







Zipline: Production-ready backtesting by Quantopian
摘要信息:
使用 Zipline 的机器学习交易工作流程:
-
数据准备
- 从数据源(如 Yahoo Finance、Quandl 等)获取股票价格数据
- 清洗和预处理数据,如处理缺失值、异常值等
- 将数据转换为 Zipline 所需的数据格式
-
特征工程
- 根据交易策略设计相关的特征,如价格趋势、波动率、交易量等
- 使用 Zipline 的数据管道功能计算特征值
-
模型构建和训练
- 选择合适的机器学习算法,如线性回归、随机森林等
- 使用 Zipline 的回测框架训练模型,并优化超参数
-
策略回测
- 利用 Zipline 的回测引擎对训练好的模型进行回测
- 分析回测结果,包括收益率、风险指标、交易情况等
-
策略部署
- 将训练好的模型部署到实时交易环境中
- 使用 Zipline 的实时交易接口执行交易操作
-
监控和优化
- 持续监控策略在实际交易中的表现
- 根据市场变化和交易情况,定期优化模型和策略
通过使用 Zipline 这个强大的回测和交易框架,可以更高效地构建、测试和部署机器学习驱动的交易策略。Zipline 提供了丰富的数据管理、回测和交易功能,大大简化了整个机器学习交易工作流程。
Zipline: 由Quantopian开发的面向生产环境的回测引擎
Zipline回测引擎支撑了Quantopian在线研究、回测和实盘(模拟)交易平台。作为一家对冲基金,Quantopian旨在识别出可靠的、超额收益的算法,并满足其风险管理标准。为此,他们利用竞赛的方式来选择最佳策略,并将资金分配给获胜者以分享收益。
Quantopian于2012年首次发布了Zipline 0.5版本,最新版本1.3于2018年7月发布。Zipline可以很好地与我们在第4章和第5章介绍的姊妹库Alphalens、pyfolio和empyrical协作,并与NumPy、pandas和其他数值计算库很好地集成,但可能无法始终支持最新版本。
The backtesting engine Zipline powers Quantopian’s online research, backtesting, and live (paper) trading platform. As a hedge fund, Quantopian aims to identify robust algorithms that outperform, subject to its risk management criteria. To this end, they have used competitions to select the best strategies and allocate capital to share profits with the winners.
Quantopian first released Zipline in 2012 as version 0.5, and the latest version 1.3 dates from July 2018. Zipline works well with its sister libraries Alphalens, pyfolio, and empyrical that we introduced in Chapters 4 and 5 and integrates well with NumPy, pandas and numeric libraries, but may not always support the latest version.
Content
- Installation
- Zipline Architecture
- Exchange calendars and the Pipeline API for robust simulations
- Code Example: How to load your own OHLCV bundles with minute data
- Code Example: The Pipeline API - Backtesting a machine learning signal
- Code Example: How to train a model during the backtest
- Code Example: How to use the research environment on Quantopian
Installation
请按照installation目录中的说明来使用我们在本示例中使用的修补版Zipline。
Please follow the instructions in the installation directory to use the patched Zipline version that we’ll use for the examples in this book.
This notebook uses the
condaenvironmentbacktest. Please see the installation instructions for downloading the latest Docker image or alternative ways to set up your environment.
Zipline Architecture
Zipline被设计用于处理成千上万个证券,每个证券都可以与大量指标相关联。与backtrader相比,Zipline在回测过程中施加了更多的结构,以确保数据质量(例如消除前瞻性偏差),并在执行回测时优化计算效率。
本章节将更深入地探讨下面图示中所示的架构的关键概念和元素,然后演示如何使用Zipline在您选择的数据上回测基于机器学习的模型。
Zipline is designed to operate at the scale of thousands of securities, and each can be associated with a large number of indicators. It imposes more structure on the backtesting process than backtrader to ensure data quality by eliminating look-ahead bias, for example, and optimize computational efficiency while executing a backtest.
This section of the book takes a closer look at the key concepts and elements of the architecture shown in the following Figure before demonstrating how to use Zipline to backtest ML-driven models on the data of your choice.
