







HDFS的数据都是以一个个的block块存储的,只要我们能够将文件的所有block块全部找出来,拼接到一起,又会成为一个完整的文件。
接下来我们就来通过命令将文件进行拼接
第一步:
先开启集群
cd /export/servers/hadoop-2.6.0-cdh5.14.0/sbin/
./start-all.sh
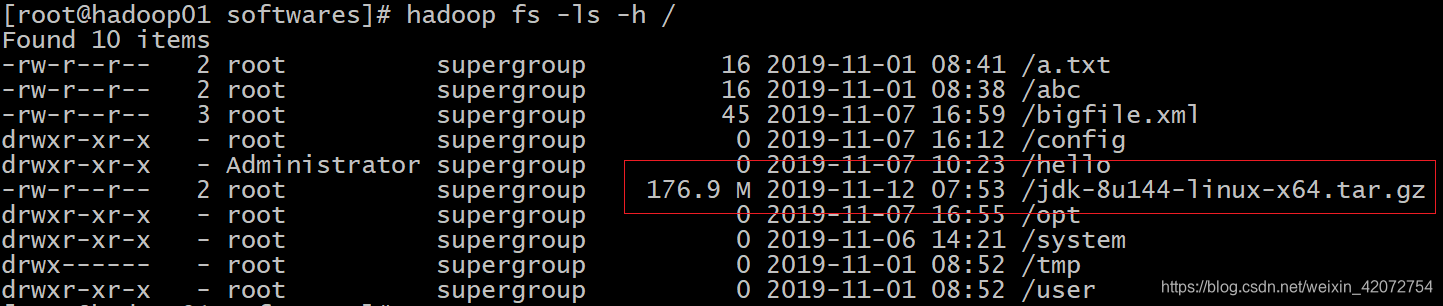
上传一个大于128M的文件到hdfs上面去
我们选择一个大于128M的文件上传到hdfs上面去,只有一个大于128M的文件才会有多个block块
这里我们选择将我们的jdk安装包上传到hdfs上面去
hadoop01执行以下命令上传jdk安装包
cd /export/softwares/
hdfs dfs -put jdk-8u144-linux-x64.tar.gz /
第二步:
web浏览器界面查看jdk的两个block块id
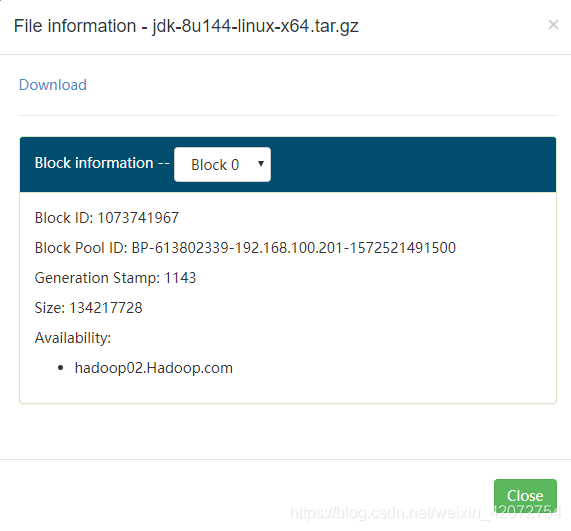
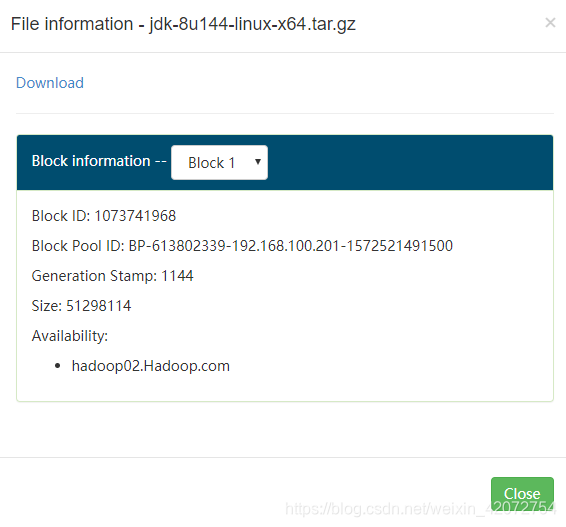
这里我们看到两个block块id分别为1073741967和1073741968
而且它们都在hadoop02上
那么我们就可以通过blockid将我们两个block块进行手动拼接了
第三步:
根据配置文件在hadoop02上找到block块所在的路径
根据我们hdfs-site.xml的配置,找到datanode所在的路径
