








etcd 集群中的多个节点不可避免地会出现相互之间数据不一致的情况。但不管是同步复制、异步复制还是半同步复制,都会存在可用性或者一致性的问题。我们一般会使用共识算法来解决多个节点数据一致性的问题,常见的共识算法有 Paxos和Raft。ZooKeeper 使用的是 ZAB 协议,etcd 使用的共识算法就是Raft。
etcd raft模块 对外提供的接口
raft模块中的主要对象是节点。
可以使用 raft.StartNode 创建新的Node节点 ,也可以使用 raft.RestartNode 从某种初始状态创建新Node节点。
在raft/node.go中定义了Node接口
// Node represents a node in a raft cluster.
type Node interface {
//时钟,触发选举或者发送心跳
Tick()
Campaign(ctx context.Context) error
//通过 channel 向 raft StateMachine 提交一个 Op,提交的是本地 MsgProp 类型的消息;
Propose(ctx context.Context, data []byte) error
ProposeConfChange(ctx context.Context, cc pb.ConfChangeI) error
//节点收到 Peer 节点发送的 Msg 时会通过该接口提交给 raft 状态机,Step 接口通过 recvc channel向raft StateMachine 传递 Msg;
Step(ctx context.Context, msg pb.Message) error
//该接口将返回类型为 Ready 的 channel,该通道表示当前时间点的channel。应用层需要关注该 channel,当发生变更时,其中的数据也将会进行相应的操作
Ready() <-chan Ready
Advance()
ApplyConfChange(cc pb.ConfChangeI) *pb.ConfState
TransferLeadership(ctx context.Context, lead, transferee uint64)
ReadIndex(ctx context.Context, rctx []byte) error
Status() Status
ReportUnreachable(id uint64)
ReportSnapshot(id uint64, status SnapshotStatus)
Stop()
}raft 模块中node 结构体实现了 Node 接口:
// node is the canonical implementation of the Node interface
type node struct {
propc chan msgWithResult
recvc chan pb.Message
confc chan pb.ConfChangeV2
confstatec chan pb.ConfState
readyc chan Ready
advancec chan struct{}
tickc chan struct{}
done chan struct{}
stop chan struct{}
status chan chan Status
rn *RawNode
}在 raft/raft.go 中还有两个核心数据结构:
-
Config,封装了与 raft 算法相关的配置参数,公开用于外部调用。
-
raft,具体实现 raft 算法的结构体。
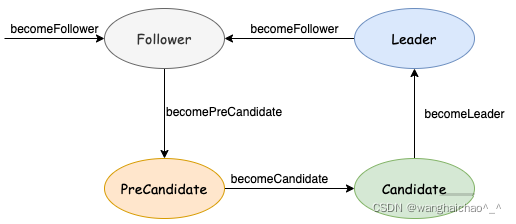
节点状态
raft StateMachine 的状态机转换,实际上就是 raft 算法中各种角色的转换。每个 raft 节点,可能具有以下三种状态中的一种:
-
Candidate:候选人状态,该状态意味着将进行一次新的选举。
-
Follower:跟随者状态,该状态意味着选举结束。
-
Leader:领导者状态,选举出来的节点,所有数据提交都必须先提交到 Leader 上。
每一个状态都有其对应的状态机,每次收到一条提交的数据时,都会根据其不同的状态将消息输入到不同状态的状态机中。同时,在进行 tick 操作时,每种状态对应的处理函数也是不一样的。
因此 raft 结构体中将不同的状态及其不同的处理函数,独立出来几个成员变量:
-
state,保存当前节点状态;
-
tick 函数,每个状态对应的 tick 函数不同;
-
step,状态机函数,同样每个状态对应的状态机也不相同。
etcd-raft StateMachine 封装在 raft机构体中,其状态转换如下图:
raft 状态转换的接口都在 raft.go 中,其定义如下:
func (r *raft) becomeFollower(term uint64, lead uint64) {
r.step = stepFollower
r.reset(term)
r.tick = r.tickElection
r.lead = lead
r.state = StateFollower
r.logger.Infof("%x became follower at term %d", r.id, r.Term)
}
func (r *raft) becomeCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> candidate]")
}
r.step = stepCandidate
r.reset(r.Term + 1)
r.tick = r.tickElection
r.Vote = r.id
r.state = StateCandidate
r.logger.Infof("%x became candidate at term %d", r.id, r.Term)
}
func (r *raft) becomePreCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> pre-candidate]")
}
// Becoming a pre-candidate changes our step functions and state,
// but doesn't change anything else. In particular it does not increase
// r.Term or change r.Vote.
