






灰色预测算法:https://blog.csdn.net/weixin_41987016/article/details/107448710









完整代码:
#GM.py
def GM(x0): #自定义灰色预测函数
import numpy as np
x1 = x0.cumsum() #1-AGO序列
z1 = (x1[:len(x1)-1] + x1[1:])/2.0 #紧邻均值(MEAN)生成序列
z1 = z1.reshape((len(z1),1))
B = np.append(-z1, np.ones_like(z1), axis = 1)
Yn = x0[1:].reshape((len(x0)-1, 1))
[[a],[b]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Yn) #计算参数
f = lambda k: (x0[0]-b/a)*np.exp(-a*(k-1))-(x0[0]-b/a)*np.exp(-a*(k-2)) #还原值
delta = np.abs(x0 - np.array([f(i) for i in range(1,len(x0)+1)]))
C = delta.std()/x0.std()
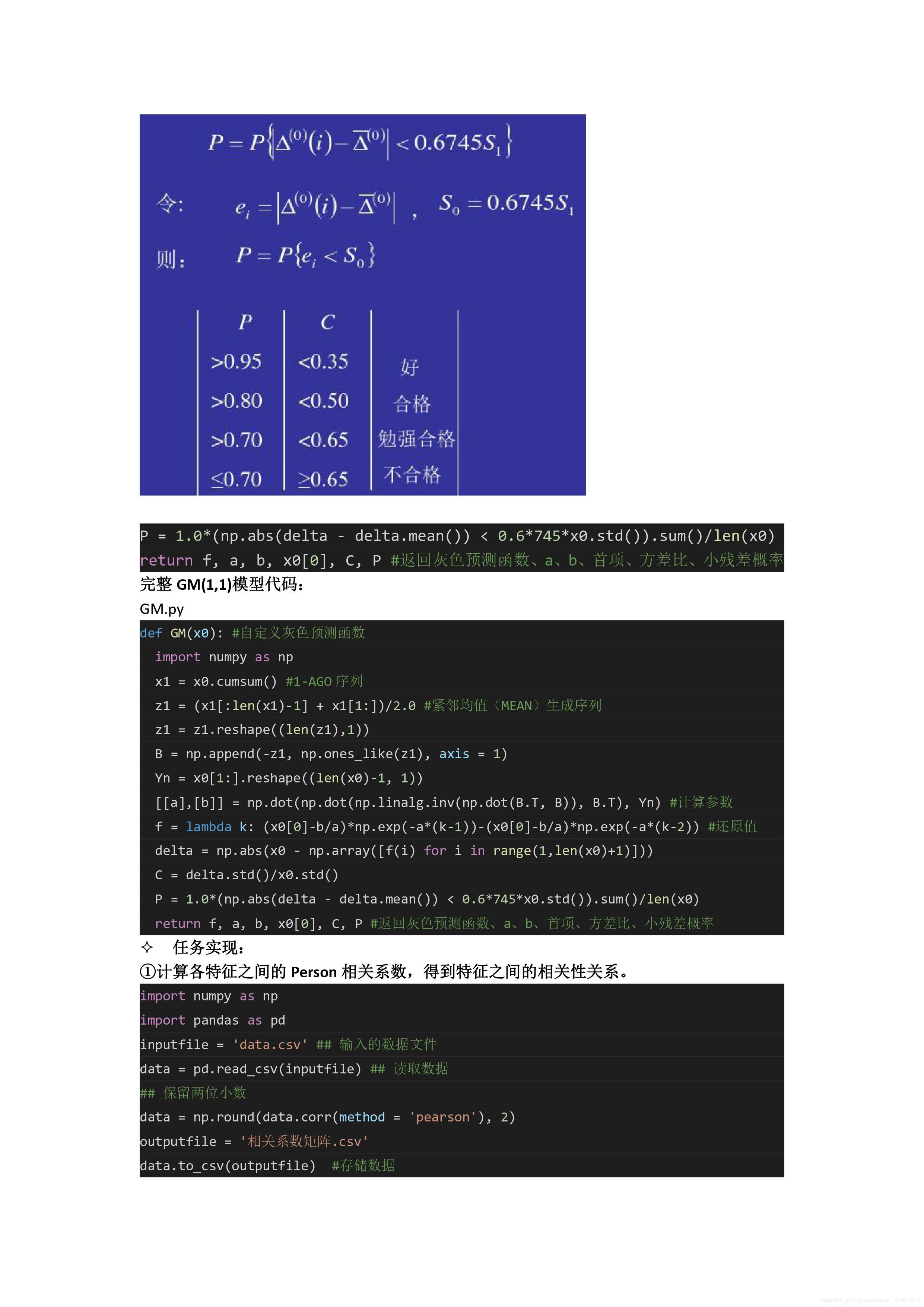
P = 1.0*(np.abs(delta - delta.mean()) < 0.6*745*x0.std()).sum()/len(x0)
return f, a, b, x0[0], C, P #返回灰色预测函数、a、b、首项、方差比、小残差概率#pearson相关系数
import numpy as np
import pandas as pd
inputfile = 'data.csv' ## 输入的数据文件
data = pd.read_csv(inputfile) ## 读取数据
## 保留两位小数
# print('相关系数矩阵为:',np.round(data.corr(method = 'pearson'), 2))
data = np.round(data.corr(method = 'pearson'), 2)
outputfile = '相关系数矩阵.csv'
data.to_csv(outputfile) #存储数据
#查看正相关和负相关
data.sort_values(by=['y'],ascending=False,inplace=True)
data.reset_index(drop = True)
print(data['y'])#使用Lasso回归选取财政收入预测的关键特征
# 代码 8-2
import numpy as np
import pandas as pd
from sklearn.linear_model import Lasso
inputfile = 'data.csv' #输入的数据文件
data = pd.read_csv(inputfile) #读取数据
lasso = Lasso(1000) #调用Lasso()函数,设置λ的值为1000
lasso.fit(data.iloc[:,0:13],data['y'])
print('相关系数为:',np.round(lasso.coef_,5)) #输出结果,保留五位小数
## 计算相关系数非零的个数
print('相关系数非零个数为:',np.sum(lasso.coef_ != 0))
mask = lasso.coef_ != 0 #返回一个相关系数是否为零的布尔数组
print('相关系数是否为零:',mask)
outputfile = 'new_reg_data.csv' #输出的数据文件
new_reg_data = data.iloc[:, mask] #返回相关系数非零的数据
