







一、什么是Stable Diffusion(SD)?
Stable Diffusion 是Stability AI公司于 2022 年发布的深度学习文字到图像生成模型。它主要用于根据文字的描述产生详细图像,能够在几秒钟内创作出令人惊叹的艺术作品。
截至目前为止,三个最流行的AI作画产品是 Stable Diffusion、 Midjourney和 DALL·E 2。与Midjourney和OpenAI的DALL·E 2相比,SD最大的优势是其开源性。任何用户都可以免费下载、使用并发布AI作品。
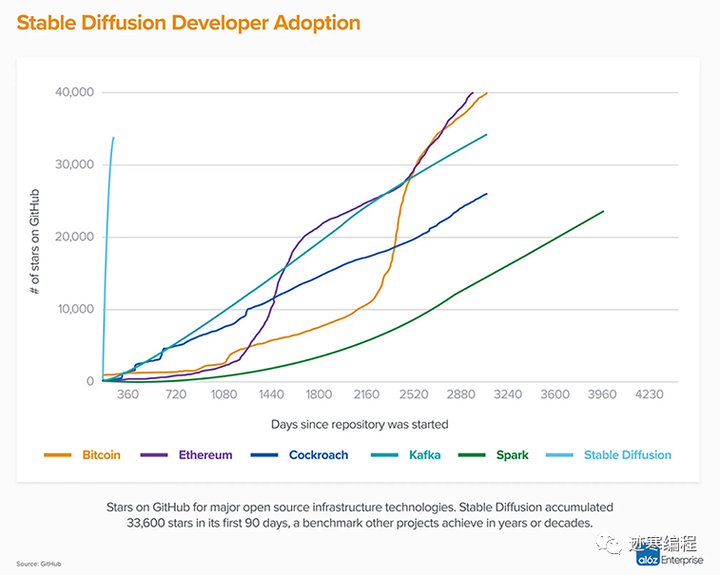
在短短三个月时间内,SD就在github收获了33K个star,其热门程度远超同期的Kafka、Spark、Bitcoin等知名项目,如下图所示。
SD的优势在于:
- 提供了一个基于网页浏览器的前端交互WebUI,用户只需要简单的输入prompt和设置参数就可以生成难以置信的图片(傻瓜式操作);
- 只需文本提示输入就能够模拟和重建几乎任何以视觉形式表达的概念;
- 提供了多种功能,如 文本到图片转换txt2img、图片到图片转换img2img等,能满足使用者的多种需求;
- 通过调节相关参数可以生成不同的效果,用户可以根据自己的需要在和喜好在本地客户端进行AI创作;
- 可扩展性极强,用户可以自由地下载SD模型,LoRA模型,ControlNet模型,还包括模型融合等高级功能;
- AI绘图社区支持,专门的模型下载网站HuggingFace和绘画分享网站Civitai(C站)
做一下笔记
文本到图片转换:用户输入提示和反向提示,设置模型参数就可以生成图片;
图片到图片转换:这个功能非常非常有趣,用户可以放入一张已有图片,来生成不同风格的新图片;另外用户也可以通过特定插件将图片反推出提示词来;图片裁剪、缩放、重绘,结合ControlNet可以实现在同一画面内容下的多种风格;提升图像分辨率等。
下面我们讲解如何安装SD~
二、安装和使用
(1)安装
首先大家最关注的想必是硬件要求啦。不用担心,不要4090Ti,普通的16xx系列N卡足够了,显存(VRAM)最好大于6GB,但利用xFormer,4GB的显卡也是够用的,硬盘最好50GB以上。
笔者的配置是Intel Core i5-12490F,16GB内存,Geforce RTX 3060Ti显卡,8GB显存,NVMe SSD硬盘,Windows 11。仅供参考。
有的读者可能说,“看不太懂英文,有汉化版吗?” “想抄近路,不想花太多时间”答案是yes。
B站上有一个**@秋葉aaaki**大佬做了一个汉化整合包,传送门
笔者自己没试过,但是听说很方便,可以自动进行“疑难诊断”,还是蛮不错的。缺点是安装包巨大+百度网盘,用过都吐槽~
如果和我一样想体验100%纯英文的开源氛围(后续有汉化包),那么请往下看:
1)在电脑上安装Python 3.10.6(更高或更低的版本都不行),下载git。
然后前往http://github.com/AUTOMATIC1111/stable-diffusion-webui下载项目,并解压到合适的位置(不建议C盘)。如果是不带WebUI的版本,请前往http://github.com/Stability-AI/stablediffusion。
2) 在项目目录下运行webui-user文件
Linux下:
./webui-user.sh
Windows下(win+R组合键运行cmd):
.\webui-user
然后它就会自动下载依赖,耗时N长时间(可能需要梯子)。

当你看到这个界面就表示安装成功了。说实话,安装了一晚上,第二天早上起来看超感动/(ㄒoㄒ)/~~
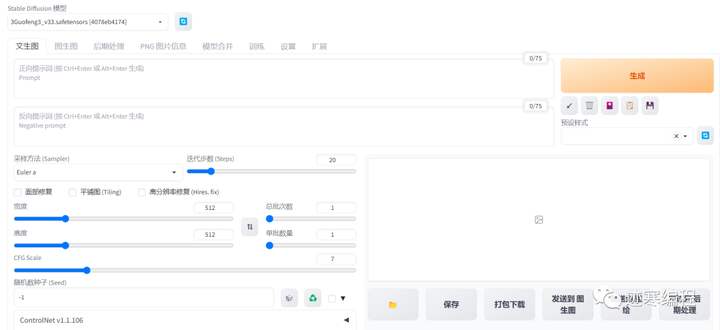
(2)文生图功能初体验
然后我们来介绍一下页面吧~
第一步,选择模型。
这里的话,笔者推荐初学者下载Counterfeit-v2.5和Anything-v3.0两个模型,下载可以前往http://huggingface.co。你要说为什么的话,当然是这两个模型最受欢迎啦~
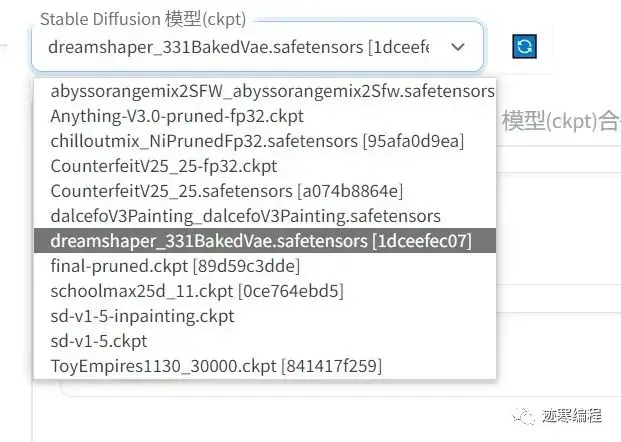
sd-v1-5系列是默认模型,出图效果不佳,适合训练。
模型默认保存在models/子目录下。
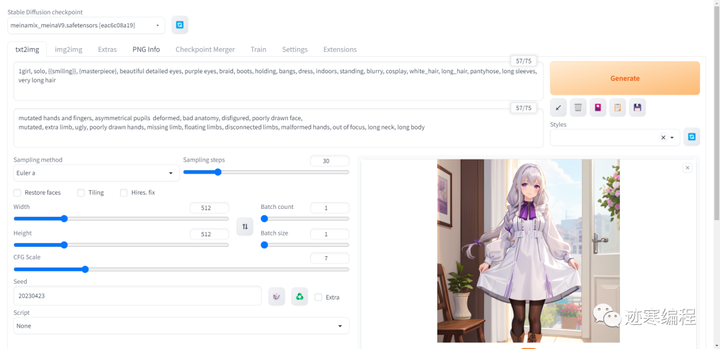
第二步,输入prompt。
注意只能是英文哦。有两种模式:
1)自然语言,例如“a girl standing on the beach alone in Bikini under clear blue sky”,需要使用者有一定英语语法基础。优势是符合阅读习惯,能准确描述画面细节。
2)提示词并且用“,”分割,例如“1girl, solo, standing, Bikini, beach, blue_sky, photorealistic, 4K”,使用者只要知道单词就行,能够描述更多的细节。
贴心的迹寒整理了一份常用prompt英汉对照表整理放在文末啦~

关于语法部分我们下一节专门讲。
第三步,输入反向提示语(Negative Prompt)。
反向提示语是指你不希望出现的特征,在模型中相应提示语的权重会被抑制。

右上角有我们当前输入的字符数,最多不超过75个字符。
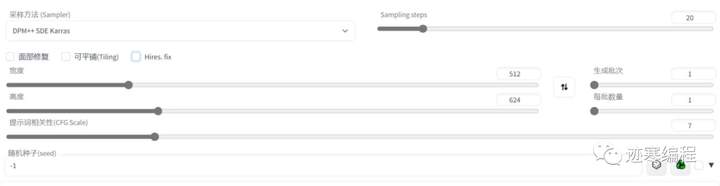
第四步,设置参数:
采样器(Sampler):默认选择“Euler a”,大部分情况下还是不错的。但是老司机更喜欢DPM++系列模型。

