







 超级会员免费看
超级会员免费看
KDD 2018
Yaqing Wang1 , Fenglong Ma1 , Zhiwei Jin2 , Ye Yuan3,Guangxu Xun1 , Kishlay Jha1 , Lu Su1 , Jing Gao1
1:纽约州立大学布法罗分校计算机科学系
2:中国科学院计算技术研究所,中国科学院北京
3:北京工业大学信息与通信工程学院
摘要重点:社交媒体上的假新闻检测面临的独特挑战之一是如何识别新出现的事件中的假新闻。不幸的是,大多数现有的方法很难处理这一挑战,因为它们倾向于学习事件特定的特征,而这些特征不能转移到看不见的事件中。为了解决这个问题,我们提出了一个端到端的框架,称为事件对抗神经网络(EANN),它可以导出事件不变特征,从而有利于在新到达的事件上检测假新闻。它由三个主要部分组成:多模态特征提取器、假新闻检测器和事件鉴别器。多模态特征提取器负责从文章中提取文本和视觉特征。它与假新闻检测器合作学习可判别表示,用于假新闻的检测。事件鉴别器的作用是去除特定于事件的特征,并在事件之间保持共享特征。
1 介绍
现有的深度学习模型在不同事件的验证文章数量充足的情况下,凭借其优越的特征提取能力,取得了比传统模型更好的性能提升。然而,它们仍然无法应对假新闻检测的独特挑战,即在新出现的、时间关键事件上检测假新闻[27]。由于缺乏相应的先验知识,此类事件的验证帖子难以及时获取,导致现有模型的性能不理想。实际上,现有的模型往往会捕获大量特定于事件的特征,而这些特征在不同事件之间并不共享。此类特定于事件的特征虽然能够帮助对已验证事件的帖子进行分类,但会影响对新出现事件的检测。因此,本文认为学习所有事件之间的共享特征,而不是捕获特定于事件的特征,将有助于我们从未经验证的帖子中检测假新闻。本文工作的目标是设计一个有效的模型来去除不可迁移的事件特定特征,并保留所有事件之间的共享特征,以完成假新闻的识别任务。
要删除特定于事件的特性,第一步是识别它们。对于不同事件上的帖子,它们有自己独特或特定的功能,不能共享。这些特征可以通过度量不同事件对应的帖子之间的差异来检测。在这里,帖子可以用学习到的特征来表示。因此,识别特定于事件的特征等价于测量在不同事件上学习到的特征之间的差异。然而,这是一个具有技术挑战性的问题。首先,由于文章学习到的特征表示是高维的,平方误差等简单的度量可能无法估计这些复杂特征表示之间的差异。其次,特征表示在训练阶段不断变化。这就要求提出的度量机制能够捕捉特征表示的变化,并始终提供准确的度量。尽管这非常具有挑战性,但有效估计学习到的特征在不同事件上的差异性是移除特定事件特征的前提。因此,如何在这种情况下有效地估计不相似性是我们必须解决的挑战。
为了应对上述挑战,本文提出了一种基于多模态特征的事件对抗神经网络(Event Adversarial Neural Networks, EANN)端到端的假新闻检测框架。受对抗网络[10]思想的启发,在训练阶段加入事件判别器来预测事件辅助标签,并利用相应的损失来估计不同事件之间特征表示的差异性。损失越大,差异越小。由于假新闻利用多媒体内容误导读者进行传播,因此我们的模型需要处理多模态输入。
