







基于非对称混合的面向感知的视频帧插值
Guangyang Wu1 Xin Tao2 Changlin Li3 Wenyi Wang4 Xiaohong Liu1† Qingqing Zheng5†
1Shanghai Jiao Tong University 2Kuaishou Technology 3SeeKoo
4University of Electronic Science and Technology of China
5Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences
paper, code
文章目录
Motivation
我们广泛地假设,最近的方法通常由3个主要模块组成。运动估计模块利用光流或可变形核来估计连续帧之间的运动。随后,对齐和融合模块通过扭曲算符或可变形卷积来对齐参考帧。最后,重构模块从提取的特征中生成最终结果。尽管最近的方法取得了成功,但模糊的结果和重影现象仍然是不可避免的问题(如图1所示)。

我们将这主要归因于两个固有的挑战:
- 不可避免的运动错误。在现实世界的视频达到无误的像素对应依然具有挑战,尤其在大范围运动下。与以往提高运动估计质量的方法不同,该模型的目标是降低对齐误差。在运动估计不准确的情况下,网络很难识别正确的帧。之前的算法通常通过平均多帧产生模糊的结果。我们认为,基于单一帧的输出,同时利用其他帧补充特定的细节,有可能产生更清晰和可信的结果。
- 时间监督偏错位。VFI任务中另一个容易被忽略的关键问题是时间的不确定性。在训练阶段,地面真实(GT)中间帧只在特定的时间提供参考。在真实世界中,两帧之间的时间间隔内,场景的变化可能是连续且多样的,而不仅仅局限于一个单一的、固定的状态。但在训练阶段,我们通常只能提供一个GT中间帧作为参考,这个GT中间帧仅代表了时间间隔内的一个特定状态。因此,当网络试图学习从输入帧预测中间帧的特征时,它可能会遇到“时间监督错位”的问题。这是因为网络学习到的中间特征可能无法准确地对应于所有可能的中间帧状态,而只是与训练时提供的特定GT中间帧相匹配。为了解决这个问题,传统的像素级损失函数,如L1和L2是不够的。我们选择生成模型来重建从一个分布中采样的结果。
Method
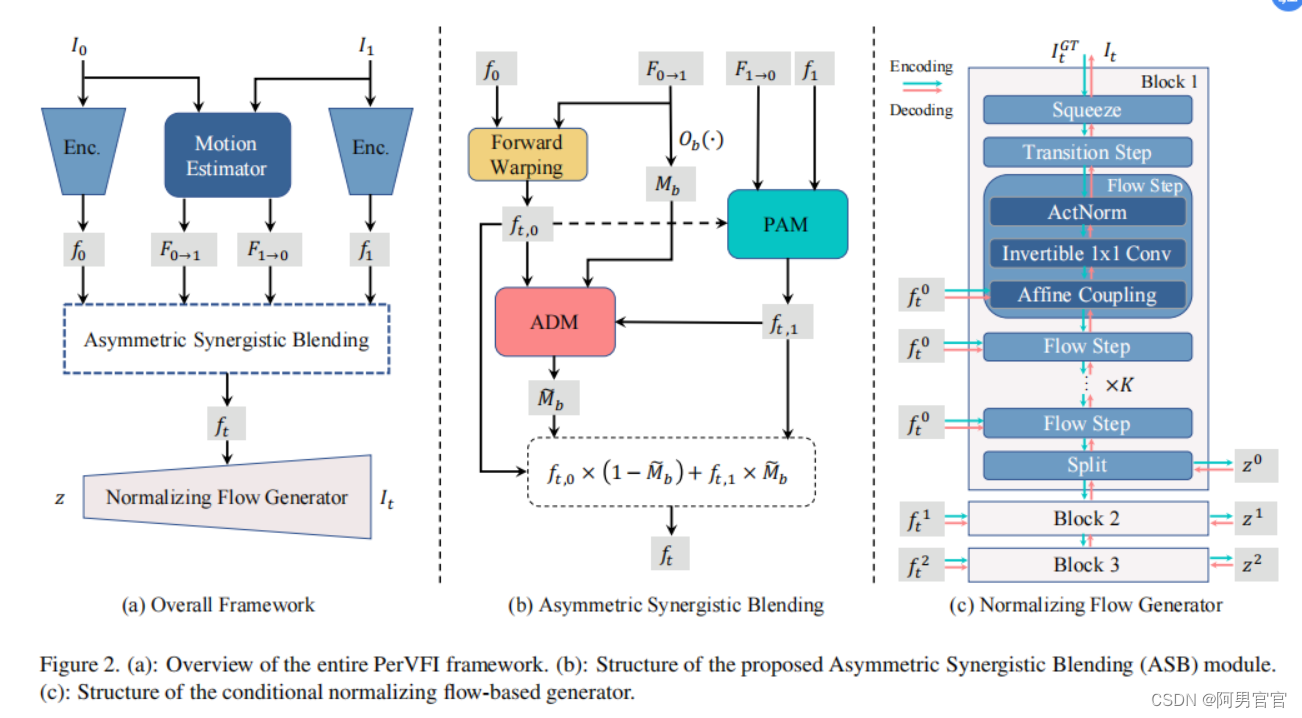
Overall Framework
给定两个高度为H和宽度为W的参考帧图像 I 0 I_{0} I0和 I 1 ∈ R H × W × 3 I_{1}\in\mathbb{R}^{H\times W \times3} I1∈RH×W×3,目标是根据时间 t ∈ ( 0 , 1 ) t\in(0, 1) t∈(0,1)重建中间帧 I t I_{t} It。PerVFI的整体框架如图2- (a)所示,其中包括图2- (b)所示的非对称协同混合模块(ASB)和图2-(c)所示的基于条件归一化流的生成器。
