







 本文探讨了如何通过迁移学习中的域自适应技术解决测试集过拟合问题。介绍样本自适应、特征自适应和模型自适应三种策略,以及它们在减少源域和目标域分布差异上的应用。重点讲解了如何通过加权采样、特征提取网络和模型结构调整来适应不同数据集。
本文探讨了如何通过迁移学习中的域自适应技术解决测试集过拟合问题。介绍样本自适应、特征自适应和模型自适应三种策略,以及它们在减少源域和目标域分布差异上的应用。重点讲解了如何通过加权采样、特征提取网络和模型结构调整来适应不同数据集。
1.导语
在真实的机器学习项目中,我们的训练数据集与测试数据集之间是存在一定数据分布差异的,这个时候往往模型会出现过拟合的情况,模型在测试集上的效果不是很理想。
那怎么样在不改变数据集的情况下,提升测试集准确率呢。这个时候就有了迁移学习的一种代表方法,域自适应(Domain adaptation)。
另外在迁移学习中又分样本迁移、特征迁移和模型迁移,其中模型迁移学习与fine-tune(微调)有一些不同的地方:
虽然二者都是利用训练过的模型来解决问题,但实际上存在一些差异:
- fine-tune(微调):是对已经训练好的模型,把整个这个模型放到另一个数据集上继续进行训练(其中参数继续发生变化)
