







The ML4T Workflow: From ML Model to Strategy Backtest
ML4T工作流程:从ML模型到策略回测
本章集成了机器学习交易(ML4T)工作流程的各个组成部分,提供了从设计、模拟到评估ML驱动交易策略的端到端视角。最重要的是,它更详细地展示了如何使用Python库backtrader和Zipline准备、设计、运行和评估回测。
ML4T工作流程的最终目标是从历史数据中收集证据,以帮助决定是否在实盘市场部署候选策略并承担财务风险。这个过程建立在您在前几章中发展的技能之上,因为它依赖于您:
- 使用多样化的数据源来构建有信息量的因子
- 设计ML模型生成预测信号以指导交易策略
- 从风险收益角度优化所得投资组合
对策略的现实模拟还需要忠实地反映证券市场的运作方式和交易执行方式。因此,交易所的制度细节,如可用的订单类型和价格决定机制(参见第2章 市场和基本面数据)在设计回测或评估回测引擎是否包含所需的准确业绩测量功能时也很重要。最后,还有几个方法学方面需要注意,以避免偏差结果和错误发现,从而导致投资决策不佳。
用于某些回测模拟的数据由data_prep.py脚本在data目录中生成,基于第7章 线性模型中的线性回归收益预测。
内容
如何回测ML驱动策略
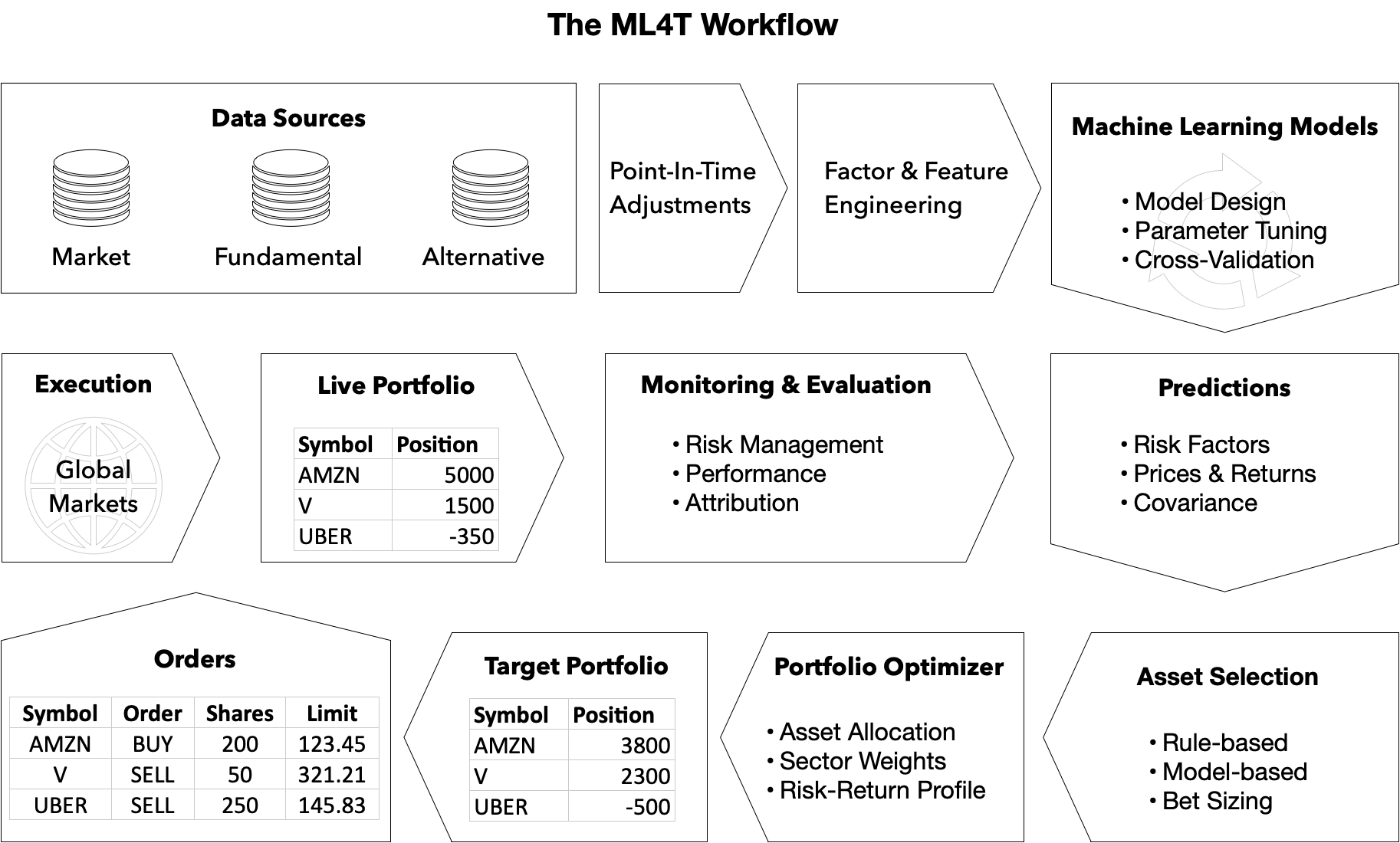
简而言之,ML4T工作流程是关于回测利用机器学习生成交易信号、选择和调整仓位或优化交易执行的交易策略。它包括以下步骤,针对特定的投资领域和时间范围:
- 获取和准备市场、基本面和替代数据
- 构建预测性alpha因子和特征
- 设计、调整和评估ML模型以生成交易信号
- 根据这些信号决定交易,例如应用规则
- 在投资组合背景下调整个别仓位
- 使用历史市场数据模拟生成的交易
- 评估所得仓位的表现
回测的陷阱及如何避免
回测基于历史数据模拟算法策略,目的是产生可推广到新市场条件的业绩结果。除了在不断变化的市场环境中预测的一般不确定性外,几个实施方面还可能偏斜结果,增加将样本内表现误认为是样本外模式的风险。
获取正确的数据
破坏回测有效性的数据问题包括:
- 前瞻性偏差
- 存活偏差
- 异常值控制
- 样本期选择
获得正确的模拟
与历史模拟实施相关的实际问题包括:
