







通过帧间注意提取运动和外观,以实现有效的视频帧插值
Guozhen Zhang1 Yuhan Zhu1 Haonan Wang1 Youxin Chen3 Gangshan Wu1 Limin Wang1, 2, *
1State Key Laboratory for Novel Software Technology, Nanjing University, China
2Shanghai AI Lab, China 3Samsung Electronics (China) R&D Centre, China
paper, code, CVPR2023
Abstract
有效地提取帧间运动和外观信息对于视频帧插值(VFI)具有重要意义。以前的工作要么以混合的方式提取这两种类型的信息,要么为每种类型的信息设计单独的模块,这导致了表示的歧义和低效率。在本文中,我们提出了一个新的模块来显式地提取运动和外观信息。这种混合pipeline可以减轻帧间注意的计算复杂度,也可以保留详细的低层结构信息。
1. Introduction
Motivation.
-
Fig. 1(a) 以混合方式处理外观和运动信息。将相邻的两个帧直接连接并输入到堆叠的相似模块组成的主干中,生成具有混合运动和外观信息的特征。虽然简单,但这种方法需要复杂的设计和提取模块的高容量,因为它需要同时处理运动和外观信息。缺乏显式的运动信息也导致了对任意时间步长插值的限制。
-
Fig. 1(b) 设计单独的模块,用于运动和外观信息的提取。这种方法需要额外的模块,如成本volume,来提取运动信息,这通常会造成很高的计算开销。只提取单帧的图像特征无法捕捉到帧间相同区域的外观信息的对应关系,这是VFI任务的有效提示。
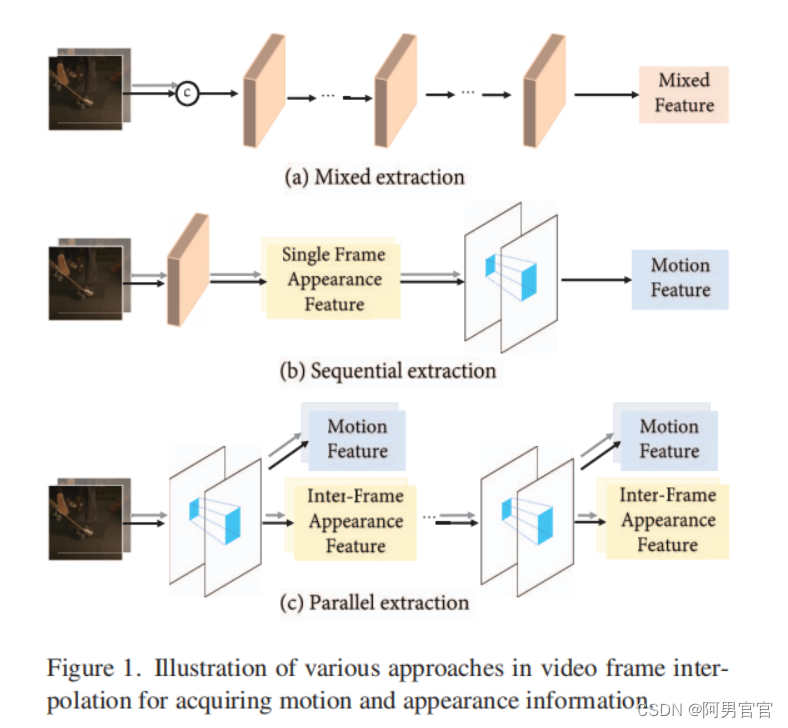
为了解决上述两种提取范式中的问题,本文提出通过帧间注意的统一操作来显式地提取运动信息和外观信息。通过单帧间注意,Fig. 1(c)所示,可以通过重用注意图来增强连续帧之间的外观特征,同时获得运动特征。
具体来说,对于当前帧中的任何patch,将它作为查询,它的时间邻居作为键和值,以推导出表示它们时间相关性的注意映射。然后,利用注意图来聚合邻居的外观特征,从而将当前的区域表示上下文化。此外,利用注意图对邻帧的位移进行加权,得到patch从当前帧到邻帧的近似运动向量。最后,将所得到的特征与轻量网络一起进行运动估计和外观细化,以合成中间帧。
优势
- 每一帧的外观特征可以相互增强,但不与运动特征混合,以保留详细的静态结构信息。
- 运动特征可以按时间进行缩放,然后作为线索,在输入帧之间的任意时刻指导帧的生成。
