







前言
大一统模型目前越来越火,不论是今天要给大家介绍的信息抽取统一模型,还是再往大了说多模态统一模型,理论上来说这个idea的出发点还是不错的,在理想情况下,他可以将很多任务建模到同一个模型,使得任务之间可以相互增益,而且另外一个好处就是既然统一到同一个模型了,那么各个任务的数据集都可以使用,一块丢进去进行学习,数据量剧增。
今天要介绍的这篇paper是对文本的信息抽取任务进行统一模型设计,关于多模态数据集的统一模型,大家感兴趣的话可以看笔者之前的写过的一篇文章:
废话不多说,开始吧~
论文链接:https://arxiv.org/pdf/2203.12277.pdf
要解决什么问题?
在进行模型设计之前,首先要明确到底我们要解决什么问题?为此先来看看信息抽取任务有哪些?论文给出了一个总结如下:
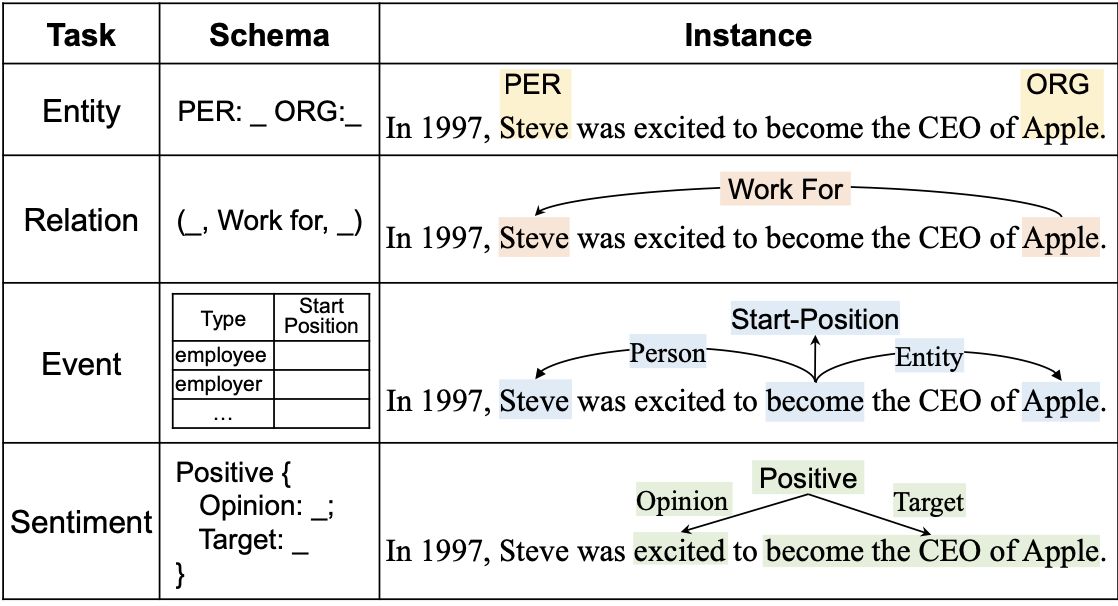
大体上有四类:实体抽取、关系抽取、事件抽取以及情感分类。
可以看到信息抽取本质上是一个text-to-structure任务,不同类型的任务有不同类型的structures ,而我们的出发点又是统一这些任务,那很显然其实就是怎么统一这些不同的structures,说的再具体点就是给一个预先准备好的schema s和texts x,模型要能够输出我们想要的structural信息。
接下来我们再将这个问题进一步具体化来看看,我们到底要解决什么问题?
不同的任务的差异无非就体现在两个方面:数据输入形式和输出形式。
只要我们能够把不同任务的输入和输出统一化了,那这个问题就算done了,用一点术语的话,输入形式其实就是paper说的schemas ,输出形式其实就是paper说的target structures 。
好了,现在比较清晰我们的问题所在了,接下来就是去怎么具体设计解决了,整体上述两个问题,作者分别提出SSI和SEL 方法。下面我们具体看看吧。
SEL
就如上面所说,这里要解决的问题是:统一不同任务的输出形式。为此作者设计了如下方案:

图(a)就是设计的模版,spot name是类型,比如实体类型,asso name是关系类型,而info span就是对应的在原文text的span文本。
有了这样的设计就可以解析任何信息抽取的任务了,具体的case可以看图(b)给的一个例子,蓝色就是实体关系抽取,红色是事件抽取,黑色是实体抽取。可以看到不论是关系抽取还是事件抽取就是不断的在()里面再套子括号,里面抽取的内容包括关系类型和关系触发词。
SSI
这里要解决的问题是统一输入,因为不同的任务需要的输出是不同的(如上所述),所以我们要在输入端给一些提示,进而告诉模型我们当前需要什么样的输出。

具体是怎么样的提示呢?看上图一目了然, [spot] 是实体提示符,[asso] 是关系提示符, [text] 是原文提示符。可以看到主要根据 [spot] 和 [asso] 的搭配样式来决定当前的任务类型。
效果
在各个数据集上都是sota

更多的实验效果以及消融实验大家感兴趣可以去看paper
总结
(1) 大一统这个idea总体上感觉还是work的,方向不错,大家在做别的方向时候可以往这方面思考思考,尤其是同一类任务一般来说会有增益。
(2) 信息抽取可以说NLP最常见的任务了,也是应用最广的能力,多跟进一些相关的最新研究还是挺好的。
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:














 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









