







信息抽取
- 实体抽取
- 关系抽取
- 事件抽取
实体关系抽取方法:
- 早期的传统RE
- 基于传统机器学习的RE
- 基于深度学习的RE
- 基于开放领域的RE
关系抽取综述
一、任务:
- 命名实体识别(Name Entity Recognition)
- 触发词识别(Trigger Word Identification)
- 关系抽取系统
二、关系抽取特点
- 领域众多
- 数据来源广泛
- 关系种类繁多复杂,噪音数据无法避免
三、常用工具
- 英文关系抽取常用工具
-
- NLTK
- DeepDive
- Stanford CoreNLP
- 中文关系抽取常用工具
-
- 中文分词工具
- LTP-Cloud
四、评价体系
准确率
![]()
是对于给定的测试数据集, 分类器正确分类为正类的样本数与全部正类样本数 之比
召回率
![]()
对于给定的测试数据集,预测正确 的正类与所有正类数据的比值
F1值

是准确率和召回率的调和平均值,可以对系统的性能进行 综合性的评价
其中:
TP:原本是正,预测也正
FP:原本是负,预测为正
TN:原本是负,预测为负
FN:原本是正,预测为负
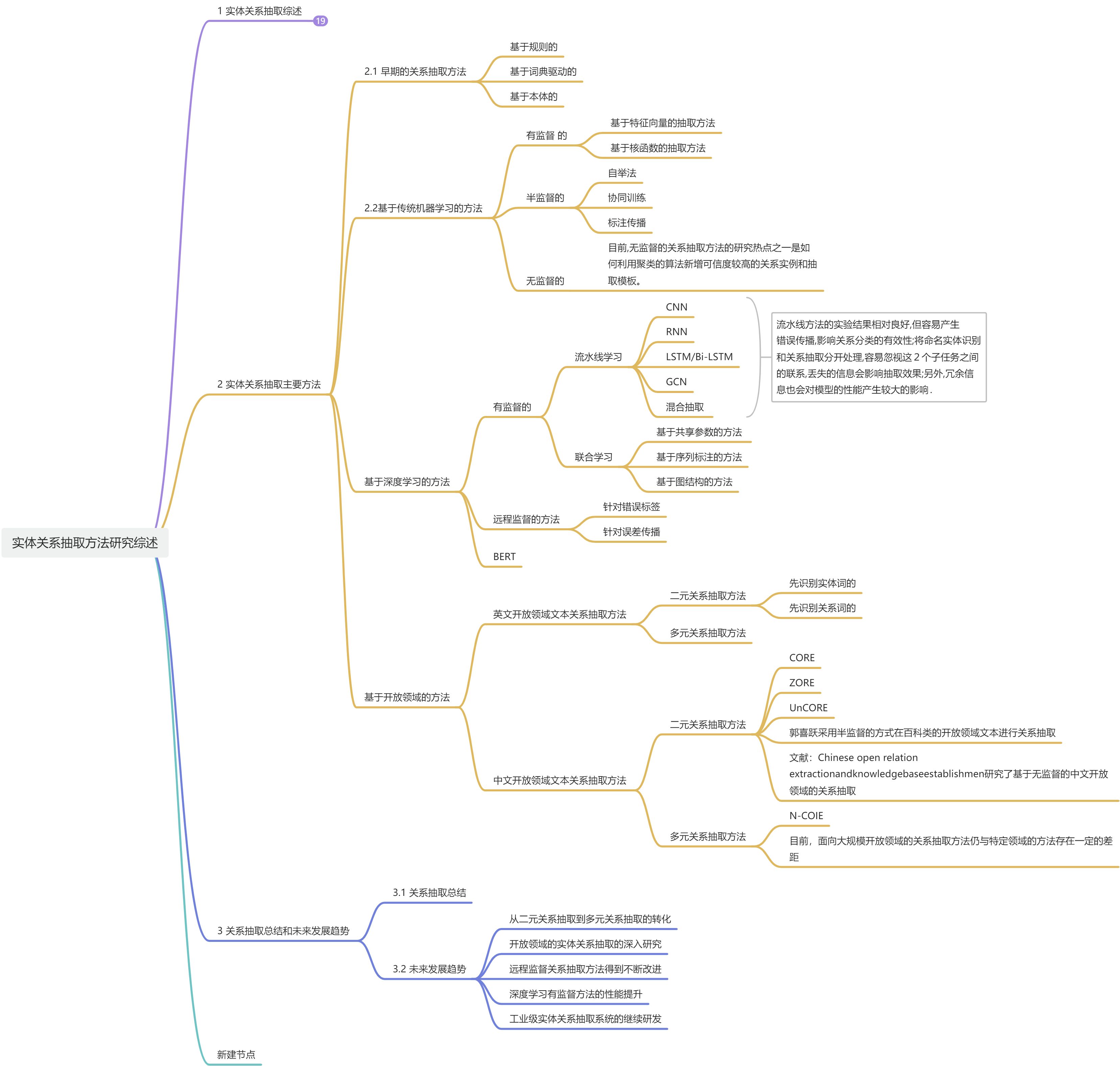
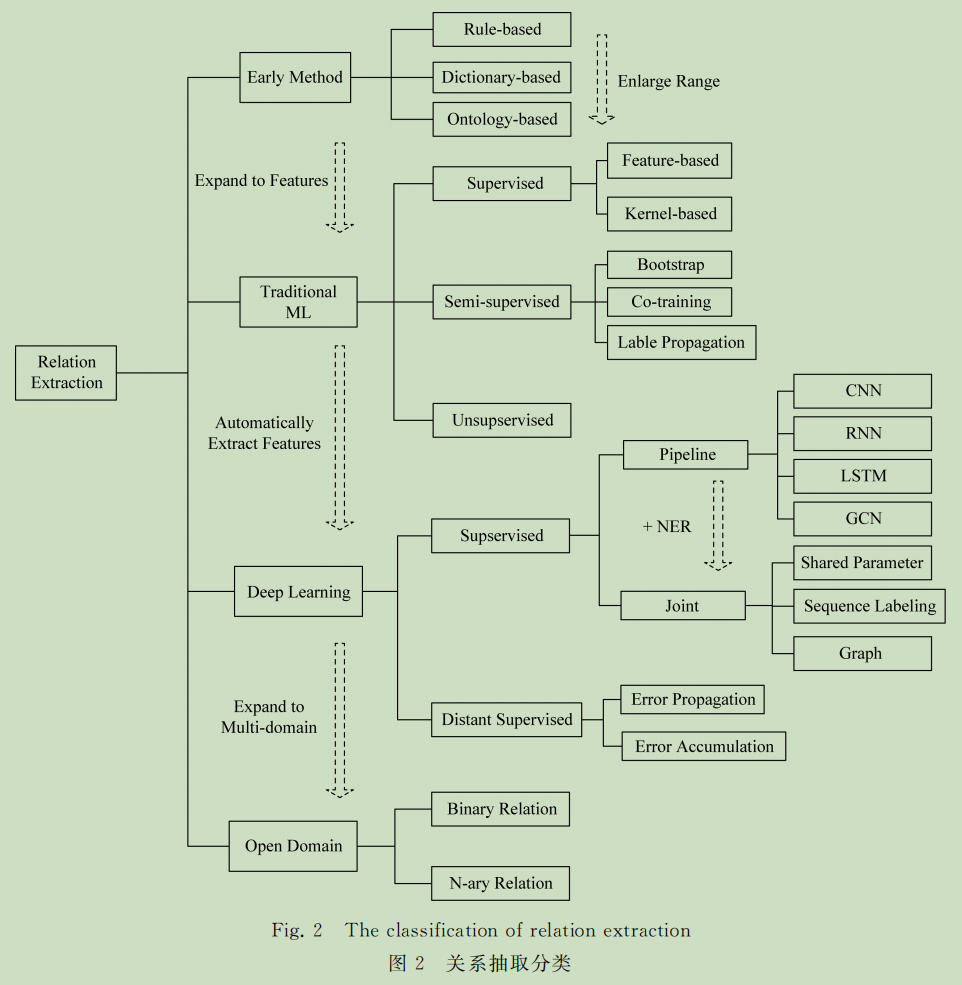
实体关系抽取主要方法
早期方法
- 基于规则的关系抽取方法
通过人工构造语法和语义规则.基于规则的方法需要运用语言学知识 提前定义能够描述2个实体所在结构的规则,这些 定义的规则主要由若干基于词语、词性或者语义的 模式集合构成.在关系抽取的过程中,将已经预处理 的语句片段与模式进行匹配判定,完成关系抽取的 分类.