- 只需要控制复杂性和模块的数量,以平衡整体性能和推理速度。
Pipeline
- 利用CNN提取高分辨率低层特性;
- 使用Transformer Block配备帧间注意提取低分辨率运动特征和帧间外观特征。
2. Related Work
2.1. Video Frame Interpolation
2.2. Extracting Motion and Appearance
2.3. Transformer in Video Frame Interpolation
3. Method
目标是在任意时间步
t
∈
(
0
,
1
)
t\in(0, 1)
t∈(0,1)给定帧
I
0
,
I
1
∈
R
H
×
W
×
3
I_{0},I_{1}\in \mathbb{R}^{H\times W\times 3}
I0,I1∈RH×W×3生成帧
I
^
t
∈
R
H
×
W
×
3
\hat{I}_{t}\in \mathbb{R}^{H\times W\times 3}
I^t∈RH×W×3
I
^
t
=
O
(
I
0
,
I
1
,
t
)
,
\hat{I}_{t}=\mathcal{O}(I_{0}, I_{1}, t),
I^t=O(I0,I1,t),
其中
O
\mathcal{O}
O是提出的模型。
3.1. Extract Motion and Appearance Information
Inter-frame Attention (IFA).
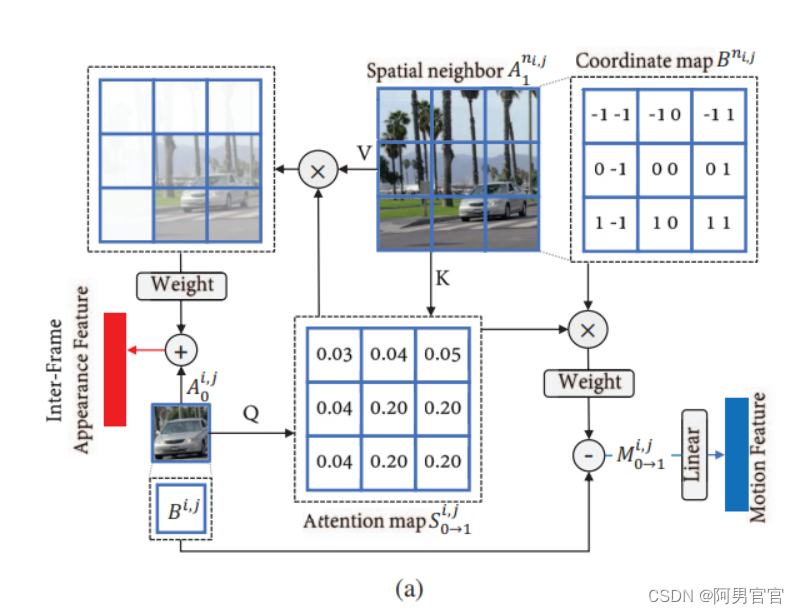
外观信息
上图展示了一个帧间注意如何获得运动和帧间外观的例子。现在假设有两个帧的外观特征,记为
A
0
,
A
1
∈
R
H
^
×
W
^
×
3
A_{0}, A_{1}\in \mathbb{R}^{\hat{H}\times \hat{W}\times 3}
A0,A1∈RH^×W^×3。对于任何区域,在
I
0
I_{0}
I0中表示为
A
0
i
,
j
∈
R
C
A_{0}^{i,j}\in \mathbb{R}^{C}
A0i,j∈RC,使用它和它的空间邻域
I
0
I_{0}
I0中的
A
1
n
i
,
j
∈
R
N
×
N
×
C
A_{1}^{n_{i,j}}\in \mathbb{R}^{N\times N\times C}
A1ni,j∈RN×N×C,其中
N
N
N表示邻域窗口大小,分别来生成查询和键/值。
Q
0
i
,
j
=
A
0
i
,
j
W
Q
,
K
1
n
i
,
j
=
A
1
n
i
,
j
W
K
;
V
1
n
i
,
j
=
A
1
n
i
,
j
W
V
