







 本文介绍了Real-ESRGAN,一个用于增强超分辨率的对抗生成网络,专注于修复模糊照片和低分辨率视频。文章详细阐述了如何安装和配置所需的Python环境、PyTorch框架及CUDA,以及如何克隆和设置项目。此外,还讨论了可能遇到的问题,如CUDA不可用和显存不足,并提供了相应的解决策略。最后,文章展示了修复效果,并提到了其他预训练模型的使用和在线Demo资源。
本文介绍了Real-ESRGAN,一个用于增强超分辨率的对抗生成网络,专注于修复模糊照片和低分辨率视频。文章详细阐述了如何安装和配置所需的Python环境、PyTorch框架及CUDA,以及如何克隆和设置项目。此外,还讨论了可能遇到的问题,如CUDA不可用和显存不足,并提供了相应的解决策略。最后,文章展示了修复效果,并提到了其他预训练模型的使用和在线Demo资源。
Real-ESRGAN:Enhanced Super-Resolution GAN:增强的超分辨率的对抗生成网络,对于GAN相信大家都比较熟悉,前有阿尔法狗,现有很多GAN的延伸版本,StyleGAN1~3系列以及DragGAN对于图片的生成和编辑,出来的效果都很惊艳。
一些旧照片,时代比较久远了,那个时候的像素不够,所以有点模糊,但这都是一种美好回忆,如果能够修复成高清晰的那就好了。这里的Real-ESRGAN就是对这些模糊照片进行处理,生成高清晰的照片,老旧的视频,颜色和分辨率也是比较差,也可以使用Real-ESRGAN进行修复成高清晰的视频。
1、安装环境
1.1、安装前提条件
Python >= 3.7 和 PyTorch >= 1.7
一般本人习惯新建一个虚拟环境来安装(建议看完本文章之后再安装):
conda create -n mypytorch python=3.8
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
安装好了之后就激活环境:activate mypytorch
1.2、克隆仓库
git clone https://github.com/xinntao/Real-ESRGAN.git
cd Real-ESRGAN
当然在克隆的时候,有时会出现下面这样的错误
fatal: unable to access 'https://github.com/xinntao/Real-ESRGAN.git/': Failed to connect to github.com port 443: Timed out
有时是网络问题,如果多次试了还是不行,那最简的办法就是将https修改成http,哈哈泰裤辣。
1.3、安装依赖包
依然推荐加上豆瓣镜像,下载速度快很多
pip install -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com basicsr
pip install -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com facexlib
pip install -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com gfpgan
pip install -r requirements.txt
python setup.py develop
1.4、预训练模型
安装好了之后,我们来测试下:
python inference_realesrgan.py -n RealESRGAN_x4plus -i 1.png -o newimgs
如果没有下载预训练模型:RealESRGAN_x4plus.pth
在推理阶段将自动进行下载: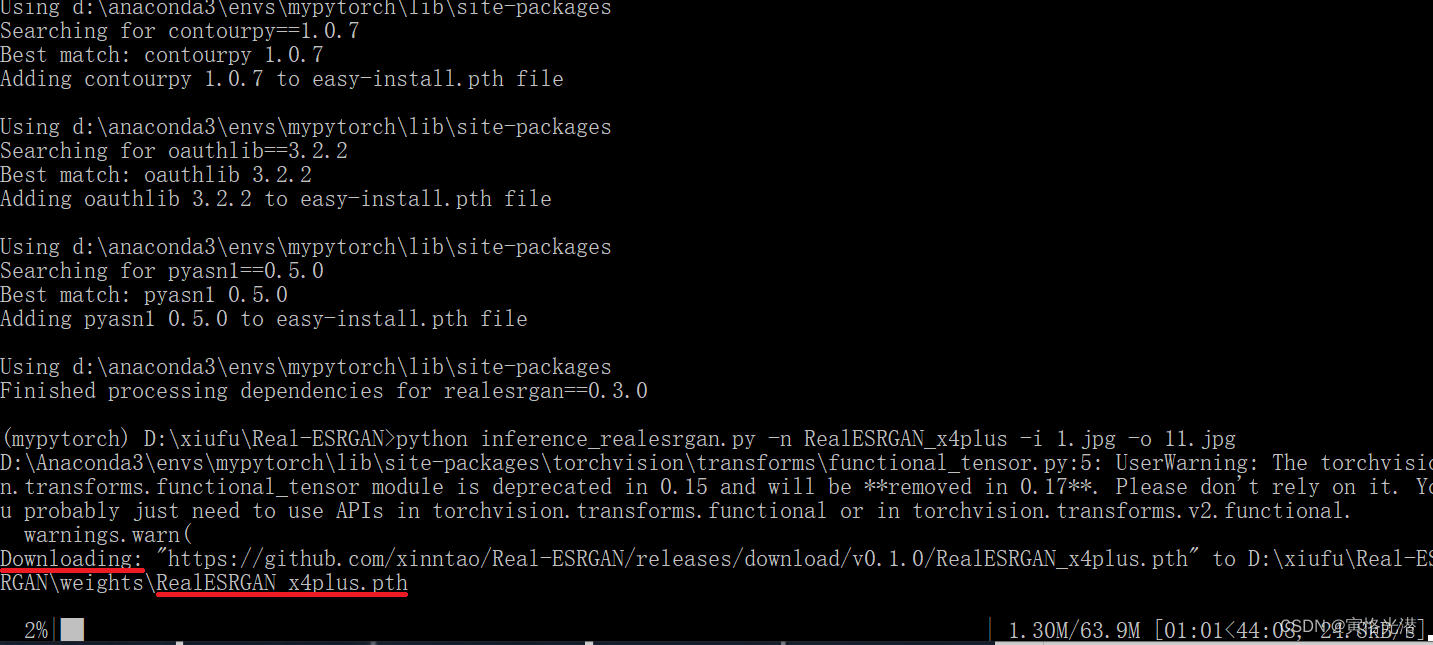
当然也可以自己手动先下载(推荐):RealESRGAN_x4plus.pth预训练模型
然后放到\Real-ESRGAN\weights这个权重目录里面即可,建议使用迅雷下载,虽然文件不大,不过下载速度很慢,所以一般都用迅雷快很多。
2、生成效果比较
我们来看几张效果,本人的一些老照片有点模糊,修复之后,清晰度真的非常不错,而且皮肤更好了,做了美颜效果。