提出的EANN模型由三个主要部分组成:多模态特征提取器、假新闻检测器和事件判别器。多模态特征提取器与假新闻检测器协同完成识别假新闻的主要任务。
本文贡献:
- 我们首次提出了针对新事件和时间关键事件的假新闻检测,可以基于多模态特征识别假新闻,并通过移除特定事件的特征来学习可迁移的特征。为此,提出一种端到端的事件对抗神经网络。
- 提出的EANN模型使用事件判别器来衡量不同事件之间的差异性,并进一步学习对新出现事件具有良好泛化能力的事件不变特征。
- 提出的EANN模型是假新闻检测的通用框架。集成的多模态特征提取器可以很容易地被不同的特征提取模型所替代。
- 实验表明,所提出的EANN模型可以有效识别假新闻,并在两个大规模真实世界数据集上优于最先进的多模态假新闻检测模型。
2 相关工作
假新闻:故意编造并可被证实为虚假的新闻
主要挑战:如何根据特征来区分新闻。
2.1 假新闻检测
2.1.1 单模态假新闻检测
- 文本特征
文本特征是从帖子的文本内容中提取的统计或语义特征,这在许多假新闻检测的文献中已经进行了探讨[4,11,19,27]。不幸的是,语言模式还没有被很好地理解,因为它们高度依赖于特定的事件和相应的领域知识[25]。因此,很难为传统的基于机器学习的假新闻检测模型设计手工制作的文本特征。为了克服这一限制,Ma等人[21]提出了一种深度学习模型来识别假新闻。具体来说,它部署了递归神经网络来学习时间序列中帖子的表示作为文本特征。实验结果表明了基于深度学习的模型的有效性。
- 视觉特征
视觉特征已被证明是假新闻检测的重要指标[15,27]。然而,关于验证社交媒体上多媒体内容可信度的研究非常有限。文章[12,15,24,31]探讨了帖子中所附图片的基本特征。然而,这些特征仍然是手工制作的,很难表示视觉内容的复杂分布。
- 社交语境特征
社会语境特征代表了社交媒体上新闻的用户参与[27],如关注者数量、标签(#)和转发数量。在[31]中,作者的目标是捕获传播模式,如消息传播的图结构。然而,社会背景特征是非常嘈杂、非结构化和劳动密集型的。特别是,它不能为新出现的事件提供足够的信息。
2.1.2 多模态假新闻检测
为了从多个方面学习特征表示,深度神经网络已经成功地应用于各种任务,包括但不限于视觉问答[2]、图像字幕[17,30]和假新闻检测[13]。在[13]中,作者提出了一种基于深度学习的假新闻检测模型,该模型提取多模态和社会语境特征,并通过注意机制进行融合。然而,多模态特征表示仍然高度依赖于数据集中的特定事件,并且不能很好地泛化以识别新的即将发生的事件的假新闻。为了克服现有工作的局限性,我们提出了一种新的深度学习模型,该模型显著提高了对不同事件的假新闻检测性能。该模型不仅可以自动学习多模态特征表示,还可以使用对抗网络生成事件不变的特征表示。
[13]Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multimodal Fusion with Recurrent Neural Networks for Rumor Detection on Microblogs.
2.2 对抗网络