缺点:基于规则的关系抽取方法 的缺点则是对跨领域的可移植性较差、人工标注成 本较高以及召回率较低.
- 基于词典驱动的关系抽取方法
需要对词典进行扩充,通常只需新增指示实体关系类型的动词即可.该方法通过字符串匹配算法识别给定文本 中的实体,并利用领域词典中的动词及其动词的关系结构判别关系类型,最终完成关系抽取任务.该方法以其简洁高效的特点曾经引起研究的热潮.
缺点:构建的词典均是以动词为关系抽取的核心依据,难以解决其他词的关系类型的抽取识别,而且灵活性较差.
- 基于本体的关系抽取方法
利用信息抽取技术抽取出的实体以及实体间的关系来构建和丰富本体,借助己有的本体层次结构和其所描述的念之间的关系来协助进行关系的抽取。
基于传统机器学习的抽取方法
有监督、半监督、无监督
过程:

- 学习过程
-
- Preprocessing,预处理,将语料文本清洗成可以直接抽取的纯文本格式
- Textual analysis,文本分析,对文本的表示及其特征进行选取;
- Relation represention,关系表示,对实体之间的联系进行语义表示;
- Relation extraction models,构建关系抽取模型
- 预测过程
前3步一样,最后一步:Relation decision,关系判定,利用训练过程中得到的关系抽取模型对测试集数据中的实体之间的关系进行判定.
有监督的
将关系抽取任务看作分类问题。需要预先了解语料库中所有可能的目标关系的种类,并通过人工对数据进行标注,建立训练语料库。

- 基于特征向量的抽取方法
最大熵/MI,支持向量机/SVM,朴素贝叶斯/NB、条件随机场/CRF
- 基于核函数的抽取方法
基于核函数的方法则是隐式地计算特征向量的内积.
此类方法在输入句法结构树之后,直接利用核函数比较关系实例之间的结构相似性。
关键在于设计出计算2个关系实例相似度的核函数.
基于核函数的方法以语料本身的结构信息为基础,比较结构化关系实例之间的相似性,完成关系抽取任务.该方法在一定程度上节省了构建高维特征的复杂工作,但在隐式计算的过程中容易产生噪声, 而且运算速度较慢。
半监督的
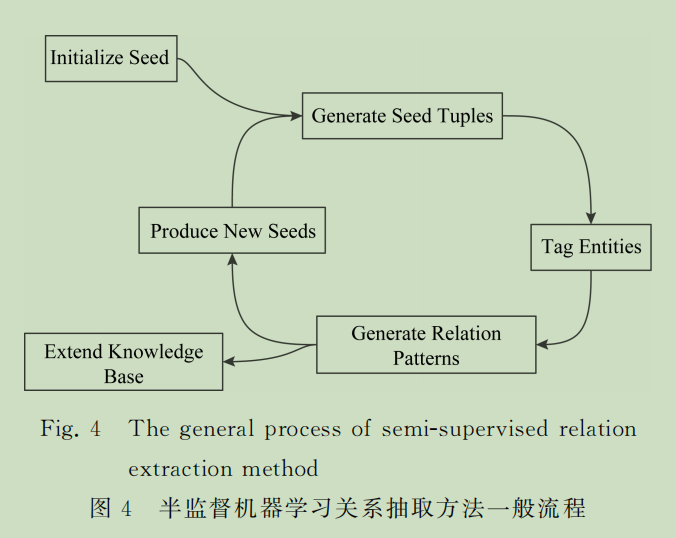
- Initialize Seed,即初始种子,利用少量关系实例人工构造的初始种子集合.
