







目录
1 背景
GEMV(General Matrix Vector Multiplication)矩阵向量乘法是一种特殊的GEMM(General Matrix Multiplication)矩阵乘法,其在Nvidia GPU上的优化方法较GEMM有所不同,Cublas也提供了一些API(如cublasSgemv和cublasDgemv等)直接计算FP32和FP64的GEMV。
在深度学习模型特别是LLM(Large Language Model)的推理优化中,HGEMV(Half-precision General Matrix Vector Multiplication)半精度矩阵向量乘法的优化日趋重要。然而Cublas没有提供直接计算HGEMV的API,只能使用cublasGemmEx等相关API来间接调用Tensor Core计算HGEMV。
Tensor Core的计算需要按块输入和输出,使用Tensor Core计算HGEMV会产生硬件资源的浪费。比如对于MMA16816来说,单次可计算16行结果,而HGEMV的有效行数为1,Tensor Core硬件利用率只有1 / 16。通常情况下,Nvidia GPU中Tensor Core FP16算力是CUDA Core FP32算力的2 ~ 16倍,比如对于RTX3090来说,在FP32乘累加的情况下,Tensor Core FP16算力只有CUDA Core FP32算力的2倍,这种情况下,使用CUDA Core来计算HGEMV,在保证精度的同时,无论是延迟还是硬件利用率都会取得一定的收益。
2 结果
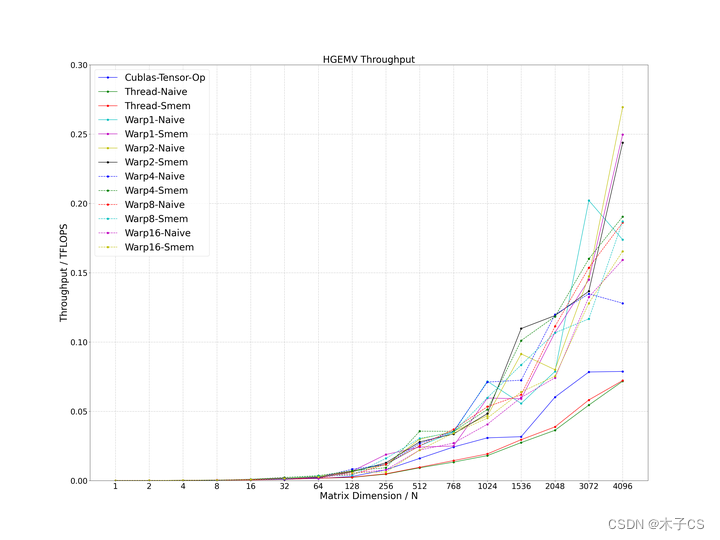
本文主要采用手写CUDA HGEMV Kernel的方式调用CUDA Core,再进行性能调优,并与Cublas的Tensor Core性能作比较,为了保证精度,都使用FP32做乘累加,通过探究各种并行任务设计,目前在1 ~ 4096维度之间的性能均超过Cublas性能的1.5倍,代码开源在cuda_hgemv。
2.1 测试条件
-
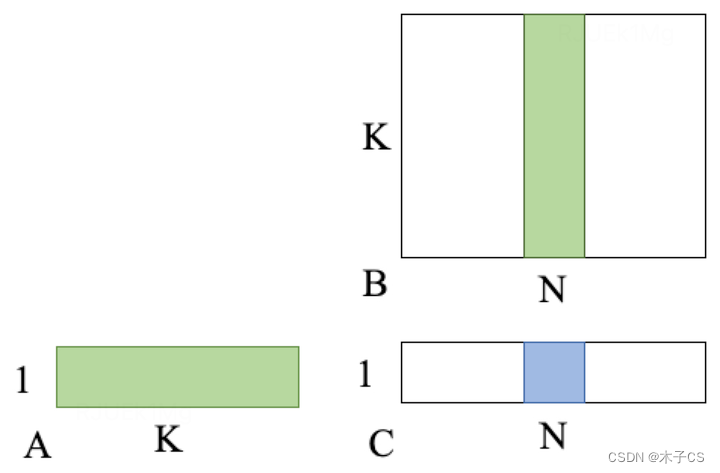
HGEMV:C (1 * N, Half, Row Major) = A (1 * K, Half, Row Major) * B (K * N, Half, Col Major)
-
CUDA:11.8
-
GPU:RTX3090
2.2 设备规格
RTX3090的设备规格如下。
| Graphics Card | RTX3090 |
|---|---|
| GPU Codename | GA102 |
| GPU Architecture | Ampere |
| GPCs | 7 |
| TPCs | 41 |
| SMs | 82 |
| CUDA Cores / SM | 128 |
| CUDA Cores / GPU | 10496 |
| Tensor Cores / SM | 4 (3rd Gen) |
| Tensor Cores / GPU | 328 (3rd Gen) |
| GPU Boost Clock (MHz) | 1695 |
| Peak FP32 TFLOPS | 35.6 |
| Peak FP16 TFLOPS | 35.6 |
| Peak FP16 Tensor TFLOPS | 142 |
| Peak FP16 Tensor TFLOPS | 71 |
| Memory Interface | 384-bit |
| Memory Clock (Data Rate) | 19.5 Gbps |
| Memory Bandwidth | 936 GB/sec |
| L1 Data Cache/Shared Memory | 10496 KB |
| L2 Cache Size | 6144 KB |
| Register File Size | 20992 KB |
2.3 RTX3090
-
K:128
3 计算
由于HGEMV计算的特殊性,在K不是特别大的时候,倾向于一次计算出C中的一个结果,即计算A向量与B矩阵中某一列的完整内积。此处选择一个Thread计算C中的一个结果还是一个Warp计算C中的一个结果,主要是还是取决于计算访存比。更进一步,也可以尝试一个Warp计算C中的多个结果,平衡计算和访存,实现更优的性能。
3.1 Thread级别
假如选择一个Thread计算C中的一个结果,代码如下,只需要在每一个Thread内部计算A向量与B矩阵中某一列的完整内积即可,源码在cuda_hgemv。
#define WARP_SIZE 32
#define WARPS_PER_BLOCK 4
#define THREADS_PER_BLOCK 128 // WARP_SIZE * WARPS_PER_BLOCK
__global__ void threadNaiveKernel(const half *__restrict__ A, const half *__restrict__ B, half *__restrict__ C,
size_t N, size_t K) {
const size_t col = blockIdx.x * THREADS_PER_BLOCK + threadIdx.x;
if (col >= N) {
return;
}
float tmp = 0.0;
#pragma unroll
for (size_t i = 0; i < K; ++i) {
tmp += __half2float(A[i]) * __half2float(B[i + col * K]);
