







AVID: 用扩散模型做任意长度视频的编辑
paper
Motivation
文本引导的视频编辑有三个主要挑战:
- 编辑前后视频时间的一致性。如果一个整个对象被渲染,它的身份应该在整个视频中持续存在。例如,如果汽车的颜色变成绿色,色调必须从开始到结束保持一致,汽车应该保持相同的绿色阴影,而不是从霓虹灯绿色过渡到一个更深的变种。
- 在不同的结构保真度级别支持不同的编辑类型。例如对象替换、纹理编辑。
- 如何处理可变视频长度。希望一个好的模型可以稳健地处理任意时间长度的视频。

Contributions:
- 将运动模块集成到T2I的插入绘制模型中,在视频序列上对其进行优化,确保时间一致性。
- 针对不同子任务定制结构指导模块,可以根据任务和编辑需要控制不同程度的输出对输入视频的结构保真度。
- 采用zero-shot生成技术处理不同时间长度的视频。同时引入中帧注意引导方法,保证在拉长的视频序列中的时间一致性。
Method
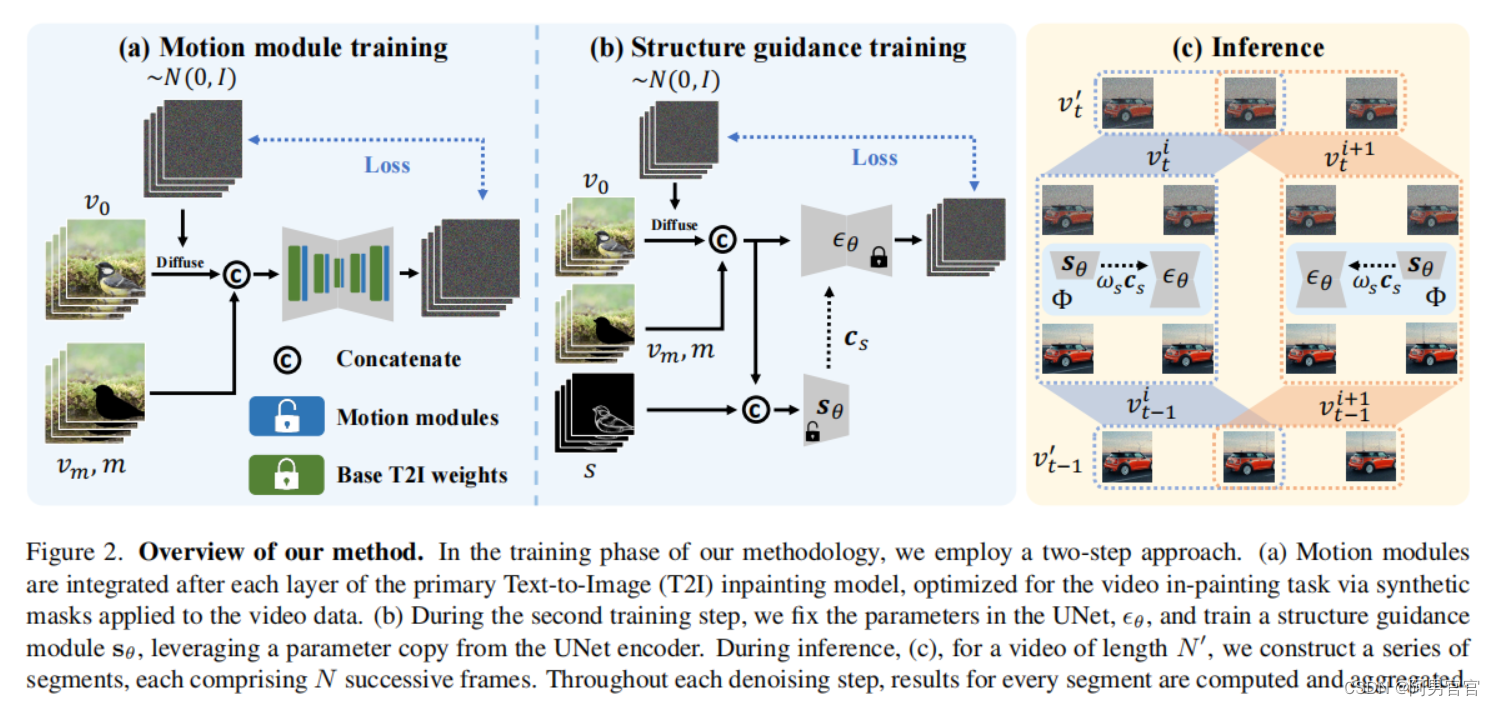
Motion module training
运动模块在主文本到图像(T2I)初始绘制模型的每一层后进行集成,通过对视频数据应用合成掩模对视频初始绘制任务进行优化。