\mathbf{Q}^{i,j}_{0}=\mathbf{A}^{i,j}_{0}\mathbf{W}_{Q},\; \mathbf{K}^{n_{i,j}}_{1}=\mathbf{A}^{n_{i,j}}_{1}\mathbf{W}_{K};\; \mathbf{V}^{n_{i,j}}_{1}=\mathbf{A}^{n_{i,j}}_{1}\mathbf{W}_{V}
Q0i,j=A0i,jWQ,K1ni,j=A1ni,jWK;V1ni,j=A1ni,jWV
其中,
W
Q
,
W
K
,
W
V
∈
R
C
×
C
^
\mathbf{W}_{Q}, \mathbf{W}_{K}, \mathbf{W}_{V}\in\mathbb{R}^{C\times\hat{C}}
WQ,WK,WV∈RC×C^为线性投影矩阵。然后我们做一个点积,在
Q
0
i
,
j
\mathbf{Q}^{i,j}_{0}
Q0i,j和
K
1
n
i
,
j
\mathbf{K}^{n_{i,j}}_{1}
K1ni,j的每个位置,然后应用SoftMax[48]生成注意力地图
S
0
→
1
i
,
j
∈
R
N
×
N
\mathbf{S}^{i,j}_{0\to 1}\in\mathbb{R}^{N\times N}
S0→1i,j∈RN×N,其中每个位置的值代表
A
0
i
,
j
\mathbf{A}^{i,j}_{0}
A0i,j与邻域之间的相似度
S
0
→
1
i
,
j
=
S
o
f
t
M
a
x
(
Q
0
i
,
j
(
K
n
i
,
j
)
T
C
^
)
.
\mathbf{S}^{i,j}_{0\to 1}= SoftMax(\frac{Q^{i,j}_{0}(K^{n_{i,j}})^{T}}{\sqrt{\hat{C}}}).
S0→1i,j=SoftMax(C^Q0i,j(Kni,j)T).
所得到的
S
0
→
1
i
,
j
\mathbf{S}^{i,j}_{0\to 1}
S0→1i,j可以同时变换外观信息和提取运动信息。在外观方面,我们首先将
I
1
I_{1}
I1中的相似外观信息聚合,然后与
A
0
i
,
j
\mathbf{A}^{i,j}_{0}
A0i,j融合,增强
I
0
I_{0}
I0中的外观信息
A
^
0
i
,
j
=
A
0
i
,
j
+
S
0
→
1
i
,
j
V
1
n
i
,
j
.
\mathbf{\hat{A}}^{i,j}_{0}=\mathbf{A}^{i,j}_{0}+\mathbf{S}^{i,j}_{0\to 1}\mathbf{V}^{n_{i,j}}_{1}.
A^0i,j=A0i,j+S0→1i,jV1ni,j.
