







保存数据
在pipelines.py文件中定义对数据的操作
1、定义一个管道类
2、重写管道类的process_item方法
3、process_item 方法处理完item之后必须返回给引擎
# 管道类
class Study1Pipeline:
def process_item(self, item, spider):
# item 是爬虫中返回的数据,一般是一个字典
print("itecast:",item)
# 默认使用完管道后需要将数据返回给引擎
return item
在settings.py中配置启用管道
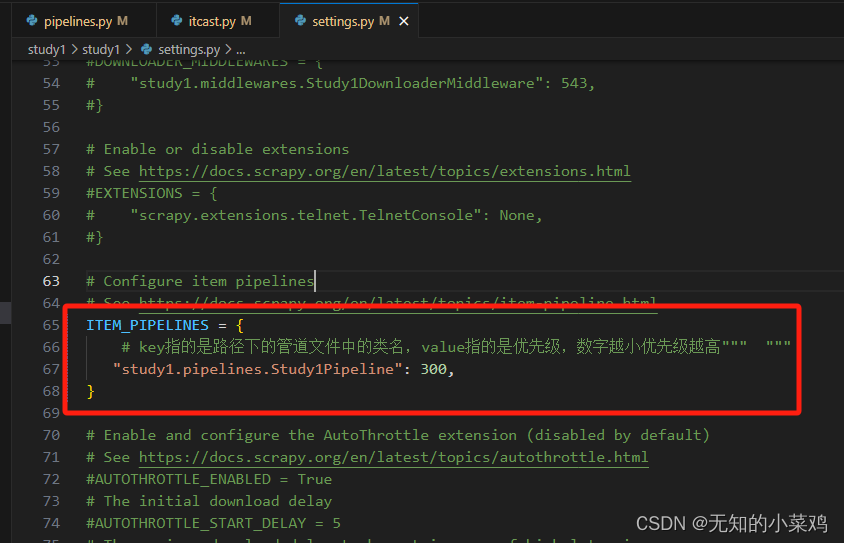
需要注意,如果以上两个操作都完成后。但是还是没有正确打印出print("itecast:",item),是因为你的爬虫文件中最后要返回出一个字典才行

这样在管道中才能拿到数据
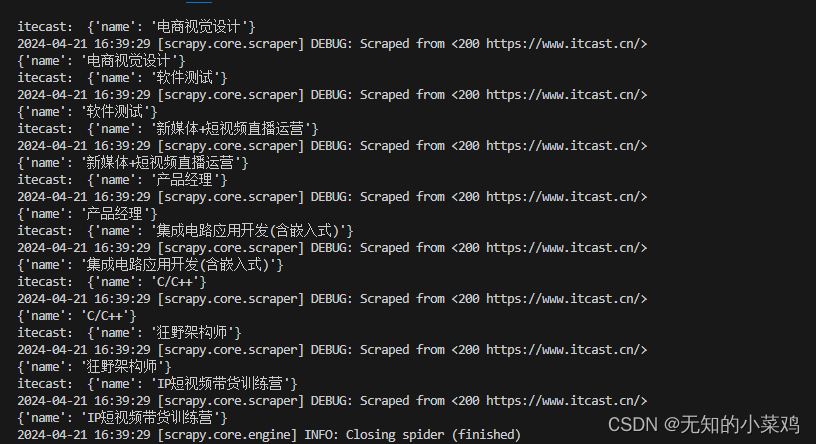
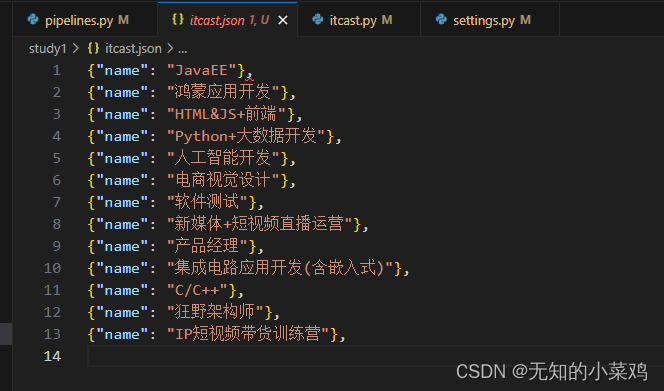
将数据保存到文件中
import json
# 管道类
class Study1Pipeline:
# 类的初始化方法
def __init__(self):
self.file = open('itcast.json','w',encoding='utf-8')
def process_item(self, item, spider):
# item 是爬虫中返回的数据,一般是一个字典
print("itecast:",item)
# 将字典数据序列号,不进行ascii编码
json_data = json.dumps(item,ensure_ascii=False) + ",\n"
# 写入文件
self.file.write(json_data)
# 默认使用完管道后需要将数据返回给引擎
return item
# 用于对象被销毁前,执行一些清理工作
def __del__(self):
# 关闭文件
self.file.close()
scrapy数据建模与请求
数据建模
建模的原因
- 定义
Item即提前规划那些字段需要爬取,防止手误。在定义好后,程序会自动检查 - 配合注释可以清晰的知道要抓取那些字段,没有定义的字段不会被抓取
- 使用
scrapy的一些特定组件需要Item的支持
建模
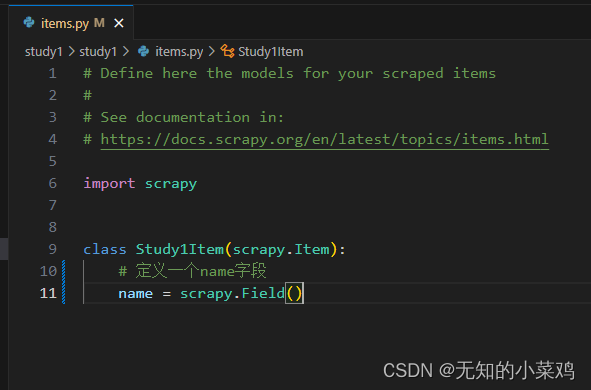
在items.py中定义要爬取的字段,在创建爬虫项目后,会自动生成该文件。
使用
定义好后需要在爬虫中导入并实例化,后续的使用和使用字典相同。