输入视频帧 v 0 v_{0} v0和mask序列 m m m
Structure guidance training
改变纹理需要保存原视频的结构,因此设计了结构引导训练。
输入
v
0
v_{0}
v0和mask序列
m
m
m,使用结构提取器
S
S
S获得每一帧的结构condition,
cs由13个特征图在4个不同的分辨率组成。
ϵ
θ
\epsilon_{\theta}
ϵθ是固定参数的UNet。
Inference
应用N帧的滑动窗口,将长视频 v t ′ v_{t}' vt′分割成重叠的片段,在每段重叠帧应用一次提出的方法。
中间帧注意指导。
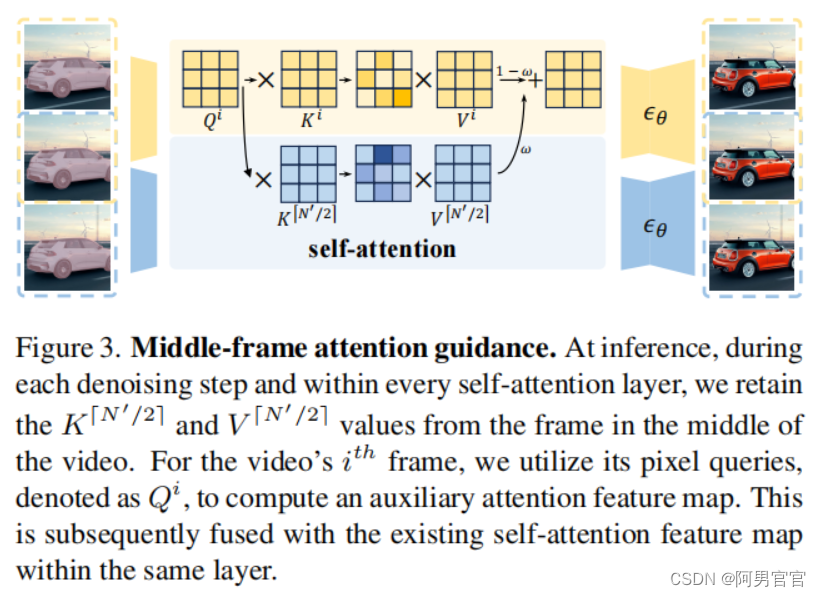
在推断中,在每个去噪步骤和每个自我注意层中,保留了视频中间一帧中的K和V两个值。对于视频的第i帧,我们利用它的像素查询,即Qi,来计算一个辅助的注意特征图。这随后与同一层内现有的自注意特征图相融合。

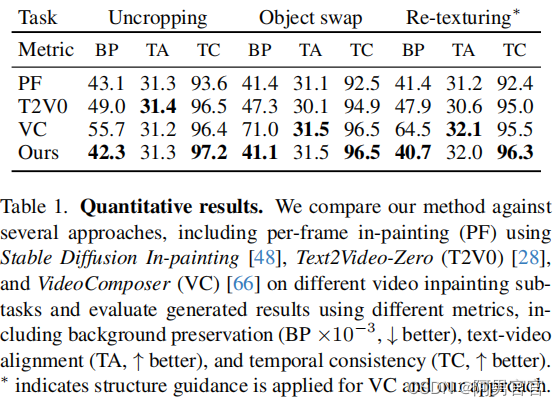
Experiment



















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