增强的外观特征
A
^
0
i
,
j
\mathbf{\hat{A}}^{i,j}_{0}
A^0i,j包含了相似区域在两个不同帧中的外观的混合,这可以提供更多关于如何在帧之间转换外观的信息,以生成中间帧。
Motion
对于运动,首先创建一个坐标图
B
∈
R
H
^
×
W
^
×
2
B\in \mathbb{R}^{\hat{H}\times \hat{W}\times 2}
B∈RH^×W^×2,其中每个位置的值表示整个图像的相对位置((-1,-1)在左上角,(1,1)在右下角),如图2(a)。然后我们对相邻的坐标进行加权,以估计出
A
0
i
,
j
\mathbf{A}^{i,j}_{0}
A0i,j在
I
1
I_{1}
I1中的近似对应位置。
A
0
i
,
j
\mathbf{A}^{i,j}_{0}
A0i,j的运动矢量
M
0
→
1
i
,
j
∈
R
2
M^{i,j}_{0\to1}\in \mathbb{R}^{2}
M0→1i,j∈R2可以由
将
A
0
i
,
j
\mathbf{A}^{i,j}_{0}
A0i,j的原始位置与
I
1
I_{1}
I1中的估计位置相减,即可得到
A
0
i
,
j
\mathbf{A}^{i,j}_{0}
A0i,j的运动向量
M
0
→
1
i
,
j
∈
R
2
M^{i,j}_{0\to1}\in \mathbb{R}^{2}
M0→1i,j∈R2
M
0
→
1
i
,
j
=
S
0
→
1
i
,
j
B
n
i
,
j
−
B
i
,
j
M^{i,j}_{0\to1}=\mathbf{S}^{i,j}_{0\to 1}\mathbf{B}^{n_{i,j}}-\mathbf{B}^{i,j}
M0→1i,j=S0→1i,jBni,j−Bi,j
M
0
→
1
i
,
j
M^{i,j}_{0\to1}
M0→1i,j包含了一些运动信息,可以为运动估计提供一个显式的先验。然后通过将
M
0
→
1
i
,
j
M^{i,j}_{0\to1}
M0→1i,j通过一个线性层生成运动特征。值得注意的是,在局部线性运动的假设下,我们可以通过将
M
0
→
1
i
,
j
M^{i,j}_{0\to1}
M0→1i,j乘以
t
t
t来近似为从
I
0
I_{0}
I0到
I
t
I_{t}
It的运动向量
M
0
→
t
i
,
j
=
t
×
M
0
→
1
i
,
j
.
M^{i,j}_{0\to t}=t\times M^{i,j}_{0\to1}.
M0→ti,j=t×M0→1i,j.
这样,
M
0
→
t
i
,
j
M^{i,j}_{0\to t}
M0→ti,j就可以作为线索,指导任意时间步长帧预测的以下运动估计,只计算
M
0
→
1
i
,
j
M^{i,j}_{0\to 1}
M0→1i,j。请注意,外观特征
A
^
0
i
,
j
\mathbf{\hat{A}}^{i,j}_{0}
A^0i,j也与时间步长无关,因此对于多个任意时间步长的帧预测,帧间的注意只需要计算一次。
Discussion.
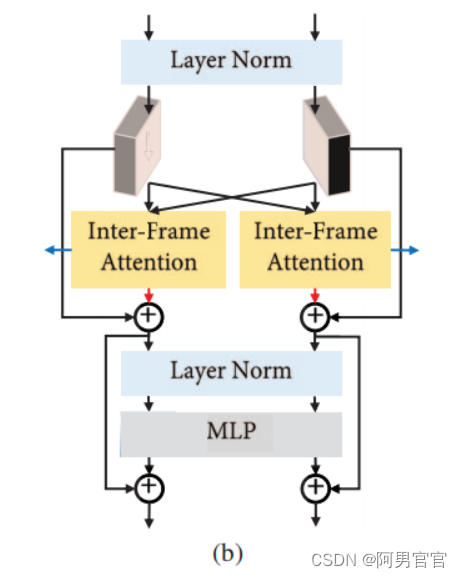
Structure of Transformer blocks.