from study1.items import Study1Item
# 继承自Scrapy中的scrapy.Spider基类
class ItcastSpider(scrapy.Spider):
# 爬虫名字
name = "itcast"
# 指定了爬虫允许爬取的域名范围
allowed_domains = ["itcast.cn"]
# 爬虫启动时要首先访问的初始URL,爬虫将从这些起始URL开始抓取网页内容,并逐渐遍历其他相关链接。
start_urls = ["http://itcast.cn/"]
# 解析方法,response时对应的响应
def parse(self, response):
# 使用xpath定位要爬取的内容,爬取精品课程
list_selector = response.xpath("//ul[@class='ulon']/li")
print(len(list_selector))
# 遍历课程列表,获取名称
for li in list_selector:
# temp = {}
# 实例化
item = Study1Item()
name = li.xpath("./a/text()")
# xpath提取数据,返回的是一个列表,使用extract_first()方法提取列表中的第一个元素
# 如果为多个元素,使用extract()方法
# print("name:", name,name.extract_first())
#temp["name"] = name.extract_first()
item['name'] = name
# 使用yield返回数据,而不是return。yield返回数据后,程序会继续执行,直到再次遇到yield,再返回数据
#yield temp
yield item
需要注意返回的item不是一个字典,在管道中使用时要对其进行转换
def process_item(self, item, spider):
# item 是爬虫中返回的数据,一般是一个字典
# 将item转换为字典
item = dict(item)
print("itecast:",item)
# 将字典数据序列号,不进行ascii编码
json_data = json.dumps(item,ensure_ascii=False) + ",\n"
# 写入文件
self.file.write(json_data)
# 默认使用完管道后需要将数据返回给引擎
return item
请求
以翻页请求为例
1、找到下一页的URL地址
2、构造URL地址的请求对象,传递给引擎