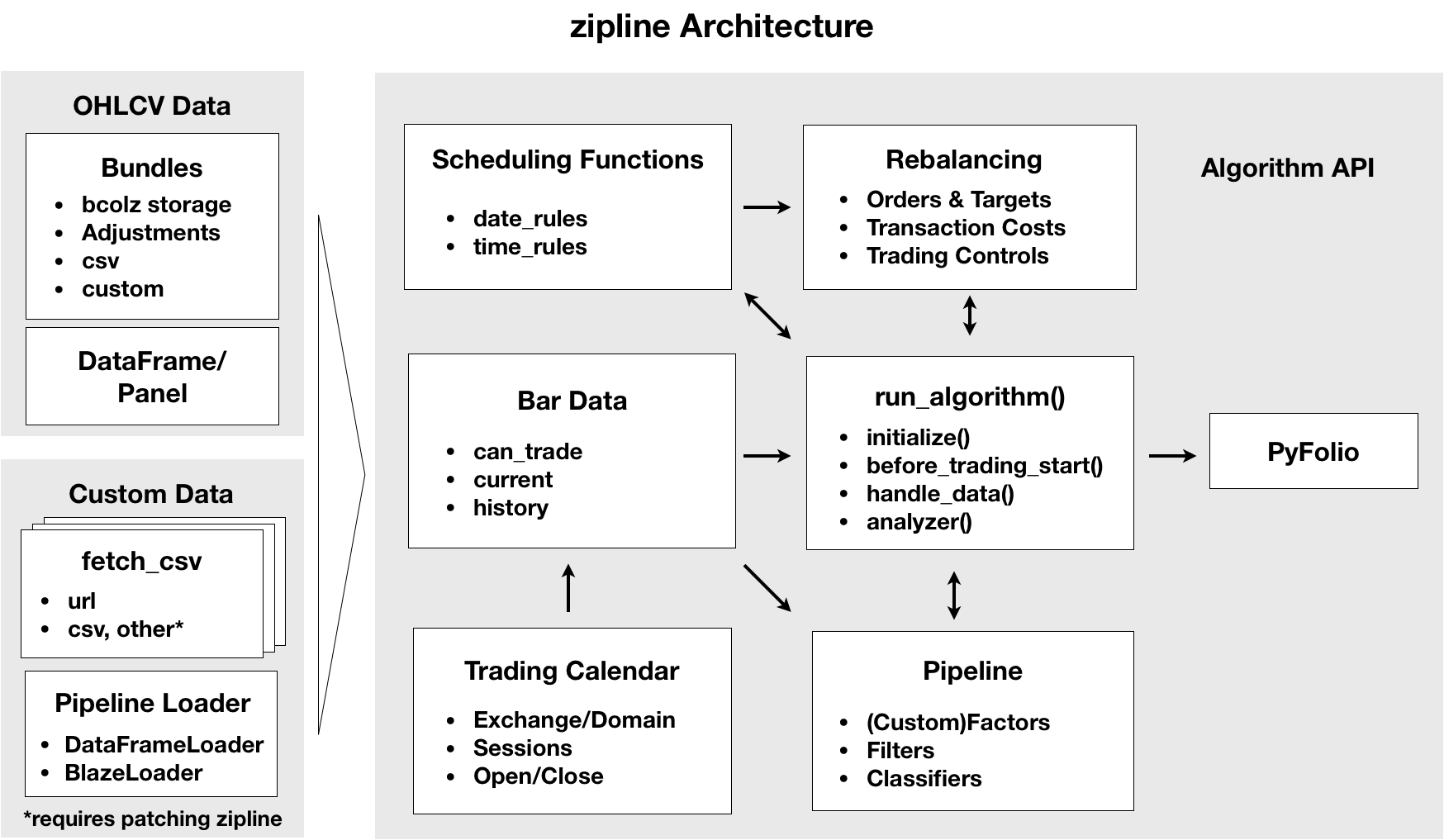
Exchange calendars and the Pipeline API for robust simulations
交易所日历和 Pipeline API 是 Zipline 中实现可扩展和可靠回测的两个关键特性:
- 交易所日历(Exchange Calendars) Zipline
内置了多个交易所的交易日历,如纽约证券交易所、纳斯达克等,用于准确模拟交易时间。
这些交易日历反映了全球各交易所的实际运营时间,确保回测结果符合现实情况。
Pipeline API
Pipeline API 是 Zipline 的一个强大功能,用于高效地计算和管理大规模的特征数据。
通过声明式的数据处理流程,Pipeline API 可以在回测时自动进行数据预处理、特征工程等操作,大大提高了计算效率。这样可以确保回测过程中不会出现前瞻性偏差等问题,提高了仿真的可靠性。
有助于实现可扩展性和可靠性目标的关键特性包括:
数据包(data bundles)存储了带有拆分和股息即时调整的OHLCV市场数据。
交易日历(trading calendars)反映了全球各交易所的运营时间和强大的Pipeline API。
本节将概述它们的使用方法,以补充前几章中简要介绍的Zipline内容
Key features that contribute to the goals of scalability and reliability are data bundles that store OHLCV market data with on-the-fly adjustments for splits and dividends, trading calendars that reflect operating hours of exchanges around the world, and the powerful Pipeline API. This section outlines their usage to complement the brief Zipline introduction in earlier chapters.
Bundles and friends: Point-in-time data with on-the-fly adjustments
数据包和相关内容:带有即时调整的时点数据
主要的数据存储是一个 数据包(bundle), 它以压缩的列式 bcolz 格式存储在磁盘上,以实现高效的检索,并配合存储在 SQLite 数据库中的元数据。数据包仅包含 OHLCV 数据,且仅支持日频和分钟频数据。一个很好的特性是,数据包存储了拆分和股息信息,Zipline 根据您选择的回测时间段计算 时点调整(point-in-time adjustments)。
Zipline 依赖 交易日历(Trading Calendars) 库(也由 Quantopian 维护)获取全球各交易所的操作细节,如时区、开市和收市时间或节假日。数据源有域(目前为国家)的概念,需要符合分配的交易所日历。Quantopian 正在积极开发对国际证券的支持,这些特性可能会不断发展。
