






DGCNN的全称为:Dynamic Graph CNN for Learning on Point Clouds
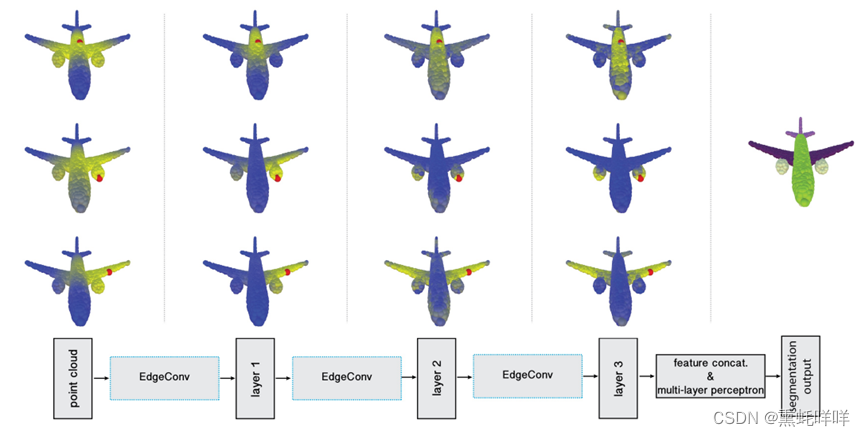
网络总体框图:
原文地址:https://arxiv.org/pdf/1801.07829.pdf
简介:
DGCNN网络结构如下图所示,主要包括两个分支,分别用于分类和分割。主要思路是通过堆叠边界卷积模块(EdgeConv)对点云数据进行高维表征。
网络总体框图:
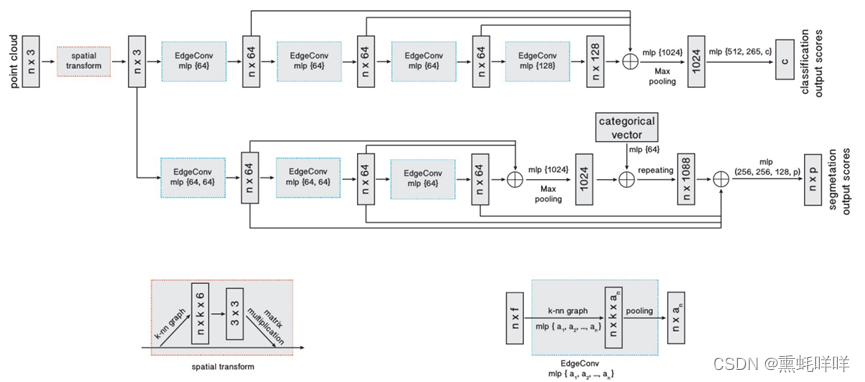
网络细节:
分类网络由三部分组成。首先通过堆叠边界卷积模块提取点云数据不同维度的特征(point-wise feature)。其次,将提取到的不同维度的特征进行拼接,并进行均值池化和最大值池化操作,得到全局特征(global feature)。最后将全局特征输入全连接神经网络(MLP),得到分类的结果。由于数据集中的分类个数是40,全连接网络输出的特征维度也为40。
分割网络与分类网络结构基本类似,区别在于经过全局/均值池化的全局特征自我复制(repeat)后,将与之前边界卷积提取的局部特征进行融合。融合的特征,再接入全连接神经网络,得到分割结果。由于S3DIS数据集中的分割类别是13,全连接网络输出的特征维度也为13。
贡献点:
-
文章提供了一个新的点云操作,即边界卷积(EdgeConv),在保持点云排列不变的基础上能更好的捕捉点云的局部几何特性。
-
文章设计的模型可以通过动态更新层与层的关系图对点运进行语义分割。
-
文章设计的边界卷积模块可以很好的集成到现有的点云处理框架中。
-
文章设计的模型在benchmark上取得了SOTA的结果。
代码实现:
数据集准备:
ModelNet40数据集:
分类任务的数据集采用ModelNet40,训练集有9843个点云、测试集有2468个点云。
共包含40个类别。下载地址为:
https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip
解压缩后结构为:
|--./ModelNet40/
|--airplane
|-- airplane_0001.txt
|-- airplane_0002.txt
|-- .......
|--bathtub
|-- bathtub_0001.txt
|-- bathtub_0002.txt
|-- .......
|--filelist.txt
|-- modelnet40_shape_names.txt
|-- modelnet40_test.txt
|-- modelnet40_train.txt
S3DIS数据集:
分割任务的数据集采用S3DIS。S3DIS数据集多用于室内点云的语义分割和实例分割,它包含6个区域(Area1,Area2,Area2,Area4,Area5,Area6),13个语义元素(天花板ceiling、地板floor、墙壁wall、梁beam、柱column、窗window、门door、桌子table、椅子chair、沙发sofa、书柜bookcase、板board 、混杂元素(其他)clutter),11种场景(办公室office、会议室conference room、走廊hallway、礼堂auditorium、开放空间open space、大堂lobby、休息室lounge、储藏室pantry、复印室copy room、储藏室storage和卫生间WC)下载地址为:https://goo.gl/forms/4SoGp4KtH1jfRqEj2,解压缩后结构为:
|--./data/
|--indoor3d_sem_seg_hdf5_data
|-- all_files.txt
|-- room_filelist.txt
|-- ply_data_all_1.h5
|-- ply_data_all_1.h5
|-- ply_data_all_1.h5
|--....