首先估计双向光流,用 F 0 → 1 \mathbf{F}_{0\to 1} F0→1和 F 1 → 0 \mathbf{F}_{1\to 0} F1→0表示。同时,特征编码器将这两帧图像编码为 L L L级的金字塔特征, f i = E θ ( I i ) f_{i}=\mathcal{E}_{\theta}(I_{i}) fi=Eθ(Ii),其中 i = 0 , 1 i=0, 1 i=0,1。双向光流和金字塔特征喂给特征混合模块ASB,得到中间金字塔特征 f t = B θ ( t , f 0 , f 1 , F 0 → 1 , F 1 → 0 ) f_{t}=\mathcal{B}_{\theta}(t,f_{0},f_{1},\mathbf{F}_{0\to 1}, \mathbf{F}_{1\to 0}) ft=Bθ(t,f0,f1,F0→1,F1→0) 。
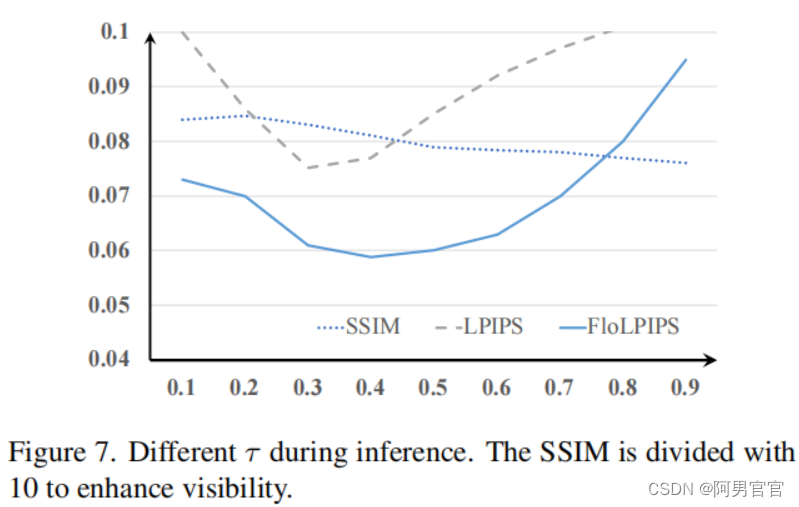
然后,使用基于条件归一化流的可逆的生成器 G θ \mathcal{G}_{\theta} Gθ将 f t f_{t} ft解码成输出帧 I t = G θ − 1 ( z ; f t ) I_{t}=\mathcal{G}^{-1}_{\theta}(z;f_{t}) It=Gθ−1(z;ft),这里的 z ∼ N ( 0 , τ ) ∈ R H × W × 3 z\sim\mathcal{N}(0,\tau)\in\mathbb{R}^{H\times W\times 3} z∼N(0,τ)∈RH×W×3是一个从服从 τ \tau τ的正态分布中采样的变量。