本文受到了对抗性网络思想的启发[10]。现有的对抗网络通常使用极小极大博弈框架来生成与观测样本匹配的图像。对抗性学习框架已被用于多项任务,如半监督学习的学习表征[23]、睡眠阶段预测[32]、判别图像特征[20]和领域自适应[8,9]。该模型还建立了事件鉴别器与多模态特征提取器之间的极大极小博弈。特别是,多模态特征提取器被强制学习事件不变表示来欺骗鉴别器。通过这种方式,它消除了对收集数据集中特定事件的紧密依赖,并对未见过的事件实现了更好的泛化能力。
3 方法
3.1模型概述
EANN模型集成了三个主要组件:多模态特征提取器、假新闻检测器和事件鉴别器。
首先,由于社交媒体上的帖子通常包含不同模态的信息(例如文本帖子和附件图像),因此多模态特征提取器包括文本特征提取器和视觉特征提取器,以处理不同类型的输入。在学习到文本和视觉潜在特征表征后,将它们连接在一起形成最终的多模态特征表征。假新闻检测器和事件鉴别器都是建立在多模态特征提取器的基础上的。假新闻检测器将学习到的特征表示作为输入来预测帖子的真假。事件鉴别器根据这个潜在表示标识每个帖子的事件标签。
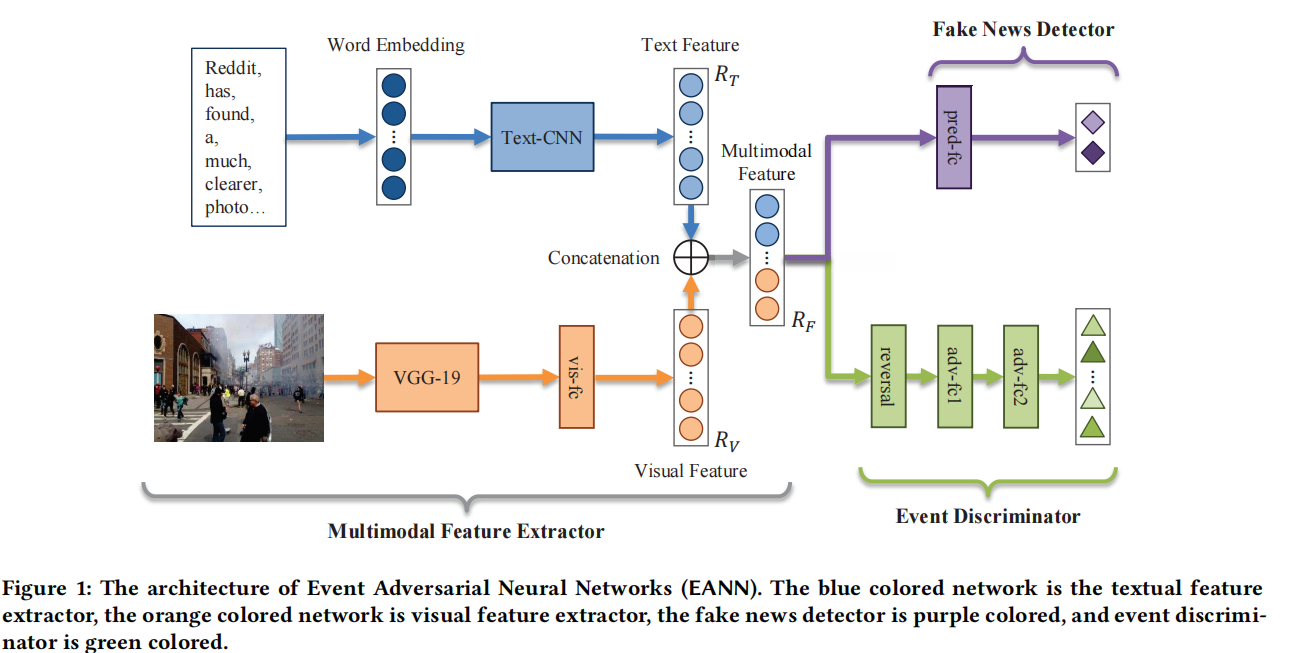
3.2 多模态特征提取器
3.2.1 文本特征提取器
为了从文本内容中提取信息丰富的特征,采用卷积神经网络(CNN)作为文本特征提取器的核心模块。如图1所示,我们在文本特征提取器中加入了一个改进的CNN模型Text-CNN[18]。
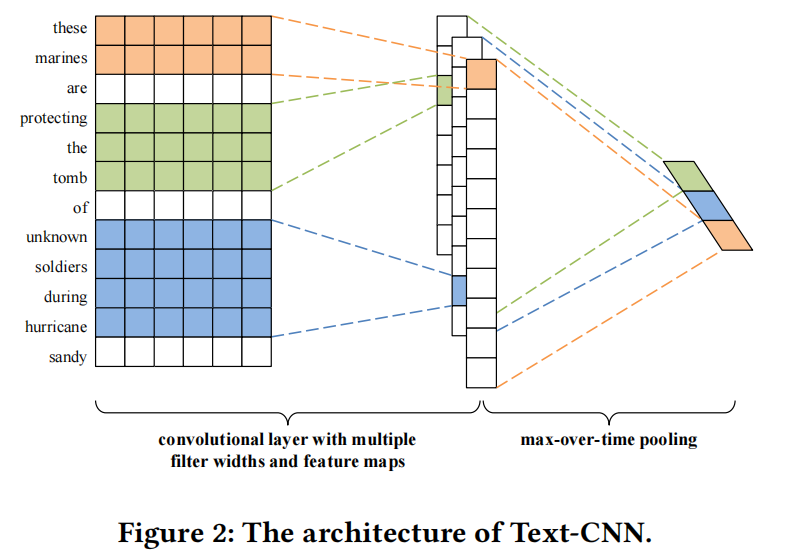
对于文本特征提取的详细过程,将文本中的每个单词表示为一个词嵌入向量。每个词的嵌入向量使用给定数据集上预训练的词嵌入进行初始化。对于句子中的第i个词,对应的k维词嵌入向量记为Ti∈R k。因此,一个包含n个单词的句子可以表示为:
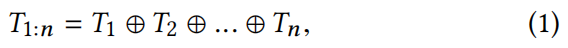
其中⊕是拼接运算符。窗口大小为h的卷积滤波器将句子中h个单词的连续序列作为输入,并输出一个特征。为了清晰地展示这个过程,我们以从第i个单词开始的连续的h个单词序列为例,过滤操作可以表示为:
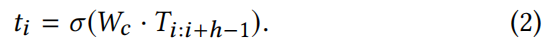
其中σ(·)是ReLU激活函数,Wc表示滤波器的权重。该过滤器也可以应用于其他单词,然后我们得到这个句子的特征向量:
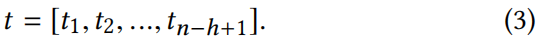
对于每个特征向量,使用最大池化操作取最大值,以提取最重要的信息。重复这个过程,直到得到所有过滤器的特征。为了提取不同粒度的文本特征,采用了不同的窗口大小。对于特定的窗口大小,我们有nh个不同的过滤器。因此,假设有c种可能的窗口大小,我们总共有c·nh个滤波器。最大池化操作后的文本特征记为
RTc∈R c·nh。在最大池化操作之后,使用一个全连接层,通过以下操作,确保最终的文本特征表示(记为RT∈Rp)与视觉特征表示具有相同的维度(记为p):

其中Wt f为全连接层的权值矩阵
3.2.2 视觉特征提取器
