







 超级会员免费看
超级会员免费看
摘要重点:本文提出了一种基于Bootstrapping Multi-view representation (bootstrap多视图表示,BMR)的假新闻检测方法。给定一个多模态新闻输入,分别从文本、图像模式和图像语义的角度提取表示。提出了一种改进的多门混合专家网络(Improved Multi-gate Mixture-of-Expert networks, iMMoE)进行特征微调和融合。分别利用每个模态的表示来粗预测整个新闻的真实度,利用多模态表示来预测跨模态的一致性(预测分数)。根据预测分数,来重新权衡表示的每个视图,并引导它们进行假新闻检测。
1 介绍
1.1 研究背景
许多现有的多模态FND(假新闻检测)方案使用文本和视觉特征作为集成表示。然而,从不同的观点对特征的解纠缠还没有得到彻底的研究。在许多情况下,模型处于黑盒级别,其中网络设计不能明确地突出最有贡献的组件此外,最近的许多研究仅依靠跨模态相关来生成融合特征,但作者认为跨模态相关性不一定起关键作用。因此,明确单模态和跨模态特征的作用对于改善FND至关重要。
针对这些问题,作者提出了一种基于bootstrap多视图表示(bootstrap Multi-view representation, BMR)的假新闻检测方案。对于一篇多模态新闻,我们分别从文本、图像模式和图像语义的角度提取新闻的表示。提出了改进的多门混合专家网络(MMoE) ,表示为iMMoE,用于特征微调和融合。每个视图的表示分别用于粗略预测整个新闻的保真度,其中预测分数用于自适应特征重加权。跨模态一致性学习进一步隐含地指导了多模态表示的改进,通过引入一个独立的表示来明确地从其他跨模态信息中分离出相关性。最后,引导了多视图特征来改进假新闻检测。在图1所示的示例中,BMR不仅预测了新闻的保真度,而且基于每个视图给出了置信度分数,这提供了一种新的方法了解不同角色在多模态FND中的作用。
1.2 本文贡献
- 提出了一种新的假新闻检测方案,该方案生成多视图表示,理解它们各自的重要性,并优化融合的特征。
- 建议通过单视图预测和跨模态一致性学习来解开单模态和多模态特征中的信息,然后自适应地重新加权和自引导以更好地检测。
- 提出的BMR检测不仅在流行数据集上优于最先进的多模态FND方案,而且还提供了一种解释不同表示的贡献的机制。
2 相关工作
多模态假新闻检测的关键问题是对齐语言和视觉表示。
- SpotFake (Singhal et al. 2020)集成了预训练的XLNet和ResNet用于特征提取。
- SAFE (Zhou, Wu, and Zafarani 2020)将新闻文本和视觉信息之间的相关性输入到分类器中以检测假新闻。EANN (Wang et al. 2018b)引入了一个额外的判别器来对新闻事件进行分类,从而抑制特定事件对分类的影响。
- MCAN (Wu et al. 2021)堆叠多个共同注意力层以进行多模态特征融合。
- MCNN (Xue et al. 2021)还融合了文本语义特征、视觉篡改特征以及文本和视觉信息的相似性,用于假新闻检测,但聚合过程只是将所有特征连接起来。因此,无法测量这些多视图特征如何影响预测。基于单视图分类显式地重新权衡多视图表示,并自适应地引导它们用于假新闻检测。