|--indoor3d_sem_seg_hdf5_data_test
|-- raw_data3d
|-- Area_1
|--conferenceRoom_1(0).txt
|-- .......
|-- all_files.txt
|-- room_filelist.txt
|-- ply_data_all_0.h5
|-- ........
|--Stanford3dDataset_v1.2_Aligned_Version
|--Aera_1
|-- ConferenceRoom_1
|--Annotations
|--beam_1.txt
|--board_1.txt
|--board_2.txt
|-- conferenceRoom_1.txt
|-- ConferenceRoom_2
|-- .......
|--Aera_2
|--stanford_indoor3d
|-- Aera_1_conferenceRoom_1.npy
|-- Aera_1_conferenceRoom_2.npy
|-- .......
数据集读取:
读取ModelNet40数据集:
class ModelNet40Dataset:
def __init__(self, root_path, split, use_norm, num_points):
self.path = root_path
self.split = split
self.use_norm = use_norm
self.num_points = num_points
shapeid_path = "modelnet40_train.txt" if self.split == "train" else "modelnet40_test.txt"
catfile = os.path.join(self.path, "modelnet40_shape_names.txt")
cat = [line.rstrip() for line in open(catfile)]
self.classes = dict(zip(cat, range(len(cat))))
shape_ids = [line.rstrip() for line in open(os.path.join(self.path, shapeid_path))]
shape_names = ['_'.join(x.split('_')[0:-1]) for x in shape_ids]
self.datapath = [(shape_names[i], os.path.join(self.path, shape_names[i], shape_ids[i]) + '.txt') for i
in range(len(shape_ids))]
def __getitem__(self, index):
fn = self.datapath[index]
label = self.classes[self.datapath[index][0]]
label = np.asarray([label]).astype(np.int32)
point_cloud = np.loadtxt(fn[1], delimiter=',').astype(np.float32)
if self.use_norm:
point_cloud = point_cloud[:self.num_points, :]
else:
point_cloud = point_cloud[:self.num_points, :3]
point_cloud[:, :3] = self._pc_normalize(point_cloud[:, :3])
return point_cloud, label[0]
def translate_pointcloud(self,pointcloud):
xyz1 = np.random.uniform(low=2. / 3., high=3. / 2., size=[3])
xyz2 = np.random.uniform(low=-0.2, high=0.2, size=[3])
translated_pointcloud = np.add(np.multiply(pointcloud, xyz1), xyz2).astype('float32')
return translated_pointcloud
def __len__(self):
return len(self.datapath)
def _pc_normalize(self, data):
centroid = np.mean(data, axis=0)
data = data - centroid
m = np.max(np.sqrt(np.sum(data ** 2, axis=1)))
data /= m
return data读取S3DIS数据集:
def download_S3DIS():
BASE_DIR=os.path.dirname(os.path.abspath(__file__))
DATA_DIR=os.path.join(BASE_DIR,"data")
if not os.path.exists(DATA_DIR):
os.mkdir(DATA_DIR)
if not os.path.exists(os.path.join(DATA_DIR, 'indoor3d_sem_seg_hdf5_data')):
www = 'https://shapenet.cs.stanford.edu/media/indoor3d_sem_seg_hdf5_data.zip'
zipfile = os.path.basename(www)
os.system('wget %s --no-check-certificate; unzip %s' % (www, zipfile))
os.system('mv %s %s' % ('indoor3d_sem_seg_hdf5_data', DATA_DIR))
os.system('rm %s' % (zipfile))
if not os.path.exists(os.path.join(DATA_DIR, 'Stanford3dDataset_v1.2_Aligned_Version')):
if not os.path.exists(os.path.join(DATA_DIR, 'Stanford3dDataset_v1.2_Aligned_Version.zip')):
print('Please download Stanford3dDataset_v1.2_Aligned_Version.zip \
from https://goo.gl/forms/4SoGp4KtH1jfRqEj2 and place it under data/')
sys.exit(0)
else:
zippath = os.path.join(DATA_DIR, 'Stanford3dDataset_v1.2_Aligned_Version.zip')
os.system('unzip %s' % (zippath))
os.system('mv %s %s' % ('Stanford3dDataset_v1.2_Aligned_Version', DATA_DIR))
os.system('rm %s' % (zippath))
def prepare_test_data_semseg():
BASE_DIR=os.path.dirname(os.path.abspath(__file__))
DATA_DIR=os.path.join(BASE_DIR,'data')
if not os.path.exists(os.path.join(DATA_DIR, 'stanford_indoor3d')):
os.system('python prepare_data/collect_indoor3d_data.py')
if not os.path.exists(os.path.join(DATA_DIR, 'indoor3d_sem_seg_hdf5_data_test')):
os.system('python prepare_data/gen_indoor3d_h5.py')
def load_data_semseg(split, test_area):
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
DATA_DIR = os.path.join(BASE_DIR, 'data')
download_S3DIS()
prepare_test_data_semseg()
if split == 'train':
data_dir = os.path.join(DATA_DIR, 'indoor3d_sem_seg_hdf5_data')
else:
data_dir = os.path.join(DATA_DIR, 'indoor3d_sem_seg_hdf5_data_test')
with open(os.path.join(data_dir, "all_files.txt")) as f:
all_files = [line.rstrip() for line in f]
with open(os.path.join(data_dir, "room_filelist.txt")) as f:
room_filelist = [line.rstrip() for line in f]
data_batchlist, label_batchlist = [], []
for f in all_files:
file = h5py.File(os.path.join(DATA_DIR, f), 'r+')
data = file["data"][:]
label = file["label"][:]
data_batchlist.append(data)
label_batchlist.append(label)
data_batches = np.concatenate(data_batchlist, 0)
seg_batches = np.concatenate(label_batchlist, 0)
test_area_name = "Area_" + str(test_area)
train_idxs, test_idxs = [], []
for i, room_name in enumerate(room_filelist):
if test_area_name in room_name:
test_idxs.append(i)
else:
train_idxs.append(i)
if split == 'train':
all_data = data_batches[train_idxs, ...]
