







一、单项选择题
1. 在存储数据时,通常不仅要存储各数据元素的值,而且还要存储____。
A. 数据的处理方法
B. 数据元素的类型
C. 数据元素之间的关系
D. 数据的存储方法
2. 下述函数中对应的渐进时间复杂度(n为问题规模)最小是 。
A.
T
1
(
n
)
=
n
l
o
g
2
n
+
5000
n
T_1(n)=nlog_2^n+5000n
T1(n)=nlog2n+5000n
B.
T
2
(
n
)
=
n
2
−
8000
n
T_2(n)=n^2-8000n
T2(n)=n2−8000n
C.
T
3
(
n
)
=
n
l
o
g
2
n
−
6000
n
T_3(n)= n^{log_2^n}-6000n
T3(n)=nlog2n−6000n
D.
T
4
(
n
)
=
7000
l
o
g
2
n
T_4(n)=7000log_2^n
T4(n)=7000log2n
3. 设线性表有n个元素,以下操作中,____在顺序表上实现比在链表上实现效率更高。
A.输出第i(1≤i≤n)个元素值
B.交换第1个元素与第2个元素的值
C.顺序输出这n个元素的值
D.输出与给定值x相等的元素在线性表中的序号
4. 设n个元素进栈序列是p1,p2,p3,…,pn,其输出序列是1,2,3,…,n,若p3=3,则p1的值____。
A.可能是2
B.一定是2
C.不可能是1
D.一定是1
5. 以下各种存储结构中,最适合用作链队的链表是____。
A.带队首指针和队尾指针的循环单链表
B.带队首指针和队尾指针的非循环单链表
C.只带队首指针的非循环单链表
D.只带队首指针的循环单链表
6. 对于链串s(长度为n,每个结点存储一个字符),查找元素值为ch的算法的时间复杂度为____。
A.
O
(
1
)
O(1)
O(1)
B.
O
(
n
)
O(n)
O(n)
C.
O
(
n
2
)
O(n^2)
O(n2)
D.以上都不对
7. 设二维数组A[6][10],每个数组元素占用4个存储单元,若按行优先顺序存放的数组元素a[3][5]的存储地址为1000,则a[0][0]的存储地址是 。
A.872
B.860
C.868
D.864
8. 一个具有1025个结点的二叉树的高h为____。
A.11
B.10
C.11~1025
D.12~1024
9. 一棵二叉树的后序遍历序列为DABEC,中序遍历序列为DEBAC,则先序遍历序列为____。
A.ACBED
B.DECAB
C.DEABC
D.CEDBA
10. 对图1所示的无向图,从顶点1开始进行深度优先遍历;可得到顶点访问序列____。
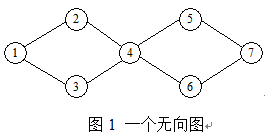
A.1 2 4 3 5 7 6
B.1 2 4 3 5 6 7
C.1 2 4 5 6 3 7
D.1 2 3 4 5 7 6
- 若使用广度优先遍历,则为:1 2 3 4 5 6 7
11. 用链表方式存储的队列(有头尾指针非循环),在进行删除运算时____。
A.仅修改头指针
B.仅修改尾指针
C.头、尾指针都要修改
D.头、尾指针可能都要修改
- 删除运算对应队首,所以在一般情况下的删除结点时只需要修改头指针,但是在特殊情况下,当整个链表/队列只有一个元素时,它既是队首又是队尾,那么删除操作进行,两个首尾指针均要发生了变化。
12. 一般说来,当深度为k的n个结点的二叉树具有最小路径长度时,第k层(根为第1层)上的结点数为____。
A.
n
−
2
k
−
2
+
1
n-2^{k-2}+1
n−2k−2+1
B.
n
−
2
k
−
1
+
1
n-2^{k-1}+1
n−2k−1+1
C.
n
−
2
k
+
n
n-2^k+n
n−2k+n
D.
n
−
2
k
−
1
n-2^{k-1}
n−2k−1
- 要使得二叉树具有最小路径,则整棵树要做到尽可能地“矮胖”,每层结点尽可能放满,第k层即最后一层,上面的k-1层全满时,共有 2 k − 1 − 1 2^{k-1}-1 2k−1−1个结点,则最后一层剩下 n − ( 2 k − 1 − 1 ) n-(2^{k-1}-1) n−(2k−1−1)个结点
二、填空题
1. 顺序队和链队的区别仅在于存储方法或存储结构的不同。
2. 在有n个顶点的有向图中,每个顶点的度最大可达2(n-1)。
3. 对有18个元素的有序表R[1…18]进行二分查找,则查找R[3]的比较序列的下标为9、4、2、3。
4. 对含有n元素的关键字序列进行直接选择排序时,所需进行的关键字之间的比较次数为
n
(
n
−
1
)
2
\frac{n(n-1)}{2}
2n(n−1)。
5. 已知关键字序列为{2,7,4,3,1,9,10,5,6,8},采用堆排序法对该序列作升序排序时,构造的初始堆(大根堆)是10,8,9,6,7,2,4,5,3,1。
三、问答题
1. 一棵完全二叉树上有1001个结点,其中叶结点的个数是多少?
- 二叉树中度为1的结点个数只能是1或0。设 n 1 = 1 n_1=1 n1=1, n = n 0 + n 1 + n 2 = n 0 + n 2 + 1 = 1001 n=n0+n1+n2=n0+n2+1=1001 n=n0+n1+n2=n0+n2+1=1001,由性质1可知 n 0 = n 2 + 1 n_0=n_2+1 n0=n2+1,由两式可求 n 0 = 500.5 n_0=500.5 n0=500.5,不成立;设 n 1 = 0 n_1=0 n1=0, n = n 0 + n 1 + n 2 = n 0 + n 2 = 1001 n=n_0+n_1+n_2=n_0+n_2=1001 n=n0+n1+n2=n0+n2=1001,由性质1可知 n 0 = n 2 + 1 n_0=n_2+1 n0=n2+1,由两式可求 n 0 = 501 n_0=501 n0=501。
2. 给出如下各种情况下求任意一个顶点的度的过程(只需文字描述):
(1)含n个顶点的无向图采用邻接矩阵存储;
(2)含n个顶点的无向图采用邻接表存储;
(3)含n个顶点的有向图采用邻接矩阵存储;
(4)含n个顶点的有向图采用邻接表存储。
- (1)对于邻接矩阵表示的无向图,顶点i的度等于第i行或第i列中元素等于1的个数
- (2)对于邻接矩阵表示的无向图,顶点i的度等于g->adjlist[i]为头结点的单链表中结点的个数
- (3)对于邻接矩阵表示的有向图,顶点i的出度等于第i行中元素等于1的个数;入度等于第i列中元素等于1的个数;度数等于它们之和
- (4)对于邻接矩阵表示的有向图,顶点i的出度等于g->adjlist[i]为头结点的单链表中结点的个数;入度需要遍历各顶点的边表,若g->adjlist[k]为头结点的单链表中存在顶点编号为i的结点,则顶点i的入度增1;度数等于它们之和
-
将整数序列{4,5,7,2,1,3,6}中的数依次插入到一棵空的平衡二叉树中,试构造相应的平衡二叉树。

