







最近在排查filebeat收集日志大量占用资源的过程中,萌生了一个想法,能不能找到一款比filebeat更好且资源消耗更低的开源组件呢?于是乎,就有了下面的实践。
ilogtail介绍
ilogtail是阿里巴巴开源的一款轻量级、高性能的可观测数据收集客户端,在阿里内部已经过了长期广泛的实践检验,详细的介绍可以参考官方用户使用手册介绍官方介绍,本文就不再赘述了。因为没有使用官方的sls服务,因此本文主要是实践kubernetes环境下通过ilogtail的daemonset部署采集pod日志,推送到kafka,并通过logstash+elasticsearch的数据处理,最后使用kibana提供日志查询服务。
daemonset模式采集k8s容器日志实践
ilogtail的configmap部署
root@devops172019000054:/tmp# vim ilogtail-user-configmap-processor.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: ilogtail-user-cm
namespace: ilogtail
data:
xcws_service.yaml: |
enable: true
inputs:
- Type: service_docker_stdout #表示采集容器的标准输出
Stderr: true #是否采集stderr
Stdout: true #是否采集stdout
K8sNamespaceRegex: "^(xcws)$" #过滤名称空间的方式采集指定pod组日志,也可以使用其他方式过滤
BeginLineCheckLength: 15
BeginLineRegex: "\\d+-\\d+-\\d+.*" #指定分隔符,默认为单行分割,可根据实际设置
flushers:
- Type: flusher_kafka #指定输出到kafka
Brokers:
- 10.15.1.75:9092
Topic: xcws-log #kafka的topic名称,需要提前存在,或kafka支持自动创建topic
注意:上述config文件中使用了ilogtail的独立名称空间,在创建该configmap前需要先创建ilogtail名称空间。
root@devops172019000054:/tmp# kubectl apply -f ilogtail-user-configmap-processor.yaml
root@devops172019000054:/tmp# kubectl get cm -n ilogtail
NAME DATA AGE
kube-root-ca.crt 1 1m
ilogtail-user-cm 1 1m
ilogtail的daemonset部署
root@devops172019000054:/tmp# vim ilogtail-daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ilogtail-ds
namespace: ilogtail
labels:
k8s-app: logtail-ds
spec:
selector:
matchLabels:
k8s-app: logtail-ds
template:
metadata:
labels:
k8s-app: logtail-ds
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: logtail
env:
- name: cpu_usage_limit
value: "1"
- name: mem_usage_limit
value: "512"
image: >-
sls-opensource-registry.cn-shanghai.cr.aliyuncs.com/ilogtail-community-edition/ilogtail:latest
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 400m
memory: 384Mi
volumeMounts:
- mountPath: /var/run
name: run
- mountPath: /logtail_host
mountPropagation: HostToContainer
name: root
readOnly: true
- mountPath: /usr/local/ilogtail/checkpoint
name: checkpoint
- mountPath: /usr/local/ilogtail/user_yaml_config.d
name: user-config
readOnly: true
dnsPolicy: ClusterFirst
hostNetwork: true
volumes:
- hostPath:
path: /var/run
type: Directory
name: run
- hostPath:
path: /
type: Directory
name: root
- hostPath:
path: /etc/ilogtail-ilogtail-ds/checkpoint
type: DirectoryOrCreate
name: checkpoint
- configMap:
defaultMode: 420
name: ilogtail-user-cm
name: user-config
root@devops172019000054:/tmp# kubectl apply -f ilogtail-daemonset.yaml
root@devops172019000054:/tmp# kubectl get pod -n ilogtail
NAME READY STATUS RESTARTS AGE
ilogtail-ds-wsxk6 1/1 Running 0 1h
ilogtail-ds-rdwqn 1/1 Running 0 1h