all_seg = seg_batches[train_idxs, ...]
else:
all_data = data_batches[test_idxs, ...]
all_seg = seg_batches[test_idxs, ...]
return all_data, all_seg
def translate_pointcloud(pointcloud):
xyz1 = np.random.uniform(low=2. / 3., high=3. / 2., size=[3])
xyz2 = np.random.uniform(low=-0.2, high=0.2, size=[3])
translated_pointcloud = np.add(np.multiply(pointcloud, xyz1), xyz2).astype('float32')
return translated_pointcloud
def jitter_pointcloud(pointcloud, sigma=0.01, clip=0.02):
N, C = pointcloud.shape
pointcloud += np.clip(sigma * np.random.randn(N, C), -1*clip, clip)
return pointcloud
def rotate_pointcloud(pointcloud):
theta = np.pi*2 * np.random.uniform()
rotation_matrix = np.array([[np.cos(theta), -np.sin(theta)],[np.sin(theta), np.cos(theta)]])
pointcloud[:,[0,2]] = pointcloud[:,[0,2]].dot(rotation_matrix) # random rotation (x,z)
return pointcloud
class S3DISDataset:
"""
A source dataset that reads, parses and augments the S3DIS dataset.
Args:
path (str): The root directory of the ModelNet40 dataset or inference pointcloud.
split (str): The dataset split, supports "train", "val", or "infer". Default: "train".
transform (callable, optional):A function transform that takes in a pointcloud. Default: None.
target_transform (callable, optional):A function transform that takes in a label. Default: None.
batch_size (int): The batch size of dataset. Default: 64.
resize (Union[int, tuple]): The output size of the resized image. If size is an integer, the smaller edge of the
image will be resized to this value with the same image aspect ratio. If size is a sequence of length 2,
it should be (height, width). Default: 224.
repeat_num (int): The repeat num of dataset. Default: 1.
shuffle (bool, optional): Whether or not to perform shuffle on the dataset. Default: None.
download (bool): Whether to download the dataset. Default: False.
mr_file (str, optional): The path of mindrecord files. Default: False.
columns_list (tuple): The column names of output data. Default: ('image', 'image_id', "label").
num_parallel_workers (int, optional): The number of subprocess used to fetch the dataset
in parallel.Default: None.
num_shards (int, optional): The number of shards that the dataset will be divided. Default: None.
shard_id (int, optional): The shard ID within num_shards. Default: None.
Raises:
ValueError: If `split` is not 'train', 'test' or 'infer'.
Examples:
>>>from mindvision.ms3d.dataset import ModelNet40
>>>dataset = ModelNet40("./data/S3DIS/","train")
>>>dataset=dataset.run()
About S3DIS dataset:
A brief description of s3dis data set: in 271 rooms in 6 areas, make ⽤ matterport camera (combined with 3
structured light sensors with different spacing) heavy after scanning Create 3D texture grids, rgb-d images and
other data, and make point clouds by sampling grids. A semantic label is added to each point in the point cloud
(such as chair, table, floor, wall, etc., a total of 13 objects)
.. code-block::
./S3DIS/
├── indoor3d_sem_seg_hdf5_data
│ ├── ply_data_all_0.h5
│ ├── ply_data_all_1.h5
│ ├── ...
│ └── all_files.bak.txt
├── indoor3d_sem_seg_hdf5_data_test
│ └── raw_data3d
│ ├── Area_1
│ ├── Area_2
│ ├── ...
│ ├── ply_data_all_0.h5
│ ├── ply_data_all_1.h5
│ ├── ...