Fig. 2 (b)所示,我们基本上遵循原始Transformer设计[48],但对VFI任务进行了两点修改: (1)保持不同帧的时空结构,执行IFA提取可区分的特征。(2)为了适应不同大小的输入帧,增强同一帧中不同区域之间的交互,我们采用了与[7,52]类似的策略,在MLP中删除原始位置编码,在MLP中进行深度卷积。
3.2 Overall Pipeline
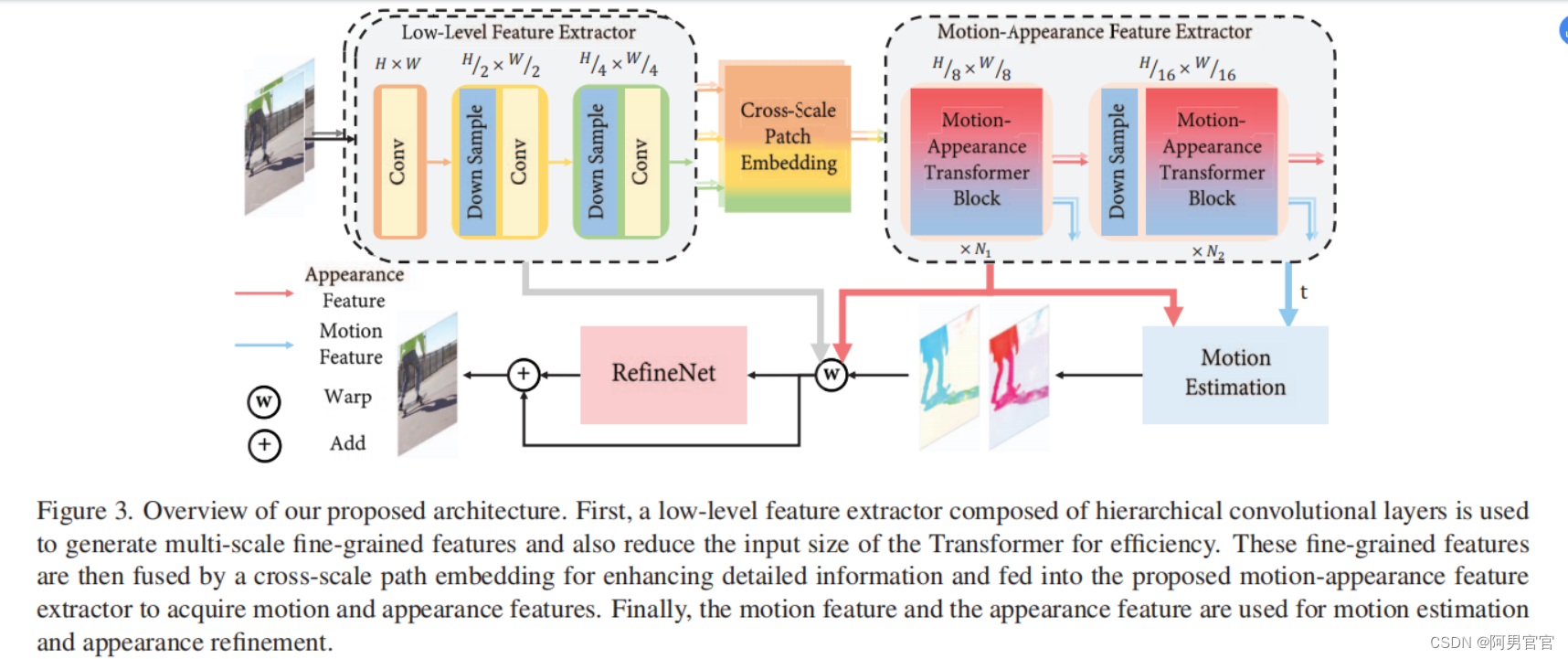
利用分层卷积层作为低级的特征提取器来生成多尺度的外观特征
L
i
0
,
L
i
1
,
L
i
2
=
F
(
I
i
)
L^{0}_{i}, L^{1}_{i}, L^{2}_{i}=\mathcal{F}(I_{i})
Li0,Li1,Li2=F(Ii)
其中,
F
\mathcal{F}
F表示低级特征提取器,
L
i
k
L^{k}_{i}
Lik表示第
i
i
i帧的外观特征,形状为
H
2
k
×
W
2
k
×
2
k
C
\frac{H}{2^k}\times \frac{W}{2^k}\times2^kC
2kH×2kW×2kC。
复用CNN提取的低级特征来补充跨尺度信息。对于形状为
H
2
k
×
W
2
k
×
2
k
C
\frac{H}{2^k}\times \frac{W}{2^k}\times2^kC
2kH×2kW×2kC的低水平特征,采用步幅
2
3
−
k
