









前言
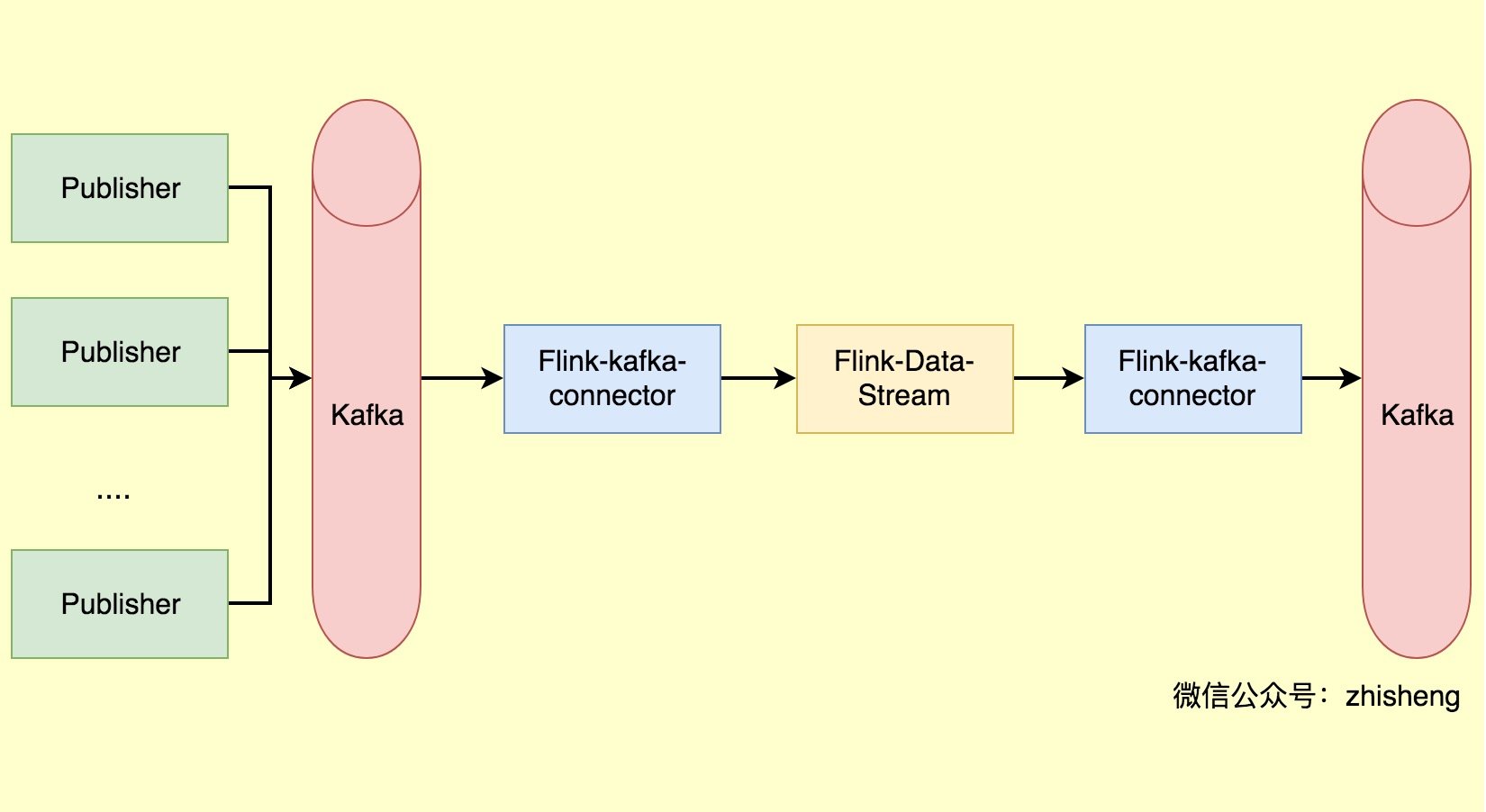
之前文章 —— Flink 写入数据到 ElasticSearch 写了如何将 Kafka 中的数据存储到 ElasticSearch 中,里面其实就已经用到了 Flink 自带的 Kafka source connector(FlinkKafkaConsumer)。存入到 ES 只是其中一种情况,那么如果我们有多个地方需要这份通过 Flink 转换后的数据,是不是又要我们继续写个 sink 的插件呢?确实,所以 Flink 里面就默认支持了不少 sink,比如也支持 Kafka sink connector(FlinkKafkaProducer),那么这篇文章我们就讲讲如何将数据写入到 Kafka。
准备
添加依赖
Flink 里面支持 Kafka 0.8、0.9、0.10、0.11 ,以后有时间可以分析下源码的实现。
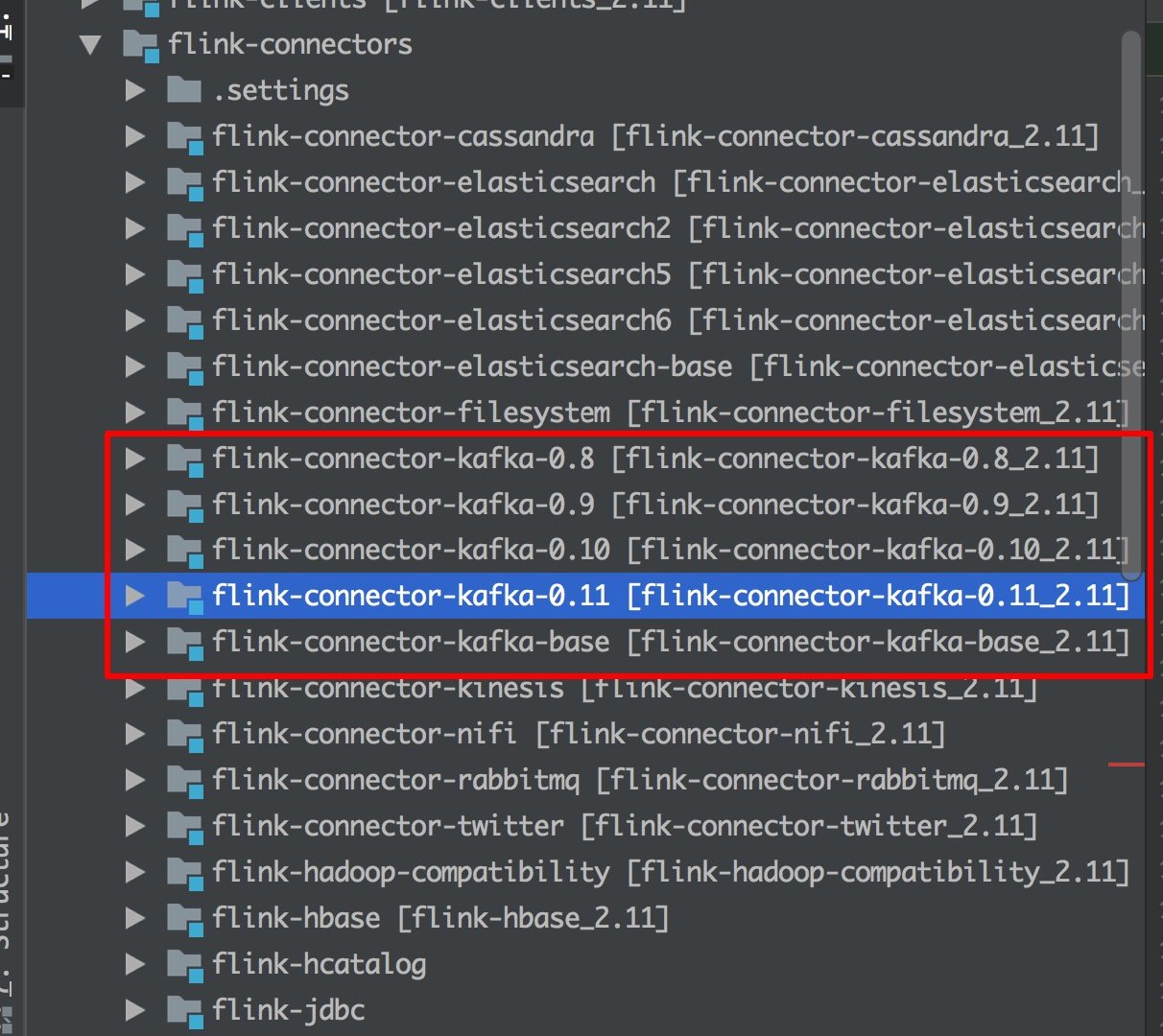