│ ├── all_files.txt
│ └── room_filelist.txt
├── Stanford3dDataset_v1.2_Aligned_Version
│ ├── Area_1
│ ├── Area_2
│ └── ...
└── stanford_indoor3d
├── Area_1_conferenceRoom_1.npy
├──Area_1_conferenceRoom_2.npy
└── ...
"""
def __init__(self,num_points=4096,split="train",test_area="1"):
self.data,self.seg=load_data_semseg(split,test_area)
self.num_points=num_points
self.split=split
def __getitem__(self, item):
pointcloud=self.data[item][:self.num_points]
seg=self.seg[item][:self.num_points]
if self.split=="train":
indices=list(range(pointcloud.shape[0]))
np.random.shuffle(indices)
pointcloud=pointcloud[indices]
seg=seg[indices]
seg=seg.astype(np.int32)
return pointcloud,seg
def __len__(self):
return self.data.shape[0]核心模块实现:
KNN模块:
def KNN(x, k):
"""
KNN Module.
The input data is x shape(B,C,N)
where B is the batch size ,C is the dimension of the transform matrix
and N is the number of points.
:param x: input data
:param k: k-NearestNeighbor Parameter
:return: Tensor shape(B,N,K)
"""
inner = -2 * ops.matmul(x.transpose(0, 2, 1), x)
xx = (x ** 2).sum(axis=1, keepdims=True)
pairwise_distance = -xx - inner - xx.transpose(0, 2, 1)
topk = ops.TopK(sorted=True)
_, idx = topk(pairwise_distance, k)
return idx特征图提取模块:
def Getgraphfeature(x,k=20,idx=None,dim9=False):
batch_size=x.shape[0]
num_points=x.shape[2]
x=x.view(batch_size,-1,num_points)
if idx is None:
if dim9==False:
idx=KNN(x,k=k)
else:
idx=KNN(x[:,6:],k=k)
idx_base=np.arange(0,batch_size,dtype=mindspore.int32).view(-1,1,1)*num_points
idx=idx+idx_base
idx=idx.view(-1)
_,num_dims,_=x.shape
x=x.transpose(0,2,1)
#print(idx)
feature = x.view(batch_size * num_points, -1)[idx, :]
feature = feature.view(batch_size, num_points, k, num_dims)
x = x.view(batch_size, num_points, 1, num_dims)
x=np.tile(x,(1,1,k,1))
#x = np.repeat(x, k, axis=2)
op = ops.Concat(3)
feature = op((feature - x, x)).transpose(0, 3, 1, 2) # .permute(0,3,1,2) #2 6 1024 20
return feature边界卷积模块:
def conv_bn_block(input,output,kernel_size):
return nn.SequentialCell(nn.Conv2d(input,output,kernel_size),
nn.BatchNorm2d(output),
nn.LeakyReLU())
class EdgeConv(nn.Cell):
def __init__(self,layers,dim9,K=20):
"""
Edge Conv Module.
The input data is x(Tensor):shape(B,F),
where B is the batch size and F is the dimension of feature.
"""
super(EdgeConv,self).__init__()
self.K=K
self.layers=layers
self.dim9=dim9
if self.layers is None:
self.mlp=None
else:
mlp_layers=OrderedDict()
for i in range(len(self.layers)-1):
if i==0:
mlp_layers["conv_bn_blcok_{}".format(i+1)]=conv_bn_block(self.layers[i],self.layers[i+1],1)
else:
mlp_layers["conv_bn_blcok_{}".format(i+1)]=conv_bn_block(self.layers[i],self.layers[i+1],1)
self.mlp=nn.SequentialCell(mlp_layers)
def construct(self,x):
x=Getgraphfeature(x,k=self.K,dim9=self.dim9)
x=self.mlp(x)
argmax=ops.ArgMaxWithValue(axis=-1)
index,x=argmax(x)
#x=x.max(axis=-1,keepdims=False)[0]
return x网络整体框架:
分类网络:
class DGCNN_cls(nn.Cell):
"""
Constructs a dgcnn architecture from
DGCNN: Dynamic Graph CNN for Learning on Point Clouds (https://arxiv.org/pdf/1801.07829).
Args:
emb_dims (int): Dimension of network characteristics. Default: 1024
k (int): Number of clustering points. Default: 20.
dropout(float): Network deactivation coefficient. Default: 0.5
Inputs:
- points(Tensor) - Tensor of original points. shape:[batch, channels, npoints].
Outputs:
Tensor of shape :[batch, 40].
Supported Platforms:
``GPU``
Examples:
>> import numpy as np
>> import mindspore as ms
>> from mindspore import Tensor, context
>> from mind3d.models.dgcnn import DGCNN_cls
>> context.set_context(mode=context.GRAPH_MODE, device_target="GPU", save_graphs=False, max_call_depth=2000)
>> net = DGCNN_cls(k=20,emb_dims=1024,drop_out=0.5)
>> xyz = Tensor(np.ones((24,3, 1024)),ms.float32)
>> output = net(xyz)
>> print(output.shape)
(24, 40)
About DGCNN_cls
This architecture is based DGCNN,
compared with PointNet, PointNet added edgeconv.