视觉特征提取器的输入,记为V。为了高效地提取视觉特征,采用了预训练的VGG19[28]。在VGG19神经网络的最后一层的基础上增加一个全连接层,将最终视觉特征表示的维度调整为p。在与文本特征提取器联合训练的过程中,预训练的VGG19神经网络的参数保持不变,以避免过拟合。表示p维视觉特征表示为RV∈rp,则视觉特征提取器中最后一层的操作可以表示为:
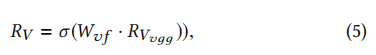
其中RVvgg是由预训练的VGG19得到的视觉特征表示,Wvf是视觉特征提取器中全连接层的权重矩阵。
将文本特征表示RT和视觉特征表示RV串联起来形成多模态特征表示RF = RT⊕RV∈R 2p,这是多模态特征提取器的输出。我们将多模态特征提取器表示为Gf (M;θf)其中M通常是一组文本和视觉帖子,是多模态特征提取器的输入,θf表示要学习的参数。
3.3 假新闻检测器
在本节中,我们将介绍假新闻检测器。它使用softmax部署一个全连接层来预测帖子是假的还是真的。在多模态特征提取器的基础上构建假新闻检测器,将多模态特征表示RF作为输入。我们将假新闻检测器表示为Gd(·;θd),其中θd表示包括的所有参数。对于第i篇多媒体文章,假新闻检测器的输出记为mi,是这篇文章是假文章的概率:
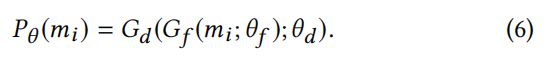
假新闻检测器的目标是识别特定帖子是否为假新闻。我们用Yd表示标签集合,用交叉熵计算检测损失:
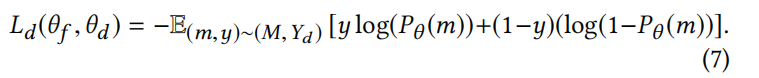
我们通过寻找最优参数θˆf和θˆd来最小化检测损失函数Ld (θf, θd),这个过程可以表示为:
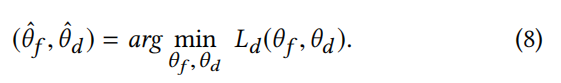
如前所述,假新闻检测的主要挑战之一来自训练数据集未覆盖的事件。这要求我们能够学习新出现事件的可迁移特征表示。直接最小化检测损失只有助于检测训练数据集中包含的事件上的假新闻,因为这只捕获了特定事件的知识(例如,关键字)或模式,不能很好地泛化。因此,我们需要使模型能够学习更通用的特征表示,以捕获所有事件之间的共同特征。这种表示应该是事件不变的,并且不包含任何特定于事件的特性。为了实现这个目标,我们需要删除每个事件的唯一性。衡量不同事件之间特征表示的差异性并删除它们,以捕获事件不变的特征表示。
3.4 事件鉴别器
事件判别器是由两个全连接层和相应的激活函数组成的神经网络。它旨在基于多模态特征表示将文章正确分类为K个事件之一。将事件判别器表示为Ge (RF;θe)θe表示其参数。我们通过交叉熵定义事件判别器的损失,并用Ye表示事件标签的集合:
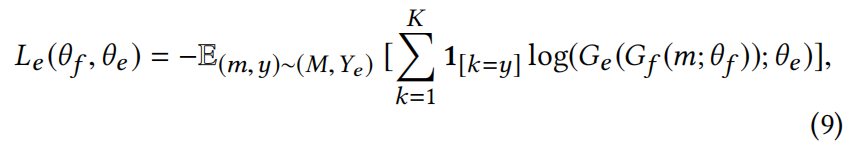
最小化损失Le(·,·)的事件判别器参数为:
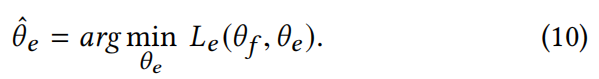
上述损失Le (θf, θˆe)可用于估计不同事件分布的差异性。较大的损失意味着不同事件表示的分布是相似的,学习到的特征是事件不变的。因此,为了消除每个事件的唯一性,我们需要通过寻找最佳参数θf来最大化区分损失Le (θf, θˆe)。
上述想法激发了多模态特征提取器和事件判别器之间的极小极大博弈。一方面,多模态特征提取器试图欺骗事件鉴别器以最大化鉴别损失,另一方面,事件鉴别器旨在发现特征表示中包含的特定于事件的信息来识别事件。下一节将介绍三个部分的集成过程和最终的目标函数。