new_reg_data.to_csv(outputfile) #存储数据
print('输出数据的维度为:',new_reg_data.shape) #查看输出数据的维度#构建灰色预测模型,并预测2014年和2015年的政财收入
import numpy as np
import pandas as pd
from GM import GM #引入自编的灰色预测函数
inputfile = 'new_reg_data.csv' #输入的数据文件
inputfile1 = 'data.csv' #输入的数据文件
new_reg_data = pd.read_csv(inputfile) #读取经过特征选择后的数据
data = pd.read_csv(inputfile1) #读取经过特征选择后的数据
new_reg_data.index = range(1994,2014)
new_reg_data.loc[2014] = None
new_reg_data.loc[2015] = None
l = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13']
for i in l:
#new_reg_data.loc[range(1994,2014),i]获取l(i)的列数据
f = GM(new_reg_data.loc[range(1994,2014),i].as_matrix())[0]
##将2014和2015的预测结果放入new_reg_data的l对应列表里
new_reg_data.loc[2014,i] = f(len(new_reg_data)-1)#2014年预测结果
new_reg_data.loc[2015,i] = f(len(new_reg_data)) ##2015年预测结果
new_reg_data[i] = new_reg_data[i].round(2) ## 保留两位小数
outputfile = 'new_reg_data_GM.xls' ## 灰色预测后保存的路径
y = list(data['y'].values) ## 提取财政收入列,合并至新数据框中
y.extend([np.nan,np.nan])
new_reg_data['y'] = y
new_reg_data.to_excel(outputfile) ## 结果输出
print('预测结果为:',new_reg_data.loc[2014:2015,:]) ##预测结果展示
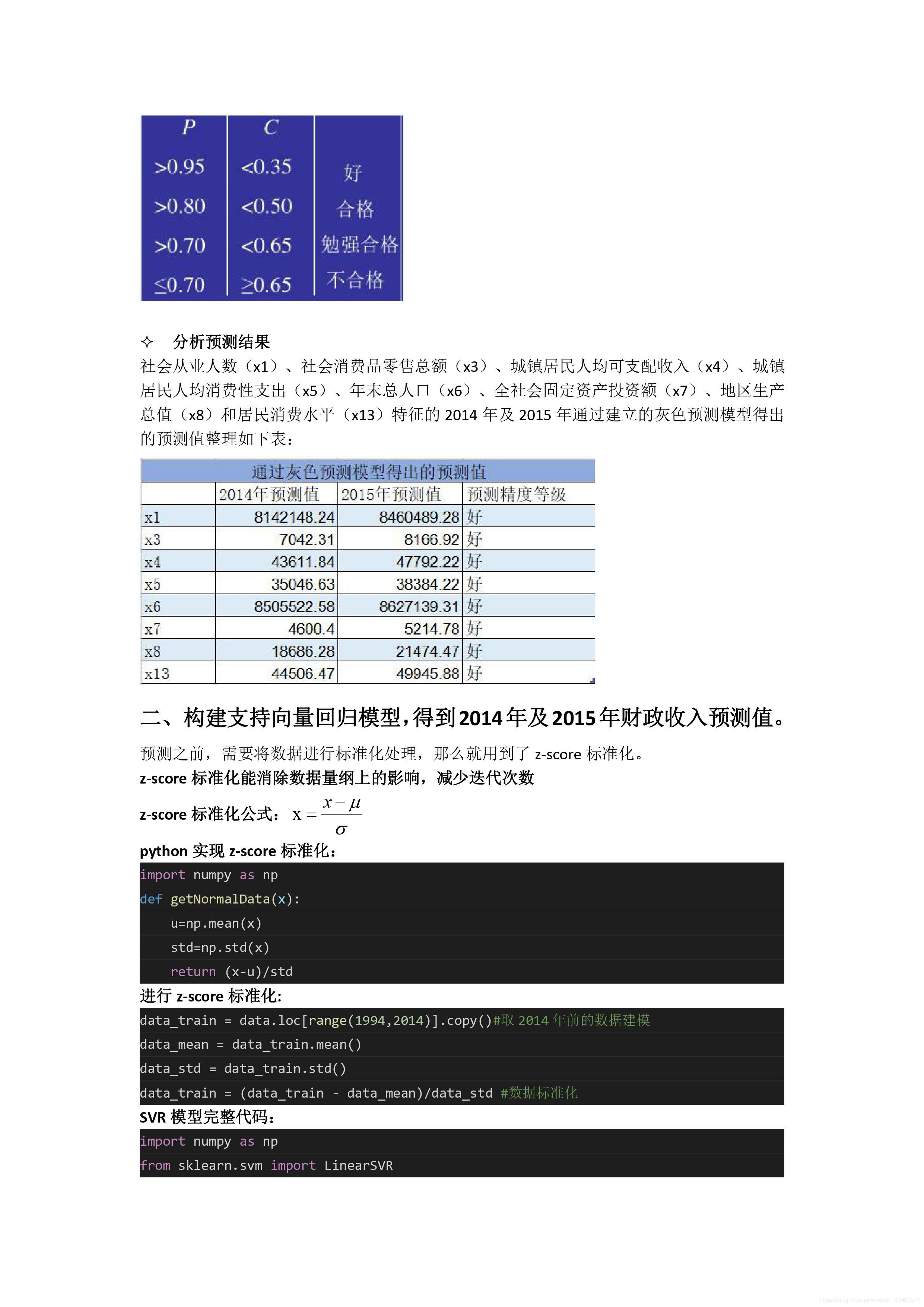
for i in l:
C = GM(new_reg_data.loc[range(1994,2014),i].as_matrix())[4]
p = GM(new_reg_data.loc[range(1994,2014),i].as_matrix())[5]
print(' P C')
print(i,p,C)
import numpy as np
from sklearn.svm import LinearSVR
import matplotlib.pyplot as plt
inputfile = 'new_reg_data_GM11.xls' #灰色预测后保存的路径
data = pd.read_excel(inputfile) #读取数据
data.index = range(1994,2016)
feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13']
data_train = data.loc[range(1994,2014)].copy()#取2014年前的数据建模
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean)/data_std #数据标准化
x_train = data_train[feature].as_matrix() #特征数据