采样器比较
Euler 最简单最快。
Euler a 更多样,不同步数可以生产出不同的图片。但是太高步数 (>30) 效果不会更好。
DDIM 收敛快,但效率相对较低,因为需要很多 step 才能获得好的结果,适合在重绘时候使用。
LMS 是 Euler 的衍生,它们使用一种相关但稍有不同的方法(平均过去的几个步骤以提高准确性)。大概 30 step 可以得到稳定结果
PLMS 是 Euler 的衍生,可以更好地处理神经网络结构中的奇异性。
DPM2 是一种神奇的方法,它旨在改进 DDIM,减少步骤以获得良好的结果。它需要每一步运行两次去噪,它的速度大约是 DDIM 的两倍,生图效果也非常好。但是如果你在进行调试提示词的实验,这个采样器可能会有点慢了。
UniPC 效果较好且速度非常快,对平面、卡通的表现较好,推荐使用。
图片尺寸(Width/Height):大小默认为512x512,也就是长宽比1:1。如果你想专门给人物进行特写的话,推荐512x768(2:3)或者512x640(4:5), 如果是横版壁纸,推荐1024x768和1280x1024等等。
生成批次(Batch count): 按照顺序生成一组图片,最小为1,最大为100。
每批数量(Batch size):单轮次生成图片的数量,可以看作并行出图。最小为1最大为8,所以生成图片填不满一个九宫格,很难受。掌握一个原则:显存足够的话的调大“每批数量”,否则乖乖增加“生成批次”。
采样步数(Sampling Steps):Stable Diffusion 的工作方式是从以随机高斯噪声起步,向符合提示的图像一步步降噪接近。随着步数增多,可以得到对目标更小、更精确的图像。但增加步数也会增加生成图像所需的时间。增加步数的边际收益递减,取决于采样器。一般开到 20~30。
- 不同采样步数与采样器之间的关系:
提示词相关性(CFG Scale): 图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示,但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。过高的 CFG Scale 体现为粗犷的线条和过锐化的图像。一般开到 7~11。
随机数种子(Seed):-1表示任意随机数,这个值一般不用改。但是如果你想每次都出一样的图的话就固定一个值吧~
脚本(Scripts):按照脚本方式生成图片。默认选”无“。有“提示矩阵”,“从文件或文档加载提示词”、“x/y/z图表”等选项。
另外,中间有三个复选框。
面部修复:用于真人面部修复,二次元的话修复效果不明显;
可平铺(Tiling):如果需要将多张图片拼接在一起或做成壁纸,那么这个选项将非常有用;
Highres. fix: 高清修复。默认情况下,文生图在高分辨率下会生成非常模糊的图像。如果使用高清修复,会型首先按照指定的尺寸生成一张图片,然后通过放大算法将图片分辨率扩大,以实现高清大图效果。最终尺寸为(原分辨率*缩放系数 Upscale by)。启用之后会多出来一些选项:

**放大算法(Upscaler):**Latent 在许多情况下效果不错,但重绘幅度小于 0.5 后就不甚理想。ESRGAN_4x、SwinR 4x 对 0.5 以下的重绘幅度有较好支持。
**Upscale by:**放大倍数。默认为2。
Hires step 表示在进行这一步时计算的步数。
重绘幅度(Denoising strength):字面翻译是降噪强度,表现为最后生成图片对原始输入图像内容的变化程度。该值越高,放大后图像就比放大前图像差别越大。低 denoising 意味着修正原图,高 denoising 就和原图就没有大的相关性了。一般来讲阈值是 0.7 左右,超过 0.7 和原图基本上无关,0.3 以下就是稍微改一些。实际执行中,具体的执行步骤为 Denoising strength * Sampling Steps。
第五步,生成图片。
点右上角最大的按钮生成就可以了,之后应该会看到一个蓝色的进度条。图片会生成在下方。你也可以选择中止或者跳过。
图片默认自动保存在\outputs文件夹下。可以在“设置-保存路径”下进行修改。
在“生成”按钮下面有一些小图标。
↙️:获取上一次图片生成参数;
️:清空提示词内容;
:将预设样式插入到当前提示词后;
:将当前提示词存储为预设样式。可以从下面预设样式下拉框中选择;
:显示/隐藏扩展模型(显示扩展图)

(3)常见问题和经验
笔者之前安装了Python3.11,安装的时候报错了。按照要求将Python3.11换成3.10.6还是报错,环境变量也改了。找了一圈没有结论,最后发现SD会把python环境拷贝到/venv目录下,将目录下内容全部删除就好了。
因为SD涉及到的模型和目录较多,为了防止大家懵圈,迹寒做了一张表,建议大家收藏:
| 类型 | 文件格式 | 目录 | 说明 |
|---|---|---|---|
| Checkpoint | *.ckpt, *.safetensors | models/Stable-diffusion | 模型文件较大,几百M到数G |
| vae | *.ckpt, *.safetensors | models/VAE | 增加图片亮度,恢复眼睛和文字等细节 |
| Textual Inversion | *.pt | embeddings | 文件很小,作为可选tag插件 |
| Lora(LoRA) | *.pt | models/Lora | 微调模型,风格化 |
| Hypernetworks | *.pt, *.ckpt, *.safetensors | models/hypernetworks | 和Lora工作方式相近 |
有时候SD提示:Something went wrong Expecting value: line 1 column 1 (char 0) 错误
解决方法:不挂梯子重启。真正原因暂时还不清楚。重启之后生成任意一张图片再打开梯子即可。
为了优化显存的使用,推理加速,可以下载可以在启动时候加入-xformers 参数。将会自动下载。其它优化方法请参考github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Optimizations。
三、如何写提示词
(1)语法糖
首先我们讲一讲提示词语法,它是一种人能看懂的单词或句子的组合。
","分割符号
使用逗号 , 用于分割词缀,且有一定权重排序功能,逗号前权重高,逗号后权重低。例:girl, beautiful
建议的通用范式
建议用以下归类的三大部分来准备相关提示词
前缀(画质词+画风词+镜头效果+光照效果) + 主体(人物&对象+姿势+服装+道具) + 场景(环境+细节)
更改提示词权重
使用小括号()增加模型对被括住提示词的注意 (提高权重)。
权重取值范围 0.4-1.6,权重太小容易被忽视,太大容易拟合图像出错。例:(beautiful:1.3) 。括号允许嵌套。
各种权重类语法公式明细:
- (PromptA:weight):用于提高或降低该提示词的权重比例,注:数值大于1提高,小于1降低
- (PromptB):PromptB的权重为1.1=(PromptA:1.1)
- {PromptC}: PromptC的权重为1.05=(PromptB:1.05)
- ((PromptE)=(PromptE:1.1*1.1)
- {{PromptF}}=(PromptF:1.05*1.05)
- [[PromptG]]=(PromptG:0.952*0.952)
调取LoRA或Hypernetworks模型
使用尖括号 <> 调取LoRA或超网络模型。
按照下述形式输入:lora:filename:multiplier或 hypernet:filename:multiplier可调取相应模型,例:lora:cuteGirlMix4_v10:0.5 。冒号后面的数字表示使用LoRA或Hypernetworks模型的百分比(0-1)。
很坑的一点是“:”必须是英文冒号且后面不能有空格,一旦有空格就会报错“Can’t find Lora with name X”

- 分布与交替渲染
使用方框号 [] 可应用较为复杂的分布与交替需求。
- [A:B:step] 代表执行A效果到多少进度,然后开始执行B。例:[blue:red:0.4],渲染蓝色到40%进度渲染红色。注:step > 1 时表示该组合在前多少步时做为 A 渲染,之后作为 B 渲染。step < 1 时表示迭代步数百分比。
- [A:0.5] 这样写的含义是从50%进度开始渲染A
- [A::step] 渲染到多少进度的时候去除A
- [A|B] A和B交替混合渲染
- 反向提示词
反向提示词(Negative prompt),就是我们不想出现什么的描述。例:NSFW 不适合在工作时看的内容,包括限制级,还有低画质相关和一些容易变形身体部位的描述等。
注:在C站可下载一个叫 Easynegative 的文件,它的作用是把一些常用的反向提示词整合在一起了,让我们只需输入简单的关键词就能得到较好效果。把它放到/enbeddings 文件夹,需要触发时在 negative prompt 中输入 EasyNegative 即可生效。除此之外还有badhandv4等。
一些注意说明
- AI 会按照 prompt 提示词输入的先后顺序和所分配权重来执行去噪工作;
- AI 也会依照概率来选择性执行,如提示词之间有冲突,AI 会根据权重确定的概率来随机选择执行哪个提示词。
- 越靠前的 Tag 权重越大;比如景色Tag在前,人物就会小,相反的人物会变大或半身。
- 生成图片的大小会影响 Prompt 的效果,图片越大需要的 Prompt 越多,不然 Prompt 会相互污染。
- Prompt 支持使用 emoji,且表现力较好,可通过添加 emoji 图来达到效果。如 形容喜欢表情, 可修手。
- 连接符号,使用 +, and, |, _ 都可连接描述词,但各自细节效果有所不同。

- 用加号连接:(red hair:1.1)+(yellow hair:1.25)+(green hair:1.4)
- 用 and 连接:(red hair:1.1) AND (yellow hair:1.25) AND (green hair:1.4)
- 用逗号连接:(red hair:1.1),(yellow hair:1.25),(green hair:1.4)
- 用下划线连接:(red hair:1.1)(yellow hair:1.25)(green hair:1.4)
- 用竖线连接:(red hair:1.1)|(yellow hair:1.25)|(green hair:1.4)
- 什么都不加直接连接:(red hair:1.1)(yellow hair:1.25)(green hair:1.4)
(2)典型提示词
提高图像质量的提示词:
| prompt(P) | 描述 |
|---|---|
| HDR, UHD, 8K | (HDR、UHD、4K、8K和64K)这样的质量词可以带来巨大的差异提升照片的质量 |
| best quality | 最佳质量 |
| masterpiece | 杰作 |
| Highly detailed | 画出更多详细的细节 |
| Studio lighting | 添加演播室的灯光,可以为图像添加一些漂亮的纹理 |
| ultra-fine painting | 超精细绘画 |
| sharp focus | 聚焦清晰 |
| physically-based rendering | 基于物理渲染 |
| extreme detail description | 极其详细的刻画 |
| Professional | 加入该词可以大大改善图像的色彩对比和细节 |
| Vivid Colors | 给图片添加鲜艳的色彩,可以为你的图像增添活力 |
| Bokeh | 虚化模糊了背景,突出了主体,像 iPhone 的人像模式 |
| (EOS R8, 50mm, F1.2, 8K, RAW photo:1.2) | 摄影师对相机设置的描述 |
| High resolution scan | 让你的照片具有老照片的样子赋予年代感 |
| Sketch | 素描 |
| Painting | 绘画 |
反向提示词:
| negative prompt(NP) | 描述 |
|---|---|
| mutated hands and fingers | 变异的手和手指 |
| deformed | 畸形的 |
| bad anatomy | 解剖不良 |
| disfigured | 毁容 |
| poorly drawn face | 脸部画得不好 |
| mutated | 变异的 |
| extra limb | 多余的肢体 |
| ugly | 丑陋 |
| poorly drawn hands | 手部画得很差 |
| missing limb | 缺少的肢体 |
| floating limbs | 漂浮的四肢 |
| disconnected limbs | 肢体不连贯 |
| malformed hands | 畸形的手 |
| out of focus | 脱离焦点 |
| long neck | 长颈 |
| long body | 身体长 |
是不是很长,迹寒按照方便复制的格式重写了下:
mutated hands and fingers, deformed, bad anatomy, disfigured, poorly drawn face,
实在不擅长英语的小伙伴可以使用一些辅助网站,如红杏TAG(http://tag.redsex.cc)和Danbooru 标签超市(tags.novelai.dev/),会中文就会tag啦,是不是很方便?
(3)提示词与AI绘画风格
AI绘图风格对照表/画风样稿详细研究记录及经验总结(分析Midjourney和Stable Diffusion风格提示词实际使用情况)不断更新中…_stablediffusion风格词-CSDN博客
四、简单的汉化流程
很多小伙伴苦于webui晦涩的英语,笔者感同身受,于是在网上搜索了很多资料,终于发现了一个巨简单的汉化方法,有手就行,分享给大家。
我们先打到主界面中的Extensions选项卡,点击打开。选择“Install from URL”:输入“http://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans”并下载安装。如果失败的话,自行在github下载安装包,将localizations下的zh-Hans (Stable)和**zh-Hans (Testing)**拷入到SD目录下的localizations目录。
之后依次点击"Settings → User interface → Localization (requires restart) → zh-Hans(Stable) → Apply settings → Reload UI就可以啦。是不是很简单呢?
五、什么是图生图?
图生图是另一种非常有用的AI生成图像方法,你不需要学习复杂的英文prompt,我们用一些例子来描述它的使用场景:
1)小明在网上找到了一张很好看的小姐姐

于是,他想要更多的小姐姐!