ilogtail-ds-f9fjr 1/1 Running 0 1h
验证
在上述步骤中,我们将集群业务模块的日志推送到kafka的xcws-log topic中,接下来就可以通过kafka验证推送数据。
root@devops010015001075:/opt/kafka# bin/kafka-console-consumer.sh --topic xcws-log --bootstrap-server 10.15.1.75:9092
{"Time":1658196626,"Contents":[{"Key":"content","Value":"[2022-07-19 10:10:25,265] INFO com.xxxxxxxxxxxxxx(PlatformService.java:236) xxxxxxxxxxx"},{"Key":"_time_","Value":"2022-07-19T10:10:25.265351372+08:00"},{"Key":"_source_","Value":"stdout"},{"Key":"_image_name_","Value":"xxxxxxxx"},{"Key":"_container_name_","Value":"xxxxxxx"},{"Key":"_pod_name_","Value":"xxxxx"},{"Key":"_namespace_","Value":"xcws"},{"Key":"_pod_uid_","Value":"2e72d904-6abc-4e98-b802-6ede278d80a2"},{"Key":"_container_ip_","Value":"10.42.1.16"}]}
{"Time":1658196626,"Contents":[{"Key":"content","Value":"[2022-07-19 10:10:25,293] INFO com.xxxxxxxxxxxxx(PlatformService.java:238)[===SYSTEM===]:xxxxxxx"},{"Key":"_time_","Value":"2022-07-19T10:10:25.293926893+08:00"},{"Key":"_source_","Value":"stdout"},{"Key":"_image_name_","Value":"xxxxxxx"},{"Key":"_container_name_","Value":"xxxxxxx"},{"Key":"_pod_name_","Value":"xxxxxxxx"},{"Key":"_namespace_","Value":"xcws"},{"Key":"_pod_uid_","Value":"2e72d904-6abc-4e98-b802-6ede278d80a2"},{"Key":"_container_ip_","Value":"10.42.1.16"}]}
从上面的输出可以看出,ilogtail对日志进行了json格式的重新组装,所有的信息被放到Contents的列表对对象中,除了本身的日志输出以外,还包含了采集时间、pod的镜像地址、容器名称、名称空间、容器ip等标识pod的信息。
elasticsearch的配置搭建
logstash中需要配置elasticsearch的服务地址,因此可以先将elasticsearch服务部署完毕后再部署logstash。
root@devops010015001075:/opt# vim es_deployment.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
generation: 1
labels:
app: elasticsearch-logging
version: v1
name: elasticsearch
spec:
minReadySeconds: 10
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: elasticsearch-logging
version: v1
strategy:
type: Recreate
template:
metadata:
creationTimestamp: null
labels:
app: elasticsearch-logging
version: v1
spec:
affinity:
nodeAffinity: {}
containers:
- env:
- name: discovery.type
value: single-node
- name: ES_JAVA_OPTS
value: -Xms512m -Xmx512m
- name: MINIMUM_MASTER_NODES
value: "1"
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.0-amd64
imagePullPolicy: IfNotPresent
name: elasticsearch-logging
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
resources:
limits:
cpu: "1"
memory: 1Gi
requests:
cpu: "1"
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /data
name: es-persistent-storage
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: user-1-registrysecret
initContainers:
- command:
- /sbin/sysctl
- -w
- vm.max_map_count=262144
image: alpine:3.6
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
