







PASCAL-VOC2012
- PASCAL-VOC2012数据集介绍官网: 参考
- 数据集下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
VOC2012数据集分为20类,包括背景为21类,分别如下:
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor

这里只说与图像分割(segmentation)有关的信息,VOC2012中的图片并不是都用于分割,用于分割比赛的图片实例如下,包含原图以及图像分类分割和图像物体分割两种png图。图像分类分割是在20种物体中,ground-turth图片上每个物体的轮廓填充都有一个特定的颜色,一共20种颜色,比如摩托车用红色表示,人用绿色表示。而图像物体分割则仅仅在一副图中生成不同物体的轮廓颜色即可,颜色自己随便填充。

VOC2012数据集的代码结构如下:
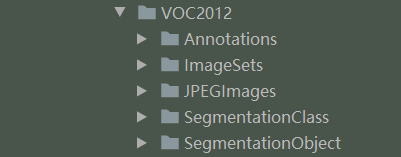
- Annotation中包含了对应图片的xml信息:
我们以下面的2007_000032.jpg为例
其Annotation中对应的xml信息为:
xml信息包含了该图片的基本信息,xml语言很易读,我们从中可以轻易得出这幅图片的一些基本信息,其中segmented一栏为1,这里的意思是这幅图用于分割(因为VOC2012中一共有10000+图,但并不都用于分割任务,有的用以物体标识或者动作识别等),若这一栏为0说明这幅图不是用于图像分割的。例如



- ImageSets中有用的部分为Segmentation文件:
因为VOC2012中的图片并不是都用于分割,所以需要txt文件信息来标记处哪些图片可以用于分割,写程序的时候就可以利用信息 train.txt 对图片进行挑选。train和val中的图片加一起一共2913张图。
- JPEGimages中存放正常样本图片:
JPEGimages则放了我们需要的图片,这些图片一共有17125张,我们并不是都使用,我们仅对train.txt和val.txt中列出的图像进行使用,而其他的图像则用于不同的任务中。

- SegmentationClass中的png图用于图像的语义分割
SegmentationClass中的png图用于图像语义分割,下图中有两类物体,人和飞机,其中飞机和人都对应着特定的颜色,注意该文件夹中的图片为三通道彩色图,与之前单通道的灰度图不同。png图中对物体的分类像素不是0-20,而是对应着不同的RGB分量

- 而SegmentationObject中的png图则不仅仅对图中不同的类别进行的分类,对其同一类别的不同物体也要分割——实例分割:
显然,上面的很多人都被标记了不同的颜色,当然仅仅是为了分离出来。

