







一:项目介绍
本项目是一个支持多人访问的http服务器,在每一个客户端访问服务器的时候可以对其进行目录内的文件列表展示,并且支持文件下载与文件上传的功能,从而达到一个资源共享的目的。
二:项目流程
1.首先搭建服务器
1)为了保证文件下载与文件上传功能的可靠性,该服务器使用TCP协议。TCP协议是一个面向字节流的,可靠 的,面向连接的传输层协议。它的确认应答机制,校验和,序列号,重发机制以及链接管理都可以实现可靠性。
2)应用层使用http协议。http协议支持客户/服务器模式。当客户端请求服务时,只需要传输请求方法与路径。由于http协议简单,程序规模小,因此它通信快速;它每次连接只会处理一个请求,当它处理完客户的请求,并收到客户的应答之后,就会断开连接。
该类具有客户端的socket与线程池任务两个成员变量与与如下主要接口:
- http服务器任务处理函数:接受请求处理对象,并对其进行解析;判断是哪种请求,如果是CGI请求则执行CGI响应,实现文件上传功能;否则执行文件列表展示/文件下载响应。
- http服务器初始化函数:完成TCP与线程池的初始化。
- http服务器执行函数:创建任务与任务入队
http服务器代码:https://github.com/TaoJun724/HttpServer/blob/master/ResourceManagementAssistant/HttpServer.cpp
3)这个服务器需要支持与多个客户端进行连接,在此我实现了一个线程池,当客户端发送一个http请求之后,就创建一个任务对象,将这个任务放在线程池中,让线程池中的线程对于这个请求进行处理,可以避免大量线程频繁的创建与销毁,防止了资源的过度消耗。
线程池代码:https://github.com/TaoJun724/HttpServer/blob/master/ResourceManagementAssistant/HttpServer.cpp
2.实现一个工具类
由于http协议解析时要判断请求方法,url,协议版本为此需要分割字符串接口;以及组织文件信息需要格林威治时间等需求,我们封装一个工具类便于使用。
-
数据分割接口:根据key:val\r\nkey: val\r\nkey: val 从key开始先找到\,再找到下一个key对数据信息进行数据分割。
-
生成Etag接口:ETag:“inode-mtime(最后修改时间)-fsize(文件大小)”\r\n
-
http协议的状态码描述接口:罗列出常用的http协议状态码
-
将数字转换为字符串接口以及字符串转换为数字接口
-
**格林威治转换接口:**将时间戳转换为格林威治时间,time(NULL)获得一个时间戳;gmtime()系统调用:根据一个时间戳获得struct tm结构体;strftime()系统调用:根据struct tm结构体中的内容,将这个时间转换为特定格式的时间。
-
文件类型的描述接口:罗列常见文件的类型
-
获取状态错误码接口
-
获取文件类型的接口
工具类代码:https://github.com/TaoJun724/HttpServer/blob/master/ResourceManagementAssistant/Util.hpp
4.http服务器请求解析类
对于客户端发送过来的http请求进行解析。解析出http请求中的请求方法与url。并且将请求头中的key:value键值对都放在一个map当中。如果请求方法是一个POST那就是文件上传,请求方法是GET,看url有没有参数,如果有参数那也是文件上传,否则就是一个文件请求,对于请求的这个文件,判断是否为目录,是目录就是文件列表展示功能,不是目录就是文件下载功能。
- 判断文件是否是目录的接口
- 判断路径是否合法的接口
- 接受http请求头的接口
- 判断是否为CGI请求
- 文件请求处理接口
- 解析http头部接口
- 解析首行的接口
4.实现一个解析的请求信息类
class RequestInfo{
public:
std::string _method;//请求方法
std::string _version; //协议版本
std::string _path_info; //资源路径
std::string _path_phys; //资源实际路径
std::string _query_string; //查询字符串
std::unordered_map<std::string, std::string> _hdr_list; //头部信息中的键值映射
struct stat _st;//存放文件信息
public:
std::string error_code;//存放错误状态
public:
void SetError(const std::string str)
{
error_code = str;
}
};
5.http服务器响应类
主要接口如下:
-
初始化类:初始化一些请求的响应包括文件的大小,文件的最后一次修改时间等
-
文件下载功能的实现类
首先组织头部信息,发送给客户端,然后在读取文件的数据,将数据全都放在body中发送给客户端就可以了(对于文件下载是将文件数据读取到一个缓冲区中然后再将文件发送出去,所以就要每次都进行读取数据大小的判断)在此我们也实现了断点续传。 -
文件列表功能类:
对于请求的url中的路径是一个目录,将读取该目录下的所有文件进行展示即可,可以根据目录下的每一个文件信息组织一个html页面,通过chunked分块传输,在浏览器进行展示,在组织的时候,表明文件大小,文件的类型,最后一次的修改时间。
判断是否为目录:采用stat结构体,获取该文件的属性然后通过stat结构体中的st_mode字段进行对比(_st.st_mode&S_IFDIR)。 -
CGI请求处理类:对于CGI请求,我们实现的是文件上传功能,我们将http头信息和正文全部交给子进程处理,使用环境变量传递头信息,使用管道传递正文数据,使用管道接受CGI程序的处理结果。
6.上传功能实现类
文件上传就是在服务器的目录下创建一个文件,并且将请求的body中的数据放入其中就好了。对于文件上传涉及到了服务器要对于数据进行处理。如果进行处理就会有可能失败,导致服务器挂掉,所以我们使用CGI(Wed应用程序)来处理而不是让服务器进行处理。