"""
def __init__(self, opt):
super(DGCNN_cls, self).__init__()
self.opt = opt["train"]
self.k = self.opt.get("k")
self.edge_conv1 = EdgeConv(layers=[6, 64], K=self.k, dim9=False)
self.edge_conv2 = EdgeConv(layers=[64 * 2, 64], K=self.k, dim9=False)
self.edge_conv3 = EdgeConv(layers=[64 * 2, 128], K=self.k, dim9=False)
self.edge_conv4 = EdgeConv(layers=[128 * 2, 256], K=self.k, dim9=False)
self.conv5 = nn.Conv1d(512, self.opt.get("emb_dims"), kernel_size=1)
self.bn5 = nn.BatchNorm2d(self.opt.get("emb_dims"))
self.leakyRelu = nn.LeakyReLU()
self.linear1 = nn.Dense(self.opt.get("emb_dims") * 2, 512, has_bias=False)
self.bn6 = nn.BatchNorm1d(512)
self.dp1 = nn.Dropout(self.opt.get("dropout"))
self.linear2 = nn.Dense(512, 256)
self.bn7 = nn.BatchNorm1d(256)
self.dp2 = nn.Dropout(self.opt.get("dropout"))
self.linear3 = nn.Dense(256, 40)
self.maxpool = nn.AdaptiveMaxPool1d(1) # 1024
self.avepool = nn.AdaptiveAvgPool1d(1) # 1024
def construct(self, x):
B, N, C = x.shape
x=x.transpose(0,2,1)
x1 = self.edge_conv1(x)
x2 = self.edge_conv2(x1)
x3 = self.edge_conv3(x2)
x4 = self.edge_conv4(x3)
cat = ops.Concat(1)
x = cat((x1, x2, x3, x4))
x = self.conv5(x)
x = ops.ExpandDims()(x, -1)
x = self.leakyRelu(self.bn5(x))
squeeze = ops.Squeeze(-1)
x = squeeze(x)
x1 = self.maxpool(x).view(B, -1)
x2 = self.avepool(x).view(B, -1)
x = cat((x1, x2))
x = self.leakyRelu(self.bn6(self.linear1(x)))
x = self.dp1(x)
x = self.leakyRelu(self.bn7(self.linear2(x)))
x = self.dp2(x)
x = self.linear3(x)
return x分割网络:
class DGCNN_seg(nn.Cell):
"""
Constructs a dgcnn architecture from
DGCNN: Dynamic Graph CNN for Learning on Point Clouds (https://arxiv.org/pdf/1801.07829).
Args:
num_classes (int): The total number of categories output by the network. Default: 13
k (int): Number of clustering points. Default: 20.
Inputs:
- points(Tensor) - Tensor of original points. shape:[batch, channels, npoints].
Outputs:
Tensor of shape :[batch, 40].
Supported Platforms:
``GPU``
Examples:
>> import numpy as np
>> import mindspore as ms
>> from mindspore import Tensor, context
>> from mind3d.models.dgcnn import DGCNN_seg
>> context.set_context(mode=context.GRAPH_MODE, device_target="GPU", save_graphs=False, max_call_depth=2000)
>> net = DGCNN_seg(k=20,emb_dims=1024,drop_out=0.5)
>> xyz = Tensor(np.ones((24,3, 1024)),ms.float32)
>> output = net(xyz)
>> print(output.shape)
(13, 3, 1024)
About DGCNN_seg
This architecture is based DGCNN,
compared with PointNet, PointNet added edgeconv.