2)小明又觉得女主穿着不太好看,想换一件其它的衣服。

抑或是休闲牛仔

3)小明想改变图片的背景,比如学校教室的门口,顺便将女主的头发改成紫色。

4)贪婪的小明还不满意,他想要改变人物动作。比如一个摸头发的动作。

通过这些例子,我们就能感受到SD的强大,利用SD+ControlNet可以满足你任何合理的诉求。生成任何你渴望生成的图片。
当然,迹寒希望大家生成的图片都是合法合规的,不要在网上传播一些负面的图片哟。
(1) 界面介绍 首先我们要导入一张图片,可以通过两种方式很方便的导入:拖到图像或者上传文件。也可以直接将文生图的图片发到这里来。

图生图的界面和文生图的界面类似,都有“提示词”、“反提示词”输入框,并且图生图多了两个按钮:

**CLIP反推和DeepBooru反推:**根据图片反推出提示词,需要另外安装插件。它们直接有什么区别呢?比如下面这张图:

CLIP反推:
a woman sitting on a bench with a rabbit on her lap next to her legs and a dog on her lap, Chen Hong, rossdraws global illumination, a detailed painting, rococo
DeepBooru反推:
1girl, :d(emoji, 一个大大的微笑), animal, animal ears, bamboo, bamboo forest, bangs, bare legs, barefoot, black skirt, blush, branch, brown eyes, bunny, bush, day, feet, flower, flower pot, foliage, forest, frills, grass, hair between eyes, ivy, knees together feet apart, leaf, looking at viewer, moss, nature, on grass, open mouth, outdoors, palm tree, plant, pond, potted plant, puffy short sleeves, puffy sleeves, rabbit ears, rabbit girl, rabbit tail, shirt, short hair, short sleeves, sitting, skirt, smile, solo, tail, tanabata, tree, tree stump, vines
大家可以清晰的看到两者的区别。CLIP注重画面内的联系,生成的自然语言描述。DeepBooru对二次元图片生成标签,对二次元的各种元素把握很好。
所以大家根据实际需求进行选择就好。此外,选项卡上还有“PNG图片信息”,它也可以获取图片的生成参数信息,但只能是SD生成的图片(貌似添加了水印),不能用于一般图片。
做一下笔记
如果发现图像很灰怎么办?尤其是真人图片。
这个时候我们需要一个叫变分自编码器VAE的插件,对就是和许嵩同英文名的插件
下载地址:http://huggingface.co/stabilityai/sd-vae-ft-mse

大家选择一个下载然后放到models\VAE目录下,重启webui,打开“设置——Stable Diffusion——外挂VAE模型”选择对应模型即可。没有看到的话,可以点右边的刷新按钮。
❗注意:
一定要“保存设置”并“重置前端”!
一定要“保存设置”并“重置前端”!
一定要“保存设置”并“重置前端”!
重要的事说三遍。
重绘幅度(Denosing strength):控制重绘幅度,数值越大,和原图差距越大,基本<0.3的时候就和原图差距很小。

下面是一个例子:
提示词:一个穿夹克的男孩。输入图片为兔耳朵女孩,可以看到这个变化过程:

有小伙伴可能很好奇到底是哪一步开始出现“性转”的,笔者也很好奇,我们在0.6~0.85范围内继续实验:

可以看到0.7-0.75左右,当头发变短,睫毛变细,胸变平就出现男性特征了。这可以作为我们进行参数调整的依据。
小技巧
如何做成上面这张图片并列的形式呢?
可以采用“脚本——x/y/z plot”

其中,x轴就是我们希望生成图片的排列是一维的,如果有两个变量那就启用y轴,依次类推,最多三个维度。选择某个量作为变量。
X轴值可以写成:
分立形式:1, 2, 5, 8,表示4个数
简单范围表示:1 - 8,表示8个数
圆括号内整数表示步长:1-9(+4),表示1, 5, 9; 8-2(-3),表示8, 5, 2
方括号内整数表示一共取几个数:1-10[5]表示1, 3, 5, 7, 10五个数
(2)改变图像尺寸或分辨率
在上传图像后有下面一排按钮:

这些看名字就知道是什么功能了,但是第四个“调整大小(潜空间超分)”是什么意思呢?
潜空间(latent space)可以理解为隐藏空间,超分就是超分辨率,综合起来就是说增加隐藏空间的分辨率酱紫。
图生图没有Hires.fix功能,如果要提高分辨率,我们可以怎么做呢?
- 首先,在提示词中加hires,在反提示词加lowres,这是一种方法
- 使用上面“调整大小(潜空间超分)”
- 增加迭代步数也是不错的方法,但是也不能调的过大,一方面浪费时间,另一方面图片会失真。
(3)涂鸦
在这个模式中,我们有一只笔,可以改变大小或者颜色:
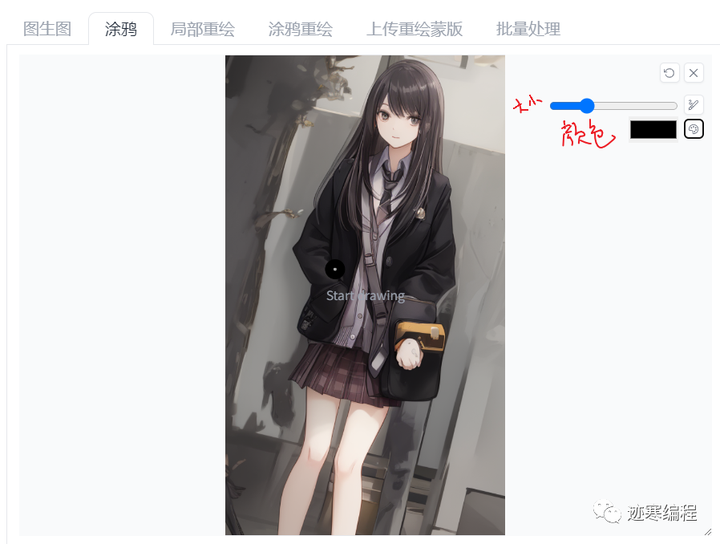
一个非常有趣的用法是改变头发颜色,比如改成粉色头发,用大概的线条覆盖头发部分
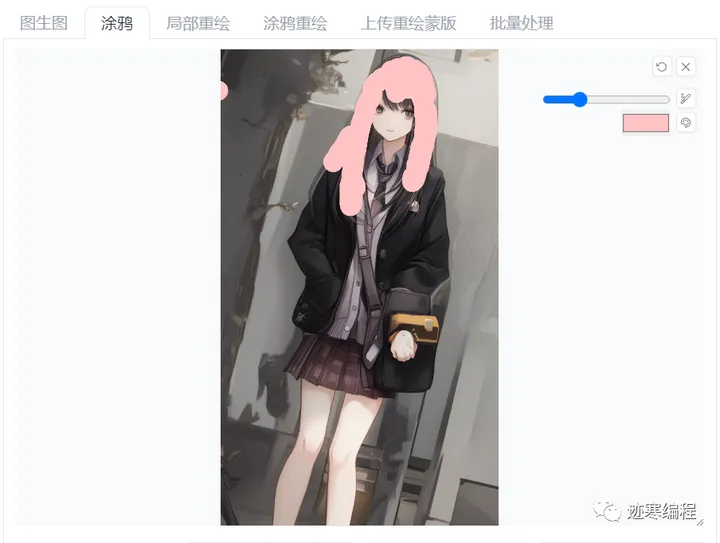
然后就变成粉色头发了

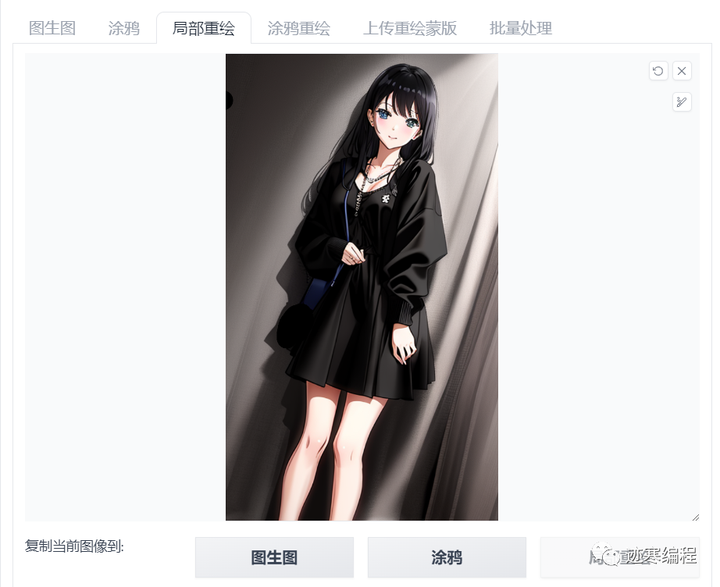
(4)局部重绘
这个功能一般是用于修复图像,但是它不能对AI无法克服的缺点进行修复:手和不对称的瞳孔。
我们假设有下面这张图片,明显多了一只手

我们直接把要重绘地方涂上黑色,这部分区域叫“蒙版”,学过PS的朋友可能对这功能爱恨交加~
下面多了一些参数:

**蒙版边缘模糊度:**用于调节遮罩边缘的模糊程度,具体来说,数值越大遮罩图像的边缘就越模糊,从而让修复后的图像效果更加平滑和自然。反之遮罩图像的边缘更加锐利,修复图像效果可能会更加清晰和明确。需要注意的是,较大的遮罩模糊度可能会导致修复图像的细节丢失;
蒙版模式:一般来说如果要改的地方很少就用“重绘蒙版内容”,否则用重绘非蒙版内容。
蒙版区域内容处理:fill就是全充满,original填充和原来一样的内容,latent noise 是潜空间噪声,latent nothing是什么都没有。一般选original就可以了。
重绘区域:重绘整张图片或者仅重绘蒙版。
仅蒙版区域下边缘预留像素:可以使得边缘过渡地更加自然,根据需要调整。
我们来看看效果:

很好多余的手已经被去掉了。
(5)涂鸦重绘
和局部重绘功能类似,不过多了一个蒙版透明度功能:

举个栗子,给小姐姐穿一件红蓝外套:

左边蒙版透明度为0的话就有一点不自然,太显眼了,右边为26明显要好一些。

(6)上传重绘模板
此外我们还可以上传蒙版文件用于精确的重绘,上传的应该是黑白的图片,像这样:

我们来看看效果,一张是人物变了,另一张是背景变了。

这个功能还是很赞的!
(7)批量处理
大家可以理解为批量地进行重绘。可能有同学会有疑问,我既然有生成批次,每批数量等参数,为什么还要加这个功能呢?
想象有这样一个场景,我想生成一幅动画,动画由很多帧组成,帧与帧之间应该在逻辑上是相关的。不能突然换一个人或者换一个场景吧!
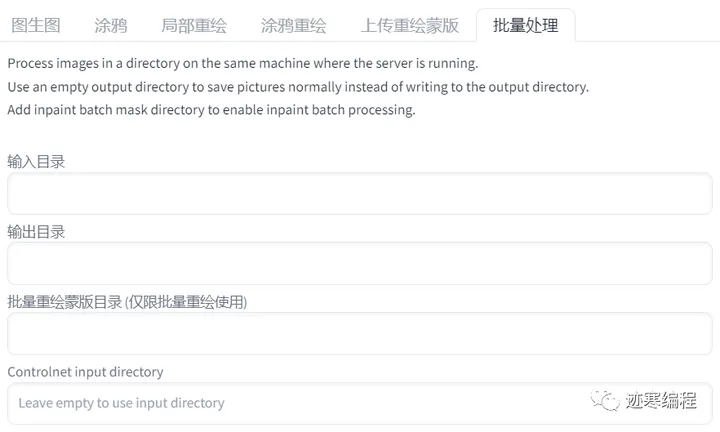
输入目录就是视频帧的目录,推荐使用img2go的convert-to-jpg工具。
输出目录指视频帧输出目录,必须是一个空文件夹。
批量重绘蒙版指重绘模板的参数,这个也很重要。如果不用蒙版的话,生成图像基本没法看。
六、ControlNet介绍
SD还有一个强大的插件叫ControlNet (简称CN),利用它我们能更生成更有创意并且符合逻辑的图片,本期我们将讲解ControlNet插件的安装使用。
1、ControlNet介绍
官网对它介绍只有两段话,

翻译成中文就是:
“ ControlNet是一个增加了额外条件来的神经网络结构来控制扩散模型(SD),它是AI图像生成游戏的改变者。它为SD带来了前所未有的控制水平。
ControlNet的革命性之处在于它解决了空间一致性问题。以前根本没有有效的方法来告诉人工智能模型要保留输入图像的哪些部分,而ControlNet引入一种方法,使稳定扩散模型能够使用额外的输入条件,准确地告诉模型要做什么,从而改变了这一现状。”
ControlNet是一个单独的插件,结合Prompt生成图像。可以与SD的文生图、图生图等功能一起使用。
2、ControlNet的安装和使用
安装和使用CN也是非常简单的,我们先启动SD,在“扩展-从网址下载”中输入http://github.com/Mikubill/sd-webui-controlnet,再点击应用更改并重载前端即可。如果失败的话也可以手动下载插件,然后解压到extensions文件夹中。
然后我们需要下载预处理器和模型。这一步可能会花比较多的时间。官方http://huggingface.co/lllyasviel/ControlNet/tree/main/models给的压缩包很大,每个都有5个多G,但是其实这些模型有很大的重复部分,这对我们这些硬盘吃紧的人来说很不友好。

为此,迹寒专门进行了资源裁剪,只保留了模型的有效部分,所有模型加起来才9个G。你也可以挑想要的进行下载。

ControlNet 目前提供的预训模型,可用性完成度更高。而 T2I-Adapter ”在工程上设计和实现得更简洁和灵活,更容易集成和扩展”。
下载完需要将模型放入models\ControlNet文件夹下,然后重启SD,点击刷新按钮 ️,应该可以看到“预处理器”和“模型”分别多了很多项:
预处理器:

模型:

(1)界面介绍

“工欲善其事,必先利其器”。我们简单了解一下界面。首先,我们看到最上面和图生图一样,有一个图像上传区域。然后右下方可以看到四个图标:
1) 表示新建画布,你可以在上面涂鸦,然后生成图像。(灵魂画手的福音)
2) 打开电脑摄像头(如果有的话),可以对自拍进行处理。
3)对电脑摄像头画面取镜像。
4)将图像尺寸发送到SD。这个功能很实用,以免忘记修改上方的图像大小。
正下面是四个选项框。
- 启用:选中此框以启用ControlNet,否则就不起作用。
- 低显存模式:顾名思义,如果你显存很低,就开启这个选项。
- 完美像素模式:可以生成更高质量的图像。
- 允许预览:将预处理器的结果显示出来。这个选项非常有用,建议勾选:
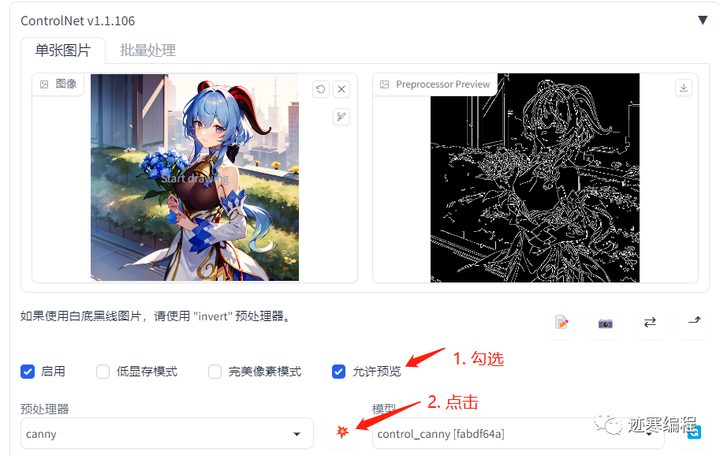
注意要点一下 按钮才能生效。
预处理器:对图像作预处理。这一步不需要很多资源,我们很快就能看到结果。
模型:ControlNet模型。预处理可以为空,但模型一定要有!
然后是一些参数相关的:
控制权重: ControlNet的权重,代表使用ControlNet生成图片的权重占比影响。
引导介入步数:从哪一步开始,ControlNet开始生效。这个值介于0-1。
引导终止步数:从哪一步开始,ControlNet结束生效。这个值介于0-1。
控制类型:有三个选项:“均衡”、“更注重提示词”和“更倾向于让ControlNet自由发挥”。这个理解起来不难,大家酌情使用。
缩放模式:有“直接调整大小”、“比例裁剪后缩放”和“缩放后填充空白”。根据需要进行选择。
[回送] 自动发送生成后的图像到此 ControlNet unit:将生成的结果做成ControlNet输入。用于多轮次迭代。
准备工作完成了,下面我们开始体验吧!
3、体验ControlNet
模型固定为Anything-V4.5。提示词依据情况设定,反提示词为EasyNegative, badhandv4。
(1)识别边缘
canny 用于识别输入图像的边缘信息。设置如下:
例如我们现在有一张手捧鲜花的甘雨图:

预处理识别边缘后的结果:

不加任何提示词,生成一个新图像,”啊,妹妹你是谁?“

是不是很神奇呢?canny的一个常见用途是提取线稿,在此基础上生成不同风格的图片。
(2)深度信息
depth用于获取图像的深度信息。大家听说过景深这个概念吧,深度信息和这个类似。人类为什么有两只眼睛?除了对称美以外,很重要的原因是为了形成立体视觉,获取深度信息。
另外还有一些参数,一般默认就好:

以下面还是以不上班的甘雨为例,采用LeRes深度图估算:

得到的深度图长这样,颜色越深表示距离观测者越远:

生成的图片是以此深度图为基础的,生成的画面就很有意思了,人物和背景的轮廓没有变,但内容大变样。

甘雨的角变成了辫子,可见CN的创意还是很棒的。
(3)线稿提取
前面我们介绍了canny边缘图,但其边界还是比较硬的,怎么样才能获得那种素描的效果呢?答案就是hed啦~
我们来看一个例子,还是王小美姐姐的例子:

预处理得到的线稿效果图,是不是有板绘那味了?