procMount: Default
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /opt/es_data
type: ""
name: es-persistent-storage
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
labels:
app: elasticsearch-logging
spec:
type: ClusterIP
ports:
- port: 9200
name: elasticsearch
selector:
app: elasticsearch-logging
root@devops010015001075:/opt# kubectl apply -f es_deployment.yml
logstash的配置搭建
logstash configmap部署
root@devops010015001075:/opt# cat logstash-config.yml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-config
data:
logstash.conf: |-
input {
kafka {
bootstrap_servers => '10.15.1.75:9092'
group_id => 'elk-dev'
client_id => 'elk-dev'
topics_pattern => "xcws-.*"
codec => "json"
decorate_events => true
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
}
}
root@devops010015001075:/opt# kubectl apply -f logstash-config.yml
logstash deployment部署
root@devops010015001075:/opt# vim logstash-dep.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash
labels:
name: logstash
spec:
replicas: 1
selector:
matchLabels:
name: logstash
template:
metadata:
labels:
app: logstash
name: logstash
spec:
containers:
- name: logstash
image: docker.elastic.co/logstash/logstash:7.12.0
ports:
- containerPort: 5044
protocol: TCP
- containerPort: 9600
protocol: TCP
volumeMounts:
- name: logstash-config
mountPath: /usr/share/logstash/pipeline/logstash.conf
subPath: logstash.conf
volumes:
- name: logstash-config
configMap:
name: logstash-config
---
apiVersion: v1
kind: Service
metadata:
name: logstash
labels:
app: logstash
spec:
type: ClusterIP
ports:
- port: 5044
name: logstash
selector:
app: logstash
root@devops010015001075:/opt# kubectl apply -f logstash-dep.yml
kibana 部署
实验环境,本次实践使用nodeport的模式暴露服务,当然在使用中也可以通过其他方式暴露服务。
root@devops010015001075:/opt# vim kibana.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
labels:
name: kibana
spec:
replicas: 1
selector:
matchLabels:
name: kibana
template:
metadata:
labels:
app: kibana
name: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.12.0
ports:
- containerPort: 5601
protocol: TCP
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
---
apiVersion: v1
kind: Service
metadata:
name: kibana
spec:
ports:
- protocol: TCP
port: 80
targetPort: 5601
nodePort: 30060
type: NodePort
selector:
app: kibana
root@devops010015001075:/opt# kubectl apply -f kibana.yml
验证
此时,通过浏览器访问任意node节点的30060,就可以访问到kibana。
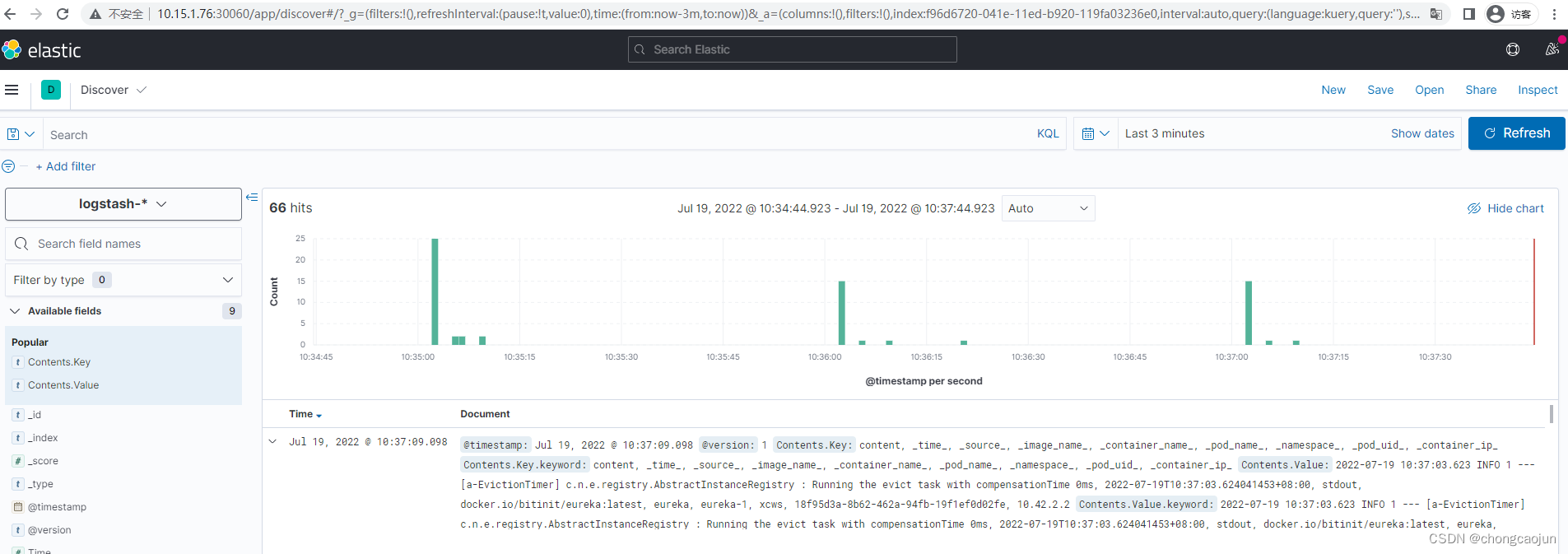
此时我们的基本流程就已经跑通了,通过ilogtail的采集到数据处理,再到数据查询展示。但是,细心的你可能会发现,此时的日志Contents.Key、Contents.Value中包含了多个字段,并且多个字段只是简单的用空格进行了分割,当单条日志比较大的时候,可读性将大大降低。于是乎,我们需要对数据进行优化,熟悉logstash的童鞋可能立马会想到能不能在logstash中对数据进行处理?