3.5 模型集成
在训练阶段,多模态特征提取器Gf(·;θf)需要与假新闻检测器Gd(·;θd)最小化检测损失Ld (θf, θd),从而提高假新闻检测任务的性能。同时,多模态特征提取器Gf(·;θf)试图欺骗事件鉴别器Ge(·;θˆe)通过最大化事件区分损失Le (θf, θe)来实现事件不变表示。事件鉴别器Ge (RF;θe)试图通过最小化事件区分损失来基于多模态特征表示识别每个事件。我们可以将这个三者关系的最终损失定义为:
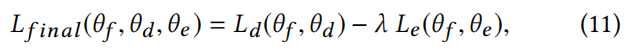
其中λ控制假新闻检测和事件判别目标函数之间的权衡。在本文中,我们简单地将λ设置为1,而没有调整权衡参数。对于极大极小博弈,我们寻找的参数集是最终目标函数的鞍点:
4 数据集
4.1 Twitter
Twitter数据集来自MediaEval Verifying Multimedia Use benchmark[3],用于检测Twitter上的虚假内容。该数据集由两部分组成:开发集和测试集。将开发集作为训练集,测试集作为测试集,保持相同的数据分割方案。Twitter数据集中的推文包含文本内容、附加的图像/视频和额外的社会上下文信息。本文专注于通过结合文本和图像信息来检测假新闻。因此,我们删除没有任何文本或图像的推文。对于这两个集合,它们之间不存在重叠事件。在Twitter数据集上进行模型训练时,采用提前停止策略。
4.2 Weibo
在[13]中使用微博数据集进行假新闻检测。该数据集的真实新闻来自中国的权威新闻来源,如新华社。
具体来说,我们在微博官方辟谣系统上抓取了2012年5月至2016年1月期间所有经过验证的虚假谣言文章。在删除纯文本推文后,原始集包含大约40k条带图像的推文。该系统鼓励普通用户举报微博上的可疑推文。然后由声誉良好的用户组成的委员会将审查这些案例,并核实它们是假的还是真的。该系统实际上是文献[21,31]中收集谣言推文的权威来源。对于非谣言推文,我们使用经过中国权威通讯社新华社验证的推文。工作13中还提出了一种基于局部敏感哈希(LSH)的近似重复图像检测算法[28],用于去除原始图像集中的重复图像。我们还会删除非常小或很长的图像,以保持良好的质量。
在预处理此数据集时,我们遵循工作[13]中的相同步骤。首先删除重复的和低质量的图像,以确保整个数据集的质量。然后,采用一种single-pass聚类方法[14]从帖子中发现新出现的事件。最后,我们将整个数据集按7:1:2的比例划分为训练集、验证集和测试集,并确保它们不包含任何公共事件。这两个数据集的详细统计数据见表1。
[13]Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multimodal Fusion with Recurrent Neural Networks for Rumor Detection on Microblogs. In Proceedings of the 2017 ACM on Multimedia Conference. ACM, 795–816.