安装后,运行命令 zipline ingest -b quandl 即可立即安装 Quandl Wiki 数据集(日频)。结果存储在默认位于您家目录的 .zipline 目录中,您也可以通过设置 ZIPLINE_ROOT 环境变量来修改位置。此外,您还可以设计自己的包含 OHLCV 数据的数据包。
数据包的缺点是无法存储价格和成交量以外的其他数据。但是,有两种替代方法可以实现这一点:
-
fetch_csv()函数可以从 URL 下载 DataFrame,设计用于其他 Quandl 数据源(如基本面数据)。Zipline 会合理地认为该数据与您提供的 OHLCV 数据属于同一证券,并相应地对齐 bars。 -
DataFrameLoader和BlazeLoader允许您向Pipeline提供其他属性(见本章后面的DataFrameLoader演示)。BlazeLoader可以与多个数据源(包括数据库)进行交互。但由于 Pipeline API 仅限于日频数据,fetch_csv()将在后续章节添加分钟频数据特征时至关重要。
总之,数据包及其相关工具为 Zipline 提供了高效、准确的数据管理能力,为稳健的回测奠定了基础。
The principal data store is a bundle that resides on disk in compressed, columnar bcolz format for efficient retrieval, combined with metadata stored in an SQLite database. Bundles are designed to contain only OHLCV data and are limited to daily and minute frequency. A great feature is that bundles store split and dividend information, and Zipline computes point-in-time adjustments depending on the time period you pick for your backtest.
Zipline relies on the Trading Calendars library (also maintained by Quantopian) for operational details on exchanges around the world, such as time zone, market open and closing times, or holidays. Data sources have domains (for now, these are countries) and need to conform to the assigned exchange calendar. Quantopian is actively developing support for international securities, and these features may evolve.