-
当实现插入直接排序过程中,假设R[0…i-1]为有序区,R[i…n-1]为无序区,现要将R[i]插入到有序区中,可以用二分查找来确定R[i]在有序区中的可能插入位置,这样做能否改善直接插入排序算法的时间复杂度?为什么?
- 不能。因为在这里,二分查找只减少了关键字间的比较次数,而记录的移动次数不变,时间的复杂度仍为 O ( n 2 ) O(n^2) O(n2)。
- 简述外排序的两个阶段。
- 外部排序通常采用归并排序法,它包括两个相对独立的阶段:
①生成若干初始归并段(顺串):将一个文件(含待排序的数据)中的数据分段读入内存,在内存中对其进行内排序,并将经过排序的数据段(有序段)写到多个外存文件上。
②多路归并:对这些初始归并段进行多遍归并,使得有序的归并段逐渐扩大,最后在外存上形成整个文件的单一归并段,也就完成了这个文件的外排序。
四、算法设计题
- 设计一个算法delminnode(LinkList *&L),在带头结点的单链表L中删除所有结点值最小的结点(可能有多个结点值最小的结点)。
- 假设二叉树采用二叉链存储结构存储,设计一个算法copy(BTNode *b,BTNode *&t),由二叉树b复制成另一棵二叉树t。
- 假设一个无向图是非连通的,采用邻接表作为存储结构,试设计一个算法,输出图中各连通分量的节点序列。
//全局变量
VertexType visited[50] = { 0 };
int count = 1;
int num = 1;
void DFS(AdjGraph g, int i)
{
printf("\n%c是第%d个连通分量的第%d个结点", g.adjlist[i].data, count, num);
visited[i] = true;
for (int w = FirstNeighbor(g, g.adjlist[i].data); w >= 0; w = NextNeighbor(g, g.adjlist[i].data, g.adjlist[w].data))
{
if (!visited[w]) //如果该顶点没有访问过
{
visited[w] = true; //修改该顶点的标记
num++; //该连通分量的结点数增加
DFS(g, w); //深度遍历
}
}
}
void DFS_Traverse(AdjGraph g,VertexType x)
{
int i, j;
for (i = 0; i < g.vexnum; i++) visited[i] = false; //访问标记数组初始化
for (i = 0; i < g.vexnum; i++)
if (g.adjlist[i].data == x) j = i; //查找结点x对应的下标
DFS(g, j); //从结点x开始访问
for (i = 0; i < g.vexnum; i++)
if (visited[i] == false)
{
count++; //连通分量数增加
num = 1; //重新每个统计连通分量中的结点个数
DFS(g, i);
}
}
运行结果:

4. 设有n个不全为负的整型元素存储在一维数组A[n]中,它包含很多连续的子数组,例如数组A=(1,-2,3,10,-4,7,2,-5},请设计一个时间上尽可能高效的算法,求出数组A的子数组之和的最大值(例如数组A的最大的子数组为{3,10,-4,7,2},因此输出为该子数组的和18)。
int FindMaxSub(int a[], int num)
{
int i, j, sum, max = a[0], index1, index2;
for (i = 0; i < num; i++)
{
sum = 0; //每一轮重新统计
for (j = i; j < num; j++)
{
sum += a[j]; //累加连续子数组
if (sum > max)
{
max = sum; //更新最大值
index1 = i; //连续子数组的起始坐标
index2 = j; //连续子数组的终止坐标
}
}
}
printf("起始下标:%d,终止下标:%d", index1, index2);
return max;
}
运行结果:
时间复杂度: O ( n 2 ) O(n^2) O(n2)
空间复杂度: O ( 1 ) O(1) O(1)
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