r.step = stepCandidate
r.prs.ResetVotes()
r.tick = r.tickElection
r.lead = None
r.state = StatePreCandidate
r.logger.Infof("%x became pre-candidate at term %d", r.id, r.Term)
}
func (r *raft) becomeLeader() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateFollower {
panic("invalid transition [follower -> leader]")
}
r.step = stepLeader
r.reset(r.Term)
r.tick = r.tickHeartbeat
r.lead = r.id
r.state = StateLeader
// Followers enter replicate mode when they've been successfully probed
// (perhaps after having received a snapshot as a result). The leader is
// trivially in this state. Note that r.reset() has initialized this
// progress with the last index already.
r.prs.Progress[r.id].BecomeReplicate()
// Conservatively set the pendingConfIndex to the last index in the
// log. There may or may not be a pending config change, but it's
// safe to delay any future proposals until we commit all our
// pending log entries, and scanning the entire tail of the log
// could be expensive.
r.pendingConfIndex = r.raftLog.lastIndex()
emptyEnt := pb.Entry{Data: nil}
if !r.appendEntry(emptyEnt) {
// This won't happen because we just called reset() above.
r.logger.Panic("empty entry was dropped")
}
// As a special case, don't count the initial empty entry towards the
// uncommitted log quota. This is because we want to preserve the
// behavior of allowing one entry larger than quota if the current
// usage is zero.
r.reduceUncommittedSize([]pb.Entry{emptyEnt})
r.logger.Infof("%x became leader at term %d", r.id, r.Term)
}raft 在不同的状态下,是如何驱动 raft StateMachine 状态机运转的呢?答案是etcd 将 raft 相关的所有处理都抽象为了 Msg,通过 Step 接口处理:
func (r *raft) Step(m pb.Message) error {``
r.step(r, m)
}这里的step是一个回调函数,根据不同的状态会设置不同的回调函数来驱动 raft,这个回调函数 stepFunc 就是在becomeXX()函数完成的设置:
type raft struct {
...
step stepFunc
}
step 回调函数有如下几个值,注意其中 stepCandidate 会处理 PreCandidate 和 Candidate 两种状态:
func stepFollower(r *raft, m pb.Message) error
func stepCandidate(r *raft, m pb.Message) error
func stepLeader(r *raft, m pb.Message) errorraft 消息
raft 算法本质上是一个大的状态机,任何的操作例如选举、提交数据等,最后都被封装成一个消息结构体,输入到 raft 算法库的状态机中。