After installation, the command zipline ingest -b quandl lets you install the Quandl Wiki dataset (daily frequency) right away. The result ends up in the .zipline directory that by default resides in your home folder but can modify the location by setting the ZIPLINE_ROOT environment variable . In addition, you can design your own bundles with OHLCV data.
A shortcoming of bundles is that they do not let you store data other than price and volume information. However, two alternatives let you accomplish this: the fetch_csv() function downloads DataFrames from a URL and was designed for other Quandl data sources, e.g. fundamentals. Zipline reasonably expects the data to refer to the same securities for which you have provided OHCLV data and aligns the bars accordingly. It’s not very difficult to make minor changes to the library’s source code to load from local CSV or HDF5 using pandas instead, and the patched version included in the conda environment backtest includes this modification.
In addition, the DataFrameLoader and the BlazeLoader permit you to feed additional attributes to a Pipeline (see the DataFrameLoader demo later in the chapter). The BlazeLoader can interface with numerous sources, including databases. However, since the Pipeline API is limited to daily data, fetch_csv() will be critical to adding features at minute frequency as we will do in later chapters.
The Algorithm API: Backtests on a schedule
算法 API:按计划进行回测
TradingAlgorithm 类实现了 Zipline 算法 API,并在与给定交易日历对齐的 BarData 上操作。在初始设置之后,回测会在指定的时间段内运行,并在特定事件发生时执行交易逻辑。这些事件由每日或每分钟的交易频率驱动,但您也可以安排任意函数来评估信号、下单、重新平衡投资组合,或记录正在进行的仿真的相关信息。
您可以从命令行、Jupyter Notebook 或使用底层 TradingAlgorithm 类的 run_algorithm() 方法来执行算法。该算法需要一个在仿真开始时被调用一次的 initialize() 方法。它通过 context 字典维护状态,并通过包含时点(PIT)当前和历史数据的 data 变量获取可操作信息。您可以向 context 字典添加属性,这些属性在所有其他 TradingAlgorithm 方法中都可用,或注册执行更复杂数据处理(如计算 alpha 因子和过滤证券)的管道。
算法执行发生在由 Zipline 自动安排或用户定义的间隔内的可选方法中。before_trading_start() 方法在每天市场开盘前被调用,主要用于识别算法当天可能交易的一组证券。handle_data() 方法按给定的交易频率(如每分钟)被调用。
完成后,算法会返回一个包含投资组合绩效指标(如果有任何交易)以及用户定义指标的 DataFrame。如第 5 章所示,输出与 pyfolio 兼容,因此您可以快速创建绩效报告。
The TradingAlgorithm class implements the Zipline Algorithm API and operates on BarData that has been aligned with a given trading calendar. After the initial setup, the backtest runs for a specified period and executes its trading logic as specific events occur. These events are driven by the daily or minutely trading frequency, but you can also schedule arbitrary functions to evaluate signals, place orders, and rebalance your portfolio, or log information about the ongoing simulation.
You can execute an algorithm from the command line, in a Jupyter Notebook, and by using the run_algorithm() method of the underlying TradingAlgorithm class. The algorithm requires an initialize() method that is called once when the simulation starts. It keeps state through a context dictionary and receives actionable information through a data variable containing point-in-time (PIT) current and historical data. You can add properties to the context dictionary which is available to all other TradingAlgorithm methods or register pipelines that perform more complex data processing, such as computing alpha factors and filtering securities.
Algorithm execution occurs through optional methods that are either scheduled automatically by Zipline or at user-defined intervals. The method before_trading_start() is called daily before the market opens and primarily serves to identify a set of securities the algorithm may trade during the day. The method handle_data() is called at the given trading frequency, e.g. every minute.
Upon completion, the algorithm returns a DataFrame containing portfolio performance metrics if there were any trades, as well as user-defined metrics. As demonstrated in Chapter 5, the output is compatible with pyfolio so that you can create quickly create performance tearsheets.