此外,一些方法提出使用跨模态关联学习进行假新闻检测。
- CAFE (Chen et al. 2022)使用VAE压缩图像和文本表示,并根据其Kullback-Leibler (KL)散度衡量跨模态一致性。在最终分类之前,一致性得分线性调整单模态和多模态特征的权重。
- CMC (Wei et al. 2022)包含一个两阶段的网络,该网络通过对比学习训练两个单模态网络来学习跨模态相关性,然后微调网络以进行假新闻检测。然而,当一致性很高时,CAFE会严厉惩罚单峰特征,这在某些新闻中可能是可疑的。CMC不会自适应地抑制或增强多视图表示,微调阶段可能会擦除第一阶段学习到的跨模态知识。
因此,我们提出了一种改进的机制来更好地利用跨模态一致性学习进行FND。
3 方法
图2描述了所提出的Bootstrapping多视图表示方法的流程,其中包含四个阶段,即多视图特征提取、微调和融合、解缠和重加权以及Bootstrapping。在前3个阶段中,有4个分支分别对应4个视图的表示,包括图像模式分支、图像语义分支、文本分支和融合分支。
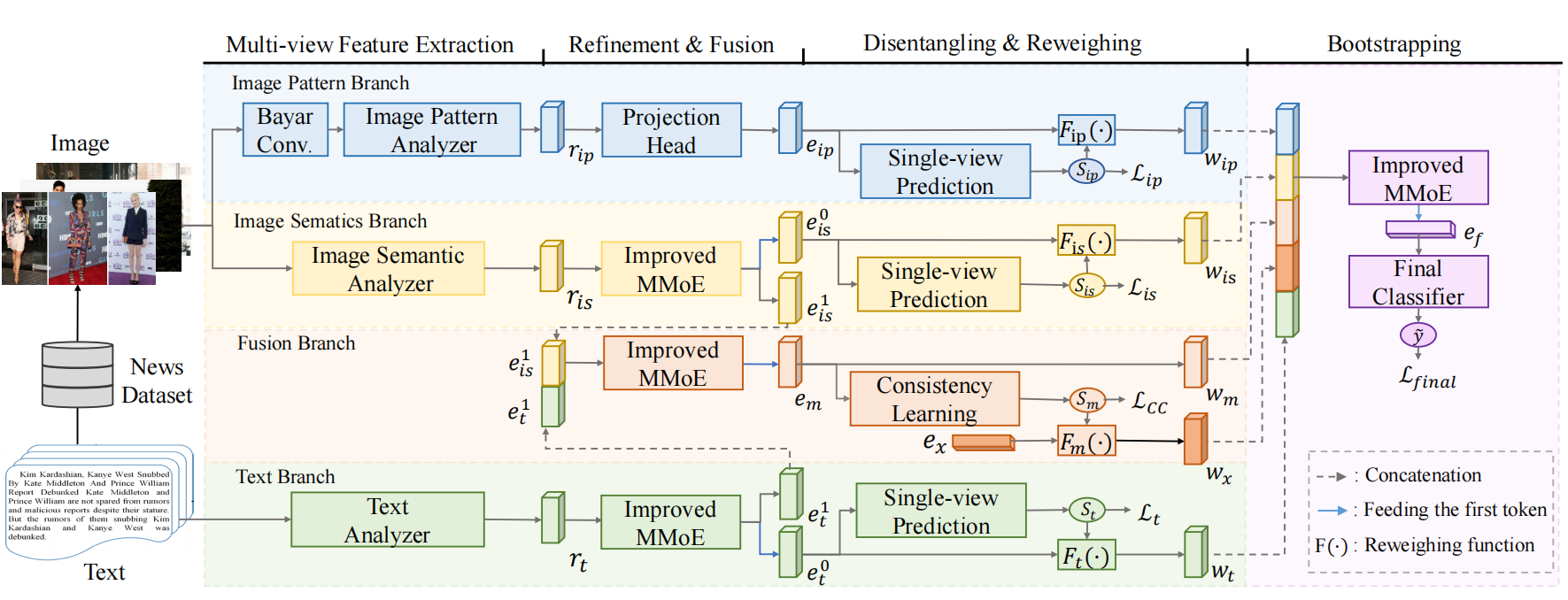
3.1 多视图特征提取
设输入的多模态新闻为
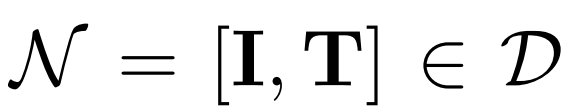
,其中I, T, D分别是图像,文本和数据集。
首先提取粗略的多视图表示,包括图像模式、图像语义和文本,分别对应于图像模式分支、图像语义分支和文本分支;我们将这些表示表示为rip、ris和rt。
作者认为,图像的总体分布和篡改或压缩留下的微小痕迹,有助于揭露假新闻。本文明确地将特征学习范式与图像模式和语义分开。
在图像模式分支中,使用InceptionNetV3 (Szegedy et al. 2016)作为图像模式分析器。我们还包括一个BayarConv (Bayar和Stamm 2018),在将I发送到InceptionNetV3网络之前处理它,因为BayarConv增强了细节并抑制了I的主要组件,这些组件对语义有很大贡献。
虽然CNN适用于视觉学习,但据报道,基于掩码语言/图像建模的transformer模型(He et al. 2022)在建立长程注意力方面效果很好。因此,在图像语义分支中,使用掩码自编码器(MAE)作为图像语义分析器来提取ris。
在文本分支中,我们使用BERT (Devlin等人。2018b)来提取rt。
3.2 基于iMMoE的特征微调与融合
3.2.1 基本过程
在微调和融合阶段,微调从第一阶段提取的表示。
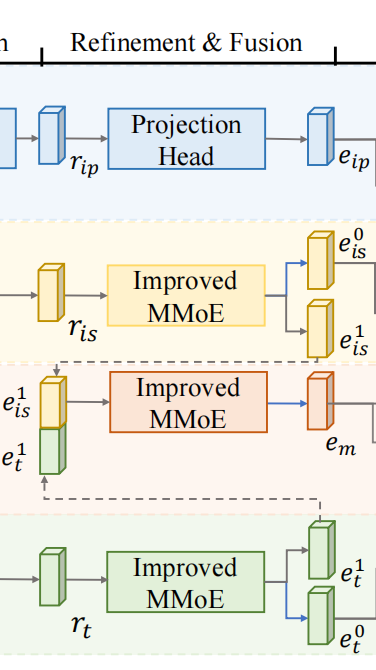
在图像模式分支中rip被投影到新的表示eip,其中InceptionNet-V3的分类头被替换为基于MLP的投影头。eip的输出大小等于MAE的单个标记表示的大小。
在图像语义分支和文本分支中,我们提出了改进的MMoE (iMMoE)网络来微调ris和rt,相应的,得到新的表示eis、et。
同时,在融合分支中,将eis和et融合成了新的表示em。