生成的图片中,我们可以看到一些光影和色调细节发生改变:

(4)建筑边缘提取
对于室内设计而言,线条大多数是直的,这就适合用mlsd进行边缘提取。

建筑边缘识别效果如下:

生成图的效果如下,这应该是…原始自然风格?不太懂。

这应该能为设计师提供不少灵感。
(5)姿态信息
姿态信息是最有趣而且最实用的信息之一,如果未来AI能生成动画的,那么根据姿态生成图像是必经之路。对应的CN模型为openpose。

对于这张图,姿态估计图中除了手部脚部细节,可以清晰看到人物躯体,并且是符合人物比例的。
做一下笔记
<br/>openpose
提取的骨骼图,面部细节缺失。<br/>openpose_face
支持识别面部,而身体的识别效果也比较好。
生成的图片也是同样的姿势。最有趣的是,我们可以用一个OpenposeEditor插件手动绘制我们想要实现的姿势。下载地址:http://github.com/fkunn1326/openpose-editor。
在选项图上可以看到Openpose编辑器选项。
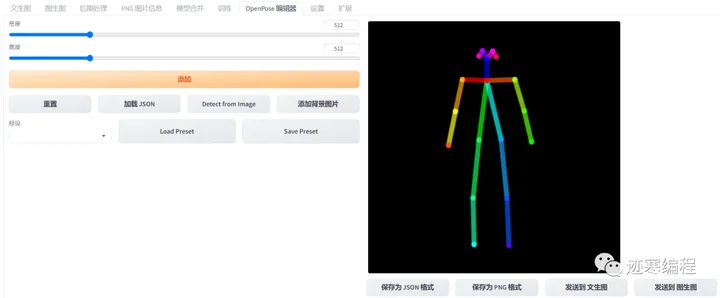
首先点击“添加一张背景图片”,然后“Detect from image”,自动检测姿势。

我们移动关节点来修改姿势,然后发送到“文生图”可以生成一组相同姿势的人物图:
1)拿着小鼓的JK女孩,躺在床上

2)带着花帽蓄着胡须的男人

3)在图书馆整理图书的少女

4)依靠着空气的帅气男孩(bushi)

(6)草图转图像
比如我们输入的是一张草图,能不能让AI上色呢?答案是Yes,利用scribble插件就可以拯救每一位有着绘画梦想的小可爱!
比如笔者简单画了一个奔跑的火柴人:

看看生成的图像:

连我自己都震惊了。灵魂画手的福音。(虽然脸部还欠缺一点)
此外你还可以上传自己画的线稿,比如迹寒之前画了一张:

看看生成的效果,Amazing!生成的图片风格与模型息息相关。如果要形成自己独一无二的风格,还需要自己训练模型才行。笔者有一个大胆的想法,以后的画家不仅会画画,而且会训练自己的模型 !
(7)图像分割
图像分割也是很实用的功能,对应的插件是seg。
例如下面是一张小女孩学习的图片,不同的色块表示不同的区域:

生成的图像,画面主要框架没变,但内容变了。

但是AI分割并不是万能的,在一些非常细节的地方,仍然会有瑕疵。
(8)不同的组合
其实这里面是有一些技巧在里面的:预处理器和模型需要一一对应吗?答案是NO。
我们来做一个实验,以canny, depth, openpose四个模型和三个预处理器为例制作一个图表。

可见有的组合会碰撞出创意的火花,有的组合是正正为负,不太河里的。通过合理的组合可以得到意想不到的效果。
(9)多通道
什么是多通道呢?简单来说,就是你希望CN在不同阶段调用不同的模型。生成的图片通常会有不同模型的特征。下面我们来演示一下:
首先启用多通道。在“设置-ControlNet”,把“多重 ControlNet 的最大模型数量”调到1以上就算开启了。回来打开CN选项卡,变成了这样:

然后我们来体验一下,将下面两张图片:


得到的图片长这样:

女孩出现在了我们设定的场景,并且画面具有上面两幅图像的特征。
如何生成更好的调整参数,达到风格各异的效果,还需要大家多多尝试~
七、模型融合
模型融合按照字面意思理解就行。其优势是可以综合两个模型的特点,例如三次元和二次元的融合,可能有非常奇特的效果。我们先学习一下界面。

模型A,B(C):最少合并2个模型,最多合并3个模型。
自定义名称【可选】:融合模型的名字,建议把两个模型和所占比例加入到名称之中,例如“Anything_v4.5_0.5_3Guofeng3_0.5”
融合比例M:意思是模型A占(1-M)x100%, 模型B占Mx100%
融合算法:推荐用“加权和”
输出模型格式:ckpt是默认格式,safetensors格式可以理解为CKPT的升级版,可以拥有更快的AI绘图生成速度,而且不会被反序列化攻击。
**存储办精度模型:**通过降低模型的精度来减少显存占用。
复制配置文件:选择A,B 或 C即可。
嵌入VAE模型:嵌入当前的vae模型,相当于加了滤镜。缺点是会增加模型大小。
删除匹配键名的表达式的权重【可选】:可以理解为,你想删除模型内的某个元素时,可以将其键值进行匹配删除。
我们尝试合并Anything_v4.5(二次元)和3Guofeng3_0(三次元)两种风格。看看会不会有有趣的事情发生。
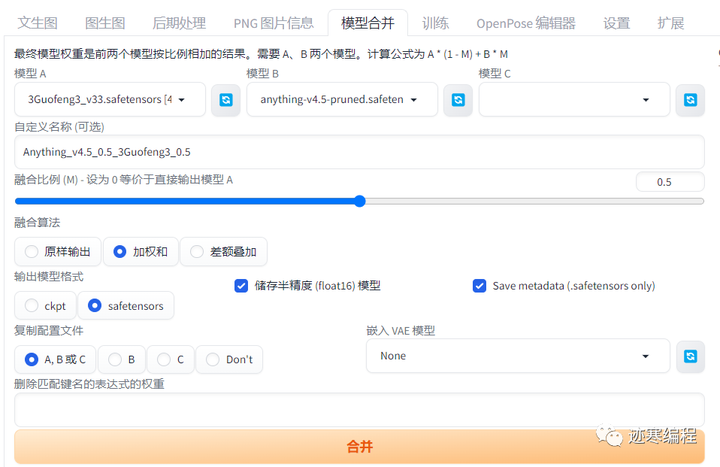
合并速度非常快,耗时为2分左右,在右侧我们已经可以看到输出后的模型路径已自动放置Stable Diffusion的主模型目录内,我们无需任何设置就已经可以加载并使用合并后的模型。
我们用同一个prompt在A,B和AB模型生成一张图片看看(为了便于比较,采用ControlNet控制画面内容):
模型A:国风,偏真人效果

咒语:
best_quality, masterpiece, 4K, 1girl, chinese style, hanfu, smiling, red lips, pursed lips, closed mouse, left hand down, green belts, landscape, hill, mountain, stone, tree, streams, pear blossom, birds, petals, windy, blurry foreground, blurry backgound
Negative prompt: EasyNegative, badhandv4, (easynegative:1.0), (worst quality, low quality:1.4), (lip, nose, tooth, rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0), (1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams, trembling, motion lines, motion blur, emphasis lines, text, title, logo, signature, backlighting
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1954584771, Size: 768x1024, Model hash: 3732b141fb, Model: Anything_v4.5_0.5_3Guofeng3_0.5, Clip skip: 2, ControlNet Enabled: True, ControlNet Module: depth_leres, ControlNet Model: control_depth [92c999f3], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
模型B:二次元风格

咒语:
best_quality, masterpiece, 4K, 1girl, chinese style, hanfu, smiling, red lips, pursed lips, closed mouse, left hand down, white dress, , green belts, landscape, hill, mountain, stone, tree, streams, pear blossom, birds, petals, windy, blurry foreground, blurry backgound
Negative prompt: EasyNegative, badhandv4, (easynegative:1.0), (worst quality, low quality:1.4), (lip, nose, tooth, rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0), (1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams, trembling, motion lines, motion blur, emphasis lines, text, title, logo, signature, backlighting
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1954584771, Size: 768x1024, Model hash: 6e430eb514, Model: anything-v4.5-pruned, Clip skip: 2, ControlNet Enabled: True, ControlNet Module: depth_leres, ControlNet Model: control_depth [92c999f3], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
融合模型AB:

咒语:
best_quality, masterpiece, 4K, 1girl, chinese style, hanfu, smiling, red lips, pursed lips, closed mouse, left hand down, green belts, landscape, hill, mountain, stone, tree, streams, pear blossom, birds, petals, windy, blurry foreground, blurry backgound
Negative prompt: EasyNegative, badhandv4, (easynegative:1.0), (worst quality, low quality:1.4), (lip, nose, tooth, rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0), (1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams, trembling, motion lines, motion blur, emphasis lines, text, title, logo, signature, backlighting
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1954584771, Size: 768x1024, Model hash: 3732b141fb, Model: Anything_v4.5_0.5_3Guofeng3_0.5, Clip skip: 2, ControlNet Enabled: True, ControlNet Module: depth_leres, ControlNet Model: control_depth [92c999f3], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
效果非常惊艳!利用这个方法我们能快速生成新模型,收获新的创意!
LoRA模型训练
模型训练指的是自己提供训练集,然后训练。能够实现自己所期望的风格。模型训练有一定的上手难度,所以本文将尽可能细致地讲解训练过程。模型训练有很多方法,例如Dream booth、Textual Inversion (embedding)、Hypernetwork和著名的Lora等方式。今天我们介绍LoRA模型训练方式,其它方式我们在以后再介绍。
(1)下载项目
前人栽树 ,后人乘凉 ♂️。我们这里出于方便直接用aki大佬的训练脚本吧!http://github.com/Akegarasu/lora-scripts
注意不要直接下zip压缩包,而是用git递归下载子模块。
git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts
下载完lora-scripts后解压到合适位置,因为直接运行会报错,所以用管理员身份打开PowerShell后输入:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned
然后输入”Y“。出于安全考虑,在脚本执行完之后将输入下述命令改回默认权限:
Set-ExecutionPolicy -ExecutionPolicy Restricted
运行install-cn.ps1脚本安装依赖。因为是国内源,下载速度应该非常快。
**(2)准备训练集
**
完毕之后我们来准备一些图片作为训练集吧不需要太多1520张enough。
训练分辨率
训练时的分辨率 宽,高,可以是非正方形,但必须为64的整数倍。建议使用大于 512x512 且小于 1024x1024 的值,长宽比根据训练集的占比决定,一般来说方形的可以照顾到各种不同的分辨率。如果多数为长图可以使用512x768这种分辨率,如果宽图居多则可以使用768x512等。
比如笔者想训练可莉的模型(问就是玩原玩的)。首先在网上收集一些图片,一种方法是下载好图片由PS软件裁剪至统一大小(没有的话用birme工具),另一种是用SD自带的裁剪(不推荐,可能把人物主体裁剪)。然后我们前往”图片预处理“文件夹,目标是生成图片的tag(图片格式必须是png),如下所示:

设置源目录和目标目录(两者不同)。调整合适的长宽(必须是64倍数)。推荐选择”自动面部焦点裁剪“和”使用Deepbooru生成标签“。然后点击”preprocess“就可以开始了。生成的目录中,每个图片和标签文本一一对应。建议检查一下标签的内容,如果觉得不好可以手动修改。
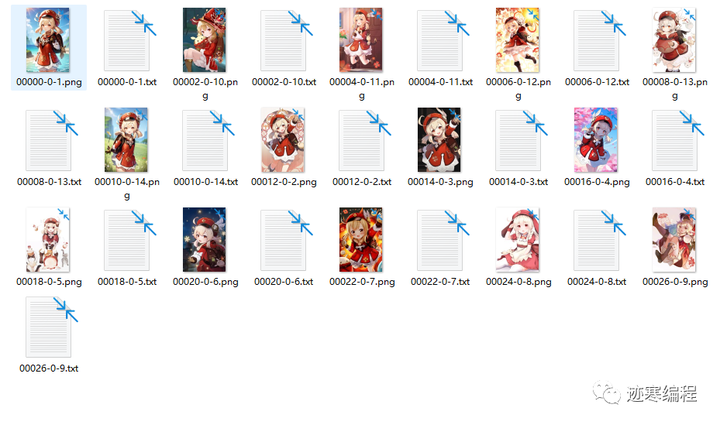
完成后可以将将文件夹重命名为"x_{名字}“,“x”表示训练次数,例如"5_klee”。
**(3)配置参数
**
我们配置一下参数,我们可以在PowerShell运行run_gui.ps1,打开一个网页:
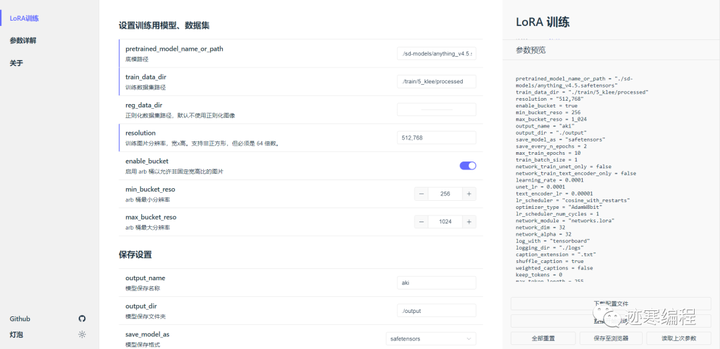
我们来介绍一下这些参数:
底模路径:用于训练的基础模型,尽量选祖宗级别的模型练出来的LoRA会更通用。如果在融合模型上训练可能会仅仅在你训练的底模上生成图片拥有不错的效果 但是失去了通用性。可以自己抉择
什么是祖宗级别的模型? sd1.5 2.0、novelai 原版泄露模型。也就是非融合模型。融合模型比如 anything 系列融合了一大堆,orangemix系列融合了 anything 和 basil 更灵车了等等。在他们上面训练的会迁移性更差一些。
**训练数据集路径:这个必须是图片文件夹的父文件夹!**例如你在".\train\5_klee"放了很多照片,那么应该填".\train"
修改分辨率,输出目录等参数。
开启 ARB 桶,以允许使用非固定宽高比的图像来训练(简单来说就是不需要手动剪裁了)。ARB 桶在一定程度上会增加训练时间。ARB桶分辨率必须大于训练分辨率
此外还有和训练相关的参数:

(4)训练
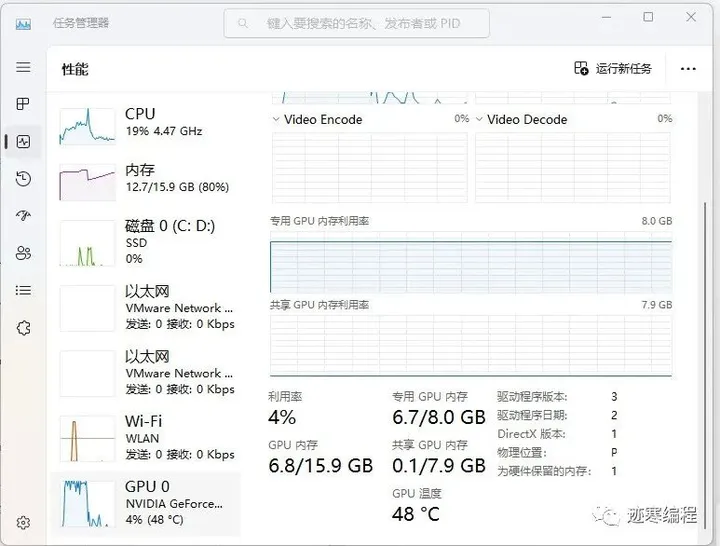
我们然后开始训练吧~
建议关闭一切占显存的应用,包括SD。 可以看到GPU基本上是占满的。
训练完成后在output文件夹下可以看到许多模型:
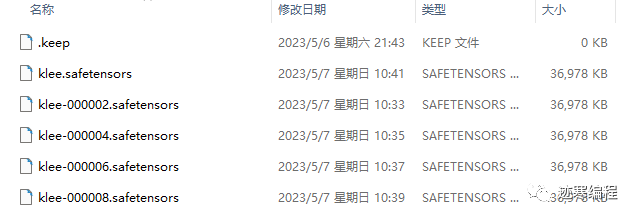
我们来试试效果吧~
注意提示词要加上lora插件**lora:klee:1**
高级教程:
学习率与优化器设置
学习率设置
UNet和TE的学习率通常是不同的,因为学习难度不同,通常UNet的学习率会比TE高 。

如图所示,我们希望UNet和TE都处于一个恰好的位置(绿色部分),但是这个值我们不知道。
如果UNet训练不足,那么生成的图会不像,UNet训练过度会导致面部扭曲或者产生大量色块。TE训练不足会让出图对Prompt的服从度低,TE训练过度则会生成多余的物品。
总学习步数 = (图片数量 * 重复次数 * epoch)/ 批次大小
以UNet学习率为1e-4为例,一般来说图片较少的时候训练人物需要至少1000步,训练画风则需要至少2500步,训练概念则需要至少3000步。这里只是最低的步数,图片多则需要更多步数。学习率更大可以适当减少步数,但并非线性关系,使用两倍的学习率需要使用比之前步数的一半更多的步数。
决定学习率和步数的最好方法是先训练,再测试。一般比较好的初始值为UNet使用1e-4,TE使用5e-5
学习率调整策略(lr_scheduler)
推荐使用余弦退火cosine。如果开启预热,预热步数应该占总步数的5%-10%。
如果使用带重启的余弦退火cosine_with_restarts,重启次数不应该超过4次。
批次大小 (batch_size)
Batch size 越大梯度越稳定,也可以使用更大的学习率来加速收敛,但是占用显存也更大。
一般而言 2 倍的 batch_size 可以使用两倍的 UNet 学习率,但是TE学习率不能提高太多。
优化器
这里只介绍最常用的三种:
- AdamW8bit:启用的int8优化的AdamW优化器,默认选项。
- Lion:Google Brain发表的新优化器,各方面表现优于AdamW,同时占用显存更小,可能需要更大的batch size以保持梯度更新稳定。
- D-Adaptation:FB发表的自适应学习率的优化器,调参简单,无需手动控制学习率,但是占用显存巨大(通常需要大于8G)。使用时设置学习率为1即可,同时学习率调整策略使用constant。需要添加"–optimizer_args decouple=True"来分离UNet和TE的学习率。(这些设置训练UI都会帮你自动处理)
网络设置网络结构(LoRA/LoCon/LoHa/DyLoRA)
不同网络结构对应不同的矩阵低秩分解方法。LoRA 是老祖宗,只控制模型中的线性层和1x1卷积层,后续的不同网络结构都是在 LoRA 的基础上进行改进。
LyCORIS 对其进行改进,添加了其他几种算法:
- LoCon 加入了对卷积层 (Conv) 的控制
- LoHa(哈达玛积)和 LoKr(克罗内克积)
- IA3
理论上来说 LyCORIS 会比 LoRA 拥有更加强的微调效果,但是也更加容易过拟合。
需要注意的是,不同的网络结构一般需要对应不同的 dim 以及学习率。
网络大小
网络大小应该根据实际的训练集图片数量和使用的网络结构决定
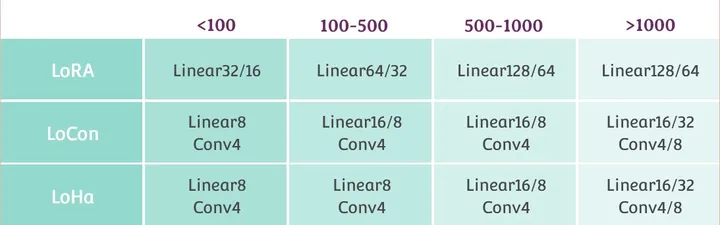
上表中值为我自己的角色训练推荐值,训练画风和概念需要适当增加 Linear 部分大小。推荐值并非对各个不同的数据集都是最优的,需要自己实验得出最优。Conv 的大小最好不要超过8。
网络Alpha(network_alpha)
alpha在训练期间缩放网络的权重,alpha越小学习越慢,关系可以认为是负线性相关的。
一般设置为dim/2或者dim/4。如果选择1,则需要提高学习率或者使用D-Adapation优化器。
高级设置
Caption 相关
caption dropout
网上关于这几个caption dropout的说明少之又少,甚至作者在文档里面也没有包含这些参数,只能在代码注释里面找到说明。但是caption dropout在某些情况下对模型性能有提升,所以拿出来讲一下。
caption_dropout_rate:丢弃全部标签的概率,对一个图片概率不使用caption或class token
caption_dropout_every_n_epochs:每N个epoch丢弃全部标签。
caption_tag_dropout_rate:按逗号分隔的标签来随机丢弃tag的概率。如果使用DB+标签的训练方法训练画风,推荐使用这个参数,能够有效防止tag过拟合,一般选择0.2-0.5之间的值。训练人物则无需开启。
token 热身
两个token热身相关的参数。
token_warmup_min:最小学习的token数量,token_warmup_step: 在多少步后达到最大token数量。
token_warmup可以理解为另一种形式的caption dropout,但是如果不随机打乱token,则只会学习前面N个token。本人并未实测过启用这两个参数的效果,有兴趣可以自行实验。
噪声相关
噪声偏移(noise_offset)
在训练过程中加入全局的噪声,改善图片的亮度变化范围(能生成更黑或者更白的图片)。
如果需要开启,推荐设置值为0.1,同时需要增加学习步数作为网络收敛更慢的补偿。
多分辨率/金字塔噪声 multires_noise_iterations、multires_noise_discount
多分辨率/金字塔噪声相关参数。iteration设置在6-8,再高提升不大。discount设置在0.3-0.8之间,更小的值需要更多步数。
其他一堆参数
- CLIP_SKIP CLIP模型使用倒数第N层的输出,需要与底模使用的值保持一致,如果是基于NAI的二次元模型,应当使用2。如果是SD1.5等真实模型应当使用1。生成时也应该使用同样的值。
- Min-SNR-γ 发表于今年CVPR23上的一种加速扩散模型收敛的方法。不同样本批次的学习难度不同导致梯度方向不一致所以收敛慢,于是引入根据信噪比调整学习率比重。 设置在5左右的值是实验效果比较好的,但是注意优化器使用D-Adaptation的时候不适用,因为学习率是优化器控制的。
- 数据增强相关 数据增强是在训练时实时对图片做变换的方法,可用于防止过拟合,能用的一共有四种: color_aug, flip_aug, face_crop_aug_range, random_crop。 其中只有翻转(flip_aug)能和cache latent兼容,因为latent可以直接翻转。 四种都不推荐使用,因为裁剪图片的两种cropping方法都会导致tag对应不上。color_aug无法启用cache latent导致训练慢,得不偿失。翻转的flip_aug在图像不对称的情况下表现差,会导致无法正确生成人物不对称的特征(刘海、发饰等)。
- max_grad_norm 限制模型更新梯度的大小,改善数值稳定性。梯度的范数超过这个值将会被缩放到这个大小,一般来说无需设置。
- gradient_accumulation_steps 梯度累积步数,用于在小显存上模拟大batch size的效果。如果显存足够使用4以上的batch size就没必要启用。
- log_with、wandb_api_key 选择logger类型,可选tensorboard或者wandb。使用wandb需要指定api key。
- prior_loss_weight DB训练当中先验部分的权重,控制正则化图像的强度,论文中使用的是1的值,如无特殊情况无需更改。
- debug_dataset 不训练模型,仅输出训练集元数据和训练参数信息,可以用来检查各项设置是否正确。
- vae_batch_size cache lantent的时候VAE编码器的batch size,和训练效果无关。一般来说使用2-4可以加速一点cache latent的过程。因为VAE编码器本身参数量比较小,实测在Linux机器上8G的显卡也能开启4。Windows下系统占用显存较多,显存小于10G不建议开启。
八、实践项目一: 设计LOGO 视觉延展