Known Issues
实时交易您自己的系统仅在 Interactive Brokers 上可用,并且没有得到 Quantopian 的完全支持。
代码示例:如何加载自己的分钟频OHLCV数据包
我们将使用在第 2 章中介绍的 AlgoSeek 提供的 NASDAQ100 样本,演示如何编写自己的自定义数据包以分钟频率的数据。参见第 11 章中关于使用日频日本股票数据的示例。
有四个步骤:
- 将您的 OHCLV 数据拆分为每个标的一个文件,并存储元数据、拆分和股息调整。
- 编写一个脚本,将结果传递给
ingest()函数,该函数负责将数据包以 bcolz 和 SQLite 格式写入。 - 在位于
ZIPLINE_ROOT/.zipline目录(默认在用户的家目录)的extension.py脚本中注册数据包,并为数据源创建符号链接。 - 对于 AlgoSeek 数据,我们还提供了一个自定义的
TradingCalendar,因为它包含了标准纽约证券交易所交易时间以外的交易活动。
custom_bundles 目录包含了代码示例。
准备 AlgoSeek 数据以打包
在第 2 章中,我们解析了包含 AlgoSeek NASDAQ 100 OHLCV 数据的日文件,以获得每个标的的时间序列。我们将使用这个结果,因为 Zipline 也会单独存储每个证券。
此外,我们使用 pandas-dataReader 的 get_nasdaq_symbols() 函数获取股票元数据。最后,由于 Quandl Wiki 数据涵盖了相关期间的 NASDAQ 100 标的,我们从该数据包的 SQLite 数据库中提取拆分和股息调整数据。
结果是一个 HDF5 存储 algoseek.h5,其中包含大约 135 个标的的价格和成交量数据以及相应的元数据和调整数据。脚本 [algoseek_preprocessing](algoseek_preprocessing.py] 说明了这个过程。
编写自定义数据包的 ingest 函数
Zipline 文档概述了 ingest() 函数所需的参数,但没有提供太多实际细节。脚本 algoseek_1min_trades.py 展示了如何使用分钟数据实现这一部分。
简而言之,有一个 load_equities() 函数提供元数据,一个 ticker_generator() 函数提供标的给 data_generator() 函数,后者则加载并格式化每个标的的市场数据,最后一个 algoseek_to_bundle() 函数整合所有部分并返回所需的 ingest() 函数。
时区对齐很重要,因为 Zipline 会将所有数据序列转换为 UTC 时间;我们为 OHCLV 数据添加 US/Eastern 时区信息并将其转换为 UTC。为了方便执行,我们在 .zipline 目录的 custom_data 文件夹中为这个脚本和 algoseek.h5 数据创建符号链接,我们将在下一步将其添加到 PATH 中,以便 Zipline 找到这些信息。为此,我们运行以下 shell 命令:
- 将此目录的绝对路径赋值给
SOURCE_DIR:export SOURCE_DIR = absolute/path/to/machine-learning-for-trading/08_strategy_workflow/04_ml4t_workflow_with_zipline/01_custom_bundles - 创建符号链接:
- 到
algoseek.h5在ZIPLINE_ROOT/.zipline:ln -s SOURCE_DIR/algoseek.h5 $ZIPLINE_ROOT/.zipline/custom_data/. - 到
algoseek_1min_trades.py:ln -s SOURCE_DIR/algoseek_1min_trades.py $ZIPLINE_ROOT/.zipline/.