2^{3-k}
23−k和从1膨胀到
2
2
−
k
2^{2-k}
22−k的展开卷积。然后,将所有获得的特征连接在一起,并将其与一个线性层融合,得到第
i
i
i帧
C
i
C_{i}
Ci的交叉尺度外观特征。通过这种方式,可以为以下Transformer Block提供细粒度的特性。
然后,将
C
0
C_{0}
C0和
C
1
C_{1}
C1输入由包含帧间注意力的Transformer Block组成的分层运动外观特征提取器,提取运动特征
M
i
M_{i}
Mi和帧间外观特征
A
i
A_{i}
Ai。根据运动感知方法,我们首先利用获得的运动和外观特征来估计双向光流
F
F
F和mask
O
O
O,然后我们使用它们来扭曲输入帧到
t
t
t并融合
I
~
t
=
O
⊙
B
W
(
I
0
,
F
t
→
0
)
+
(
1
−
O
)
⊙
B
W
(
I
1
,
F
t
−
1
)
\tilde{I}_{t}=O \odot BW(I_{0},F_{t\to 0})+(1-O)\odot BW(I_{1},F_{t-1})
I~t=O⊙BW(I0,Ft→0)+(1−O)⊙BW(I1,Ft−1)
其中,BW为向后翘曲操作,
⊙
\odot
⊙表示Hadamard乘积。最后,我们进一步利用低级特征
L
L
L和帧间外观特征
A
A
A,通过细化融合帧的外观
I
^
t
=
I
~
t
+
R
e
f
i
n
e
N
e
t
(