数据的优化输出
我们首先将logstash的数据输出到终端查看具体的格式,通过修改logstash的配置文件,输出到终端。
root@devops010015001075:/opt# vim logstash-config.yml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-config
data:
logstash.conf: |-
input {
kafka {
bootstrap_servers => '10.15.1.75:9092'
group_id => 'elk-dev'
client_id => 'elk-dev'
topics_pattern => "xcws-.*"
codec => "json"
decorate_events => true
}
}
output {
stdout { #修改原有输出elasticsearch到终端输出
codec => rubydebug
}
}
root@devops010015001075:/opt# kubectl apply -f logstash-config.yml
root@devops010015001075:/opt# kubectl get pod
NAME READY STATUS RESTARTS AGE
logstash-65bb74d7c5-sgn2l 1/1 Running 0 57s
使用kubectl logs 查看logstash pod的日志输出
root@devops010015001075:/opt# kubectl logs -f logstash-65bb74d7c5-sgn2l
.....
{
"Time" => 1658199078,
"@version" => "1",
"@timestamp" => 2022-07-19T02:51:23.312Z,
"Contents" => [
[0] {
"Key" => "content",
"Value" => "[2022-07-19 10:51:14,840] INFO Resolving eureka endpoints via configuration"
},
[1] {
"Key" => "_time_",
"Value" => "2022-07-19T10:51:14.841162814+08:00"
},
[2] {
"Key" => "_source_",
"Value" => "stdout"
},
[3] {
"Key" => "_container_name_",
"Value" => "xxxxxx"
},
[4] {
"Key" => "_pod_name_",
"Value" => "xxxxx"
},
[5] {
"Key" => "_namespace_",
"Value" => "xcws"
},
[6] {
"Key" => "_pod_uid_",
"Value" => "e5e786d6-056d-4cd3-be21-f181ab1f88ef"
},
[7] {
"Key" => "_container_ip_",
"Value" => "10.42.1.8"
},
[8] {
"Key" => "_image_name_",
"Value" => "xxxxxx"
}
]
}
....
通过查看上述日志,我们发现pod信息和日志内容被放在了Contents列表中,接下来我们要做的工作就是将列表中的内容提取出来,因为列表是无序的,因此不能通过如上的索引简单的进行提取,提取之前需要做判断,继续改造logstash的configmap文件。
root@devops010015001075:/opt# vim logstash-config.yml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-config
data:
logstash.conf: |-
input {
kafka {
bootstrap_servers => '10.15.1.75:9092'
group_id => 'elk-dev'
client_id => 'elk-dev'
topics_pattern => "xcws-.*"
codec => "json"
decorate_events => true
}
}
filter { #通过添加filter字段,对原有内容就行提取
if [Contents][0][Key] == "content" { #判断内容较为死板,如果你有更好的办法,欢迎批评指正
mutate { #新增字段
add_field => ["message","%{[Contents][0][Value]}"]
}
} else if [Contents][1][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][1][Value]}"]
}
} else if [Contents][2][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][2][Value]}"]
}
} else if [Contents][3][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][3][Value]}"]
}
}else if [Contents][4][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][4][Value]}"]
}
}else if [Contents][5][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][5][Value]}"]
}
}else if [Contents][6][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][6][Value]}"]
}
}else if [Contents][7][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][7][Value]}"]
}
}else if [Contents][8][Key] == "content"{
mutate {
add_field => ["message","%{[Contents][8][Value]}"]
}
}
if [Contents][0][Key] == "_source_" {
mutate {
add_field => ["source","%{[Contents][0][Value]}"]
}
} else if [Contents][1][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][1][Value]}"]
}
} else if [Contents][2][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][2][Value]}"]
}
} else if [Contents][3][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][3][Value]}"]
}
}else if [Contents][4][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][4][Value]}"]
}
}else if [Contents][5][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][5][Value]}"]
}
}else if [Contents][6][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][6][Value]}"]
}
}else if [Contents][7][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][7][Value]}"]
}
}else if [Contents][8][Key] == "_source_"{
mutate {
add_field => ["source","%{[Contents][8][Value]}"]
}
}
if [Contents][0][Key] == "_image_name_" {
mutate {
add_field => ["image_name","%{[Contents][0][Value]}"]
}
} else if [Contents][1][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][1][Value]}"]
}
} else if [Contents][2][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][2][Value]}"]
}
} else if [Contents][3][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][3][Value]}"]
}
}else if [Contents][4][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][4][Value]}"]
}
