








深度森林
深度学习最大的贡献是表征学习(representation learning),通过端到端的训练,发现更好的features,而后面用于分类(或其他任务)的输出function,往往也只是普通的softmax(或者其他一些经典而又简单的方法)而已,所以,只要特征足够好,分类函数本身并不需要复杂representation learning。目前DL的成功都是建立在多层神经网络的基础上的,那么这种成功能否复刻到其他模型上呢?南京大学的周志华老师尝试提出一种深度的tree模型,叫做gcForest,用文中的术语说,就是“multi-Grained Cascade forest”,多粒度级联森林。此外,还提出了一种全新的决策树集成方法,使用级联结构让 gcForest 做表征学习。
论文和实现
https://arxiv.org/abs/1702.08835v2
https://github.com/kingfengji/gcForest
https://github.com/pylablanche/gcForest
整体架构
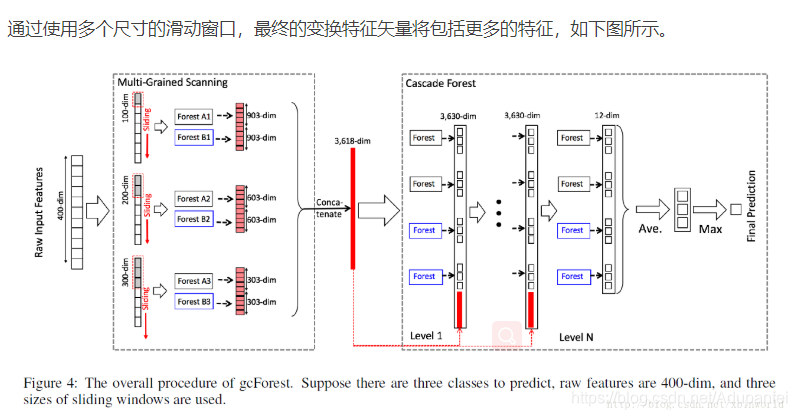
此图为例,三分类,使用三个window,先通过多粒度扫描模块,每个森林的输出都是三位向量,将不同尺度window扫描的结果级联起来得到3618维的向量,再输入到级联森林模块,比如四个森林(两个完全随机森林和两个随机森林)输出12位向量,再与输入的3618维向量级联得到3630维向量,输入下一阶段。最终输出12维向量,取平均,再取最大输出。
两个完全随机森林 每个包括500棵完全随机(完全随机选择特征做节点分裂)
两个随机森林,每个包括500棵树,随机选择sqr(d)个特征,然后选择最好gini系数的一个特征做分裂。
如何得到概率分布
给定一个样本,样本会通过每个树落入一个叶子节点,通过统计训练样本中此节点不同类别的比例,得到概率分布。
如何防止过拟合
每个类别向量通过K折交叉验证生成,每个训练样本被用作k-1次训练数据,最后平均输出。
自动调整级联森林级数(层数)
在该结构中,首先会在一级结束后做一个性能测试,然后再继续生成下一级,当扩展一个新的级后,整个级联的性能将在验证集上进行估计,如果没有显着的性能增益,训练过程将终止。因此,gcForest能够通过适当的终止,来决定其模型的复杂度,这就使得相对于DNN,gcForest在即使面对小数据集的情况下一样使用,因为它的结构不依赖于大量的数据生成。
多粒度扫描模块实现
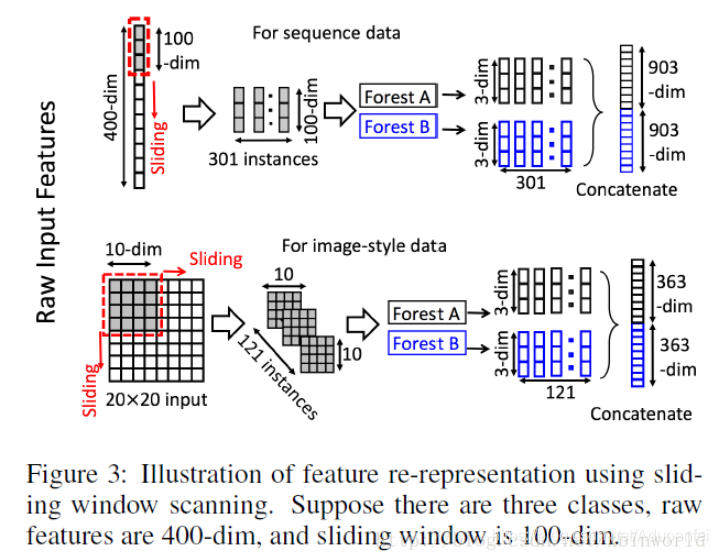
通过多个尺度的滑动窗口实现特征重用(原特征的重新表示),滑动窗口只是扫描特征,不涉及参数(不同于卷积操作),扫描的特征向量作为新的(正/负例)样本。如原特征400维,窗口100,将得到301个100维特征向量的新样本输入森林。最后将所有森林输出的结果级联作为转换特征。如果转换特征维度太长,可做下采样。