}
C[col] = __float2half(tmp);
}
void threadNaive(half *A, half *B, half *C, size_t N, size_t K) {
dim3 block(THREADS_PER_BLOCK);
dim3 grid(div_ceil(N, THREADS_PER_BLOCK));
threadNaiveKernel<<<grid, block>>>(A, B, C, N, K);
}3.2 Warp级别
假如选择一个Warp计算C中的一个结果,代码如下,与threadNaive不同的是,此处Warp里每个Thread内部仅计算A向量与B矩阵中某一列的部分内积,所以在计算完成之后需要进行一次Reduce Sum,源码在cuda_hgemv。
#define WARP_SIZE 32
#define WARPS_PER_BLOCK 4
#define THREADS_PER_BLOCK 128 // WARP_SIZE * WARPS_PER_BLOCK
__global__ void warp1NaiveKernel(const half *__restrict__ A, const half *__restrict__ B, half *__restrict__ C, size_t N,
size_t K) {
const size_t warp_id = threadIdx.x / WARP_SIZE;
const size_t warp_col = blockIdx.x * WARPS_PER_BLOCK + warp_id;
if (warp_col >= N) {
return;
}
const size_t K_iters = div_ceil(K, WARP_SIZE);
const size_t lane_id = threadIdx.x % WARP_SIZE;
float tmp = 0.0;
#pragma unroll
for (size_t i = 0; i < K_iters; ++i) {
const size_t A_idx = i * WARP_SIZE + lane_id;
const size_t B_idx = i * WARP_SIZE + lane_id + warp_col * K;
tmp += __half2float(A[A_idx]) * __half2float(B[B_idx]);
}
const unsigned int mask = 0xffffffff;
#pragma unroll
for (size_t i = WARP_SIZE / 2; i >= 1; i /= 2) {
tmp += __shfl_xor_sync(mask, tmp, i);
}
if (lane_id == 0) {
C[warp_col] = __float2half(tmp);
}
}
void warp1Naive(half *A, half *B, half *C, size_t N, size_t K) {
dim3 block(THREADS_PER_BLOCK);
dim3 grid(div_ceil(N, WARPS_PER_BLOCK));
warp1NaiveKernel<<<grid, block>>>(A, B, C, N, K);
}我们考虑增加Warp计算量,即一个Warp计算C中的两个结果,代码如下,与warp1Naive不同的是,此处Warp里前16个Thread和后16个Thread内部分别计算A向量与B矩阵中某一列的完整内积,所以在计算完成之后需要在前16个Thread和后16个Thread内部分别进行一次Reduce Sum,源码在cuda_hgemv。
#define WARP_SIZE 32
#define WARPS_PER_BLOCK 4
#define THREADS_PER_BLOCK 128 // WARP_SIZE * WARPS_PER_BLOCK
#define COLS_PER_WARP 2
#define COLS_PER_BLOCK 8 // COLS_PER_WARP * WARPS_PER_BLOCK
#define GROUP_SIZE 16 // WARP_SIZE / COLS_PER_WARP
__global__ void warp2NaiveKernel(const half *__restrict__ A, const half *__restrict__ B, half *__restrict__ C, size_t N,
size_t K) {
const size_t group_id = threadIdx.x / GROUP_SIZE;
const size_t group_col = blockIdx.x * COLS_PER_BLOCK + group_id;
if (group_col >= N) {
return;
}
const size_t K_iters = div_ceil(K, GROUP_SIZE);
const size_t group_lane_id = threadIdx.x % GROUP_SIZE;
float tmp = 0.0;
#pragma unroll
for (size_t i = 0; i < K_iters; ++i) {
const size_t A_idx = i * GROUP_SIZE + group_lane_id;
const size_t B_idx = i * GROUP_SIZE + group_lane_id + group_col * K;