- 未能按市价计价以准确反映市场价格和账户回撤;
- 对交易可用性、成本或市场影响的不现实假设;
- 信号和交易执行时间不正确。
获得正确的统计:数据窥探和回测过拟合
包括已发表结果在内的回测有效性最突出的挑战,与策略选择过程中多次测试同一数据导致的虚假模式发现有关。在同一数据上测试不同候选策略后进行选择,很可能会偏斜选择,因为正面结果更可能是由于业绩度量本身的随机性质造成的。换句话说,该策略过度拟合于手头的数据,产生具有欺骗性的积极结果。
Marcos Lopez de Prado广泛发表了关于回测风险及其检测和避免方法的著作。这包括一个在线回测过拟合模拟器。
代码示例:收缩Sharpe比率
De Lopez Prado和David Bailey推导出一个收缩Sharpe比率,在控制多次测试、非正态收益和较短样本长度的膨胀效应的同时,计算Sharpe比率具有统计显著性的概率。
multiple_testing目录中的Python脚本deflated_sharpe_ratio包含相关公式推导的参考文献。
参考文献
- The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting and Non-Normality, Bailey, David and Lopez de Prado, Marcos, Journal of Portfolio Management, 2013
- Backtest Overfitting: An Interactive Example
- Backtesting, Lopez de Prado, Marcos, 2015
- Secretary Problem (Optimal Stopping)
- Optimal Stopping and Applications, Ferguson, Math Department, UCLA
- Advances in Machine Learning Lectures 4/10 - Backtesting I, Marcos Lopez de Prado, 2018
- Advances in Machine Learning Lectures 5/10 - Backtesting II, Marcos Lopez de Prado, 2018