环境搭建
在进行设计之前我们需要先下载Controlnet QR Code Monster模型,该模型可以很好的帮助我们对品牌视觉符号logo图形进行比较准确的控制。
模型下载传送门:https://huggingface.co/monster-labs/control_v1p_sd15_qrcode_monster

进入传送门下载_control_v1p_sd15_qrcode_monster.safetensors_、control_v1p_sd15_qrcode_monster.yaml 两个文件。
并将文件存放在_extensions\sd-webui-controlnet\models_ 文件中。

素材准备
完成基本环境搭建后,我们进入做前期素材准备环节。准备好想要进行视觉延展的原始品牌符号素材以及预期构思的视觉风格prompt关键词。
我们以苹果logo为例,准备的原始素材图片使用了512x512像素尺寸,素材尺寸可以根据个人实际需要调整。为了方便controlnet识别控制结构,素材的颜色这里我们需要统一处理成黑白稿。


Prompt构思
准备好素材后,进入Stable diffusion 文生图界面。
Stable diffusion模型这里以epicrealism_pureEvulutionV5为例,如果没有该模型也可以选择任意其他偏写实类的模型。

我们以硬件主题为例对苹果品牌进行视觉扩展,围绕硬件主题发散出计算机、晶片、芯片、空间、多维等Prompt关键词。在文生图文本框中输入Prompt:
geometric multidimensional space, many three-dimensional light emitting blocks, blue light and black background, with a glowing polygonal computer crystal chip,

如果发散不出比较合适的关键词,也可以先在网上收集一些比较贴切的设计参考,在图生图界面下置入参考图片,点击CLIP反推提示词,选取里面生成的词汇再输入文生图的Prompt中。
04 参数调试
完成prompt输入后,我们进行生成调试环节。点击controlnet插件,将黑白图片素材拖放至controlnet,勾选“启动”,“pixel perfect”和“Allow Preview”选项。
新版ControlNet 1.1新增Pixel Perfect(完美像素模式)可以让ControlNet 自动计算最佳预处理器分辨率,实现与 Stable Diffusion 的完美匹配。
如果没有该选项,可以通过进入扩展选项,点击从网址安装, 复制粘贴以下链接到扩展的git仓库网址,安装完后重启界面即可使用。
GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
预处理选择invert,模型选择control_v1p_sd15_qrcode_monster,其他选项保持默认即可。点击中间红色爆炸图标,可以预览反白效果。如果希望最终生成的视觉效果logo图形部分以深色为主,则预处理器则可以选择无。

在SDXL Styles 界面中勾选“Enable Style Selector” ,Style中勾选“Digital Art”。
该选择器可以提供的选项生成不同类型的风格。如果没有该选项,同样可以复制以下链接在扩展中进行在线安装。
https://github.com/ahgsql/StyleSelectorXL

选择迭代步数,采样方法,宽度和高度,提示次引导系数。宽度和高度这里设置为512,为了方便快速生成不同效果图。

设置好参数后,点击生成开始抽卡。

在生成的图片中选择比较符合设想期望的方向。这里以左上角第一张图为例。
我们在随机数种子中输入符合方向的图片种子,并通过高分辨率修复放大图片精度。在高分辨率修复 (Hires. fix)界面中选择放大算法ESRGAN_4x,设置高分迭代步数,重绘幅度,放大倍数。迭代步数一般选在 10~20 ,步数超过 20 可能会出现畸形。重绘幅度一般在 0.3~0.8 ,根据实际效果调整,如果希望变化更大就调高数值。

点击生成重绘后的图片。

通过PS对生成的画面进行简单处理,将画面中心融入更多发光晶体元素。

我们切换到图生图模式,将处理后的图片放到图生图模式进行二次生成。输入与文生图模式一样的Prompt。设置迭代步数,采样方法,宽度和高度和重绘幅度。


controlnet参数与前面文生图基本一致。

设置好参数后,就可以点击生成了。在这个过程中,可以根据效果调整重绘幅度,直到生成比较满意的画面。

最终效果。

05 其他主题
使用同样的方法,可以尝试不同设计主题风格。我们以环境为主题,我们输入沙漠相关的Prompt,比如_Golden sandstorms and floating sand on a black background, ray traced image,_
设置基本参数。

Style可以选择cinematic。

设置Controlnet参数,可以提高Control Weight强度,让图形轮廓更加明显。

完成参数设置后,开始抽卡生成图片。

我们选择右图进行进下一步生成,在PS中进行简单处理调整底部和头部结构,将火焰替换为沙尘效果。

PS完后我们切换到图生图模式,置入处理后的图片,输入与前面一样的prompt和参数设置。

然后就可以点击生成符合期望的最终画面效果啦。

有了主视觉效果之后,相关延展应用就水到渠成,结合信息内容以及根据应用环境对视觉效果进行适配扩充。

06、结语
以上就是我们在使用StableDiffuse辅助品牌视觉延展的制作过程。整体的制作思路可以大概拆解为6个步骤:以品牌视觉符号为核心>>提炼主题风格关键词>>使用Contrnet控制品牌识别度>>选择符合方向的画面>>结合图生图模式合成细化画面>>完成最终品牌主视觉。
AI的出现为我们节省了大量后期制作的时间,让我们可以更快地达成目标,也让我们有更多的空间去探索表现的形式与内容。AI工具可以决定输出的下限,而设计师的想象力决定了可以触达的上限。合理的借助AI尽情地发挥你的想象力去尝试各种可能吧!
九、实践项目一: 实现运营设计海报落地
如今,AI的应用已经遍布各个行业,运用的方式也越来越丰富,越来越多的人尝试将AI参与进自己的工作流程中。
不过在此之前,我们做项目需求的时候也需要评估项目是否适合使用AI辅助,毕竟AI的功能不是万能的,有些地方也存在着它暂时的“硬伤”。
这次我们将以一个活动运营海报需求为案例,分享如何运用AI工具Stable Diffusion对其进行辅助设计(本篇案例使用的是秋叶版本Stable Diffusion)


制作前期构思与参考
这次需求是制作一张活动推送图,推送给玩家增加活动热度以及获取更多流量。
需求方希望画面中主要体现IP、信件相关的元素,**能给人一种在书写信件的画面感。**按照需求方所给到的信息,我们找了批参考图供给需求方确认画面大致感觉。

通过参考图与需求方的沟通后,我们大致确认画面是一张信纸在桌面上,信纸上写着本次活动的相关内容。

确定风格&AI运用
视觉风格上,通过讨论以及参考图的视觉效果,最终还是决定倾向于三维质感,不过这次我们打算尝试运用AI辅助制作整体的画面基调。
因为之前做过一版类似的推送图,所以本次就相当于做一次画面迭代,而用AI来进行画面的迭代也正好是非常合适的。

话不多说,我们先进入到Stable diffusion。首先,我们进入到图生图界面,将垫图素材拖入图生图的图片区域。输入好关键词并调节好参数开始炼图。

关键词如下:The center of the image is a piece of paper on the table, The image is a close-up shot, showing the details of the paper, The image is taken from a bird’s-eye view angle, Close-up view, indoors, the scene is bright, The overall picture is bright, The picture is a 3D modeling, C4D, Octane renderer, masterpiece, best quality, highres, original, reflection, unreal engine rendered, body shadow, extremely detailed CG unity 8k wallpaper, minimalistlora:toon2:0.5 lora:COOLKIDS_MERGE_V2.5:0.2
(在这里我们使用了toon2 和 COOLKIDS这两个lora模型。模型不唯一,可根据自己需求在C站上自行选择下载。)
反向关键词:(worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((greyscale))
反向关键词就使用一些通用的即可。
参数内容如下:

其中要注意下,在一开始炼图时,重绘幅度需要大概控制在0.5-0.7范围内,避免变化过大破坏构图,也要避免变化过小达不到画面迭代的效果。
接着就可以开始炼图了,这个环节对比Midjourney来说,可以避免花费过多时间炼图,Stable Diffusion的可控制参数比较多,也因此可以更快的炼出接近自己想要的图片。

