个凸优化问题?
一个凸优化问题可以定义为:

其中f是一个凸函数,C是一个凸集。根据先前介绍过的水平子集等概念,上面问题又可以等价写为:

其中,g(x)是凸函数,h(x)是仿射函数。 也就是说,原约束集C被我们表示为一系列凸集的交集(数学上可以证明,凸集的交集还是凸集)。
对于凸函数来讲, 局优就是全局最优。
常见凸优化问题:
- 线性规划
如果f f 和g i gi 都是仿射函数,则凸优化问题变为了线性规划问题:

- 二次规划
线性规划中,如果f f 变为一个凸二次函数,则凸优化问题变为二次规划:

- 二次约束二次规划
f f 和g i gi 都是凸二次函数

- 半定规划

其中,X∈S n X∈Sn 是一个n维对称方阵,并且我们将它约束为半正定矩阵。C,A i C,Ai 都是对称矩阵。这和前面的问题有点不太相同,前面是优化一个向量,而这里是优化一个矩阵。
2、凸优化问题求解方法
2.1 梯度下降法
在机器学习领域中,梯度下降的方式有三种,分别是:批量梯度下降法BGD、随机梯度下降法SGD、小批量梯度下降法MBGD,并且都有不同的优缺点。
下面我们以线性回归算法(也可以是别的算法,只是损失函数(目标函数)不同而已,它们的导数的不同,做法是一模一样的)为例子来对三种梯度下降法进行比较。
1. 线性回归
假设 特征 和 结果 都满足线性。即不大于一次方。这个是针对 收集的数据而言。
收集的数据中,每一个分量,就可以看做一个特征数据。每个特征至少对应一个未知的参数。这样就形成了一个线性模型函数,向量表示形式:

这个就是一个组合问题,已知一些数据,如何求里面的未知参数,给出一个最优解。 一个线性矩阵方程,直接求解,很可能无法直接求解。有唯一解的数据集,微乎其微。
基本上都是解不存在的超定方程组。因此,需要退一步,将参数求解问题,转化为求最小误差问题,求出一个最接近的解,这就是一个松弛求解。
求一个最接近解,直观上,就能想到,误差最小的表达形式。仍然是一个含未知参数的线性模型,一堆观测数据,其模型与数据的误差最小的形式,模型与数据差的平方和最小:
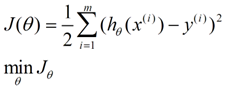
2. 参数更新
对目标函数进行求导,导数如下:

利用梯度下降跟新参数,参数更新方式如下:
 (1)
(1)
3. 批量梯度下降法(Batch Gradient Descent,简称BGD)是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,也就是方程(1)中的m表示样本的所有个数。
优点:全局最优解;易于并行实现;
缺点:当样本数目很多时,训练过程会很慢。
4. 随机梯度下降法:它的具体思路是在更新每一参数时都使用一个样本来进行更新,也就是方程(1)中的m等于1。每一次跟新参数都用一个样本,更新很多次。如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次,这种跟新方式计算复杂度太高。
但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
优点:训练速度快;
缺点:准确度下降,并不是全局最优;不易于并行实现。
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。
5.小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD):它的具体思路是在更新每一参数时都使用一部分样本来进行更新,也就是方程(1)中的m的值大于1小于所有样本的数量。为了克服上面两种方法的缺点,又同时兼顾两种方法的有点。
6.三种方法使用的情况:
如果样本量比较小,采用批量梯度下降算法。如果样本太大,或者在线算法,使用随机梯度下降算法。在实际的一般情况下,采用小批量梯度下降算法。
2.2 坐标下降法
1.首先给定一个初始点,如 X_0=(x1,x2,…,xn);
2.for x_i=1:n
固定除x_i以外的其他维度
以x_i为自变量,求取使得f取得最小值的x_i;
end
3. 循环执行步骤2,直到f的值不再变化或变化很小.
2.3 牛顿迭代法略
3、 最小二乘法与梯度下降法区别
最小二乘是构建目标函数中的一种方法;
梯度下降是求解最优目标函数中的一种方法。
对于变量个数为2-3个的目标函数,可以直接用方程组的方式求解出来,这也就是我们常见的狭义上的最小二乘法。
对于变量个数多个的目标函数,这时,狭义的最小二乘法就难以胜任,而用梯度下降法求解就容易多。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









