







 本文详细介绍了回归算法的评价标准,包括MSE(均方误差)、RMSE(均方根误差)、MAE(平均绝对误差)和R-Squared。MSE是损失函数,RMSE是MSE的开方,用于统一单位。MAE关注误差的绝对值,而R-Squared则通过比较模型误差与平均值误差来评估模型的解释能力,提供了一个无单位的度量。文章还提及R-Squared小于0意味着预测模型的误差大于基准模型(取平均值)。
本文详细介绍了回归算法的评价标准,包括MSE(均方误差)、RMSE(均方根误差)、MAE(平均绝对误差)和R-Squared。MSE是损失函数,RMSE是MSE的开方,用于统一单位。MAE关注误差的绝对值,而R-Squared则通过比较模型误差与平均值误差来评估模型的解释能力,提供了一个无单位的度量。文章还提及R-Squared小于0意味着预测模型的误差大于基准模型(取平均值)。
一、MSE 均方误差
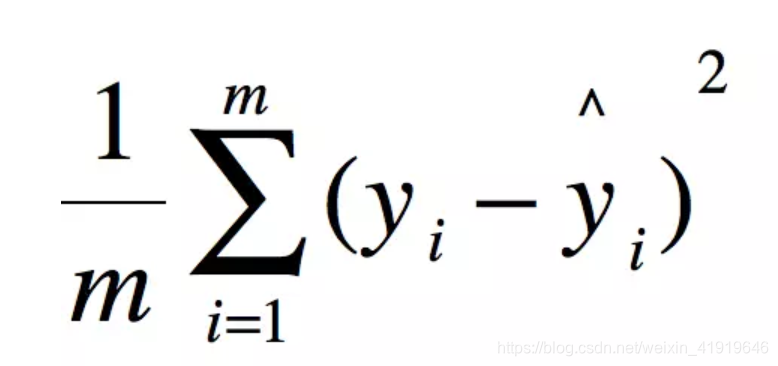
即(真实值-预测值)的平方/测试集个数
其实(真实值-预测值)的平方 就是线性回归的损失函数,线性回归的目的就是为了让损失函数最小化。但这种判断方式是会放大误差的,即本身误差越大的平方后会更大。所以从这也可以看出,损失函数是为了减小最大的那个误差。
二、RMSE 均方根误差
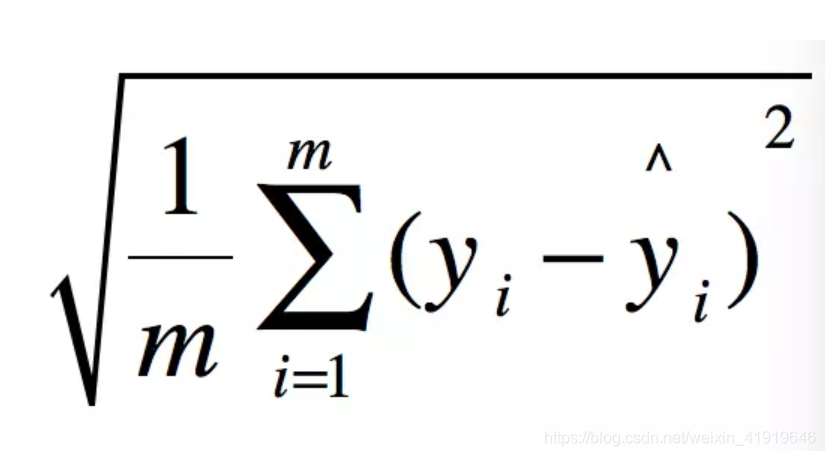
即MSE开根号,使结果的单位和数据集一致,更好描述
三、MAE 平均绝对误差

四、R-Squared
以上3种评价方式,针对不同的模型,有不同的单位。比如米,元。这些不同的单位缺乏可读性。
衡量分类算法通常使用准确率进行衡量,那么衡量回归算法就引入了R-Squared

化简上面公式

分子就变成了我们的均方误差MSE,下面分母就变成了方差。
这里的基准模型即取平均值。分式的分母为方差公式,若R**2<0,即分子大于分母,预测模型误差大于基准模型。
五、实现代码
#这里我们使用sklearn数据集中的波士顿房产数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datastes
boston=datasets.load_boston()
x=boston.data[:,5]
y=boston 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4121
4121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