5 实验
5.1 Baseline
5.1.1 单模态模型
- Text。我们使用来自所有帖子的文本内容的32维预训练单词嵌入权重来初始化嵌入层的参数。然后利用CNN提取每篇文章的文本特征RT;最后,使用一个附加的带有softmax函数的全连接层来预测这篇文章是否为假。我们使用20个滤波器,窗口大小从1到4不等,全连接层的隐藏大小为32。
- Vis。输入是一幅图像。使用预训练的VGG-19和全连接层来提取视觉特征RV。然后,将RV送入全连接层进行预测。我们设置全连接层的隐藏大小为32。
5.1.2 多模态模型
- VQA. 视觉问答(Visual Question answer, VQA)模型的目的是根据给定的图像来回答问题。原VQA模型是针对多类分类任务设计的。在假新闻检测工作中,重点是二分类任务,因此,在实现VQA模型时,将最终的多类层替换为二类层。此外,为了公平比较,还使用单层LSTM, LSTM的隐藏大小为32。
- NeuralTalk. NeuralTalk是一个为给定图像生成字幕的模型。通过对RNN在每个时间步长的输出进行平均,得到潜在表征,然后将这些表征送入全连接层进行预测。LSTM和全连接层的隐藏大小都是32。
- att- RNN. att- rnn是当前最先进的多模态假新闻检测模型。它利用注意机制融合文本、视觉和社会语境特征。在我们的实验中,我们去掉了处理社会语境信息的部分,但剩下的部分是一样的。参数设置与[13]相同。
- EANN-.EANN-是EANN的变体模型,即去除原EANN模型中的事件鉴别器,只保留多模态特征提取器和假新闻检测器,这也可以实现假新闻检测的功能。
5.2 实验设置
在文本特征提取器中,设置k = 32作为词嵌入的维数。设置过滤器nh = 20,在Text-CNN中过滤器的窗口大小从1到4不等。在文本和视觉提取器中,完全连接层的隐藏大小为32。对于假新闻检测器,全连接层的隐藏大小为64。事件鉴别器由两层完全连接组成:第一层隐藏大小为64,第二层隐藏大小为32。对于所有baseline模型和EANN,在训练阶段使用相同的100个实例的批处理大小,训练epoch为100。
5.3 实验结果
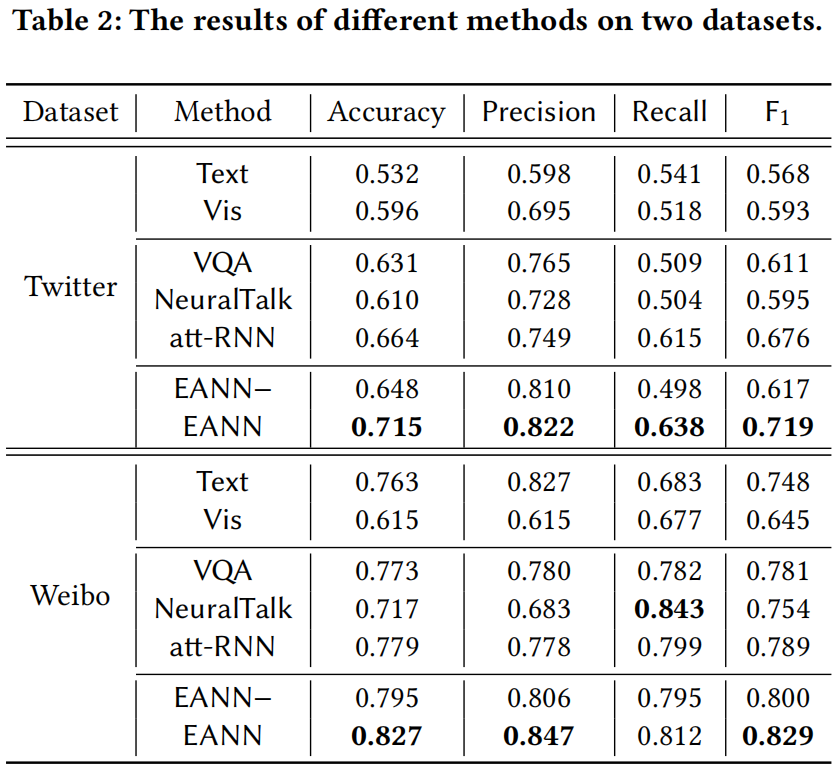
表2给出了在两个数据集上基线和建议方法的实验结果。
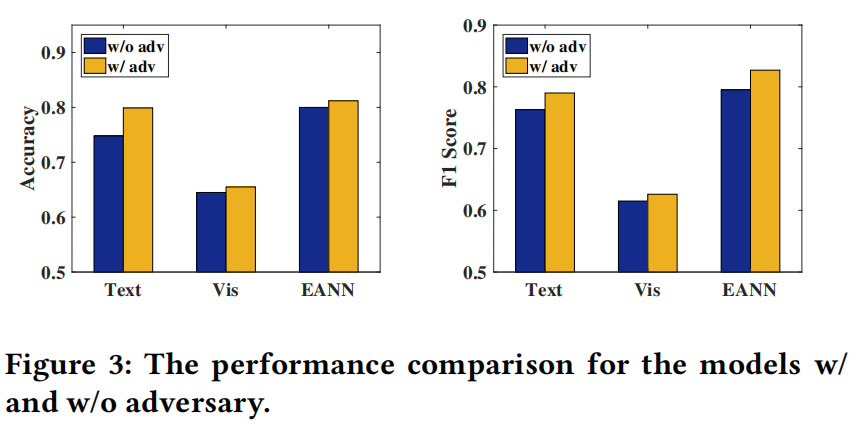
在图3中,“w/ adv”表示将事件鉴别器添加到相应的方法中,“w/o adv”表示原始方法。为简单起见,用Text+和Vis+表示相应的方法Text和Vis,分别添加了事件鉴别器组件。