- 到
注册您的数据包
在我们可以运行 zipline ingest -b algoseek 之前,我们需要注册我们的自定义数据包,以便 Zipline 知道我们在谈论什么。为此,我们将在 .zipline 目录中的 extension.py 脚本中添加以下几行。您可能需要创建此文件,并添加一些输入和设置(参见 extension 示例)。
注册本身相当简单,但突出了一些重要细节:
- Zipline 需要能够导入
algoseek_to_bundle()函数,因此它的位置需要在搜索路径上,例如使用sys.path.append()。 - 我们引用了一个我们将在下一步创建和注册的自定义日历。
- 我们需要告知 Zipline 我们的交易日比默认的纽约证券交易所 6.5 小时更长,以避免错位。
创建和注册自定义交易日历
正如本节介绍中提到的,Quantopian 还提供了一个 交易日历(Trading Calendar) 库来支持全球交易。该软件包包含许多可以轻松子类化的示例。基于纽约证券交易所日历,我们只需要覆盖开市/收市时间,将结果放在 extension.py 中,并为此日历添加注册。现在我们可以引用这个交易日历来确保回测包括市场休市时间的活动。
代码示例: Pipeline API - 回测机器学习信号
Pipeline API 有助于从历史数据中为一组证券定义和计算 alpha 因子。Pipeline 显著提高了效率,因为它优化了整个回测期间的计算,而不是单独处理每个事件。换句话说,它继续遵循事件驱动架构,但在可能的情况下对因子计算进行向量化。
Pipeline 使用 Factors、Filters 和 Classifiers 类来定义产生一组证券的时点值表格的计算。Factors 接受一个或多个历史 bar 数据输入数组,并产生一个或多个输出。内置有许多因子,您也可以设计自己的 CustomFactor 计算。
下图描述了如何使用 DataFrameLoader 加载数据、使用 Pipeline API 计算预测 MLSignal、以及各种计划活动如何与通过 run_algorithm() 函数执行的整体交易算法集成。我们将在本节中详细介绍细节和相应的代码。
Live trading your own systems is only available with Interactive Brokers and not fully supported by Quantopian.
Code Example: How to load your own OHLCV bundles with minute data
We will use the NASDAQ100 sample provided by AlgoSeek that we introduced in Chapter 2 to demonstrate how to write your own custom bundle for data at minute frequency. See Chapter 11 for an example using daily data on Japanese equities.
There are four steps:
- Split your OHCLV data into one file per ticker and store metadata, split and dividend adjustments.
- Write a script to pass the result to an
ingest()function that in turn takes care of writing the bundle to bcolz and SQLite format. - Register the bundle in an
extension.pyscript that lives in yourZIPLINE_ROOT/.ziplinedirectory (per default in your user’s home folder), and symlink the data sources. - For AlgoSeek data, we also provide a custom
TradingCalendarbecause it includes trading activity outside the standard NYSE market hours.
The directory custom_bundles contains the code examples.
Getting AlgoSeek data ready to be bundled
In Chapter 2, we parsed the daily files containing the AlgoSeek NASDAQ 100 OHLCV data to obtain a time series for each ticker. We will use this result because Zipline also stores each security individually.
In addition, we obtain equity metadata using the pandas-dataReader get_nasdaq_symbols() function. Finally, since the Quandl Wiki data covers the NASDAQ 100 tickers for the relevant period, we extract the split and dividend adjustments from that bundle’s SQLite database.
The result is an HDF5 store algoseek.h5 containing price and volume data on some 135 tickers as well as the corresponding meta and adjustment data. The script [algoseek_preprocessing](algoseek_preprocessing.py] illustrates the process.
Writing your custom bundle ingest function
The Zipline documentation outlines the required parameters for an ingest() function that kicks off the I/O process but does not provide a lot of practical detail. The script algoseek_1min_trades.py shows how to get this part to work for minute data.
In a nutshell, there is a load_equities() function that provides the metadata, a ticker_generator() function that feeds symbols to a data_generator() which in turn loads and format each symbol’s market data, and an algoseek_to_bundle() function that integrates all pieces and returns the desired ingest() function.
Time zone alignment matters because Zipline translates all data series to UTC; we add US/Eastern time zone information to the OHCLV data and convert it to UTC. To facilitate execution, we create symlinks for this script and the algoseek.h5 data in the custom_data folder in the .zipline directory that we’ll add to the PATH in the next step so Zipline finds this information. To this end, we run the following shell commands:
- Assign the absolute path to this directory to
SOURCE_DIR:export SOURCE_DIR = absolute/path/to/machine-learning-for-trading/08_strategy_workflow/04_ml4t_workflow_with_zipline/01_custom_bundles - create symbolic link to
algoseek.h5inZIPLINE_ROOT/.zipline:ln -s SOURCE_DIR/algoseek.h5 $ZIPLINE_ROOT/.zipline/custom_data/.algoseek_1min_trades.py:ln -s SOURCE_DIR/algoseek_1min_trades.py $ZIPLINE_ROOT/.zipline/.