非对称协同混合模块(ASB)
ASB模块由两个主要组件组成:金字塔对准模块(PAM)和自适应扩张模块(ADM)。PAM的设计是为了实现更精确的两侧特征对齐,而ADM旨在提供一个准二进制mask,可以作为一个加权mask更好地处理遮挡。
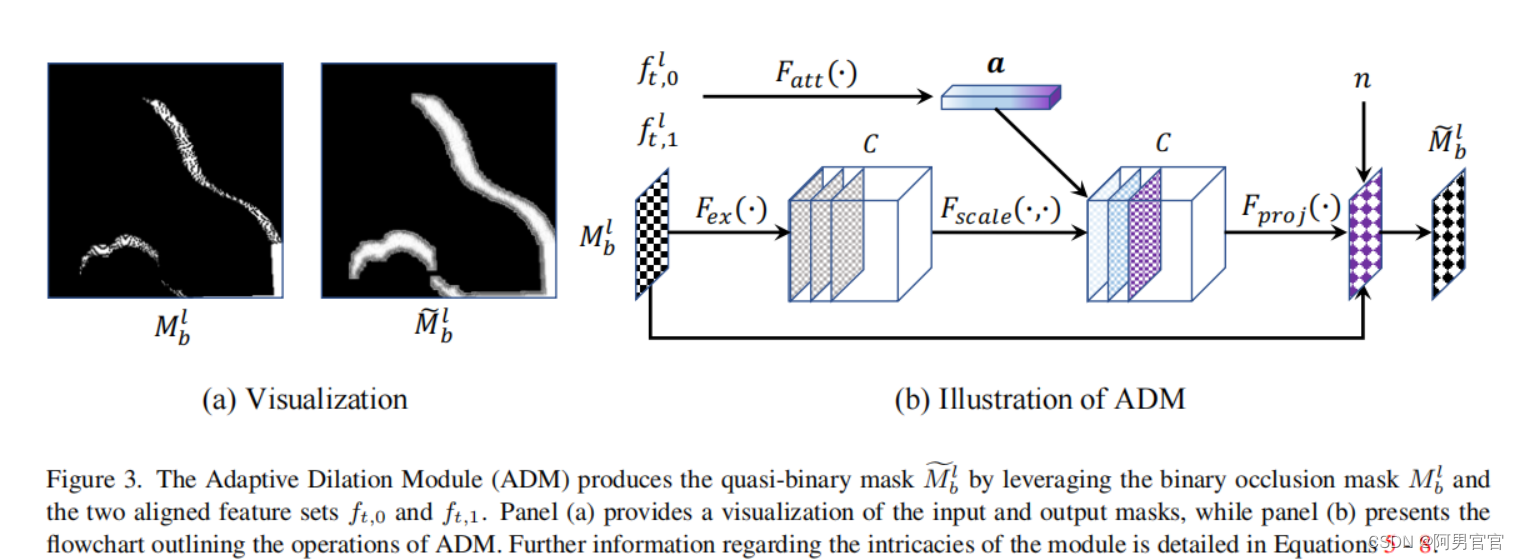
基于条件归一化流的可逆的生成器
为了参数化条件分布 p ( I t ∣ f t ) p(I_{t}|f_{t}) p(It∣ft),设计了一个可逆神经网络 G θ \mathcal{G}_θ Gθ,它将中间特征 f t f_t ft和目标图像 I t I_t It映射到一个潜在变量 z = G θ ( I t ; f t ) z=\mathcal{G}_{\theta}(I_t;f_t) z=Gθ(It;ft)。通过使用可逆归一化流生成器 G θ \mathcal{G}_θ Gθ,保证了 I t I_t It可以从潜在编码 z z z精确地重构为 y = G θ − 1 ( z ; f t ) y=\mathcal{G}^{-1}_{\theta}(z;f_t) y=Gθ−1(z;ft)。通过假设在潜在空间 z z z中有一个简单的分布 p z ( z ) p_z(z) pz(z)(例如,高斯分布),通过 z ∼ p z z\sim p_z z∼pz的映射 y = G θ − 1 ( z ; f t ) y=\mathcal{G}^{-1}_{\theta}(z;f_t) y=Gθ−1(z;ft)隐式地定义了分布 p ( I t ∣ f t , θ ) p(I_t|f_t,\theta) p(It∣ft,θ)。