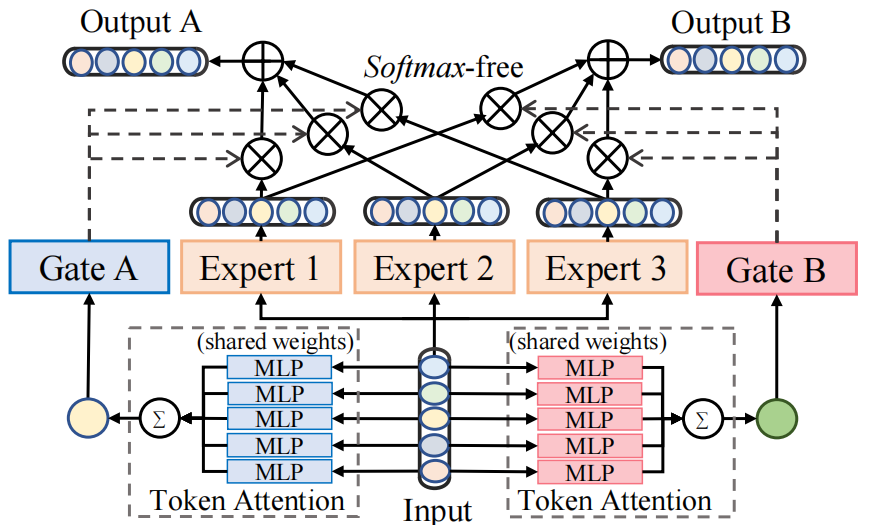
3.2.2 iMMoE
如图3所示,所提出的iMMoE包含几个专家意见、门和token注意力,在不同的分支中产生特征。MMoE网络(Ma et al. 2018)最初旨在通过在所有任务中共享专家来对数据中的多任务关系进行建模。输入x平均送入n个专家网络,k个门使用softmax函数自适应地权衡专家的输出作为最终输出。N是一个超参数,k是下游任务的数量。
MMoE算法总结在Eq.(1)中。
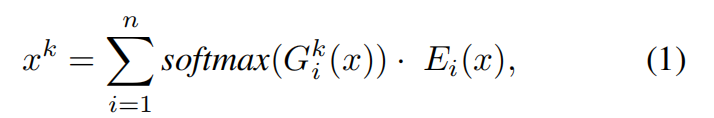
其中其中Ei是第i个专家意见,
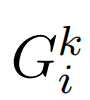
是任务k的第i个门的输出。
在BMR中,将多视图单模态表示挖掘和跨模态特征融合视为不同的子任务。它们既要有共同的特点,又要保留各自的特点。我们从两个方面对MMoE网络进行了改进。
首先,使用标记注意力来使用MLP计算每个标记表示的重要性分数,并根据分数将所有标记表示聚合为一个来执行降维。然后将汇总的表示送入gate,计算每个专家的权重。其次,门中的softmax函数被用来保证输出权重都是正的,并且总和等于1。根据我们的实验,这是不必要的。因此,我们取消了softmax约束,并允许权重在[0,1]范围之外。综上所述,我们将Eq.(1)修改为iMMoE的Eq. (2)
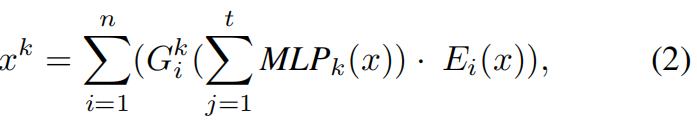
其中t是token的数量,MLPk表示任务k的token注意力。k∈[1,2]。
在iMMoE网络中,将ris和rt分别细化为特征
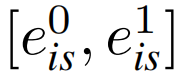
和
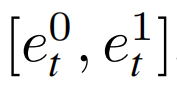
。
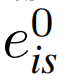
和
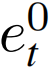
被保留用于单视图预测。同时,将
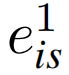
和
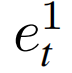
联合送入融合分支的iMMoE网络中生成多模态特征em,并保留该特征em用于跨模态一致性学习和bootstrapping。
3.3 解缠和重加权
经过微调和融合,从4个分支得到新的表示。然后,通过单视图预测处理图像模式、图像语义和文本的表示,同时在融合分支中处理融合表示以进行一致性学习;
3.3.1 单视角预测与重估
单视图预测使用
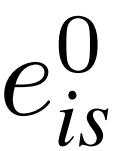
的第一个token,
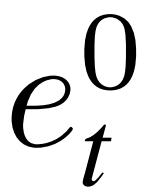
的第一个token和
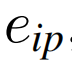
,来预测多模态新闻

的保真度。 设计这个模块基于两个考虑。
- 许多假新闻独立存在明显的图像噪声异常、分布异常或文本异常;因此,对具有单视图特征的