Registering your bundle
Before we can run zipline ingest -b algoseek, we need to register our custom bundle so Zipline knows what we are talking about. To this end, we’ll add the following lines to an extension.py script in the .zipline directory. You may have to create this file alongside some inputs and settings (see the extension example).
The registration itself is fairly straightforward but highlights a few important details:
- Zipline needs to be able to import the
algoseek_to_bundle()function, so its location needs to be on the search path, e.g. by usingsys.path.append(). - We reference a custom calendar that we will create and register in the next step.
- We need to inform Zipline that our trading days are longer than the default six and a half hours of NYSE days to avoid misalignments.
Creating and registering a custom TradingCalendar
As mentioned in the introduction to this section, Quantopian also provides a Trading Calendar library to support trading around the world. The package contains numerous examples that are fairly straightforward to subclass. Based on the NYSE calendar, we only need to override the open/close times, place the result in extension.py, and add a registration for this calendar. And now we can refer to this trading calendar to ensure a backtest includes off-market-hour activity.
Code Example: The Pipeline API - Backtesting a machine learning signal
The Pipeline API facilitates the definition and computation of alpha factors for a cross-section of securities from historical data. The Pipeline significantly improves efficiency because it optimizes computations over the entire backtest period rather than tackling each event separately. In other words, it continues to follow an event-driven architecture but vectorizes the computation of factors where possible.
A Pipeline uses Factors, Filters, and Classifiers classes to define computations that produce columns in a table with PIT values for a set of securities. Factors take one or more input arrays of historical bar data and produce one or more outputs for each security. There are numerous built-in factors, and you can also design your own CustomFactor computations.
The following figure depicts how loading the data using the DataFrameLoader, computing the predictive MLSignal using the Pipeline API, and various scheduled activities integrate with the overall trading algorithm executed via the run_algorithm() function. We go over the details and the corresponding code in this section.

You need to register your Pipeline with the initialize() method and can then execute it at each time step or on a custom schedule. Zipline provides numerous built-in computations such as moving averages or Bollinger Bands that can be used to quickly compute standard factors, but it also allows for the creation of custom factors as we will illustrate next.
Most importantly, the Pipeline API renders alpha factor research modular because it separates the alpha factor computation from the remainder of the algorithm, including the placement and execution of trade orders and the bookkeeping of portfolio holdings, values, and so on.
The notebook backtesting_with_zipline demonstrates the use of the Pipeline interface while loading ML predictions from another local (HDF5) data source. More specifically, it loads the lasso model daily return predictions generated in Chapter 7 together with price data for our universe into a Pipeline and uses a CustomFactor to select the top and bottom 10 predictions as long and short positions, respectively.
The goal is to combine the daily return predictions with the OHCLV data from our Quandl bundle and then to go long on up to 10 equities with the highest predicted returns and short on those with the lowest predicted returns, requiring at least five stocks on either side similar to the backtrader example above. See comments in the notebook for implementation details.
Code Example: How to train a model during the backtest
We can also integrate the model training into our backtest. You can find the code for the following end-to-end example of our ML4T workflow in the ml4t_with_zipline notebook.
The notebook ml4t_with_zipline shows how to train an ML model locally as part of a Pipeline using a CustomFactor and various technical indicators as features for daily bundle data using the workflow displayed in the following figure:

The goal is to roughly replicate the daily return predictions we used in the previous and generated in Chapter 7. We will, however, use a few additional Pipeline factors to illustrate their usage.
The principal new element is a CustomFactor that receives features and returns as inputs to train a model and produce predictions. See notebook for comments on implementation.
Code Example: How to use the research environment on Quantopian
The notebook ml4t_quantopian shows how to train an ML model on the Quantopian platform to utilize the broad range of data sources available there.


















 1943
1943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