参考:https://blog.csdn.net/haoji007/article/details/80361587
Cityscapes
- 数据集下载法1(百度云): https://pan.baidu.com/s/108_NgFheDIpnQRrwz5uhmw , 提取码:dhr8
- 数据集下载法2(命令行,可以直接linux系统操作)
- 登录Cityscapes官网(网址),注册并登录
- 将下面命令中的myusername、mypassword替换自己的账号和密码
wget --keep-session-cookies --save-cookies=cookies.txt --post-data 'username=myusername&password=mypassword&submit=Login' https://www.cityscapes-dataset.com/login/- 使用提供的ID下载对应数据集(语义分割一般用1,3)
wget --load-cookies cookies.txt --content-disposition https://www.cityscapes-dataset.com/file-handling/?packageID=1
ID与数据集对照表:
1 -> gtFine_trainvaltest.zip (241MB)
2 -> gtCoarse.zip (1.3GB)
3 -> leftImg8bit_trainvaltest.zip (11GB)
4 -> leftImg8bit_trainextra.zip (44GB)
8 -> camera_trainvaltest.zip (2MB)
9 -> camera_trainextra.zip (8MB)
10 -> vehicle_trainvaltest.zip (2MB)
11 -> vehicle_trainextra.zip (7MB)
12 -> leftImg8bit_demoVideo.zip (6.6GB)
28 -> gtBbox_cityPersons_trainval.zip (2.2MB)
-
解压leftImg8bit_trainvaltest,gtFine_trainvaltest后,目录结构如下:
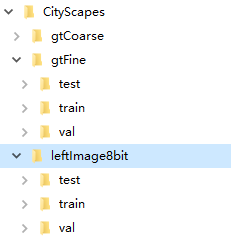
-
该数据集包含精标数据5000份,图片数据存放在“leftImg8bit”目录下,训练集和验证集的语义ground truth放在“gtFine”目录下
- 其中图片尺寸: 1024*2048;
- 训练集: 2975, 验证集: 500, 测试集: 1525;
- 总共类别数目为:包括未标注的0类,总共35类, 其中的labels说明如下图:
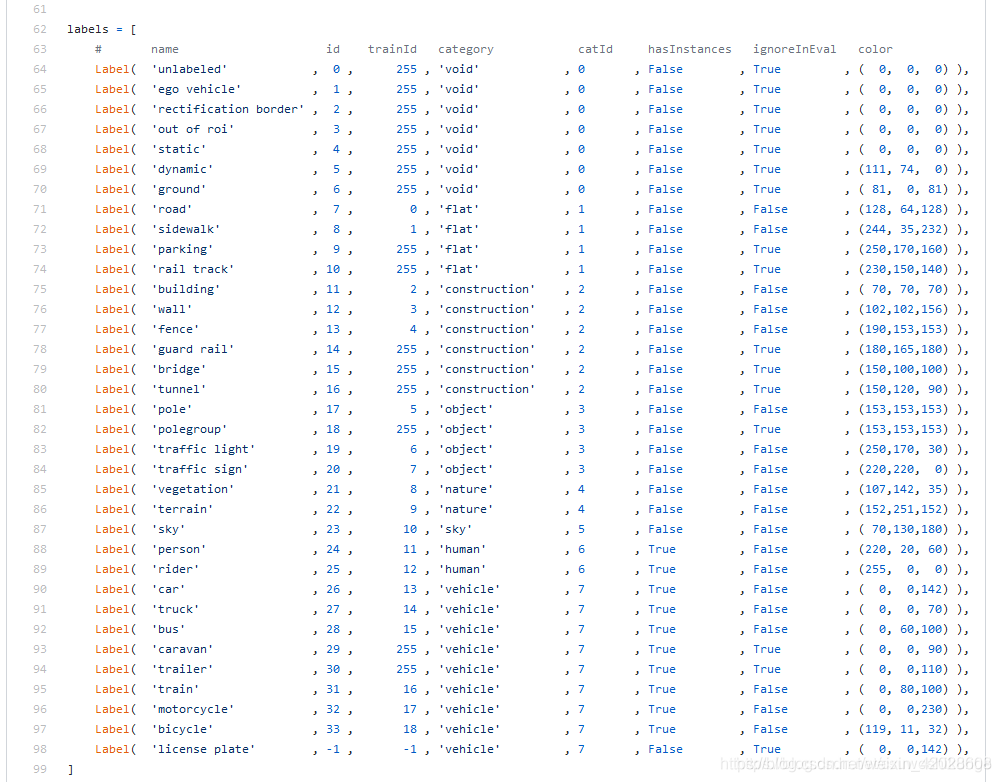
注意到上图中“ignoreInEval”列含有16类在测试集上进行计算时需要忽略,所以总共有19类,关于语义分割任务。
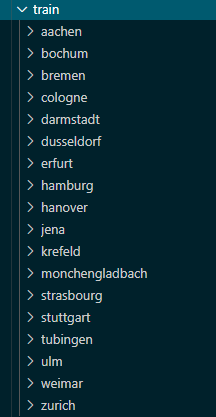
- 在leftImg8bit/train下有18个子文件夹对应德国的16个城市,法国一个城市和瑞士一个城市;在leftImg8bit/val下有3个子文件夹对应德国的3个城市;在leftImg8bit/test下有6个子文件夹对应德国的6个城市。
- 在gtFine/train下也有18个子文件夹对应leftImg8bit/train里面的文件夹,但是不一样的leftImg8bit里面的一张原图,对应着gtFine里面有4个文件

分别为

1. gtFine_color.png是为了可视化,不同类别与色彩的对应关系也在labels.py文件中给出

2. gtFine_instaceIds.png是实例分割的结果,即对同一类中的不同个体进行区分;

3. gtFine_labelIds.png的值是0-33,不同的值代表不同的类,值和类的对应关系在代码中cityscapesscripts/helpers/labels.py中定义;
 4.gtFine_polygons.json存储的标注的第一手数据,即类(“label”: “sky”,“building”,“sidewalk”,等)及其在图像中对应的区域(由多边形"polygon"顶点在图像中的像素坐标给出的封闭区域);
4.gtFine_polygons.json存储的标注的第一手数据,即类(“label”: “sky”,“building”,“sidewalk”,等)及其在图像中对应的区域(由多边形"polygon"顶点在图像中的像素坐标给出的封闭区域);














 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