- 迁移学习:提取模型中所需要的部分层,对这些层进行冻结(固定层的参数)在冻结层后增加新的训练层,最后完成训练。
fine-tune是继续更新模型的参数,迁移学习是固定一部分参数,训练更新一部分参数。
2.Domain adaptation
域自适应方法,通常表示域不同,但任务相同的方法,这里域代表一个数据集的集合。
什么样子的域(数据集),可以适合来做域自适应呢
通常我们的源域(与测试样本不同的数据集,也可以说是训练集)数据集有标签,目标域数据(测试集)没有标签或者很少数据有标签
2.1 Domain adaptation思路
定义源域(训练集):source
定义目标域(测试集):target
主要的思路就是将source训练好的模型能够用在target上,域适配问题最主要的就是如何减少source和target不同分布之间的差异。域适配包括无监督域适配和半监督域适配,前者的target是完全没有label的,后者的target有部分的label,但是数量非常的少
通过在不同阶段进行领域自适应,研究者提出了三种不同的领域自适应方法:
- 样本自适应:对源域样本进行加权重采样,从而逼近目标域的分布。
- 特征层面自适应:将源域和目标域投影到公共特征子空间。
- 模型层面自适应:对源域误差函数进行修改,考虑目标域的误差。
2.2 样本自适应
样本自适应也可以说是样本迁移。