以上是筛选出的几张图,接着再选出一张图作为本次需求的底图,并开始进行下一环节的操作。
S****D放大&重绘功能的使用
我们选择用第二张图作为底图,但是放大后不难发现,它的分辨率低,不清晰。有很多细节也存在缺失的问题。这个时候我们可以对他进行SD放大操作。
1.SD Upscale介绍
SD Upscale也被叫为SD放大,简单理解可以把它看作是图生图中的高清修复。它的工作原理是将要放大的图片均匀的分成多块,分别进行重新绘制,并最终拼回一张图,以此来进行高清放大的效果,于此同时还能为画面添加不少细节。
我们可以在图生图界面中滑至最下方,点击脚本这一栏展开,里面有一个使用SD放大(SD Upscale),点击选择即可开启。(注意,只有图生图才能使用该脚本)
2.SD Upscale的使用
首先,我们将底图拖入图生图的图片区域,然后打开SD放大,其中放大倍数以及图块重叠像素可以不做变化,放大算法可以选择R-ESRGAN 4X+ 或者R-ESRGAN 4x+ Anime6B(这个偏向二次元一些)。其它也可以尝试,这两个放大算法是我们比较常用的。

接着我们在画面尺寸这里,宽度高度分别在原来的基础上加上图块重叠的像素数值,也就是分别加64。对应着现在的宽度为902,高度为512,加上64后宽度就变为966,高度变为576。

也许很多人疑惑为什么要加上这64像素呢,这里简单解释下。因为SD放大的原理是将一张图分成均匀的多块重新渲染,然后再重新将这几块图片拼回一张图。而为了使拼接部分不会出现断层,割裂等不和谐的感觉,在这四块图片的贴合处增加了一部分区域,算法会利用这部分区域去处理拼接处,使得拼接位置过度的更加自然,整体。
回到正题,设置好后,将重绘幅度调低至0.3-0.35(因为只是用于高清修复,并不想画面内容发生变化,所以此时要保持低重绘幅度),设置好后就可以开始生成图片了。

以上是高清修复后的图,可看到画面的清晰度肉眼可见地提高了,画面的细节也丰富了不少。但是也存在着一个问题,画面有许多奇怪的物体,以及一些bug存在,这时候就可以开始用到Stable Diffusion的重绘功能了。
3.重绘功能的使用
首先,我们想去掉纸上的内容,并且把桌子上一些杂乱的东西都去掉,我们可以选择把图片导入ps里进行简单的p图处理,然后再导回Stable Diffusion中的图生图,将重绘幅度调低再生成一次即可。(一般重新用图生图输出的图片分辨率都会变低,需要重新用Stable Diffusion放大高清修复一下,然后再在此基础上进行重绘)

紧接着我们开始对画面个别元素进行调整。首先,我们想把右上角的黄色卡纸换成信封,这时候我们就可以运用涂鸦重绘功能。点击涂鸦重绘,进入涂鸦重绘版面。

因为我们想把卡纸换成黄色的信封,点击右上角的色盘icon,选择黄色,调整画笔大小,在卡纸的位置涂上一层,示意这里要换成一封信(注意涂鸦的造型尽量和想生成的物体的造型接近,这样有利于算法识别)。然后在关键词后加上一个黄色的信封,并给上一些权重。(a yellow envelope:1.3)


点击生成后,多生成几次图,挑选较为满意的一张后,先不着急细化修改,继续把画面其它想要替换的物品调整好。替换的方式也可以像信封一样,使用涂鸦重绘即可。

不过像重叠的书本,或者玩具这类,造型轮廓不规则的,AI在计算过程可能不能很好地识别。这个时候我们也可以直接使用局部重绘功能,在要重新绘制的区域涂上一层蒙版,然后在关键词后补充上想要替换的内容。例如一叠书本,就在关键词后补充上(A stack of books:1.4),记得加一点权重。


通过这种方式,我们可以把画面里想要替换的元素都替换掉,并且风格也能保持一致,实现“指哪打哪”。(当然,这也避免不了需要多次炼图,尽管Stable Diffusion可控性好,但AI始终是AI,想要直接渲出自己想要的图片还是很难的。)

到最后,我想在桌面上加一支笔和一个闹钟,但是在涂鸦重绘过程中,始终渲不出我想要的效果。这个时候我们可以找一个笔和闹钟的png素材在ps里简单处理下放在画面中,然后再把它放回到Stable Diffusion的图生图中,调整好低重绘幅度然后重新生成,最后筛选出较为满意的进行后期细化即可。

到了最后阶段,我们就可以回到ps里去增加一些画面的细节和内容了。

最后的最后,给画面加一些后期氛围处理后得到最终版本。

总结
不管是Midjourney、Stable Diffusion还是一些其他AI工具,随着他们版本的不断更新,它们的功能也越来越丰富。这也导致很多设计师越发焦虑,觉得自己这个功能还没学会怎么就出了另外一个功能了。
其实我们没必要焦虑,学习工具的主要目的就是为了把自己想做的东西实现出来,能够在工作中使项目落地。
在这个案例中我们也没有使用较为新颖的功能,主要就是Stable Diffusion放大和重绘功能,这两功能在Stable Diffusion也算是比较基础的。学习新的技能固然重要,但去探索如何运用这些技能去实现项目落地的方法思路更为关键。
十、实践项目三:双十一视觉
录/注册
今天分享一个用Stable Diffusion制作“电商视觉海报”和“电商产品视觉”的小分享,随着双十一的到来,这个分享或许可以给你提供一些创作灵感,也有可能可以帮助你更高效的完成视觉海报的制作。

双十一视觉
在开始之前,需要先准备一张双十一的字体图片。

-
打开Stable Diffusion,将双十一的字体图片上传上去,然后启动“ControlNet”,并且勾选“完美像素”模式。

-
控制类型选择“Canny”,然后“控制权重”可以稍微调整一下,想让双十一字体更明确一些就将控制权重调高,如果不要那么明确就调低或者保持默认就可以。

-
设置好“ControlNet”之后,选择一个模型,这里推荐使用“revAnimated”这个模型,它比较通用。然后输入正向提示词和反向提示词。

这里我使用了两个Lora模型一个是“3D电商模型V1”,另一个是“光效科幻场景”,这两个模型都可以在“liblib”模型站上下载。(在这里感谢两位模型作者的分享,谢谢!)

-
设置生成参数,尺寸建议设置成和ControlNet的那张参考图同样的尺寸比例,然后其他的可以根据自己的需求设置。

-
设置完成后,点击“生成”即可。

电商产品视觉
开始之前需要先准备一张透明背景,或者纯色背景的产品图片。

(图片来自网络,如有侵权,请联系我删除,谢谢)
-
打开Stable Diffusion,选择一个模型,这里推荐使用“revAnimated”这个模型,它比较通用。然后输入正向提示词和反向提示词,先生成一张电商场景图。

这里我使用了一个电商场景Lora模型“电商场景PLUS”,这个模型可以在“liblib”模型站上下载(在这里感谢这位模型作者的分享,谢谢!)

-
设置生成参数,这里可以根据自己的需求设置。

-
点击“生成”,可以多生成几次,然后挑选一张自己满意的场景图。

-
场景生成完成之后,将图片保存下来,然后用“PS”或者其他的图片编辑工具将产品图和场景图合并在一起。

-
打开Stable Diffusion,将合并好后的产品图片上传到图生图。

-
设置生成参数,尺寸建议和原图片一样的大小或比例,然后“重绘幅度”建议调整到0.5左右。

-
设置ControlNet,在“ControlNet Unit 0”,启用并勾选“完美像素模式”,然后控制类似选择“Lineart”这里也可以选择“Canny”这两个都可以。

-
在“ControlNet Unit 1”,启用并勾选“完美像素模式”,然后控制类似选择“Depth”。

-
设置好以上参数之后,选择一个模型,然后输入正向提示词和反向提示词(这里用生成场景的模型和提示词就可以),然后点击“生成”即可。

我们可以看到产品很好的融入到了场景里面,但是还是会有一些细节上的东西需要用“PS”或其他图片处理工具在处理一下。
最后
以上是对使用Stable Diffusion进行电商产品视觉制作的分享。虽然目前AI生成的图片仍需要使用第三方图片处理工具进行二次处理,但这已经极大地提高了我们的工作效率。
十一、实践项目四:五一劳动节的海报
用stable diffusion制作一张庆祝五一劳动节的海报。模型:
一、出几张劳动者
最关键词:(silhouette style) 剪影风格
absurdres, 8k, comic, viewfinder,silhouette style, white background, full body, (construction worker working),
调性还是不错的。如果没有太阳,自己加sunshine,sun,dusk,early morning,诸如此类的名称。

去掉颜色,但我还想要简洁一点,让他变成黑白照
absurdres, 8k, comic, viewfinder, silhouette style, black and white style, construction workers working

再换个单人的看看效果
正向:剪影+黑白+扁平风,白色背景,完整身体,建筑工人工作,只有动作
反向:建筑物,施工结构
CFG(提示词相关性):26
// positive
absurdres, 8k, comic, viewfinder, silhouette style, black and white style, flat design style, white background, full body, construction worker working, (only action),
// negative
((buildings)),(construction site)

最后一次,加入单色、只有一个人、不要出现黑色背景,提示词相关性降低为22
// positive
absurdres, 8k, comic, viewfinder, (silhouette style), (black and white style), (monochrome), (flat design style), white background, (full body), 1construction worker working, (only one worker in viewer),
// negative
easynegative, buildings, construction site, mechanical, black background, instrument, colorful, room, hole

二、出几张背景
让chatgpt写一段夕阳,看看有没有能用的。
The clouds at sunset are tinged with shades of orange, pink, and gold, creating a stunning and dramatic backdrop for the setting sun. The clouds appear as if they are on fire, glowing with warmth and radiance, slowly drifting across the sky as the sun sinks below the horizon, duotone

再换个城市画面看看
sky, sun, city, buildings faraway, light, happy,

利用绘图模式试试看云端鸟瞰城市
((aerial view)), (photorealistic), absurdres, 8k, cloudy sky, (sunlight:1.2), sunshine, buildings in city under the clouds,

看来不能用蓝色画云,AI总以为云下面是大海。
三、整合出图
选张AI生成的工人图,抠图

给工人上点线条,再和背景整合
本文是将工人主体填充别的色彩了,如果一开始就决定这么做,那么是不是黑白剪影都无所谓,只是这样抠图会容易些罢了。

看看放到图生图里有什么效果
((aerial view)), (photorealistic), absurdres, 8k, construction worker, city, buildings faraway, sunlight, beautiful red,

最后加点文字出图
不要评论我的审美啊~~要赞美劳动者!

最后来一个超高饱和,红得发紫的旭日东升!



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