5.4 实验分析
(1)结果分析
在Twitter数据集上,不同事件上的推文数量不平衡,超过70%的推文与单个事件相关。这使得学习到的文本特征主要集中在一些特定的事件上。与视觉模态相比,文本模态包含更明显的事件特定特征,严重阻碍了文本模型提取不同事件之间可转移的特征。因此,文本的准确率是所有方法中最低的。对于另一种单模态检测模型Vis,其性能远优于文本基线。图像特征具有更好的可迁移性,从而降低了不平衡信息的影响。借助VGG19提取有用特征的强大工具,可以捕捉到图像中包含的比文本模态更可分享的模式来判断新闻的真实性。虽然视觉模态对假新闻检测是有效的,但Vis的性能仍然低于多模态方法。这证实了融合多种模态对于假新闻检测任务的优越性。在多模态模型中,att-RNN的表现优于VQA和NeuralTalk,表明引入注意力机制有助于提高预测模型的性能。
对于所提出的模型EANN−的变体,它不包括事件判别器,因此倾向于捕获特定于事件的特征。这将导致无法学习到足够多的事件之间的共享特征,即泛化性较差。相比之下,在事件判别器的帮助下,完整的EANN在所有度量方面都显著提高了性能。这证明了事件判别器对性能改进的有效性。具体而言,EANN的准确率比最好的基线att-RNN提高了10.3%,F1值提高了16.5%。
在微博数据集上,可以观察到与Twitter数据集相似的结果。然而,对于单模态方法,观察到矛盾的结果。从表2可以看出,文本的性能远远高于Vis。原因是微博数据集不存在Twitter数据集那样的不平衡问题,具有足够的数据多样性,可以提取有用的语言模式用于假新闻检测。这导致在微博数据集上为文本模态学习一个可区分的表示。另一方面,微博数据集中的图像比Twitter数据集中的图像在语义上要复杂得多。对于这样具有挑战性的图像数据集,Vis无法学习有意义的表示,尽管它使用有效的视觉提取器VGG19来生成特征表示。
实验结果表明,所提模型的变体EANN-在微博数据集上的表现优于所有多模态方法。在对文本信息进行建模时,EANN使用了具有多个过滤器和不同单词窗口大小的卷积神经网络。由于每篇文章的长度相对较短(小于140个字符),CNN可以捕获更多的局部代表性特征。所提出的EANN在准确率、精度和F1值上优于所有方法。与EANN−相比,我们可以得出结论,使用事件判别器组件确实提高了假新闻检测的性能。
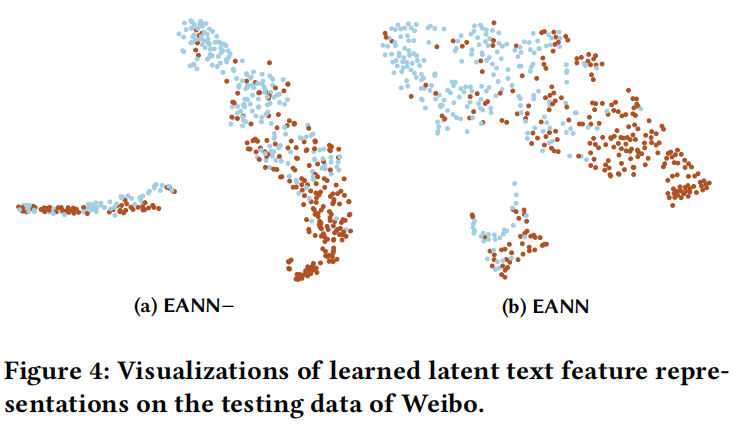
(2)事件鉴别性分析