级联森林模块
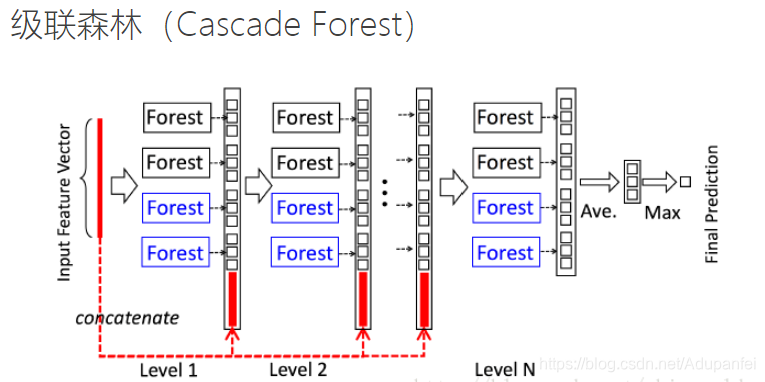
如上图所示,每一层都是由决策树组成的森林组成的,也就是每层都是“集成的集成”。但注意,这里每层都是由两种不同的森林所组成,这是因为周教授在2012年发表论文说,多样的结构对集成学习来说是很重要的。那这里所谓的两种森林是指什么呢?这里举了个简单的例子,例如说图中黑色的完全随机森林,而蓝色的是普通随机森林。完全随机森林是由1000棵决策树组成,每棵树随机选取一个特征作为分裂树的分裂节点,然后一直生长直到每个叶节点细分到只有1个类别或者不多于10个样本。类似的,普通随机森林由1000棵决策树构成,每棵树通过随机选取sqrt(k)(k表示输入特征维度,即特征数)个候选特征,然后通过gini分数筛选分裂节点。所以两种森林的主要区别在于候选特征空间,完全随机森林是在完整的特征空间中随机选取特征来分裂,而普通随机森林是在一个随机特征子空间内通过gini系数来选取分裂节点。这里只提到完全随机森林中决策树的生长规则——完全或近乎完全生长,但没有提到普通随机森林的生长规则,按经验应该是可以设定停止生长规则或者采用后剪枝来修剪模型的。每个森林里决策树的数量其实是个超参数。
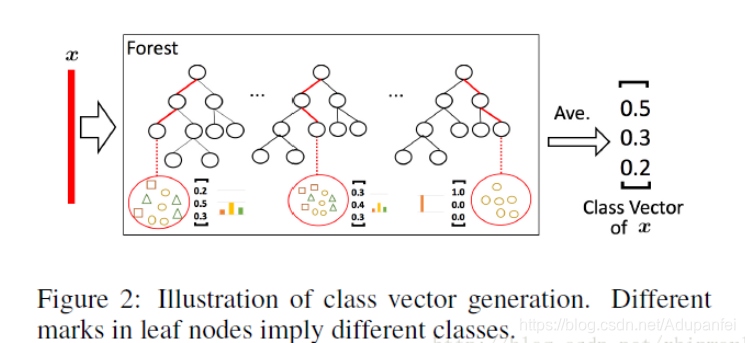
因为决策树其实是在特征空间中不断划分子空间,并且给每个子空间打上标签(分类问题就是一个类别,回归问题就是一个目标值),所以给予一条测试样本,每棵树会根据样本所在的子空间中训练样本的类别占比生成一个类别的概率分布,然后对森林内所有树的各类比例取平均,输出整个森林对各类的比例。例如下图所示,这是根据图1的三分类问题的一个简化森林,每个样本在每棵树中都会找到一条路径去找到自己对应的叶节点,而同样在这个叶节点中的训练数据很可能是有不同类别的,我们可以对不同类别进行统计获取各类的比例,然后通过对所有树的比例进行求均值生成整个森林的概率分布。
优势(相对DNN):
- 深度神经网络需要花大力气调参,相比之下 gcForest 要容易训练得多。实际上,在几乎完全一样的超参数设置下,gcForest在处理不同领域(domain)的不同数据时,也能达到极佳的性能。
- gcForest 的训练过程效率高且可扩展。在我们的实验中,它在一台PC 上的训练时间和在 GPU 设施上跑的深度神经网络差不多,有鉴于 gcForest 天然适用于并行的部署,其效率高的优势就更为明显。
- 此外,深度神经网络需要大规模的训练数据,而 gcForest 在仅有小规模训练数据的情况下也照常运转。
- 不仅如此,作为一种基于树的方法,gcForest 在理论分析方面也应当比深度神经网络更加容易。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