基本思想:
- 通过对source,进行重采样,在source里找到与target相似的数据,命这些相似数据为新的source。
- 把source数据的数据量,量权值进行调整,使其这些数据与target数据分布基本一致,如下图所示:

也可以对source的数据集进行数据增强,在图像中,可以对图像进行旋转,缩放,白噪声等。
优点缺点:
- 优点:方法简单,容易
- 缺点:权重选择与数据相似度衡量标准难定
2.3 特征自适应
特征自适应也可以说是特征迁移,
基本思路:
通过构建特征提取网络,训练网络模型,使模型能够提取出source与target的共同特征部分,相似的数据分布。如下图所示,我们输入source和target数据集
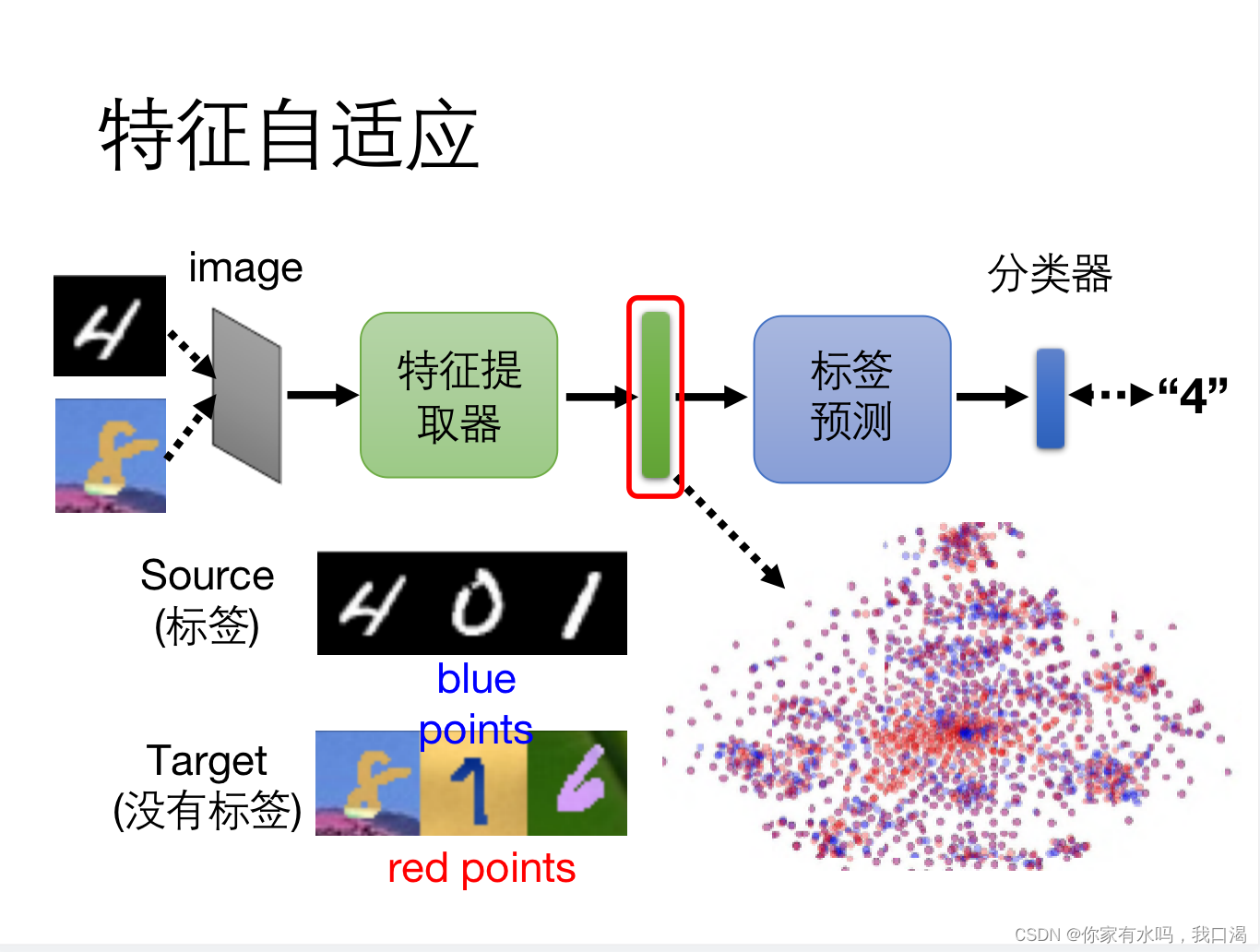
最后得到的特征数据分布相似。
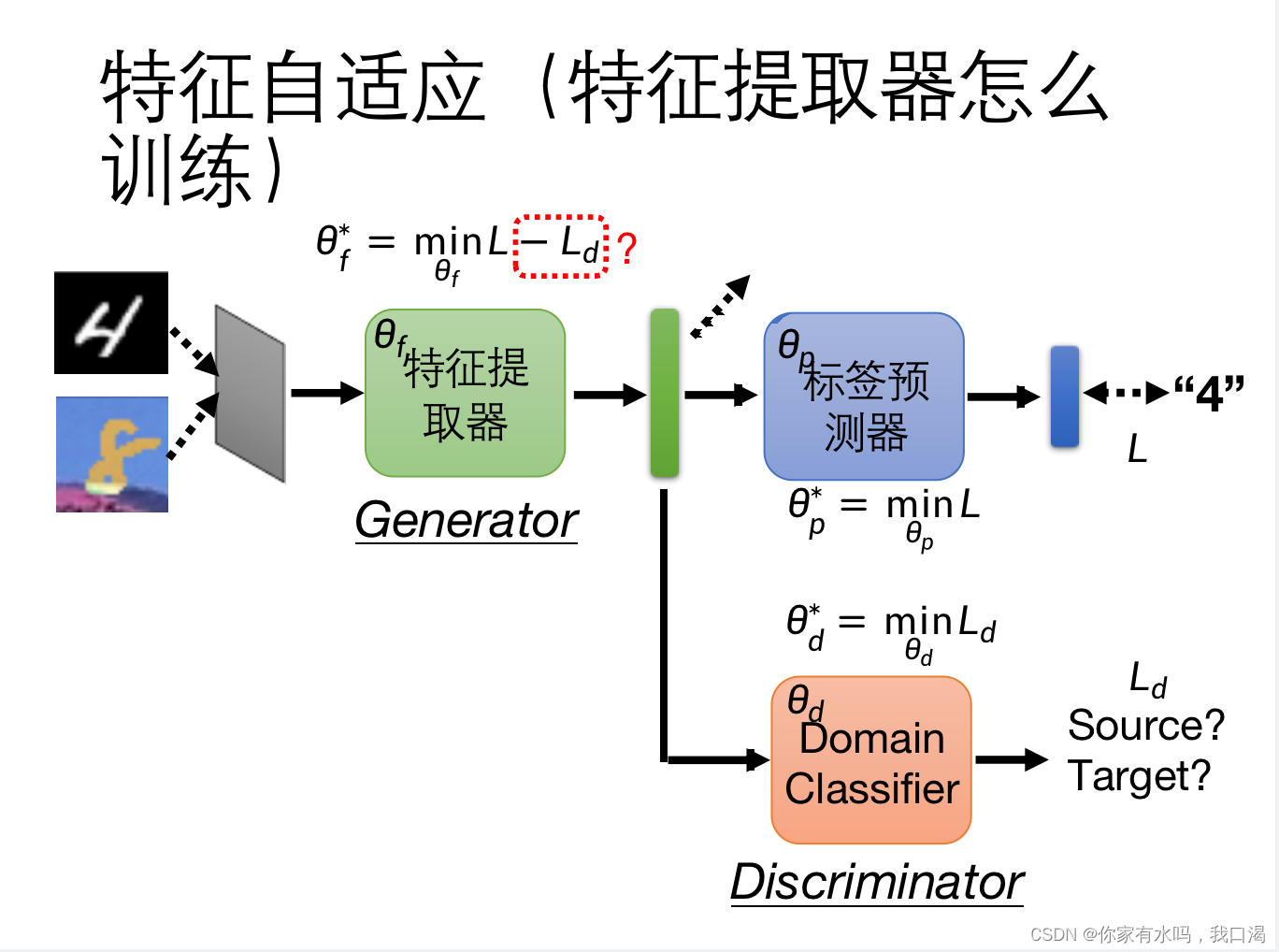
如上图,特征提取器可以看成GAN中的generator,domain classifier就是GAN中的discriminator,我们的目的,就是找到一个特征提取器,能够使训练集与测试集的特征分布,几乎一样的,可以骗过domain classifier。