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>
file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas
</value>
</property>
进入到以下路径(每个机器都不一样,自己找)
cd /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current/BP-613802339-192.168.100.201-1572521491500/current/finalized/subdir0/subdir0/
第四步:
执行block块的拼接
cat blk_1073741967 >> jdktest.tar.gz
cat blk_1073741968 >> jdktest.tar.gz
移动jdk到/export路径,然后进行解压
mv jdktest.tar.gz /export/
cd /export/
tar -zxvf jdktest.tar.gz
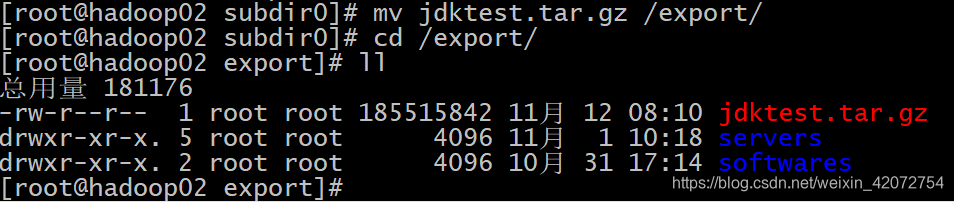
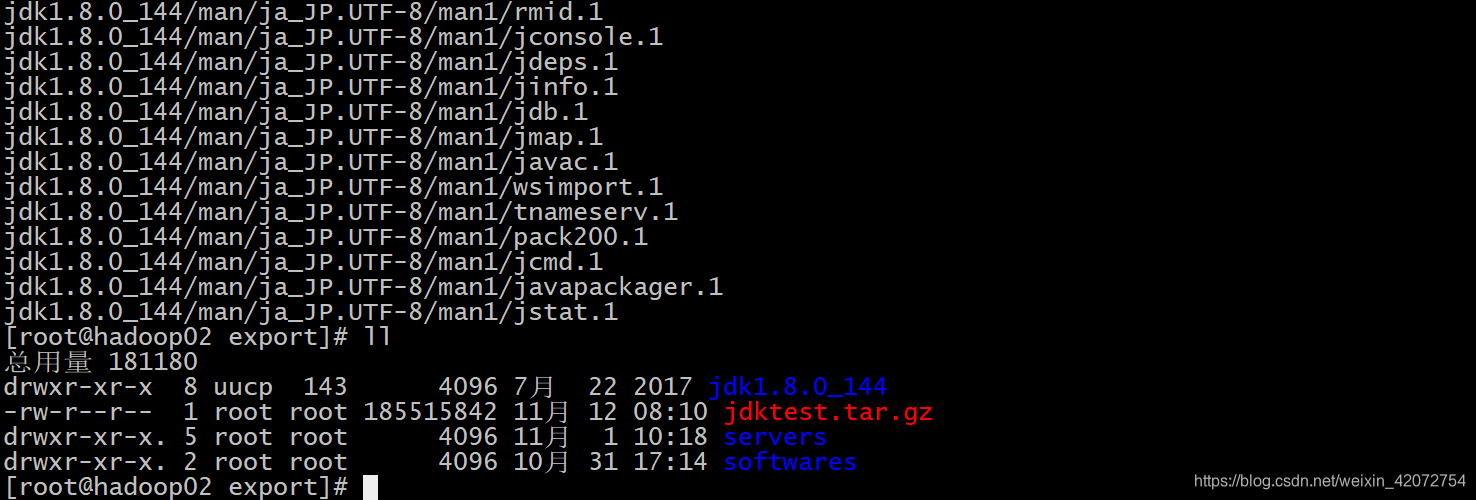
正常解压,没有问题,说明手动拼接block块成功

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