实现方法
1、确定url地址
2、构造请求,scrapy.Request(url,callback) 。callback 指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析
3、把请求交给引擎:yield scrapy.Request(url,callback)
实例
爬取字体网站的字体名称、对应的字体类型和链接地址
字体网站:https://www.font.cn/zitiku/?scdh
创建项目:scrapy startproject study2
1、在items.py 文件里进行建模
class Study2Item(scrapy.Item):
# 定义字体的名称和类型
fontName = scrapy.Field()
fontType = scrapy.Field()
2、创建爬虫文件
在项目目录下运行:scrapy genspider font font.cn 其中font是爬虫名称,font.cn是网站域名
3、编写相应基础内容
# 引入建模
from study2.items import Study2Item
class FontSpider(scrapy.Spider):
# 爬虫名称
name = "font"
# 允许访问的域名
allowed_domains = ["font.cn"]
# 起始地址,一般需要进行修改
start_urls = ["https://www.font.cn/zitiku/"]
def parse(self, response):
# 1、提取数据,字体名称和类型
# 1.1 获取所有的节点
node_list = response.xpath("//div[@class='item_top clearfix']")
# print("节点数量:",len(node_list))
# 1.2 遍历节点,获取数据
for num, node in enumerate(node_list):
# 实例化对象
item = Study2Item()
# print(num,node)
name = node.xpath(
"./div[@class='item_top_left']/p/a/text()"
).extract_first()
type = node.xpath(
"./div[@class='item_top_right']/p/a/text()"
).extract_first()
# response.urljoin 将相对路径转换为绝对路径
url = response.urljoin(