这里我们需要安装下 Kafka,请对应添加对应的 Flink Kafka connector 依赖的版本,这里我们使用的是 0.11 版本:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>${flink.version}</version>
</dependency>Kafka 安装
这里就不写这块内容了,可以参考我以前的文章 Kafka 安装及快速入门。
这里我们演示把其他 Kafka 集群中 topic 数据原样写入到自己本地起的 Kafka 中去。
配置文件
kafka.brokers=xxx:9092,xxx:9092,xxx:9092
kafka.group.id=metrics-group-test
kafka.zookeeper.connect=xxx:2181
metrics.topic=xxx
stream.parallelism=5
kafka.sink.brokers=localhost:9092
kafka.sink.topic=metric-test
stream.checkpoint.interval=1000
stream.checkpoint.enable=false
stream.sink.parallelism=5目前我们先看下本地 Kafka 是否有这个 metric-test topic 呢?需要执行下这个命令:
bin/kafka-topics.sh --list --zookeeper localhost:2181
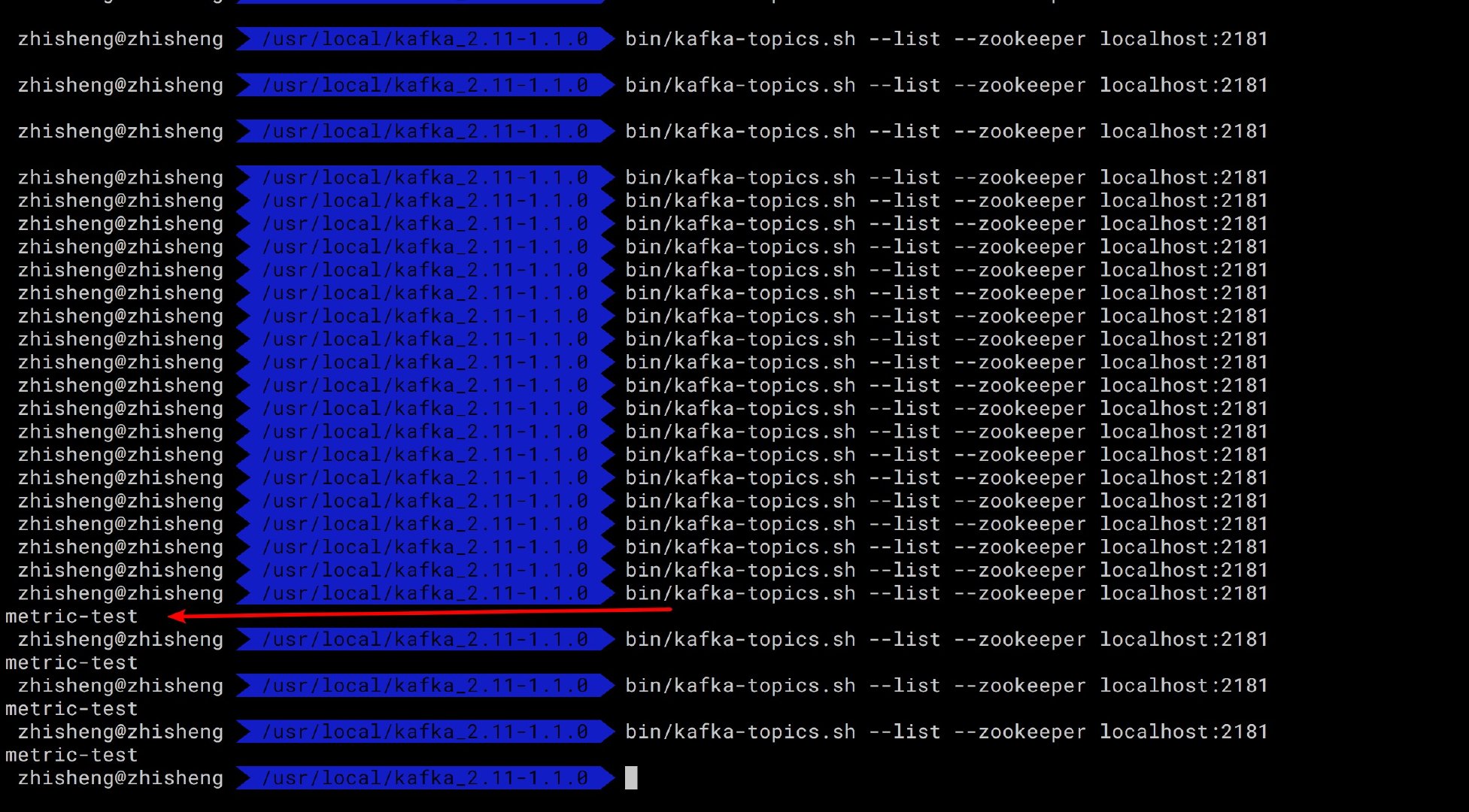
可以看到本地的 Kafka 是没有任何 topic 的,如果等下我们的程序运行起来后,再次执行这个命令出现 metric-test topic,那么证明我的程序确实起作用了,已经将其他集群的 Kafka 数据写入到本地 Kafka 了。
程序代码
Main.java
public class Main {
public static void main(String[] args) throws Exception{
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
data.addSink(new FlinkKafkaProducer011<Metrics>(
parameterTool.get("kafka.sink.brokers"),
parameterTool.get("kafka.sink.topic"),
