







使用扩散模型的视频插帧(VIDIM)
Siddhant Jain* Google Research
Daniel Watson* Google DeepMind
Eric Tabellion Google Research
Aleksander Hoły´nski Google Research
Ben Poole Google DeepMind
Janne Kontkanen Google Research
Motivation
- 之前的工作中已经提出了许多方法,但当开始和结束帧变得越来越明显时(快速运动、旋转或翻转、形变以及遮挡和揭示),即使是最先进的也不能产生合理的插值,因为这些方法依赖于线性或明确的运动。
- 现有的扩散模型用于视频插值任务,显式地训练那些以开始和结束帧为条件的生成模型,因此无论是在定量结果还是定性结果上,都会得到显著的提升。生成模型的这个关键优势在于它能够产生样本,而不是预测一个确定的均值。这意味着生成模型生成的中间帧具有多样性,能够更好地模拟真实世界中复杂和不确定的运动变化。

Method
遵循级联模型策略,训练单独的baseline和超分模型。虽然维护多个扩散模型会产生额外的开销,但这避免了LDM的一些复杂性,例如找到一个最优的编码解码器模型,以及必须使用其他训练或微调程序来解决解码器中的时间不一致性。
训练两个视频扩散模型:首先,训练一个以2个64x64帧条件的基础模型,在帧之间生成7帧64x64。然后,训练一个以2张256x256帧和7帧64x64为条件的超分辨率模型,生成7个相应的256x256帧。选择奇数帧来评估中间帧,类似于之前的视频插值工作。
Contributions:
- 我们提出了一个级联视频插值扩散模型VIDIM,能够在两个输入帧之间生成高质量的视频。
- 我们仔细地删减了VIDIM的一些设计选择,包括参数共享处理条件框架和使用无分类器引导,展示它们对取得好成绩的重要性。
Overall Framework
VIDIM的灵感来自Imagen Video,其中UNet架构通过在帧上共享所有卷积和自注意块来适应视频生成,并且特征映射只允许在添加查询键值序列长度为帧数的时间关注块的情况下在帧之间混合。将归一化为[0,1]的视频时间戳的简单位置编码(不同帧)求和为通常的噪声水平嵌入(对所有噪声帧相同)。
使用FiLM将这些嵌入传播到每个UNet块,类似于Nichol和Dhariwal。我们对超分辨率模型做了同样的处理,以高分辨率的开始帧和结束帧为条件。超分辨率模型与基本模型的唯一不同之处在于:
(1)它将每个(单纯上采样的)低分辨率条件反射帧连接到沿线的有噪声的高分辨率帧
(2)在第一个卷积残差块之前向下采样,遵循撒哈拉等人的方法来减少内存使用。为了更稳定和有效的训练,额外使用了Dehghani等人的注意力块,它采用了查询键规范化和与注意力块并行运行的MLP块。

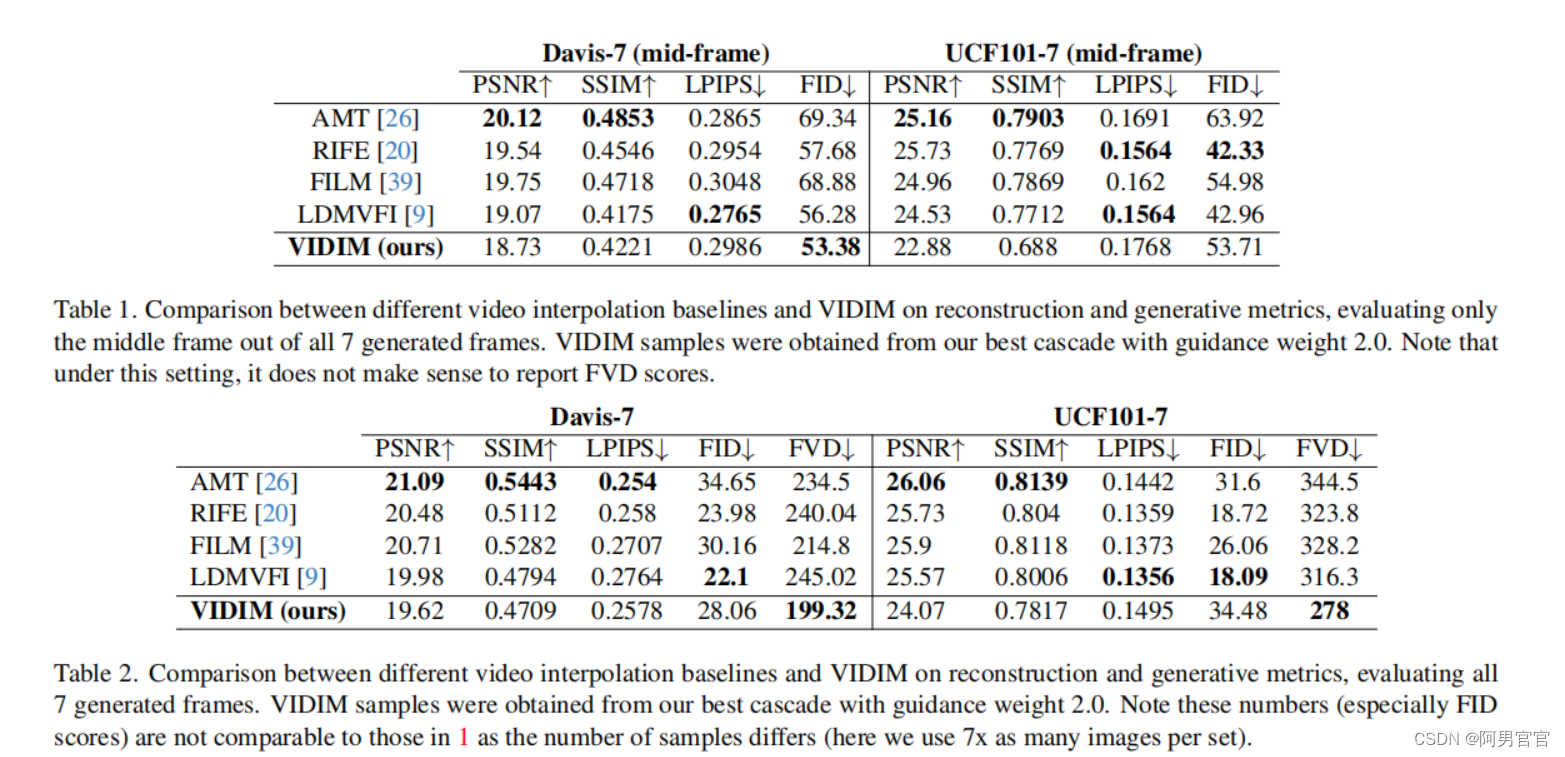
Experiments


















 2755
2755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