"""
def __init__(self, opt):
super().__init__()
self.opt = opt["train"]
self.num_classes = self.opt.get("num_classes")
self.k = self.opt.get("k")
self.edge_conv1 = EdgeConv(layers=[18, 64, 64], K=self.k, dim9=True)
self.edge_conv2 = EdgeConv(layers=[64 * 2, 64, 64], K=self.k, dim9=False)
self.edge_conv3 = EdgeConv(layers=[64 * 2, 64], K=self.k, dim9=False)
self.conv6 = nn.Conv1d(192, 1024, kernel_size=1, has_bias=False)
self.conv7 = nn.Conv1d(1216, 512, kernel_size=1, has_bias=False)
self.conv8 = nn.Conv1d(512, 256, kernel_size=1, has_bias=False)
self.dp1 = nn.Dropout(0.5)
self.conv9 = nn.Conv1d(256, self.num_classes, kernel_size=1, has_bias=False)
self.bn6 = nn.BatchNorm2d(1024)
self.bn7 = nn.BatchNorm2d(512)
self.bn8 = nn.BatchNorm2d(256)
self.leakyRelU = nn.LeakyReLU()
def construct(self, x):
x = x.transpose(0, 2, 1)
x1 = self.edge_conv1(x)
x2 = self.edge_conv2(x1)
x3 = self.edge_conv3(x2)
cat = ops.Concat(1)
x = cat((x1, x2, x3))
x = self.conv6(x) # batch_size,64*3,num_points
x = ops.ExpandDims()(x, -1)
x = self.leakyRelU(self.bn6(x))
squeeze = ops.Squeeze(-1)
x = squeeze(x)
argmax = ops.ArgMaxWithValue(axis=-1, keep_dims=True)
index, x = argmax(x)
x = np.tile(x, (1, 1, 4096)) # (batch_size,1024,num_points)
x = cat((x, x1, x2, x3)) # (batch_size,1024+64*3,num_points)
x = self.conv7(x) # (batch_size,1024+64*3,num_points)->(batch_size,512,num_points)
x = ops.ExpandDims()(x, -1)
x = self.bn7(x)
x = self.leakyRelU(ops.Squeeze(-1)(x))
x = self.conv8(x) # (batch_size,512,num_points)->(batch_size,256,num_points)
x = ops.ExpandDims()(x, -1)
x = self.bn8(x)
x = self.leakyRelU(ops.Squeeze(-1)(x))
x = self.dp1(x)
x = self.conv9(x) # (batch_size,256,num_points)->(batch_size,13,num_points)
return x损失函数定义:
class CrossEntropySmooth_CLS(LossBase):
"""CrossEntropy for cls"""
def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):
super(CrossEntropySmooth_CLS, self).__init__()
self.onehot = ops.OneHot()
self.sparse = sparse
self.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)
self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)
self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)
def construct(self, logit, label):
if self.sparse:
label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)
loss = self.ce(logit, label)
return loss
class CrossEntropySmooth_SEG(LossBase):
"""CrossEntropy for seg"""
def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):
super(CrossEntropySmooth_SEG, self).__init__()
self.onehot = ops.OneHot()
self.sparse = sparse
self.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)
self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)
self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)
def construct(self, logit, label):
logit=logit.transpose(0,2,1)
logit=logit.view(-1,13)
label=label.view(-1,1).squeeze()
if self.sparse:
label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)
loss = self.ce(logit, label)
return loss网络训练:
分类网络:
""" DGCNN classfication training script. """
import argparse
import os
import sys
import logging
from datetime import datetime
import numpy as np
from tqdm import tqdm
import importlib
import mindspore
import mindspore.nn as nn
from mindspore import context,load_checkpoint,load_param_into_net
from mindspore.context import ParallelMode
from mindspore.common import set_seed
import mindspore.dataset as ds
import mindspore.ops as ops
from mindspore import save_checkpoint
from mindspore.communication.management import init
from mindspore.train import Model
from mindspore.train.callback import ModelCheckpoint,CheckpointConfig
set_seed(1)
BASE_DIR=os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.dirname(os.path.dirname(BASE_DIR)))
ROOT_DIR=os.path.join(os.path.dirname(os.path.dirname(BASE_DIR)),"models")
sys.path.append(ROOT_DIR)
from dataset.ModelNet40 import ModelNet40Dataset
from engine.callback.monitor import ValAccMonitor
from utils.Lossfunction import CrossEntropySmooth_CLS
from src.load_yaml import load_yaml
from models.dgcnn import DGCNN_cls
def dgcnn_cls_train(opt):
"""DGCNN cls train."""
# device.
device_id = int(os.getenv('DEVICE_ID', '0'))
device_num = int(os.getenv('RANK_SIZE', '1'))
if not opt['device_target'] in ("Ascend", "GPU"):
raise ValueError("Unsupported platform {}".format(opt['device_target']))
if opt['device_target'] == "Ascend":
context.set_context(mode=context.GRAPH_MODE,
device_target="Ascend",
save_graphs=False,
device_id=device_id)
context.set_context(max_call_depth=2048)
else:
context.set_context(mode=context.GRAPH_MODE,
device_target="GPU",
save_graphs=False,
max_call_depth=2048)
# run distribute.
if opt['run_distribute']:
if opt['device_target'] == "Ascend":
if device_num > 1:
init()
context.set_auto_parallel_context(
parallel_mode=ParallelMode.DATA_PARALLEL, gradients_mean=True)
else:
if device_num > 1:
mindspore.dataset.config.set_enable_shared_mem(False)
context.set_auto_parallel_context(
parallel_mode=context.ParallelMode.DATA_PARALLEL,
gradients_mean=True,
device_num=device_num)
mindspore.common.set_seed(1234)
init()
else:
context.set_context(device_id=device_id)
#Data Pipeline.