}else if [Contents][5][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][5][Value]}"]
}
}else if [Contents][6][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][6][Value]}"]
}
}else if [Contents][7][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][7][Value]}"]
}
}else if [Contents][8][Key] == "_image_name_"{
mutate {
add_field => ["image_name","%{[Contents][8][Value]}"]
}
}
if [Contents][0][Key] == "_container_name_" {
mutate {
add_field => ["container_name","%{[Contents][0][Value]}"]
}
} else if [Contents][1][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][1][Value]}"]
}
} else if [Contents][2][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][2][Value]}"]
}
} else if [Contents][3][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][3][Value]}"]
}
}else if [Contents][4][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][4][Value]}"]
}
}else if [Contents][5][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][5][Value]}"]
}
}else if [Contents][6][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][6][Value]}"]
}
}else if [Contents][7][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][7][Value]}"]
}
}else if [Contents][8][Key] == "_container_name_"{
mutate {
add_field => ["container_name","%{[Contents][8][Value]}"]
}
}
if [Contents][0][Key] == "_pod_name_" {
mutate {
add_field => ["pod_name","%{[Contents][0][Value]}"]
}
} else if [Contents][1][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][1][Value]}"]
}
} else if [Contents][2][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][2][Value]}"]
}
} else if [Contents][3][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][3][Value]}"]
}
}else if [Contents][4][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][4][Value]}"]
}
}else if [Contents][5][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][5][Value]}"]
}
}else if [Contents][6][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][6][Value]}"]
}
}else if [Contents][7][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][7][Value]}"]
}
}else if [Contents][8][Key] == "_pod_name_"{
mutate {
add_field => ["pod_name","%{[Contents][8][Value]}"]
}
}
if [Contents][0][Key] == "_namespace_" {
mutate {
add_field => ["namespace","%{[Contents][0][Value]}"]
}
} else if [Contents][1][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][1][Value]}"]
}
} else if [Contents][2][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][2][Value]}"]
}
} else if [Contents][3][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][3][Value]}"]
}
}else if [Contents][4][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][4][Value]}"]
}
}else if [Contents][5][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][5][Value]}"]
}
}else if [Contents][6][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][6][Value]}"]
}
}else if [Contents][7][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][7][Value]}"]
}
}else if [Contents][8][Key] == "_namespace_"{
mutate {
add_field => ["namespace","%{[Contents][8][Value]}"]
}
}
if [Contents][0][Key] == "_container_ip_" {
mutate {
add_field => ["container_ip","%{[Contents][0][Value]}"]
}
} else if [Contents][1][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][1][Value]}"]
}
} else if [Contents][2][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][2][Value]}"]
}
} else if [Contents][3][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][3][Value]}"]
}
}else if [Contents][4][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][4][Value]}"]
}
}else if [Contents][5][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][5][Value]}"]
}
}else if [Contents][6][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][6][Value]}"]
}
}else if [Contents][7][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][7][Value]}"]
}
}else if [Contents][8][Key] == "_container_ip_"{
mutate {
add_field => ["container_ip","%{[Contents][8][Value]}"]
}
}
mutate {
remove_field => ["Contents"] #删除原有Contents字段内容
}
}
output {
stdout {
codec => rubydebug
}
}
root@devops010015001075:/opt# kubectl apply -f logstash-config.yml
再次查看logstash 的输出日志
root@devops010015001075:/opt# kubectl logs -f logstash-65bb74d7c5-pvzbd
....
