







阿里的集群数据分析的资料比较少,所以我在学习的同时也记录一下学习过程。
集群数据数据下载,以及介绍地址:https://github.com/alibaba/clusterdata/blob/v2018/cluster-trace-v2018/trace_2018.md
每个文件的大概内容:
- machine_meta.csv:机器的元信息和事件信息。
- machine_usage.csv:每台机器的资源使用情况。
- container_meta.csv:容器的元信息和事件信息。
- container_usage.csv:每个容器的资源使用情况。
- batch_instance.csv:有关批处理工作负载中实例的信息。
- batch_task.csv:有关批处理工作负载中实例的信息。请注意,task_name字段中描述了每个作业任务的DAG信息。
一开始我首先对批处理工作中的任务进行初步的分析:
有关批处理工作的表格中的属性如下所示,其中task_name所写的名字则隐含了DAG有向无环图的信息。
- batch_task.csv
| 列名 | 类型 | 解释 | 评论 |
|---|---|---|---|
| task_name | 字符串 | 任务实例所属的名字 | 注意任务名称表明DAG的信息,请参见批处理工作负载的解释 |
| inst_num | int | 的实例数量的任务 | |
| task_type | 枚举 | 类型的任务 | |
| job_name | 字符串 | job_name任务 | |
| 状态 | 枚举 | 一个实例的状态 | 任务的状态 |
| start_time | int | 开始时间的一个实例 | 0意味着时间戳之前或之后的八天时间跨度 |
| end_time | int | 结束时间的一个实例 | 0意味着时间戳之前或之后的八天时间跨度 |
| plan_cpu | int | cpu的要求为每个实例的任务 | 100意味着核心 |
| plan_mem | int | 规范化的内存请求的每个实例的任务 | 标准化的最大内存大小的机器 |
完整的批处理计算作业可以使用“job-task-instance”模型进行描述。 我们将描述每个术语的意义和如何表达的DAG信息跟踪。
这里的一个Job是由几个task组成的,而每个task又是由许多instance组成的,这里注意一下阿里的数据和google的数据不一样,google的数据的最小处理单位是task,而阿里的则是instance。根据同一个Job里面,我们是可以根据task_name来分析出这个Job的DAG图的。
作业通常由若干任务组成,其依赖性由DAG(有向无环图)表示。每个任务都有许多实例,并且只有当任务的所有实例都完成后才能将任务视为“已完成”,即如果任务-2依赖于任务-1,则任务2的任何实例都无法启动在任务-1的所有实例完成之前。作业中的任务DAG可以从task_name该作业的所有任务的字段中推断出来,并通过以下示例进行说明。