I
~
t
,
L
,
A
)
\hat{I}_{t}=\tilde{I}_{t}+RefineNet(\tilde{I}_{t},L,A)
I^t=I~t+RefineNet(I~t,L,A)
由于运动和外观特征已经有了足够的信息,只有三个卷积层来估计运动和一个简化的U-Net [43]来估计re-fine网就足以获得优异的性能。运动估计和细化网的细节在补充材料中提供。
4. Experiments
4.1. Datasets
Vimeo90K, UCF101, Middlebury, SNU-FILM, Xiph, HD, X4K1000FPS
4.2. Implementation Details
4.3. Comparison with the State-of-the-Art Methods
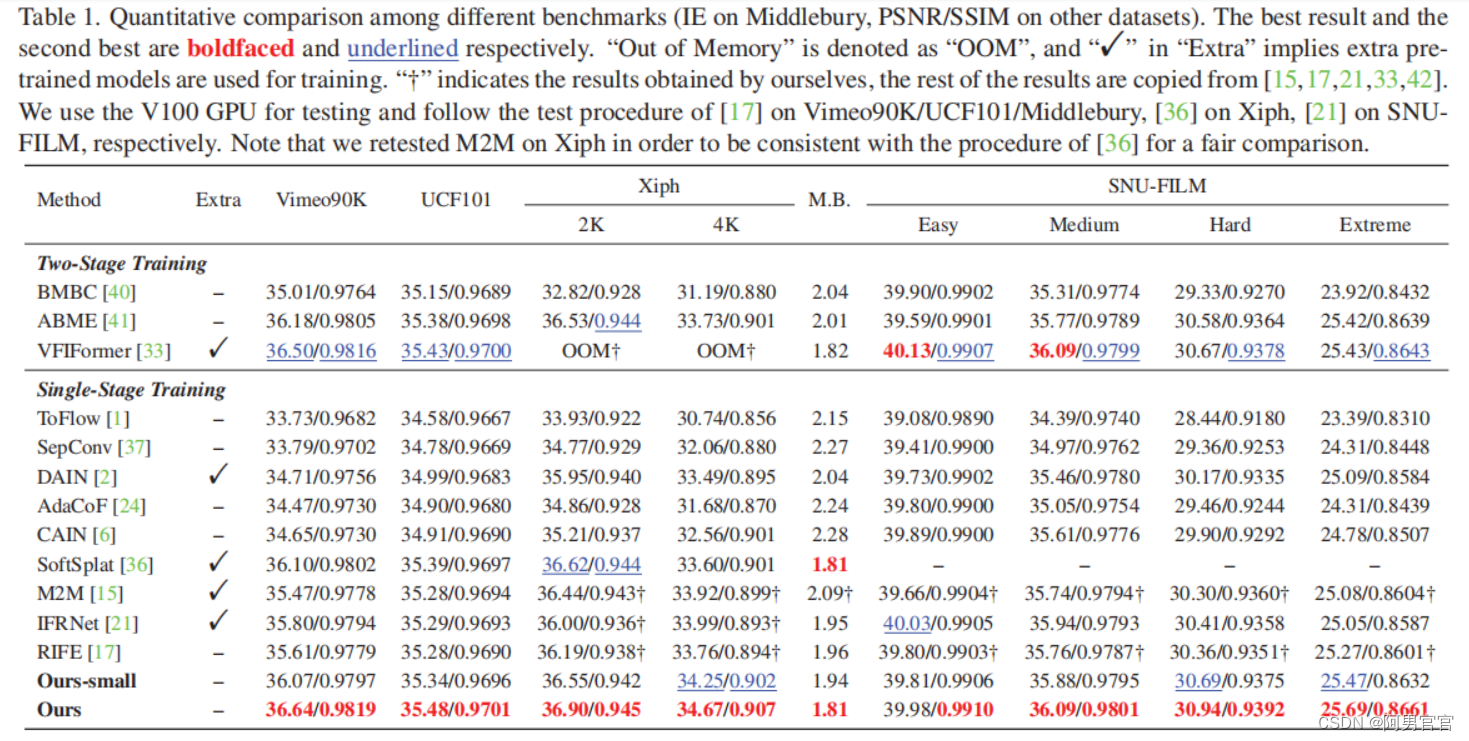

4.4. Ablation Study
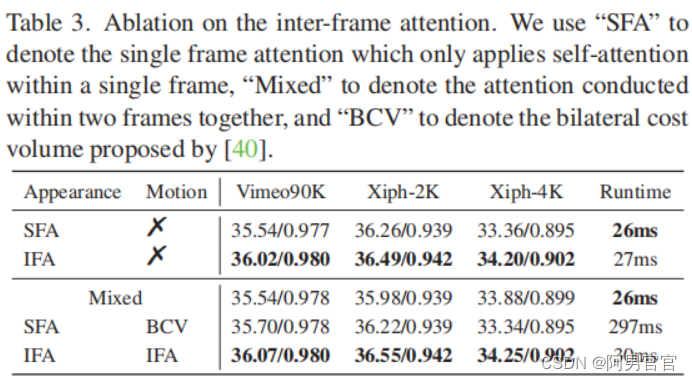

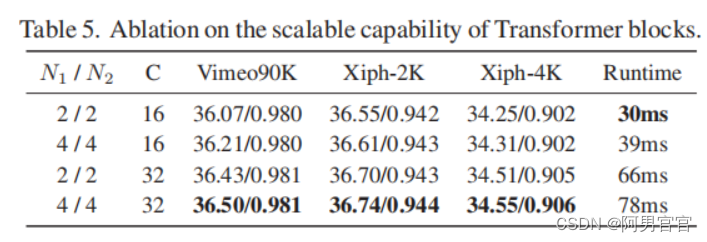
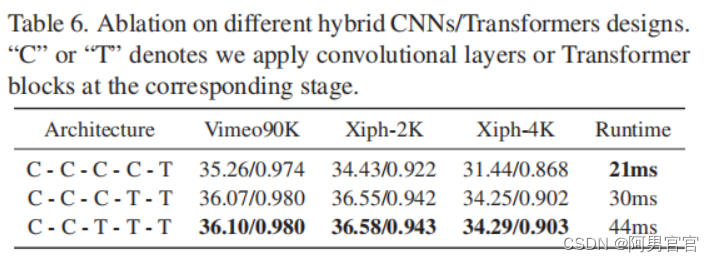















 2307
2307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