{
"image_name" => "xxxxxxxx",
"message" => "[2022-07-19 11:02:00,083] INFO com.xxxx(MediaCheckJob.java:95)[===SYSTEM===]:xxx",
"container_ip" => "10.42.1.16",
"Time" => 1658199723,
"namespace" => "xcws",
"@version" => "1",
"container_name" => "xxxxx",
"pod_name" => "xxxxxx",
"source" => "stdout",
"@timestamp" => 2022-07-19T03:02:05.365Z
}
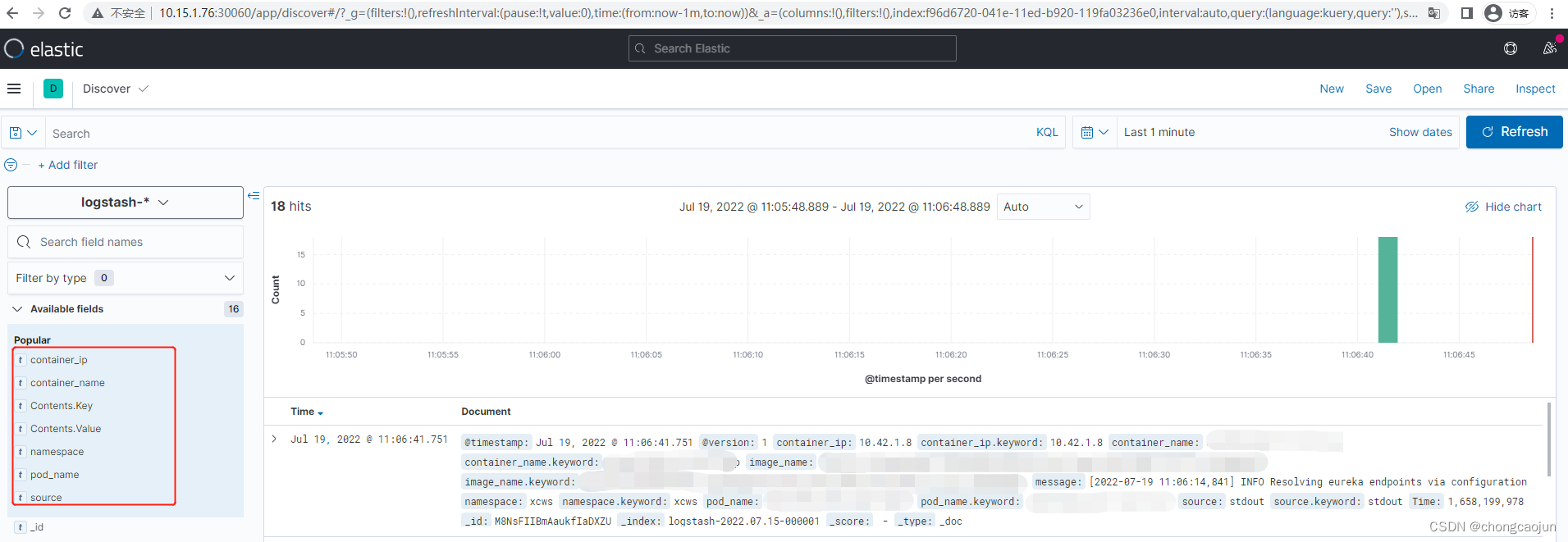
通过上述内容我们发现,之前的Contents字段内容已经被删除了,并且新增了我们定义的多个字段,此时修改logstash的输出到elasticsearch,在kibana上验证数据输出。可以看出字段已经被完全的分离开,并且按照我们预想的进行了输出。

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