为了进一步分析事件判别器的有效性,作者使用t-SNE在微博测试集上对EANN−和EANN学习到的文本特征RT进行了定性可视化,如图4所示。每个帖子的标签是真的还是假的。从图4可以观察到,对于EANN−方法,它可以学习可区分的特征,但学习到的特征仍然扭曲在一起,特别是对于图4a的左侧部分。相比之下,模型EANN学习到的特征表示更具判别性,不同标签的样本之间存在较大的分隔区域,如图4b所示。这是因为在训练阶段,事件鉴别器试图去除特征表示和特定事件之间的依赖关系。在极大极小博弈的帮助下,多模态特征提取器可以学习到不同事件的不变特征表示,并获得更强大的迁移能力,用于检测新事件上的假新闻。通过与EANN−方法的比较,证明了该方法可以利用事件判别器的成分学习到更好的特征表示,从而获得更好的性能。
t-SNE:Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research 9, Nov (2008), 2579–2605.
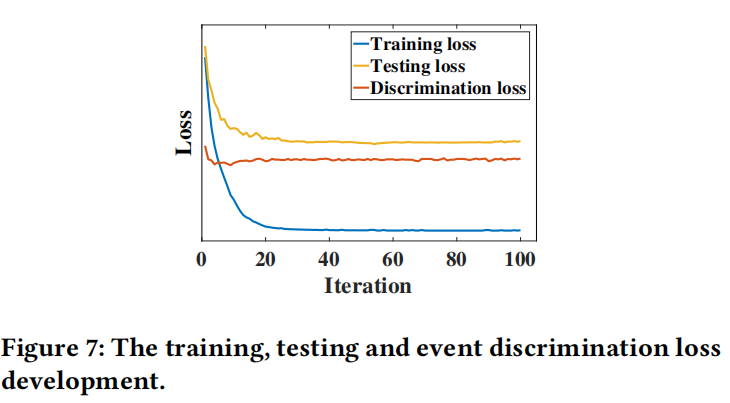
(3)收敛性分析
为了探索所提出的EANN模型的训练过程,训练、测试和区分损失(对抗性损失)的发展如图7所示。开始时,三种损失都减少了。鉴别损失增加并稳定在一定水平。开始时逐渐减少的判别损失表示事件判别器检测到多模态特征提取器的特征表示中包含的事件特定信息。随着鉴别器和特征提取器之间的极小极大博弈的继续,特征表示往往是事件不变的。因此,特定于事件的信息逐渐被删除,并且区分损失随着时间的推移而增加。在训练过程中,三个损失平滑收敛,这意味着达到了一定水平的均衡。随着训练损失稳步减少,可以观察到测试损失也稳步减少,并显示出非常相似的趋势模式。这一观察证明,所提出的EANN学习到的特征表示可以捕获所有事件中的一般信息,并且这种表示即使在新到来的事件上也具有区分性。
6 总结
本文研究了多模态假新闻检测问题。假新闻检测的主要挑战来自于如何更快速有效的检测新出现的事件,现有方法在这些新事件上的效果并不理想。为了解决这个问题,本文提出了一种新的事件对抗神经网络框架,可以为未见过的事件学习可迁移的特征。具体而言,该模型由3个主要组件组成,即多模态特征提取器、事件判别器和假新闻检测器。多模态提取器与假新闻检测器协同学习具有判别性的表示以识别假新闻,同时通过去除事件特有特征来学习事件不变表示。在两个从流行社交媒体平台上收集的大规模数据集上的大量实验表明,提出的模型是有效的,且性能优于当前最先进的模型。


















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