- Generate Seed Tuples即生成初始种子的关系三元组,由初始种子集合之间的实体关系产生,便于之后的实体的标识
- Tag entity,即标识实体,对文本进行预处理,利用知识库中的初始关系三元组识别训练文本中实体
- Generate relation patterns,即生成抽取模式,利用模式学习的方法,通过不断迭代,产生新关系实例
- Produce new seeds,即产生新的种子,根据新的关系实例增加新的种子,不断扩充种子集合的规模。
- Extend knowledge base,扩展知识库,将新的关系实例扩展到知识库中
自举法
首先确认少量的关系种子类型,通过不断迭代的方法自动地从大量训练语料库中获取抽取模板和新的关系实例;
协同训练
该方法利用2个分类器对同一个实例从不同角度进行关系分类。2个分类器相互学习、相互强化,不断提高关系抽取的性能,它被广泛应用在自然语言处理和信息检索领域中标注传播
标注传播
这是一种基于图的半监督机器学习方法,基本思路是用已标记节点的标签信息去预测未标记节点的标签信息.该算法将分类问题看作是标签在图上的传播,所有实体看作图中的节点,实体对之间的关系看作边.但是该方法的不确定性较高,不适合关系类别特别复杂的文本数据
无监督的
无监督的机器方法是自底向上从大规模的语料库中抽取实体之间的关系.该方法首先通过基于聚类(cluster)的思想将上下文信息相似性的实体对聚成一类,然后选取合适的词语标记关系,之后自动地抽取实体之间的语义关系.
基于深度学习的关系抽取方法
有监督的
1. 流水线学习
流水线学习方法是指在实体识别已经完成的基础上直接进行实体之间关系的抽取。
CNN、RNN、LSTM、Bi-LSTM、GCN
流水线方法的实验结果相对良好,但容易产生错误传播,影响关系分类的有效性;将命名实体识别和关系抽取分开处理,容易忽视这2个子任务之间的联系,丢失的信息会影响抽取效果;另外,冗余信息也会对模型的性能产生较大的影响.为解决这些问题,研究人员尝试将命名实体识别和关系抽取融合成一个任务,进行联合学习
2. 联合学习
- 基于共享参数的方法
命名实体识别和关系抽取通过共享编码层在训练过程中产生的共享参数相互依赖,最终训练得到最佳的全局参数.因此,基于共享参数方法有效地改善了流水线方法中存在的错误累积传播问题和忽视2个子任务间关系依赖的问题,提高模型的鲁棒性。
- 基于序列标注的方法
由于基于共性参数的方法容易产生信息冗余,而基于序列标注的方法可以同时识别出实体和关系
- 基于图的方法
前2种方法无法解决的实体重叠、关系重叠问题,基于图的方法可有效解决
远程监督的
针对海量无标记数据的处理,远程监督的实体关系抽取方法极大地减少了对人工的依赖,可以自动地抽取大量的实体对,从而扩大了知识库的规模.此外,远程监督的方法具有较强的可移植性,比较容易应用到其他领域。远程监督的基本假设是如果2个实体在己知知识库中存在着某种关系,那么涉及这2个实体的所有句子都会以某种方式表达这种关系。
这类方法在数据标注过程会带来2个问题:噪音数据和抽取特征的误差传播.基于远程监督的基本假设,海量数据的实体对的关系会被错误标记,从而产生了噪音数据;由于利用自然语言处理工具抽取的特征也存在一定的误差,会引起特征的传播误差和错误积累.本文主要针对减少错误标签和错误传播问题对远程监督的关系抽取方法进行阐述.