回测引擎的工作原理
简单地说,回测引擎遍历历史价格(和其他数据),将当前值传递给您的算法,收到订单作为回报,并跟踪所得仓位及其价值。实际上,要创建ML4T工作流程所描述的真实和稳健的模拟,需要满足众多要求。向量化和事件驱动方法之间的差异说明了忠实再现实际交易环境增加了显著复杂性。
向量化vs事件驱动回测
向量化回测是评估策略的最基本方式。它只是将表示目标头寸大小的信号向量与投资期收益向量相乘,以计算期间业绩。
代码示例:简单的向量化回测
我们使用在第7章中创建的日收益预测来说明向量化方法。
- 本节的代码示例在笔记本vectorized_backtest中。
关键实现方面
满足现实模拟要求可以由一个支持该过程所有步骤的单一平台完成,也可以由专注于不同方面的多个工具完成。例如,您可以使用我们在本书中遇到的scikit-learn等通用ML库设计和测试生成信号的ML模型,并将模型输出输入单独的回测引擎。或者,您可以在像Quantopian和QuantConnect这样的单一平台上端到端运行整个ML4T工作流程。
为了实现这个过程,需要解决以下实现细节,并在本章节中进行更详细的讨论:
- 数据摄取:格式、频率和时间
- 因子工程:内置计算vs第三方库
- ML模型、预测和信号
- 交易规则和执行
- 业绩评估
backtrader:灵活的本地回测工具
backtrader是一个流行、灵活、用户友好的Python库,由Daniel Rodriguez自2015年以来开发,用于本地回测。除了大量活跃的个人交易者社区,也有几家银行和交易公司使用backtrader来原型和测试新策略,然后将其移植到生产就绪的平台,如Java。您还可以使用backtrader进行实盘交易,与多家经纪商集成(参见backtrader文档和第23章 下一步)。
- 本节的代码示例在笔记本backtesting_with_backtrader中。
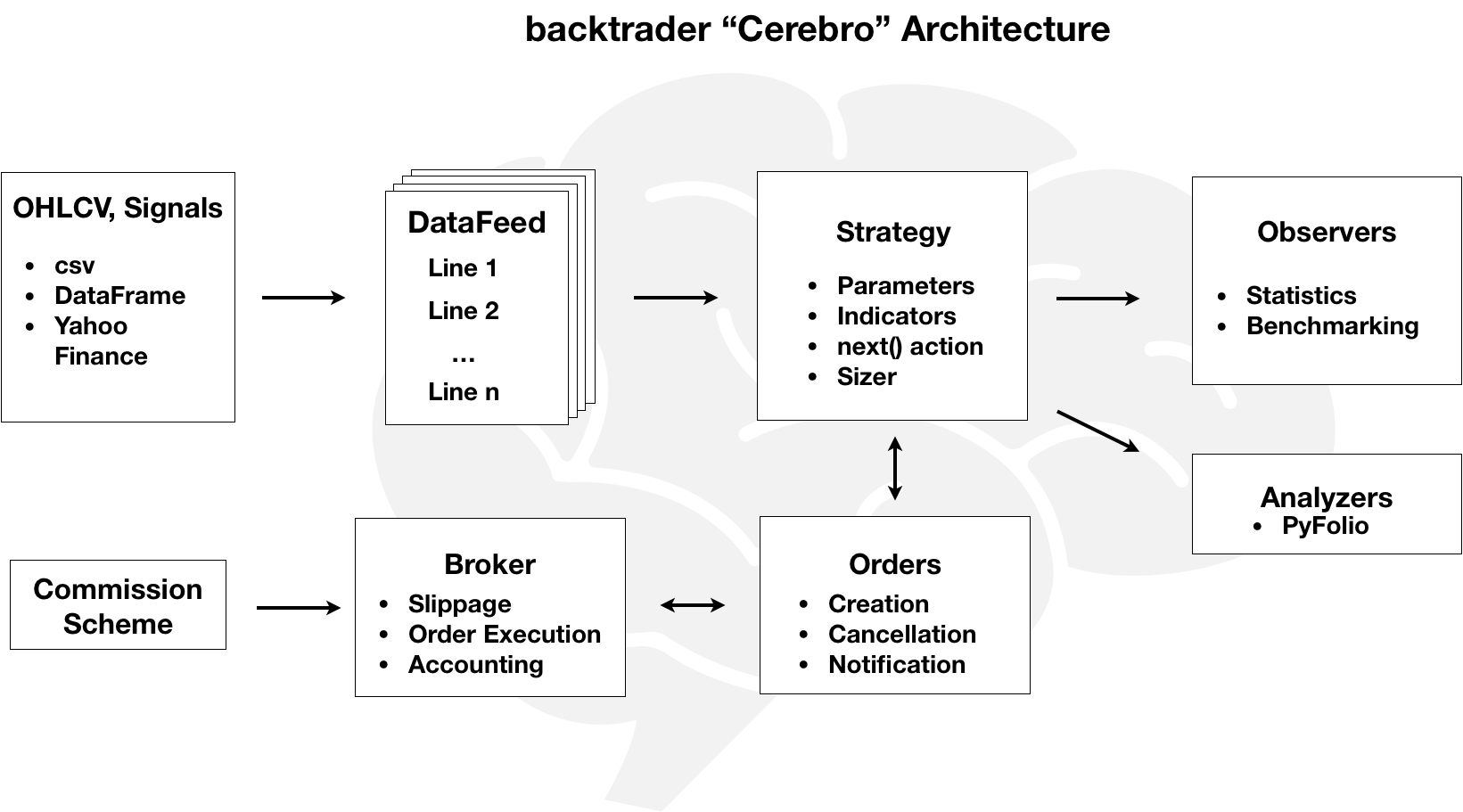
backtrader Cerebro架构的关键概念
Backtrader的Cerebro(西班牙语,意为"大脑")架构将回测工作流程的关键组件表示为(可扩展的)Python对象。这些对象相互作用,以便于输入数据的处理和因子计算,制定和执行策略,接收和执行订单,以及跟踪和度量业绩。Cerebro实例协调整个过程,从收集输入、逐bar执行回测到提供结果。