这里的提取器要做的是让生成的特征难以分辨出(也就是说让训练集和测试集的特征很相似),classifier是要努力分辨他们(我们通过classifier的反馈,进一步优化提取器),这样才能让提取器更好工作,我们最后要的是提取器。
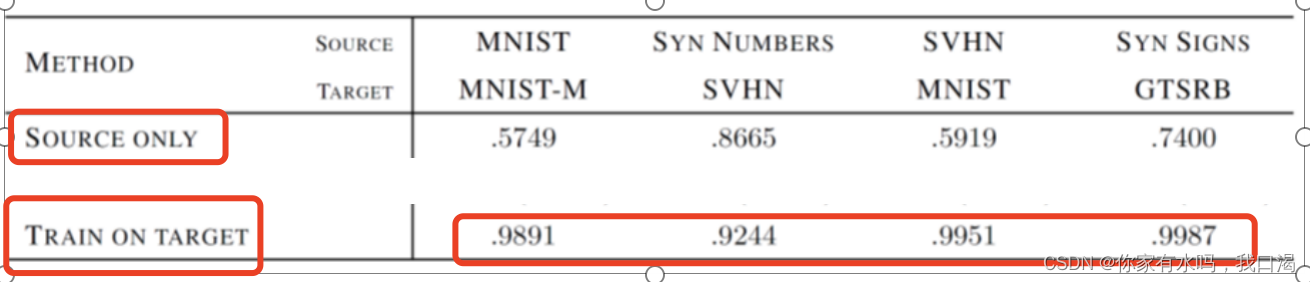
下图为不同source和target数据集下,只有source和加入了target训练下的结果。
优缺点:
- 优点:大多数方法适用
- 缺点:在于难于求解,容易发生过适配
2.4 模型自适应
模型自适应就是最常用的迁移学习方式,模型迁移。
基本思想:
- 通过已经训练好的模型,将模型放入到一个新的领域数据集中训练
- 固定住模型部分层(不改变层的结构,以及参数)
- 更改部分模型层,(初始化这些层的参数,可能也会改变层的结构)
- 训练模型
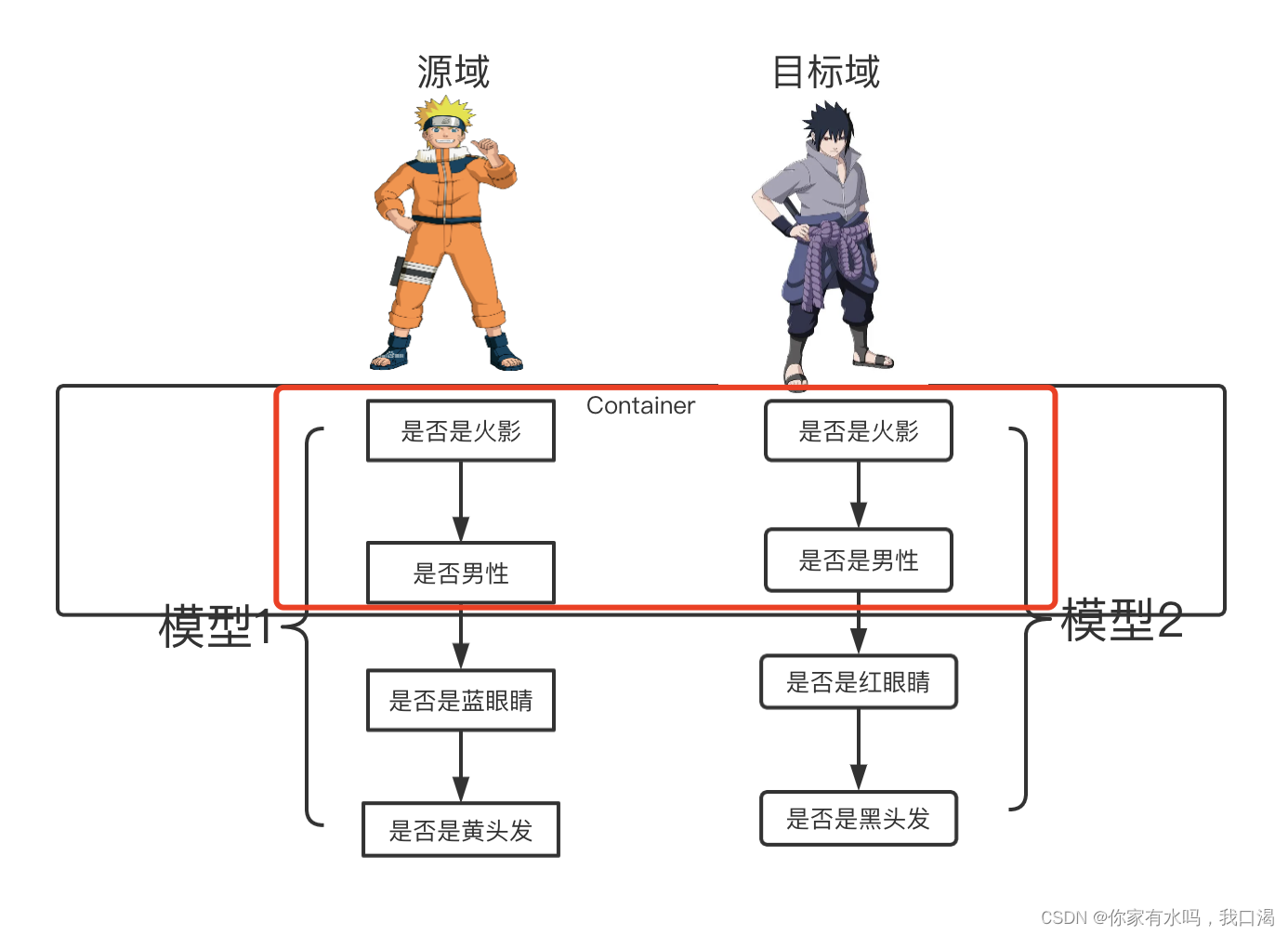
如下图案例一样,模型2固定住了模型1前二层的“是否是火影”,“是否是男性”的层和参数,我们在模型2中改变了模型1后二层的层和参数,模型2就可以完成识别是不是“傻死给”的模型。


















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