进行预测在经验上是可行的,这允许网络深度挖掘每个视图的特征。
- 预测分数可以投影到权重中,自适应地重新权衡表示。因此,我们使用MLP将每个单视图表示投影到分数中,并使用另一个MLP,即图2中的F(·)将分数投影到权重中。以
和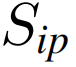
的生成为例,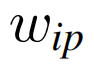
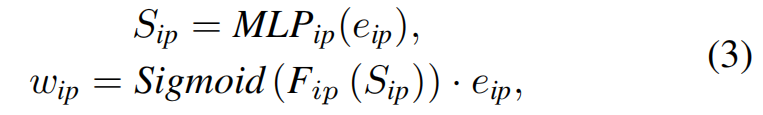
其中MLPip(·)表示基于mlp的单视图预测器。以同样的方式,生成了成对的预测分数,并重新加权表示{Sis, wis}、{Sm, wm}和{St, wt}。然后,重新加权的表示形式就可以进行引导了。
3.3.2 跨模态一致性学习
与近期的一些工作类似,本文用跨模态一致性学习来指导融合分支中的多模态特征融合。训练BMR来预测给定的文本-图像对是否匹配。
- 在数据集
的基础上构建一个新的数据集D' = [Dreal, Dsyn],其中具有相关文本和图像的新闻标记为y' = 1,否则标记为y'= 0。
图4展示了跨模态一致性学习的三个训练数据,其中正例直接是从D中借用的真实新闻,负例是通过任意组合来自不同真实新闻的图像和文本合成“新闻”。尽管在现实中可能存在一些新闻不包含跨模态一致性的情况,但Dsyn的文本图像对具有一致性的可能性实际上要低得多。因此,模型仍然可以基于这样的混合数据集学习相关性。

- 将新数据集中的多模态新闻输入到BMR中,(
)。在计算出相应的em后,使用基于MLP的预测器输出一致性分数Sm,并期望分数接近标签y'。使用简单的回归损失作为监督,而不是CMC中应用的对比损失(Wei et al. 2022),因为来自负池的任何文本与查询图像匹配的可能性,即假阴性率,与池的大小成正比。跨模态一致性学习的训练过程只激活BMR中的一部分模块。该任务可以与主任务并行学习。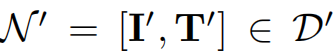
3.3.3 多模态表示的重新加权
预测的一致性分数也会调整多模态表示。
作者认为多模态特征不应仅仅代表跨模态相关性。还有许多其他因素,如联合分布、情感差异等。这可以帮助决定这个消息是否假。因此,我们不要用Sm来加权。相反,我们通过让Sm重新权衡一个独立的可移动的token ex,从而明确地从其他跨模态信息中分离出来,这代表了跨模式的不相关性。wx
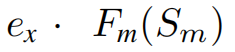
和
![]()
,都被认为是bootstrapping的多模态表示。
与以前的工作相比,我们没有将跨模态学习与检测阶段分开,用相关性分数(Chen et al)重加权单模态和多模态表示。
3.4 Bootstrapping阶段和损失函数
多视图表示[wis, wip, wm, wx, wt]是使用另一个iMMoE进行引导的,它进一步完善了对决策至关重要的信息。最终的基于mlp的分类器得到输出ef的第一个标记来预测
,它预计接近标签y。
假新闻检测是一个二分类问题。二元交叉熵损失(BCE)在等式(4)中定义,其中x和
![]()
分别代表基本事实和预测。