在 raft/raftpb/raft.proto 文件中,定义了 raft 算法中传输消息的结构体。raft 算法其实由好几个协议组成,etcd-raft 将其统一定义在了 Message 结构体之中,以下总结了该结构体的成员用途:
type Message struct {
Type MessageType `protobuf:"varint,1,opt,name=type,enum=raftpb.MessageType" json:"type"`
To uint64 `protobuf:"varint,2,opt,name=to" json:"to"`
From uint64 `protobuf:"varint,3,opt,name=from" json:"from"`
Term uint64 `protobuf:"varint,4,opt,name=term" json:"term"`
// logTerm is generally used for appending Raft logs to followers. For example,
// (type=MsgApp,index=100,logTerm=5) means leader appends entries starting at
// index=101, and the term of entry at index 100 is 5.
// (type=MsgAppResp,reject=true,index=100,logTerm=5) means follower rejects some
// entries from its leader as it already has an entry with term 5 at index 100.
LogTerm uint64 `protobuf:"varint,5,opt,name=logTerm" json:"logTerm"`
Index uint64 `protobuf:"varint,6,opt,name=index" json:"index"`
Entries []Entry `protobuf:"bytes,7,rep,name=entries" json:"entries"`
Commit uint64 `protobuf:"varint,8,opt,name=commit" json:"commit"`
Snapshot Snapshot `protobuf:"bytes,9,opt,name=snapshot" json:"snapshot"`
Reject bool `protobuf:"varint,10,opt,name=reject" json:"reject"`
RejectHint uint64 `protobuf:"varint,11,opt,name=rejectHint" json:"rejectHint"`
Context []byte `protobuf:"bytes,12,opt,name=context" json:"context,omitempty"`
}Message结构体相关的数据类型为 MessageType,MessageType 有 19 种。当然,并不是所有的消息类型都会用到上面定义的Message结构体中的所有字段,因此其中有些字段是Optinal的。
常见消息类型:
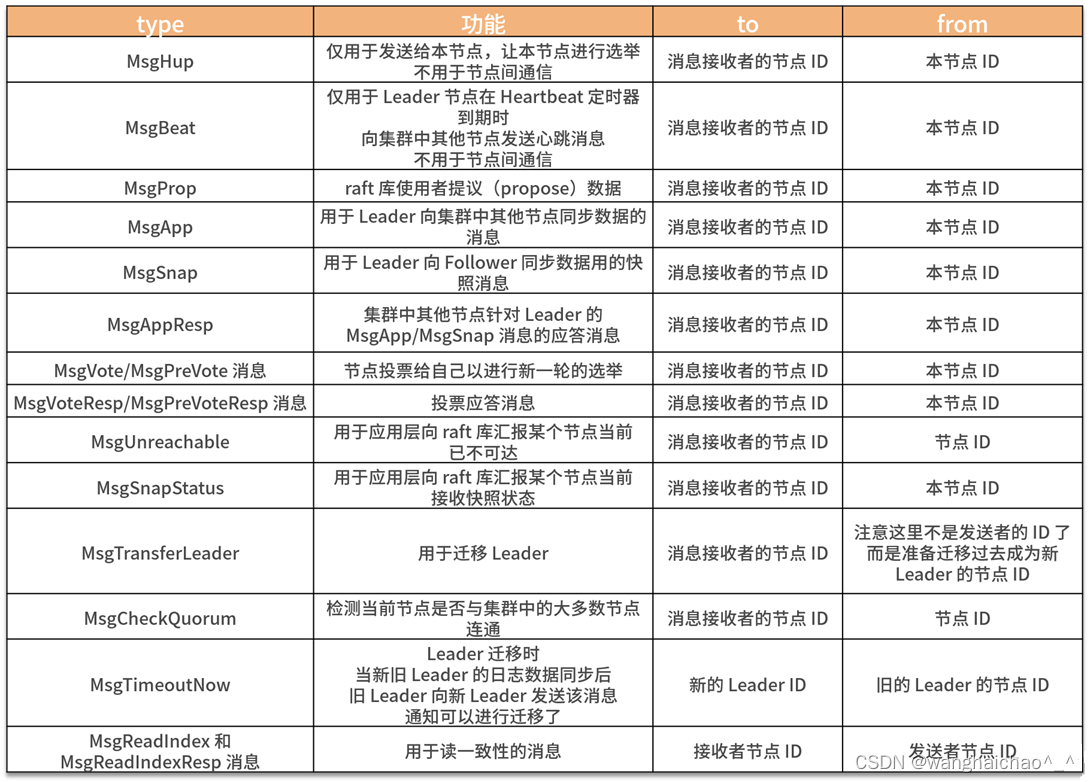
上表列出了消息的类型对应的功能、消息接收者的节点 ID 和消息发送者的节点 ID。在收到消息之后,根据消息类型检索此表,可以帮助我们理解 raft 算法的操作。
选举流程
raft 一致性算法实现的关键有 Leader 选举、日志复制和安全性限制。Leader 故障后集群能快速选出新 Leader,集群只有Leader 能写入日志, Leader 负责复制日志到 Follower 节点,并强制 Follower 节点与自己保持相同。
raft 算法的第一步是选举出 Leader,即使在 Leader 出现故障后也需要快速选出新 Leader,下面我们来梳理一下选举的流程。
发起选举
发起选举对节点的状态有限制,很显然只有在Candidate 或者 Follower 状态下的节点才有可能发起一个选举流程,而这两种状态的节点,其对应的tick 函数为 raft.tickElection 函数,用来发起选举和选举超时控制。发起选举的流程如下:
-
节点启动时都以Follower 启动,同时随机生成自己的选举超时时间。
-
在Follower的tickElection 函数中,当选举超时,节点向自己发送 MsgHup 消息。
-
在状态机函数 raft.Step函数中,收到 MsgHup 消息之后,节点首先判断当前有没有 apply 的配置变更消息,如果有就忽略该消息。