tmp += __half2float(A[A_idx]) * __half2float(B[B_idx]);
}
constexpr unsigned int mask = 0xffffffff;
#pragma unroll
for (size_t i = GROUP_SIZE / 2; i >= 1; i /= 2) {
tmp += __shfl_xor_sync(mask, tmp, i);
}
if (group_lane_id == 0) {
C[group_col] = __float2half(tmp);
}
}
void warp2Naive(half *A, half *B, half *C, size_t N, size_t K) {
dim3 block(THREADS_PER_BLOCK);
dim3 grid(div_ceil(N, COLS_PER_BLOCK));
warp2NaiveKernel<<<grid, block>>>(A, B, C, N, K);
}同样地,我们可以继续增加Warp计算量,即一个Warp计算C中的4、8、16个结果,代码与warp2Naive类似,源码在cuda_hgemv。
4 访存
由于HGEMV是一次计算出C中的一个结果,即计算A向量与B矩阵中某一列的完整内积。在Block内部,A向量需要重复访问,B矩阵只有计算该列的Thread才会访问,所以将A向量提前加载到Shared Memory,有利于缓解对A向量的Global Memory的频繁访问,但是会增加一次数据同步,收益预期会降低。
以threadNaive为例,将A向量提前加载到Shared Memory,代码如下,源码在cuda_hgemv。
#define WARP_SIZE 32
#define WARPS_PER_BLOCK 4
#define THREADS_PER_BLOCK 128 // WARP_SIZE * WARPS_PER_BLOCK
__global__ void threadSmemKernel(const half *__restrict__ A, const half *__restrict__ B, half *__restrict__ C, size_t N,
size_t K) {
extern __shared__ half A_smem[];
size_t A_smem_iters = div_ceil(K, THREADS_PER_BLOCK);
#pragma unroll
for (size_t i = 0; i < A_smem_iters; ++i) {
size_t idx = i * THREADS_PER_BLOCK + threadIdx.x;
A_smem[idx] = A[idx];
}
__syncthreads();
const size_t col = blockIdx.x * THREADS_PER_BLOCK + threadIdx.x;
if (col >= N) {
return;
}
float tmp = 0.0;
#pragma unroll
for (size_t i = 0; i < K; ++i) {
tmp += __half2float(A_smem[i]) * __half2float(B[i + col * K]);
}
C[col] = __float2half(tmp);
}
size_t initThreadSmem(size_t K) {
int dev_id = 0;
HGEMV_CHECK_CUDART_ERROR(cudaGetDevice(&dev_id));
cudaDeviceProp dev_prop;
HGEMV_CHECK_CUDART_ERROR(cudaGetDeviceProperties(&dev_prop, dev_id));
size_t smem_max_size = K * sizeof(half);
HLOG("smem_max_size: %.0f KBytes (%zu bytes)", static_cast<double>(smem_max_size) / 1024, smem_max_size);
HGEMV_CHECK_GT(dev_prop.sharedMemPerMultiprocessor, smem_max_size);
HGEMV_CHECK_CUDART_ERROR(
cudaFuncSetAttribute(threadSmemKernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_max_size));
return smem_max_size;
}
void threadSmem(half *A, half *B, half *C, size_t N, size_t K) {
static size_t smem_max_size = initThreadSmem(K);
dim3 block(THREADS_PER_BLOCK);
dim3 grid(div_ceil(N, THREADS_PER_BLOCK));
threadSmemKernel<<<grid, block, smem_max_size>>>(A, B, C, N, K);
}5 其他
5.1 优化方法
本文主要介绍了CUDA HGEMV的通用优化方法,即计算和访存的平衡。
5.2 源码
本文使用的所有优化方法都开源在cuda_hgemv,后续可能会结合源码进行分析。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