node.xpath("./div[@class='item_top_left']/p/a/@href").extract_first()
)
item["fontName"] = name
item["fontType"] = type
item["fontUrl"] = url
print(item)
# 2、模拟翻页
# 2.1 获取下一页的链接
pageBox = response.xpath("//div[@class='PageBox']")
next_url = ''
# 2.2 判断是否有下一页
# 2.3 构建请求对象
yield scrapy.Request(url=next,callback=self.parse)
效果图:
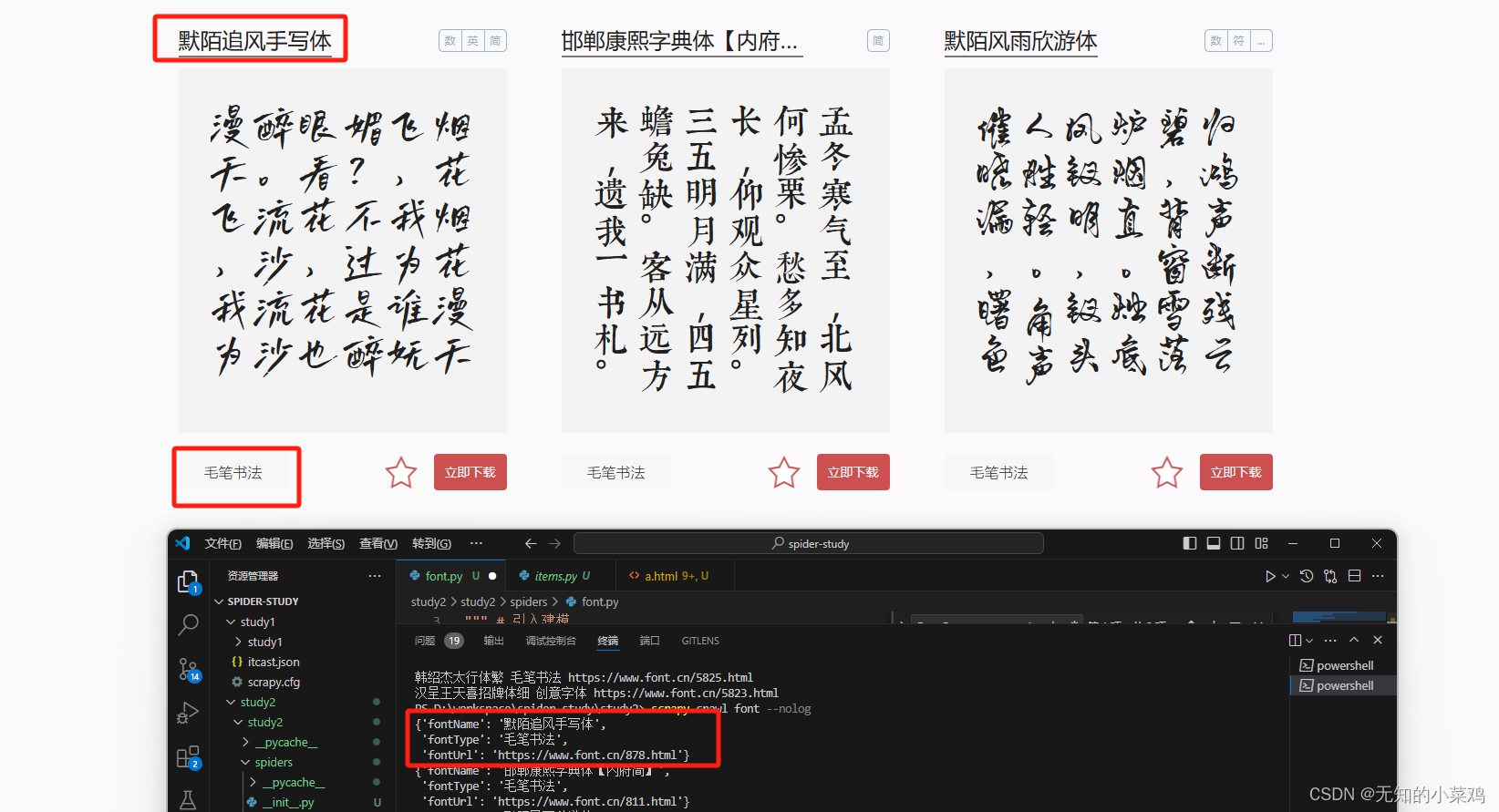
注意:
1、你在浏览器里看到的元素代码是解析后的,但是scrapy获取到的是未经解析过的代码。未经解析过的代码可以直接查看网页源代码
在写xpath时一定要比较一下网页代码是否一致,不一致以网页源代码为准
2、网页源代码中是未经过编译的,所以有些通过javascript生成的代码是拿不到的。就比如上面的分页条是动态生成的拿不到。
因此未实现翻页功能。关于如何处理动态生成的部分,后面学到相关内容后在进行补充。
ROBOTS协议
ROBOTS协议,全称为Robots Exclusion Protocol(网络爬虫排除标准),是一种由网站所有者创建的、位于网站服务器根目录下的纯文本文件,通常命名为robots.txt。这个文件作为网站和网络爬虫(包括搜索引擎爬虫和其他自动抓取工具)之间的通信手段,指示爬虫哪些页面或目录可以抓取,哪些不应被抓取。
可以在settings中设置ROBOTS协议
# False表示忽略协议,默认为True
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
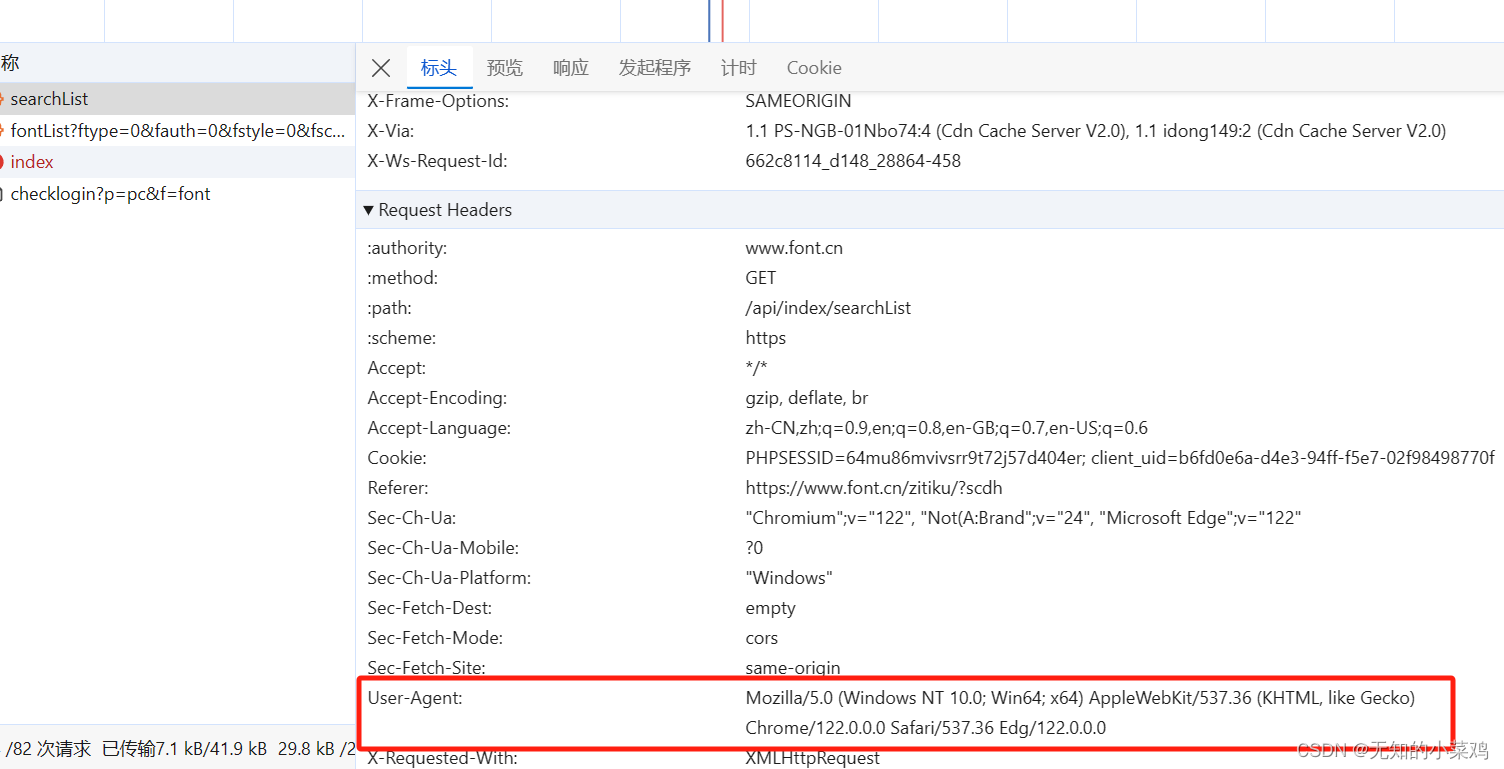
User-Agent
User-Agent 是 HTTP 请求头中的一个字段,用于标识发起请求的应用程序或用户代理软件的信息,包括软件的名称、版本以及其他一些相关信息。当浏览器、搜索引擎爬虫或者其他客户端向Web服务器发起请求时,会在请求头中包含 User-Agent 字段,以便于服务器识别客户端类型并做出相应的响应。

这一部分可以复制实际的User-Agent来进行简单的伪装
















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