该库使用这些交互的约定,让您可以省略一些细节,简化回测设置。如果您计划使用backtrader开发自己的策略,我强烈建议您浏览文档以深入了解。
代码示例:如何在实践中使用backtrader
我们将再次使用第7章线性模型中的日收益预测作为向量化回测的例子,演示backtrader的使用。我们将创建Cerebro实例,加载数据,制定并添加策略,运行回测,并查看结果。
笔记本backtesting_with_backtrader包含代码示例和一些附加细节。
资源
zipline:Quantopian的生产就绪回测
开源的Zipline库是一个事件驱动的回测系统,由众包量化投资基金Quantopian维护和生产使用,以促进算法开发和实盘交易。它自动化了算法对交易事件的反应,并为其提供了当前和历史的时点数据,避免了前瞻性偏差。
在第4章中,我们介绍了zipline来模拟alpha因子的计算;在第5章中,我们添加了交易来模拟一个简单的策略,并使用不同的技术测量其业绩并优化投资组合持仓。
代码示例:离线和在Quantopian上摄取数据和训练ML模型
本节的代码在子目录ml4t_workflow_with_zipline中。请参阅README了解详细信息。
This chapter integrates the various building blocks of the machine learning for trading (ML4T) workflow and presents an end-to-end perspective on the process of designing, simulating, and evaluating an ML-driven trading strategy. Most importantly, it demonstrates in more detail how to prepare, design, run and evaluate a backtest using the Python libraries backtrader and Zipline.