CGI程序:也即是服务器fork出一个子进程,让这个子进程进行exec(程序替换)来进行处理,服务器只需要接收处理好的数据然后再次发送给客户端就可以了。
数据的传输:进程具有独立性。此时我们可以采用匿名管道的方式进行进程间通信。因为父进程需要将数据写到子进程,子进程也要返回数据给父进程,所以我们需要两个管道来进行通信。对于http请求头中的数据,因为是key:value的形式存在的和环境变量一样。所以对于http请求头中的数据就使用环境变量来进行传递就好了。对于body中的数据使用管道子进程exec(程序替换)之后对于管道的文件描述符会发生改变,所以在exec之前必须要进行dup2()系统调用,进行文件描述符的复制。让stdin和stdout分别对应一个管道。
上传功能的流程:
1)首先初始化文件上传信息:从Content-type获取boundry信息,组织first/middle/last boudry信息
2)接着处理文件上传:
从正文起始位置匹配first boundry;从boundry头信息获取上传的文件名称;
继续循环从剩下的信息中匹配middle boundry(可能会有多个middle boundry)
- middle boundry 之前的数据是上一个文件的数据
- 将之前的数据存储到文件中关闭文件
- 从头信息中获取文件名,若有, 则打开文件
当匹配到last boundry时,将boundry之前的数据存储到文件,文件上传处理完毕。
三:项目所用字段
1.在组织文件信息时
需要Content-Length(文件大小)、DATE(日期与时间)、Last_Modified(文件最后一次修改时间)(*下列功能也需要这些字段)
2.文件下载:
实现断点续传就要对于ETag”inode-mtime(最后修改时间)-fsize(文件大小)"\r\n和Last Modify这两个字段才能支持断点续传;
If_Range判断这个文件是否符合常规,请求的是上次响应的ETag;
通过If-Range判断有没有改变,对于If_Range一般是Last Modify中的ETag;
Range:记录需要这次需要请求的文件的数据部分;
If-Range:最后一次修改时间或者是Etag。假设是ETag
举例:
Range:bytes=0~100
文件长度:1000
则传输过程为:
0-100 请求从0到第100字节的数据
101- 请求从101到结尾的数据
-100 请求文件末尾的100个字节
3.文件列表展示
Transfer-Encoding字段:该字段告诉客户端进行分块传输,每次传输正文的一部分,而不是全部上传。它的响应状态码必须是206,并且响应的头信息中需要有Content-Range这个字段。在目录获取时,可能有很多文件,使用分块传输可以提高效率。
rsp_header += "Transfer-Encoding: chunked\r\n";
//按照chunked机制进行分块传输
//chunked发送数据的格式
//假设发送hello
//0x05\r\n :发送的数据的大小,十六进制的
//hello\r\n :发送这么多的数据
//最后一个分块
//0\r\n\r\n :发送最后的一个分块
4.文件上传
对于头部当中的Content-Type,有着一个boundary信息,也就是分隔符。我们通过获取到boundary来对于正文部分的信息进行解析POST方法是文件上传的常用方法。
Content-Type设置为multipart/from-data(多部分获得数据)
对于boundary分为三种:
- –boundary first boundary
- \r\nboundary\r\n middle boundary
- \r\nboundary-- last boundary
boundary的作用:用来对于正文数据进行分割,为了避免和正文内容重复,boundary是http自己生成的。middle boundary可以有着多个,因为有可能是上传多个文件,但是first boundary和lastboundary只可能是有一个组成:在每部分的boundray中, 首先是boundary分割符,紧挨着就是内容的描述信息,之后使用一个空行分隔, 空行后是正文部分,正文部分的后面又紧跟着下一个boundary。
在上传的时候,根据匹配的boundry来创建文件的几种情况:
1.没有匹配到boundary:全是数据直接写入文件,删除写入的文件
2.匹配到部分boundary:将boundary之前的数据写入到文件当中,删除写入的数据.
3.匹配到first boundary:创建/打开文件,删除first boundary:防止下次在匹配到first boundary
4.匹配到middle boundary:要循环匹配,因为有可能会有多个middle boundary,将boundary之前的数据写入到文件中,并且删除写入的数据,在继续在boundary下面查看内容描述符信息,有没有filename,有,创建文件,移除boundary,没有,查看内容描述符信息是否完全,完全,说明此次不是要上传文件,将boundary删除,防止下次不会再次匹配到这个boundary【注意】:本次只是将boundary删除了并没有删除boundary后面的内容描述信息,下次就有可能将这下信息写入到文件当中,但是此时我们没有打开文件所有不会出现将垃圾信息写入到文件当中,不完全,说明从管道中没有读取到完整的信息,再次读取,跳出循环.
5.匹配到last boundary:直接写入数据,并且退出函数.
项目源码:https://github.com/TaoJun724/HttpServer
四:项目效果展示
文件列表:

文件下载:
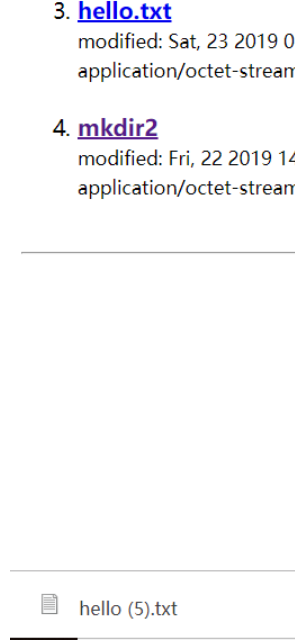
文件上传:

















 7237
7237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