dataset = ModelNet40Dataset(root_path=opt['datasets']['train'].get('data_path'),
split="train",
num_points=opt['datasets']['train'].get('resize'),
use_norm=opt['datasets']['train'].get('use_norm'))
dataset_train = ds.GeneratorDataset(dataset, ["data", "label"], shuffle=True)
dataset_train = dataset_train.batch(batch_size=opt['datasets']['train'].get('batch_size'), drop_remainder=True)
dataset = ModelNet40Dataset(root_path=opt['datasets']['val'].get('data_path'),
split="val",
num_points=opt['datasets']['val'].get('resize'),
use_norm=opt['datasets']['val'].get('use_norm'))
dataset_val = ds.GeneratorDataset(dataset, ["data", "label"], shuffle=True)
dataset_val = dataset_val.batch(batch_size=opt['datasets']['val'].get('batch_size'), drop_remainder=True)
step_size = dataset_train.get_dataset_size()
'''MODEL LOADING'''
# Create model.
network=DGCNN_cls(opt,output_channels=opt['train'].get("num_classes"))
# load checkpoint
if opt['train']['pretrained_ckpt'].endswith('.ckpt'):
print("Load checkpoint: %s" % opt['train']['pretrained_ckpt'])
param_dict = load_checkpoint(opt['train']['pretrained_ckpt'])
load_param_into_net(network, param_dict)
# Set learning rate scheduler.
if opt['train']['lr_decay_mode'] == "cosine_decay_lr":
lr = nn.cosine_decay_lr(min_lr=opt['train']['min_lr'],
max_lr=opt['train']['max_lr'],
total_step=opt['train']['epoch_size'] * step_size,
step_per_epoch=step_size,
decay_epoch=opt['train']['decay_epoch'])
elif opt['train']['lr_decay_mode'] == "piecewise_constant_lr":
lr = nn.piecewise_constant_lr(opt['train']['milestone'], opt['train']['learning_rates'])
# Define optimizer.
network_opt = nn.Adam(network.trainable_params(), lr, opt['train']['momentum'])
# Define loss function.
network_loss = CrossEntropySmooth_CLS(num_classes=40)
# Define metrics.
metrics = {"Accuracy": nn.Accuracy()}
# Init the model.
model = Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=metrics)
# Set the checkpoint config for the network.
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size,
keep_checkpoint_max=opt['train']['keep_checkpoint_max'])
ckpt_callback = ModelCheckpoint(prefix='dgcnn_cls',
directory=opt['train']['ckpt_save_dir'],
config=ckpt_config)
# Begin to train.
model.train(opt['train']['epoch_size'],
dataset_train,
callbacks=[ckpt_callback, ValAccMonitor(model, dataset_val, opt['train']['epoch_size'])],
dataset_sink_mode=opt['train']['dataset_sink_mode'])
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='PointNet train.')
parser.add_argument('-opt', type=str, required=True, help='Path to option YAML file.')
args = parser.parse_known_args()[0]
opt = load_yaml(args.opt)
dgcnn_cls_train(opt)分割网络:
""" DGCNN segmentation training script."""
import argparse
import os
import sys
import logging
from datetime import datetime
import numpy as np
from tqdm import tqdm
import mindspore
import mindspore.nn as nn
from mindspore import context,load_checkpoint,load_param_into_net
from mindspore.context import ParallelMode
from mindspore.common import set_seed
import mindspore.dataset as ds
import mindspore.ops as ops
from mindspore import save_checkpoint
from mindspore.communication.management import init
from mindspore.train import Model
from mindspore.train.callback import ModelCheckpoint,CheckpointConfig
set_seed(1)
BASE_DIR=os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.dirname(os.path.dirname(BASE_DIR)))
ROOT_DIR=os.path.join(os.path.dirname(os.path.dirname(BASE_DIR)),"models")
sys.path.append(ROOT_DIR)
from dataset.S3DIS import S3DISDataset
from engine.callback.monitor import ValAccMonitor
from utils.Lossfunction import CrossEntropySmooth_SEG
from src.load_yaml import load_yaml
from models.dgcnn import DGCNN_seg
def dgcnn_seg_train(opt,test_area):
"""DGCNN set train"""
# device.
device_id = int(os.getenv('DEVICE_ID', '0'))
device_num = int(os.getenv('RANK_SIZE', '1'))
if not opt['device_target'] in ("Ascend", "GPU"):
raise ValueError("Unsupported platform {}".format(opt['device_target']))
if opt['device_target'] == "Ascend":
context.set_context(mode=context.GRAPH_MODE,
device_target="Ascend",
save_graphs=False,
device_id=device_id)
context.set_context(max_call_depth=2048)
else:
context.set_context(mode=context.GRAPH_MODE,
device_target="GPU",
save_graphs=False,
max_call_depth=2048)
# run distribute.
if opt['run_distribute']:
if opt['device_target'] == "Ascend":
if device_num > 1:
init()
context.set_auto_parallel_context(
parallel_mode=ParallelMode.DATA_PARALLEL, gradients_mean=True)
else:
if device_num > 1:
mindspore.dataset.config.set_enable_shared_mem(False)
context.set_auto_parallel_context(
parallel_mode=context.ParallelMode.DATA_PARALLEL,
gradients_mean=True,
device_num=device_num)
mindspore.common.set_seed(1234)
init()
else:
context.set_context(device_id=device_id)
#Data Pipeline.
dataset = S3DISDataset(split="train", num_points=opt["datasets"]['train'].get("resize"), test_area=test_area)
dataset_train = ds.GeneratorDataset(dataset, ["data", "label"], shuffle=True)
dataset_train = dataset_train.batch(opt["datasets"]['train'].get("batch_size"), drop_remainder=True)
dataset = S3DISDataset(split='test', num_points=opt["datasets"]['val'].get("resize"), test_area=test_area)
dataset_val = ds.GeneratorDataset(dataset, ["data", "label"], shuffle=False)
dataset_val = dataset_val.batch(opt["datasets"]['val'].get("batch_size"),drop_remainder=True)
step_size = dataset_train.get_dataset_size()
"""MODEL LOADING."""