The ultimate goal of the ML4T workflow is to gather evidence from historical data that helps decide whether to deploy a candidate strategy in a live market and put financial resources at risk. This process builds on the skills you developed in the previous chapters because it relies on your ability to
- work with a diverse set of data sources to engineer informative factors,
- design ML models that generate predictive signals to inform your trading strategy, and
- optimize the resulting portfolio from a risk-return perspective.
A realistic simulation of your strategy also needs to faithfully represent how security markets operate and how trades are executed. Therefore, the institutional details of exchanges, such as which order types are available and how prices are determined (see Chapter 2, Market and Fundamental Data, also matter when you design a backtest or evaluate whether a backtesting engine includes the requisite features for accurate performance measurements. Finally, there are several methodological aspects that require attention to avoid biased results and false discoveries that will lead to poor investment decisions.
The data used for some of the backtest simulations are generated by the script data_prep.py in the data directory and are based on the linear regression return predictions in Chapter 7, Linear Models.
Content
- How to backtest an ML-driven strategy
- The pitfalls of backtesting and how to avoid them
- How a backtesting engine works
- backtrader: a flexible tool for local backtests
- zipline: production-ready backtesting by Quantopian
How to backtest an ML-driven strategy
In a nutshell, the ML4T workflow is about backtesting a trading strategy that leverages machine learning to generate trading signals, select and size positions, or optimize the execution of trades. It involves the following steps, with a specific investment universe and horizon in mind:
- Source and prepare market, fundamental, and alternative data
- Engineer predictive alpha factors and features
- Design, tune, and evaluate ML models to generate trading signals
- Decide on trades based on these signals, e.g. by applying rules
- Size individual positions in the portfolio context
- Simulate the resulting trades triggered using historical market data
- Evaluate how the resulting positions would have performed
The pitfalls of backtesting and how to avoid them
Backtesting simulates an algorithmic strategy based on historical data with the goal of producing performance results that generalize to new market conditions. In addition to the generic uncertainty around predictions in the context of ever-changing markets, several implementation aspects can bias the results and increase the risk of mistaking in-sample performance for patterns that will hold out-of-sample.
Getting the data right
Data issues that undermine the validity of a backtest include
- look-ahead bias,
- survivorship bias,
- outlier control, as well as
- the selection of the sample period.
Getting the simulation right
Practical issues related to the implementation of the historical simulation include:
- a failure to mark to market to accurately reflect market prices and account for drawdowns;
- unrealistic assumptions about the availability, cost, or market impact of trades; or
- incorrect timing of signals and trade execution.
Getting the statistics right: Data-snooping and backtest-overfitting
The most prominent challenge to backtest validity, including to published results, relates to the discovery of spurious patterns due to multiple testing during the strategy-selection process. Selecting a strategy after testing different candidates on the same data will likely bias the choice because a positive outcome is more likely to be due to the stochastic nature of the performance measure itself. In other words, the strategy is overly tailored, or overfit, to the data at hand and produces deceptively positive results.
Marcos Lopez de Prado has published extensively on the risks of backtesting, and how to detect or avoid it. This includes an online simulator of backtest-overfitting.
Code Example: The deflated Sharpe Ratio
De Lopez Prado and David Bailey derived a deflated SR to compute the probability that the SR is statistically significant while controlling for the inflationary effect of multiple testing, non-normal returns, and shorter sample lengths.
The pyton script deflated_sharpe_ratio in the directory multiple_testing contains the Python implementation with references for the derivation of the related formulas.