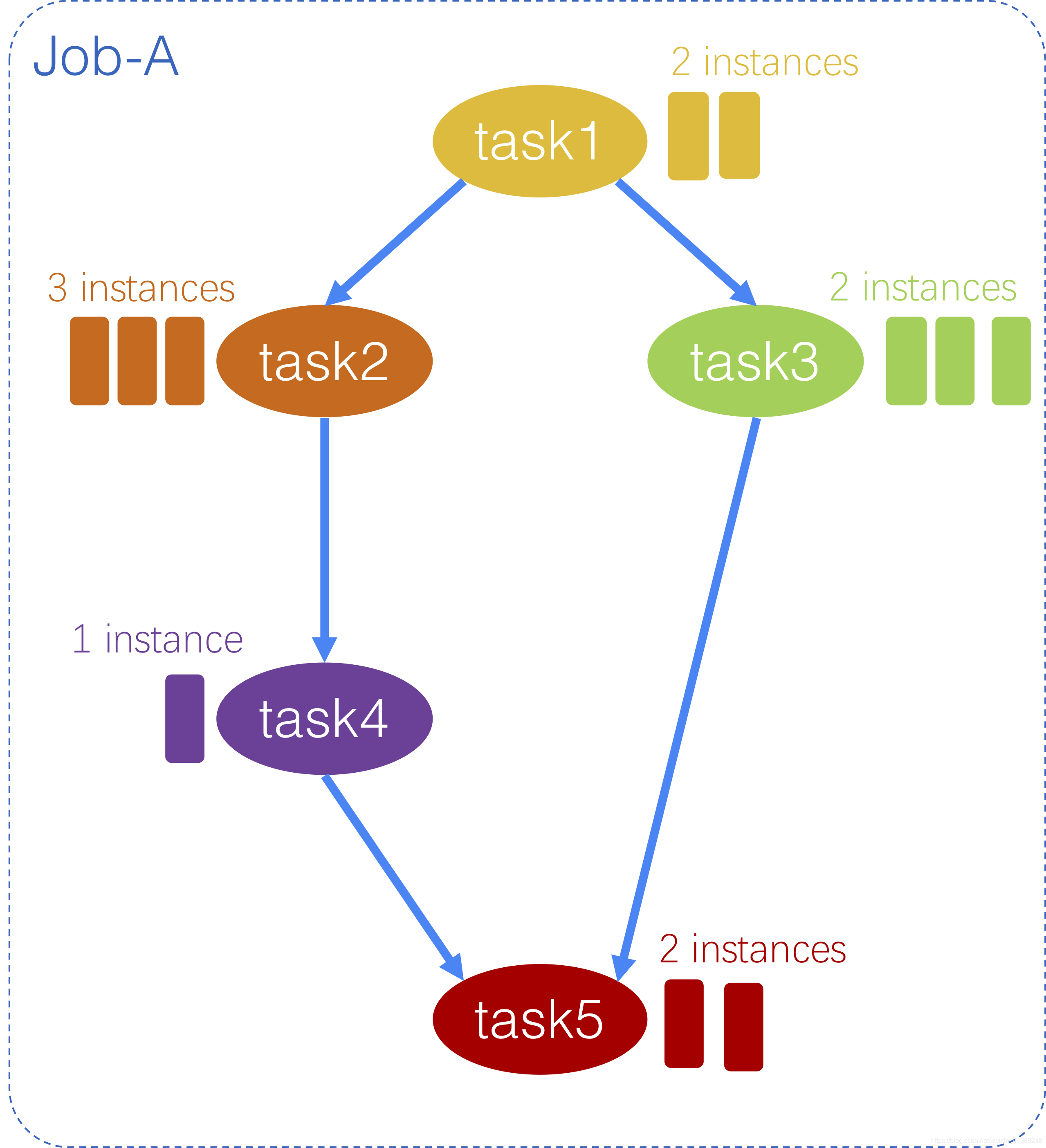
Job-A的DAG如下图所示。Job-A由5个具有一些依赖性的任务组成。5个任务的DAG用它们表示task_name。对于每项任务:
task1的task_name是M1:意味着task1是一个独立的任务,可以在不等待任何其他任务开始。同样的休息M2_1:意味着task2取决于完成task1M3_1:意味着task3取决于完成task1R4_2:意味着task4取决于完成task2M5_3_4:意味着task5依赖于两个task3和task4,也就是说,task5既可以的所有实例之前不会启动task3和task4完成。
请注意,对于DAG信息,只有task_name中的数字值很重要,而第一个字符(例如M,R在示例中)与依赖关系无关。
每个任务的实例数用另一个字段表示instance_num。
明白了这个之后,第一步就是把清洗一下这个数据,对于本来的数据来说,里面有太多杂乱的东西了,而且无用的列也无需保留着。这里提供一下我自己使用python清洗的代码。
import pandas as pd
index_name=['task_name', 'inst_num', 'job_name', 'task_type', 'status', 'start_time', 'end_time' , 'plan_cpu', 'plan_mem']
df = pd.read_csv('F:/aliyun cluster data/batch_task/batch_task.csv', header=None, names=index_name)
# 只获取task_name和job_name
df2=df[['task_name', 'job_name']]
# 方法二:直接按列名删除
# df2 = df.drop(['task_name', 'job_name'], axis=1)
# 获取task_name中包含task和MergeTask字符的布尔值,并取反。然后获得不是单独任务的task
booltask = ~df2['task_name'].str.contains('task|MergeTask')
df2 = df2[booltask]
print(df2.head(50))
# 把清洗出来的数据保存起来,index=0不保留行索引 ,head=None不保存列名
df2.to_csv('F:/aliyun cluster data/batch_task/DAGAnalysis.csv', mode='a', header=None, index=0)
整理出来的文件从原来的700多M编程了178M,读取速度快了许多。而里面的数据变成如下:
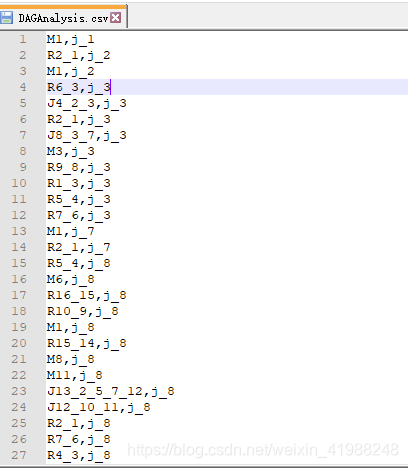
接下来就是画图了,使用matplotlib和networkx来生成DAG图,查看任务的依赖情况。Python代码如下:
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
index_name = ['task_name', 'job_name']
df = pd.read_csv('G:/Administrator/Desktop/阿里集群分析/batch_task', header=None, names=index_name)
# 分组
# grouped = df.groupby('job_name')
# 分组后每小组的数量
# grouped = df.groupby(['job_name']).size()
# 对分组进行迭代
for name, group in df.groupby('job_name'):
G = nx.DiGraph() # 建立一个有向空图
task_nameList = list(group['task_name'])
# 遍历task_name
for x in task_nameList:
# 删除第一个字符
strlist = x.replace(x[0], "")
numlist = strlist.split('_')
start =numlist[0]
del numlist[0]
G.add_node(start)
for y in numlist:
G.add_edge(y, start)
# print('边关系:')
# print(y+'->'+start)
nx.draw(G, cmap=plt.get_cmap('jet'), with_labels=True, font_weight='bold')
plt.savefig("F:/aliyun cluster data/DAG/"+name+".png", format="png")
# plt.show()
# 上一次的保存的图片会有重叠,需要清除一下缓存
plt.close()
G.clear()
# print(task_nameList)
print(name)
# print(group)
然后就可以看到每个Job里task的依赖关系了。
效果如下:
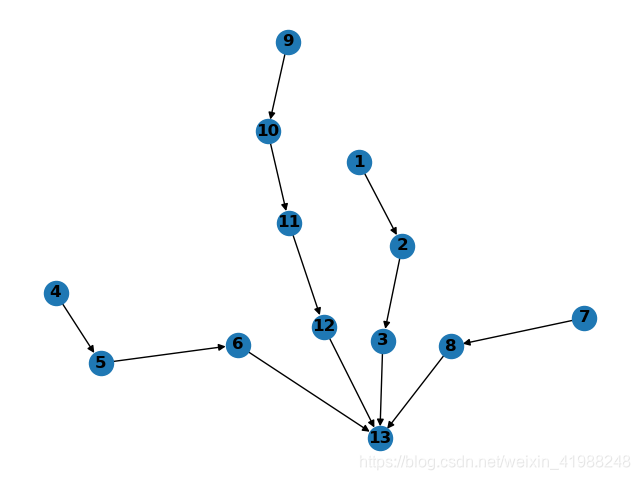
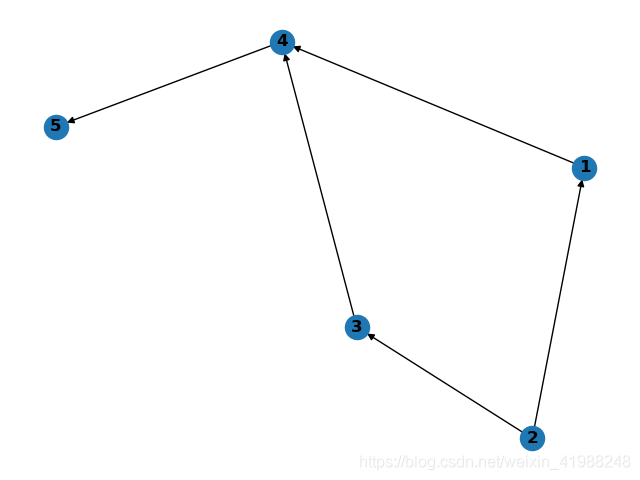
可能我的方法有点笨,这一是我自己记录的一个过程,如有错误,希望能指出来哈。

















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