Experiments
Experiments Setting
训练数据集由来自公开可用的Vimeo-90k数据集的训练部分的框架组组成。在整个训练过程中,我们使用了256×256的patch大小,每次迭代的batchsize大小为16。使用了带有默认超参数设置的ADAM优化器,并且初始学习速率被设置为 5 e − 4 5e^{−4} 5e−4。学习率每20epoch就减半一次。使用2张3090在64epoch左右PerVFI模型被训练到收敛。
Quantitative&Qualitative Evaluation
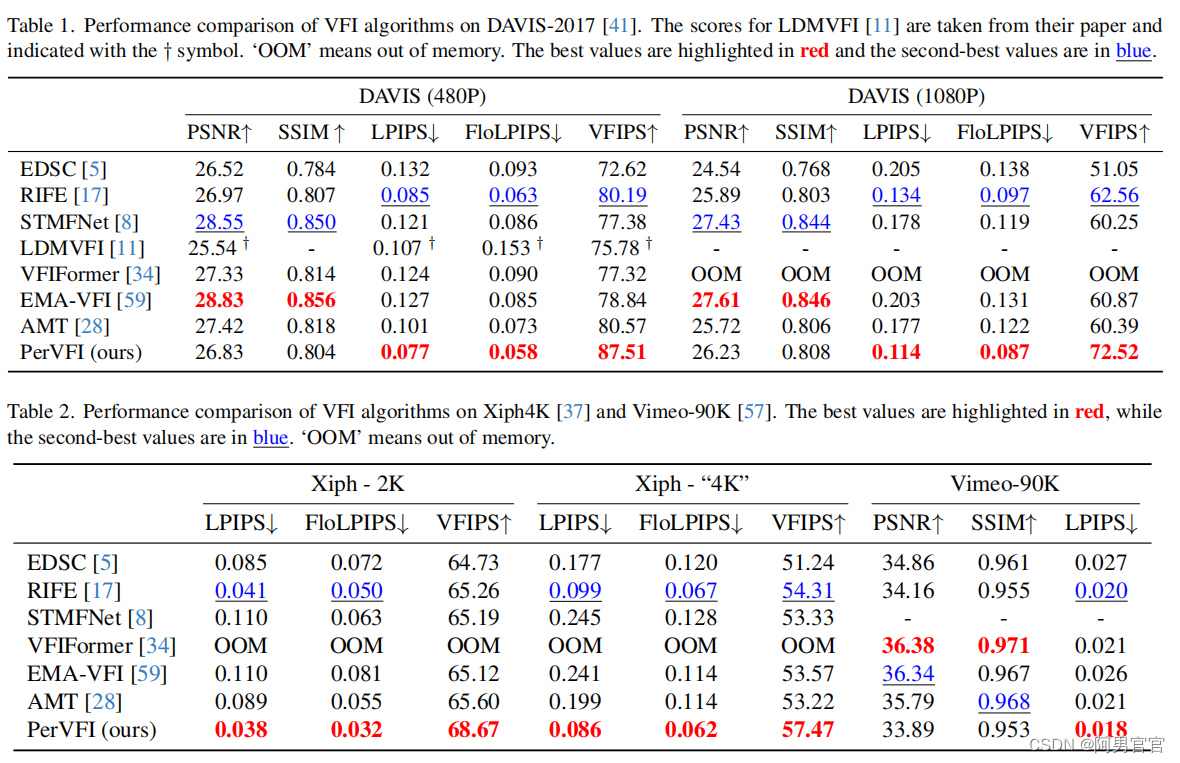
Ablation Experiments
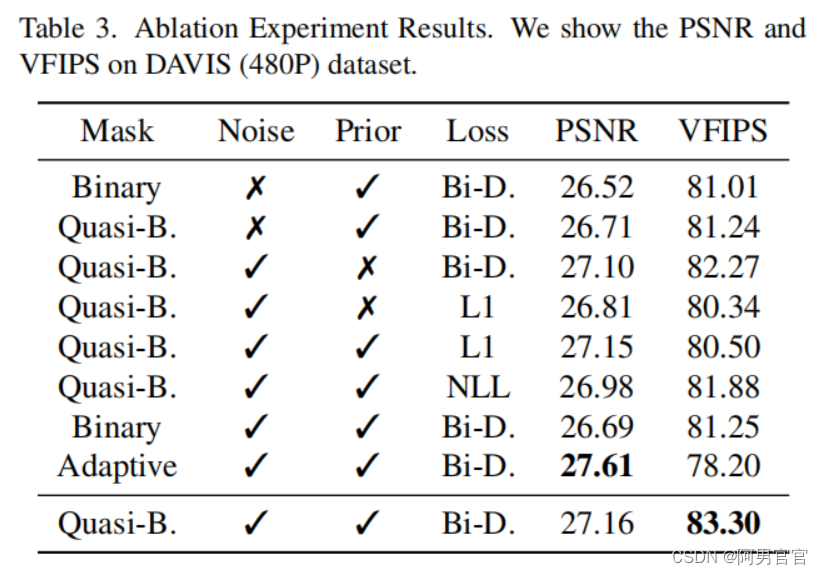
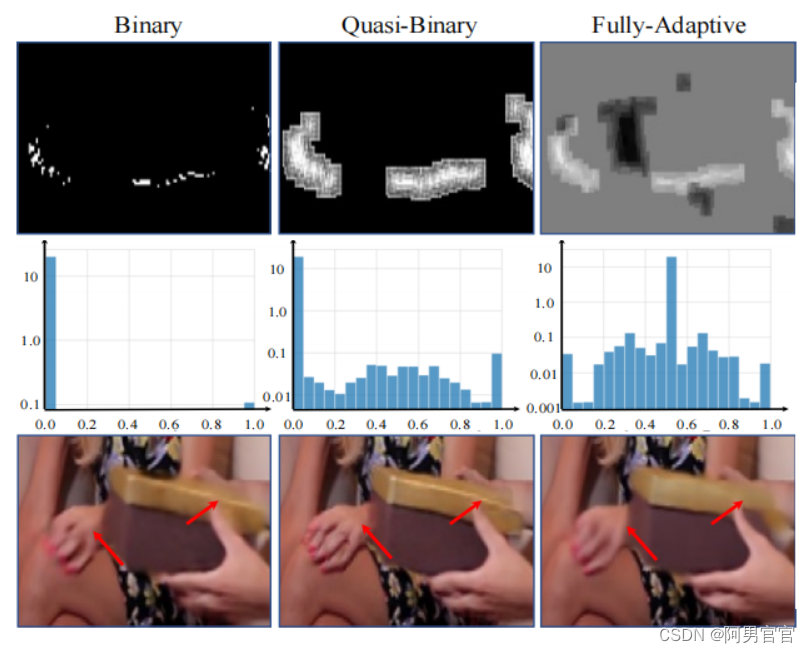
第一行显示不同的掩模,第二行显示每个mask的直方图。完全自适应mask倾向于以0.5左右为中心,表明两侧特征的贡献相等。准二进制mask在部分自适应的同时保持稀疏性,提供了一种有效的混合机制。第三行显示了使用这些mask的结果。红色箭头强调了准二进制掩模在视觉质量上表现突出的区域。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