-
否则进入 campaign 函数中进行选举:首先将任期号增加 1,然后广播给其他节点选举消息,带上的其他字段,包括:节点当前的最后一条日志索引(Index 字段)、最后一条日志对应的任期号(LogTerm 字段)、选举任期号(Term 字段,即前面已经进行 +1 之后的任期号)、Context 字段(目的是告知这一次是否是 Leader 转让类需要强制进行选举的消息)。
-
如果在一个选举超时期间内,发起新的选举流程的节点,得到了超过半数的节点投票,那么状态就切换到 Leader 状态。成为 Leader的同时,Leader 将发送一条 dummy 的 append 消息,目的是提交该节点上在此任期之前的值。
在上述流程中,之所以每个节点随机选择自己的超时时间,是为了避免有两个节点同时进行选举,此时没有任何一个节点会赢得半数以上的投票,从而导致这一轮选举失败,继续进行下一轮选举。在第三步,判断是否有 apply 配置变更消息,其原因在于,当有配置更新的情况下不能进行选举操作,即要保证每一次集群成员变化时只能变化一个,不能多个集群成员的状态同时发生变化。
参与选举
当收到任期号大于当前节点任期号的消息,且该消息类型如果是选举类的消息(类型为 prevote 或者 vote)时,节点会做出以下判断。
-
首先判断该消息是否为强制要求进行选举的类型(context 为 campaignTransfer,表示进行 Leader转让)。
-
判断当前是否在租约期内,满足的条件包括:checkQuorum 为 true、当前节点保存的 Leader 不为空、没有到选举超时。
如果不是强制要求选举,且在租约期内,就忽略该选举消息,这样做是为了避免出现那些分裂集群的节点,频繁发起新的选举请求。
-
如果不是忽略选举消息的情况,除非是 prevote 类的选举消息,否则在收到其他消息的情况下,该节点都切换为 Follower 状态。
-
此时需要针对投票类型中带来的其他字段进行处理,同时满足日志新旧的判断和参与选举的条件。
只有在同时满足以上两个条件的情况下,才能同意该节点的选举,否则都会被拒绝。这种做法可以保证最后选出来的新 Leader 节点,其日志都是最新的。
日志复制
选举好 Leader 后,Leader在收到 put 提案时,将提案复制给其他 Follower 流程图:
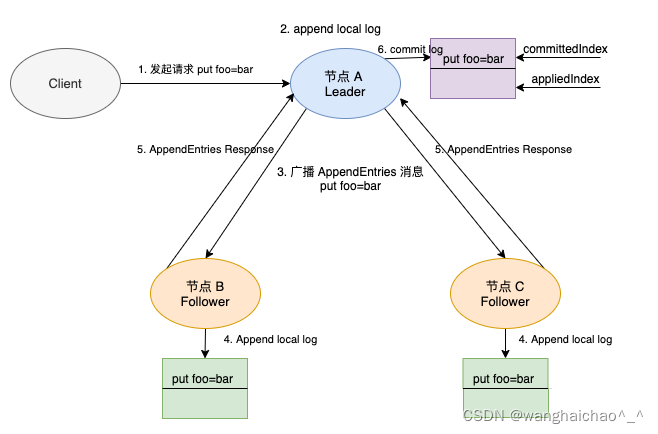
-
收到客户端请求之后,etcd Server 的 KVServer 模块会向 raft 模块提交一个类型为 MsgProp 的提案消息。
-
Leader节点在本地添加一条日志,其对应的命令为
put foo bar。此步骤只是添加一条日志,并没有提交,两个索引值还指向上一条日志。 -
Leader 节点向集群中其他节点广播 AppendEntries 消息,带上 put 命令。
第二步中,两个索引值分别为 committedIndex和appliedIndex,图中有标识。committedIndex 存储最后一条提交日志的索引,而 appliedIndex 存储的是最后一条应用到状态机中的日志索引值。两个数值满足committedIndex 大于等于 appliedIndex,这是因为一条日志只有被提交了才能应用到状态机中。
接下来我们看看 Leader 如何将日志数据复制到 Follower 节点:
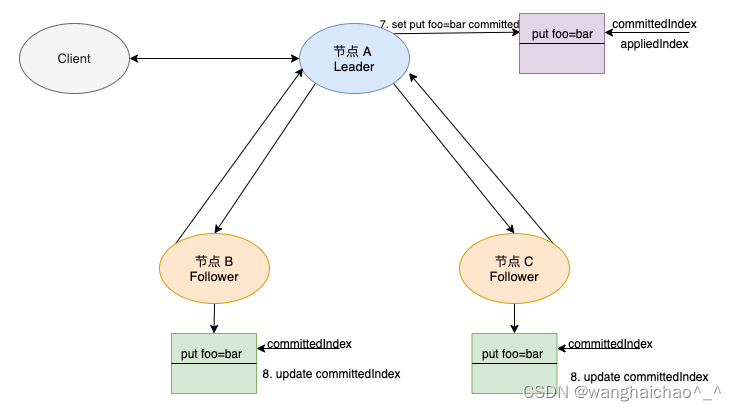
-
Follower 节点收到 AppendEntries 请求后,与 Leader 节点一样,在本地添加一条新的日志,此时日志也没有提交。
-
添加成功日志后,Follower 节点向 Leader 节点应答 AppendEntries 消息。
-
Leader 节点汇总 Follower 节点的应答。当Leader 节点收到半数以上节点的 AppendEntries 请求的应答消息时,表明
put foo bar命令成功复制,可以进行日志提交。 -
Leader 修改本地 committed 日志的索引,指向最新的存储
put foo bar的日志,因为还没有应用该命令到状态机中,所以 appliedIndex 还是保持着上一次的值。
当这个命令提交完成之后,命令就可以提交给应用层了。
-
此时修改 appliedIndex的值,与 committedIndex 的值相等。
-
Leader 节点在后续发送给 Follower 的 AppendEntries 请求中,总会带上最新的 committedIndex 索引值。
-
Follower 收到AppendEntries 后会修改本地日志的 committedIndex 索引。

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