new MetricSchema()
)).name("flink-connectors-kafka")
.setParallelism(parameterTool.getInt("stream.sink.parallelism"));
env.execute("flink learning connectors kafka");
}
}运行结果
启动程序,查看运行结果,不段执行上面命令,查看是否有新的 topic 出来:
执行命令可以查看该 topic 的信息:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic metric-test

分析
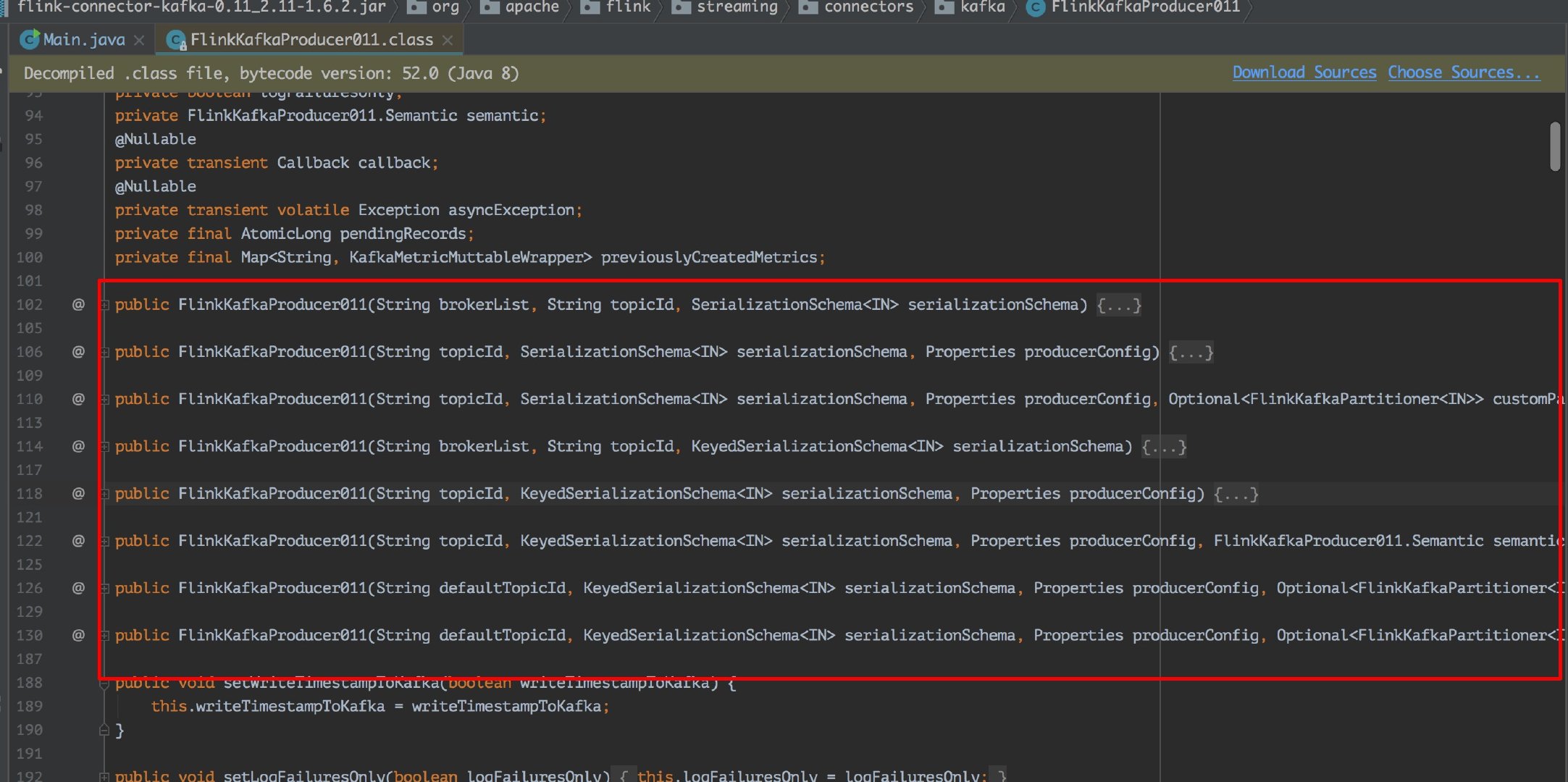
上面代码我们使用 Flink Kafka Producer 只传了三个参数:brokerList、topicId、serializationSchema(序列化)















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