References
- The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting and Non-Normality, Bailey, David and Lopez de Prado, Marcos, Journal of Portfolio Management, 2013
- Backtest Overfitting: An Interactive Example
- Backtesting, Lopez de Prado, Marcos, 2015
- Secretary Problem (Optimal Stopping)
- Optimal Stopping and Applications, Ferguson, Math Department, UCLA
- Advances in Machine Learning Lectures 4/10 - Backtesting I, Marcos Lopez de Prado, 2018
- Advances in Machine Learning Lectures 5/10 - Backtesting II, Marcos Lopez de Prado, 2018
How a backtesting engine works
Put simply, a backtesting engine iterates over historical prices (and other data), passes the current values to your algorithm, receives orders in return, and keeps track of the resulting positions and their value. In practice, there are numerous requirements to create a realistic and robust simulation of the ML4T workflow depicted above. The difference between vectorized and event-driven approaches illustrates how the faithful reproduction of the actual trading environment adds significant complexity.
Vectorized vs event-driven backtesting
A vectorized backtest is the most basic way to evaluate a strategy. It simply multiplies a signal vector that represents the target position size with a vector of returns for the investment horizon to compute the period performance.
Code example: a simple vectorized backtest
We illustrate the vectorized approach using the daily return predictions that we created using ridge regression in Chapter 7
- The code examples for this section are in the notebook vectorized_backtest.
Key Implementation Aspects
The requirements for a realistic simulation may be met by a single platform that supports all steps of the process in an end-to-end fashion, or by multiple tools that each specialize in different aspects. For instance, you could handle the design and testing of ML models that generate signals using generic ML libraries like scikit-learn or others that we will encounter in this book and feed the model outputs into a separate backtesting engine. Alternatively, you could run the entire ML4T workflow end-to-end on a single platform like Quantopian and QuantConnect.
The following implementation details need to be addressed to put this process in action, and are discussed in more detail in this section of the book:
- Data ingestion: Format, frequency, and timing
- Factor engineering: Built-in computations vs third-party libraries
- ML models, predictions, and signals
- Trading rules and execution
- Performance evaluation
backtrader: a flexible tool for local backtests
backtrader is a popular, flexible, and user-friendly Python library for local backtests with great documentation, developed since 2015 by Daniel Rodriguez. In addition to a large and active community of individual traders, there are several banks and trading houses that use backtrader to prototype and test new strategies before porting them to a production-ready platform using, e.g., Java. You can also use backtrader for live trading with several brokers of your choice (see the backtrader documentation and Chapter 23, Next Steps)).
- The code examples for this section are in the notebook backtesting_with_backtrader.
Key concepts of backtrader’s Cerebro architecture
Backtrader’s Cerebro (Spanish for “brain”) architecture represents the key components of the backtesting workflow as (extensible) Python objects. These objects interact to facilitate the processing of input data and the computation of factors, formulate and execute a strategy, receive and execute orders, and track and measure performance. A Cerebro instance orchestrates the overall process from collecting inputs, executing the backtest bar-by-bar, and providing results.
The library uses conventions for these interactions that allow you to omit some detail and streamline the backtesting setup. I highly recommend browsing the documentation to dive deeper if you plan on using backtrader to develop your own strategies.
Code Example: How to use backtrader in practice
We are going to demonstrate backtrader using again the daily return predictions by the ridge regression from Chapter 7, Linear Models, as for the vectorized backtest earlier in this chapter. We will create the Cerebro instance, load the data, formulate and add the Strategy, run the backtest, and review the results.
The notebook backtesting_with_backtrader contains the code examples and some additional details.
Resources
- Backtrader website
zipline: production-ready backtesting by Quantopian
The open source Zipline library is an event-driven backtesting system maintained and used in production by the crowd-sourced quantitative investment fund Quantopian to facilitate algorithm-development and live-trading. It automates the algorithm’s reaction to trade events and provides it with current and historical point-in-time data that avoids look-ahead bias.
Chapter 4, we introduced zipline to simulate the computation of alpha factors, and in Chapter 5 we added trades to simulate a simple strategy and measure its performance as well as optimize portfolio holdings using different techniques.
Code Examples: Ingesting Data and training ML models, offline and on Quantopian
The code for this section is in the subdirectory ml4t_workflow_with_zipline. Please see the README for details.
















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