y_train = data_train['y'].as_matrix() #标签数据
linearsvr = LinearSVR() #调用LinearSVR()函数
linearsvr.fit(x_train,y_train)
x = ((data[feature] - data_mean[feature])/ \
data_std[feature]).as_matrix() #预测,并还原结果。
data[u'y_pred'] = linearsvr.predict(x) * \
data_std['y'] + data_mean['y']
## SVR预测后保存的结果
outputfile = 'new_reg_data_GM11_revenue.xls'
data.to_excel(outputfile)
print('真实值与预测值分别为:',data[['y','y_pred']])
print('预测图为:',data[['y','y_pred']].plot(subplots = True,
style=['b-o','r-*']))#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
功能:计算回归分析模型中常用的四大评价指标
'''
from sklearn.metrics import explained_variance_score, mean_absolute_error, median_absolute_error, r2_score
def calPerformance(y_true,y_pred):
'''
模型效果指标评估
y_true:真实的数据值
y_pred:回归模型预测的数据值
explained_variance_score:解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量
的方差变化,值越小则说明效果越差。
mean_absolute_error:平均绝对误差(Mean Absolute Error,MAE),用于评估预测结果和真实数据集的接近程度的程度
,其其值越小说明拟合效果越好。
r2_score:判定系数,其含义是也是解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因
变量的方差变化,值越小则说明效果越差。
'''
model_metrics_name=[mean_absolute_error, median_absolute_error,explained_variance_score, r2_score]
tmp_list=[]
for one in model_metrics_name:
tmp_score=one(y_true,y_pred)
tmp_list.append(tmp_score)
print(['mean_absolute_error','median_absolute_error','explained_variance_score','r2_score'])
print(tmp_list)
return tmp_list
if __name__=='__main__':
inputfile = 'predict_data.csv' #输入的数据文件
data = pd.read_csv(inputfile)
data.drop(data[np.isnan(data['y'])].index, inplace=True)
y_pred = data['y_pred']
y_true = data['y']
calPerformance(y_true,y_pred)















 2336
2336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