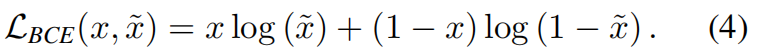
我们在全局真实标签y和预测的分数
,以及粗分类结果Sip, Sis, st之间应用BCE损失。跨模态一致性训练有一个额外的损失,我们还在地面真实制作的标签y 0和Sm之间应用BCE损失。因此,该损失被定义为
![]()
,


。单视图FND分类损失是Lis、Lip和Lt的总和,即

BMR的总损失定义如下:
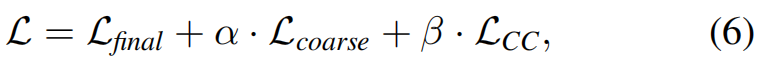
其中超参数α和β根据经验设置为α = 1, β = 4。
Algo.1给出了算法BMR详细训练过程的伪代码。

4 实验
4.1 实验设置
- 对于中文数据集,我们使用" mae-pretrain-vitbase "模型,对于英文数据集,我们使用" bert-base-chinese "模型
- MAE和BERT的隐藏大小都是768。
- BMR中的所有mlp都包含一个隐藏层、一个BatchNorm1D和一个ELU激活。
- 使用ViT中定义的单层transformer块来实现iMMoE中的专家模块。每个iMMoE网络拥有三名专家。
- 我们使用带有默认参数的Adam优化器。批量大小为24,学习率为1 × 10−4,采用余弦退火衰减。
- 图片大小调整为224×224,文本的最大长度设置为197。通过提供零矩阵作为图像或“无文本提供”作为文本,BMR还被设计为与单模态新闻兼容。
- 与EANN 类似,我们通过替换小于64 × 64的图像和小于5个单词的文本来提高数据集的质量。
- 数据集:使用Weibo(Jin et al. 2017)、GossipCop(Shu et al. 2020a)和Weibo-21 (Nan et al. 2021)进行训练和测试。微博包含3749条真实新闻和3783条假新闻用于训练,1000条假新闻和996条真实新闻用于测试。GossipCop包含7974条真实新闻和2036条用于训练的假新闻,2285条真实新闻和545条用于测试的假新闻。Weibo-21是一个新发布的数据集,共包含4640条真实新闻和4487条假新闻,我们将其按9:1的比例分为训练数据和测试数据。尽管MediaEval (Boididou et al. 2018)和Politifact (Singhal et al. 2020)也是很受欢迎的数据集,但它们在训练集中只包含460张图像和381篇文章。因此,使用Politifact训练的神经网络很容易在如此小的数据量上过拟合。我们在每个数据集上用不同的初始权重训练BMR 5次,并报告了平均最佳性能。
- 根据(He和Garcia 2009)中的理论,我们根据每个数据集的分布确定一个固定的阈值。由于gossipcop训练集中真实新闻与假新闻的比例接近4:1,我们将gossipcop的阈值设置为0.80。同样,微博和Weibo-21的阈值设置为0.50。对于实际应用,我们可以将默认阈值设置为0.50。
实验结果及总结 略


















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