#create model.
network=DGCNN_seg(opt,k=opt["train"].get("k"))
# load checkpoint
if opt['train']['pretrained_ckpt'].endswith('.ckpt'):
print("Load checkpoint: %s" % opt['train']['pretrained_ckpt'])
param_dict = load_checkpoint(opt['train']['pretrained_ckpt'])
load_param_into_net(network, param_dict)
# Set learning rate scheduler.
if opt['train']['lr_decay_mode'] == "cosine_decay_lr":
lr = nn.cosine_decay_lr(min_lr=opt['train']['min_lr'],
max_lr=opt['train']['max_lr'],
total_step=opt['train']['epoch_size'] * step_size,
step_per_epoch=step_size,
decay_epoch=opt['train']['decay_epoch'])
elif opt['train']['lr_decay_mode'] == "piecewise_constant_lr":
lr = nn.piecewise_constant_lr(opt['train']['milestone'], opt['train']['learning_rates'])
#Define optimizer.
network_opt = nn.Adam(network.trainable_params(), lr, opt['train']['momentum'])
#Define loss function.
network_loss=CrossEntropySmooth_SEG(num_classes=13,reduction="mean",sparse=True)
# Define metrics.
metrics = {"Accuracy": nn.Accuracy()}
# Init the model.
model = Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=metrics)
# Set the checkpoint config for the network.
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size,
keep_checkpoint_max=opt['train']['keep_checkpoint_max'])
prefix_name="model_%s"%test_area
ckpt_callback = ModelCheckpoint(prefix=prefix_name,
directory=opt['train']['ckpt_save_dir'],
config=ckpt_config)
# Begin to train.
print("============ Starting Training ================")
model.train(opt['train']['epoch_size'],
dataset_train,
callbacks=[ckpt_callback, ValAccMonitor(model, dataset_val, opt['train']['epoch_size'])],
dataset_sink_mode=opt['train']['dataset_sink_mode'])
print("============ End Training ====================")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Dgcnn train.')
parser.add_argument('-opt', type=str, required=True, help='Path to option YAML file.')
parser.add_argument("-test_area",type=int,required=True,help="Choose test_area")
args = parser.parse_known_args()[0]
opt = load_yaml(args.opt)
dgcnn_seg_train(opt,args.test_area)模型导出:
import os
import sys
import argparse
import numpy as np
import mindspore
from mindspore import Tensor,export,load_checkpoint,context
from models.dgcnn import DGCNN_seg,DGCNN_cls
from src.load_yaml import load_yaml
if not os.path.exists("./mindir"):
os.mkdir("./mindir")
num_classes=40
part_num=50
def dgcnn_export(opt,args):
if args.task=="classification":
classifier=DGCNN_cls(opt,output_channels=opt['train'].get("num_classes"))
load_checkpoint(args.model,net=classifier)
input_data=Tensor(np.random.uniform(0.0,1.0,size=[32,1024,3]),mindspore.float32)
export(classifier,input_data,file_name="./mindir/dgcnn_cls",file_format=args.file_format)
print("successfully export model")
elif args.task=="segmentation":
classifier=DGCNN_seg(opt, opt['train'].get("k"))
load_checkpoint(args.model,net=classifier)
input_data=Tensor(np.random.uniform(0.0,1.0,size=[3,4096,9]),mindspore.float32)
export(classifier,input_data,file_name="./mindir/dgcnn_seg_model_6",file_format=args.file_format)
print("successfully export model")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Mindspore DGCNN")
parser.add_argument("--device_target", default="GPU", help='device')
parser.add_argument("-task", default="segmentation", help="classificaton or segmentation")
parser.add_argument('--model', type=str, default="", help="model path")
parser.add_argument("--file_format", type=str, default="MINDIR", help="export file format")
parser.add_argument("-opt", type=str, default="",
help='Path to option YAML file.')
args = parser.parse_known_args()[0]
os.environ["CUDA_VISBLE_DEVICES"] = '1'
context.set_context(mode=context.PYNATIVE_MODE, device_target=args.device_target)
opt = load_yaml(args.opt)
dgcnn_export(opt,args)
参考文献:
@article{dgcnn,
title={Dynamic Graph CNN for Learning on Point Clouds},
author={Wang, Yue and Sun, Yongbin and Liu, Ziwei and Sarma, Sanjay E. and Bronstein, Michael M. and Solomon, Justin M.},
journal={ACM Transactions on Graphics (TOG)},
year={2019}
}














 3890
3890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