- 减少错误标签
- 错误传播问题
BERT
BERT作为一个预训练语言表示模型,通过上下文全向的方式理解整个语句的语义,并将训练学到的知识(知识)用于关系抽取等领域,但BERT存在许多不足之处:
- 不适合用于长文本,BERT以基于注意力机制的Transformer作为基础,不便于处理长文本;
- 易受到噪音数据的影响,BERT适用于短文本,而短文本中若出现不规则表示、错别字等噪音数据,这不仅会对关系触发词的抽取千万一定的影响,而且在联合学习时进行命名实体识别阶段也会产生错误的积累和传播,最终导致模型的性能下降;
- 无法较好地处理一词多义问题
基于开放领域的关系抽取方法
由于互联网不断发展,开放语料的规模不断扩大,并且包含的关系类型愈加复杂,研究者直接面向大多未经人工标注的开放语料进行关系抽取,有利于促进实体关系抽取的发展,而且具有更大的实际意义。
该关系抽取方法主要分为半监督和无监督2种,并结合语形特征和语义特征自动地在大规模非限定类型的语料库中进行关系抽取.开放领域关系抽取的方法无需事先人为制定关系类型,减轻了人工标注的负担,而由此设计的系统可移植性较强,极大地促进关系抽取的发展.
- 深层解析小规模的语料集,自动抽取实体间关系三元组,利用朴素贝叶斯分类器训练已标注可信和不可信的关系三元组构建关系表示模型;
- 利用关系抽取模型并输入词性、序列等特征等数据,在训练好的分类器上进行大量网络文献的关系抽取,获取候选关系三元组;
- 合并候选三元组,通过统计的方法计算各个关系三元组的可信度,并建立索引.
英文开放领域文本关系抽取方法
- 二元关系抽取方法
- 先识别实体词的方法
在早期的开放式信息抽取领域主要是针对实体词进行关系抽取该阶段利用无语义的特征,自动地学习实体之间的关系,并构建好表示文本关系的模型.主要的信息抽取系统包括 TextRunner,WOE, PATTY
2. 先识别关系词的方法
由于早期的关系抽取系统存在抽取的关系词不连贯以及关系词无法提供有效信息的问题.因此,之后面向开放领域的关系抽取开始转向先识别关系词,并深入地解析句子的语言成分进行关系抽取.
该阶段比较引人注意的有 ReVerb,OLLIE,C1ausIE等.其中,ReVerb主要以动词为核心,OLLIE 主要以名词和副词为核心
2.多元关系抽取方法
中文开放领域文本关系抽取方法
- 二元关系抽取方法
由于中文与英文存在较大的差距,因此针对英语的关系抽取系统无法直接对中文进行抽取,为了解决中文中缺省某些语言成分和倒序的问题,研究者发布CORE,ZORE,UnCORE这3个面向开篇领域的信息抽取系统。
郭喜跃采用半监督的方式在百科类的开放领域文本进行关系抽取
基于无监督的中文开放领域的关系抽取:
Jia Shengbin,Li Maozhen,Xiang Yang.Chinese open
relationextractionandknowledgebaseestablishment[J].
ACM Transactionson AsianandLowGResourceLanguage
InformationProcessing,2018,17(3):1522
总结和未来发展趋势
- 从二元关系抽取到多元关系抽取的转化
- 开放领域的实体关系抽取的深入研究
- 远程监督关系抽取方法的改进
- 深度学习有监督方法的性能提升
- 工业级实体关系抽取系统的继续研发
















 2451
2451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