老照片修复
当然有兴趣的还可以使用其他的预训练模型,比如:RealESRGAN_x4plus_anime_6B.pth
RealESRGAN_x4plus_anime_6B.pth预训练模型下载
试下效果会怎么样。
视频也可以,在论文里面也有地址,Demo需要科学上网,有兴趣的可以去试试。
python inference_realesrgan.py -n RealESRGAN_x4plus_anime_6B -i 1.png -o newimgs
这样就会在newimgs文件夹里面生成高清晰的照片了
3、错误处理
在安装之后,运行时会出现一些常见的错误,我们一起来看下
3.1、CUDA不可用
Testing 0 1
Error "slow_conv2d_cpu" not implemented for 'Half'
If you encounter CUDA out of memory, try to set --tile with a smaller number.
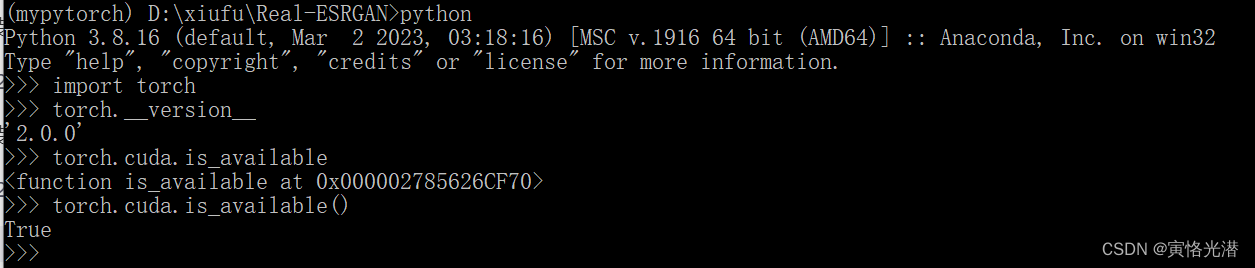
没有CUDA的支持,不能实现半精度。于是查看CUDA的状态是否可用:
torch.cuda.is_available()
奇怪的是返回 False
明明上面已经安装了CUDA的,这种情况,一般是版本匹配问题,试着换一个版本重新安装下:
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
恩,没有问题。返回True
3.2、显存不足
Error CUDA out of memory. Tried to allocate 236.00 MiB (GPU 0; 2.00 GiB total capacity; 1.42 GiB already allocated; 0 bytes free; 1.57 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
If you encounter CUDA out of memory, try to set --tile with a smaller number.
这个就是显存不足了,本人配置比较低,1050的显卡,一些大点的模型基本都很吃力,所以平时测试的时候一般是调低batchnum,图片的输入分辨率,另外就是将需要用到GPU的进程先结束掉,节省一部分出来。所以这个模型基本上能搞定,有兴趣的可以去试试。
在线Demo:https://arc.tencent.com/en/ai-demos/imgRestore
可执行文件:各种OS的执行文件
github地址:https://github.com/xinntao/Real-ESRGAN
论文地址:ESR_Generative_Adversarial_Networks_ECCVW_2018_paper.pdf
后期有时间将论文和源码全部看一遍再发出来一起学习下。



















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











